
이번 글은 TCP가 데이터를 교환하는 과정에 대해서 집중적으로 보겠습니다.
고전적인 형태 (티키타카/핑퐁)
- 고전적인 동작을 보는 이유는 큰 흐름을 잡기 위해서 입니다.
- 데이터를 주고, ACK를 받고 ACK가 오지 않으면 송신자 측에서 재전송
- ACK를 확인할 때 까지 송신자는 추가적으로 보내지 않음.
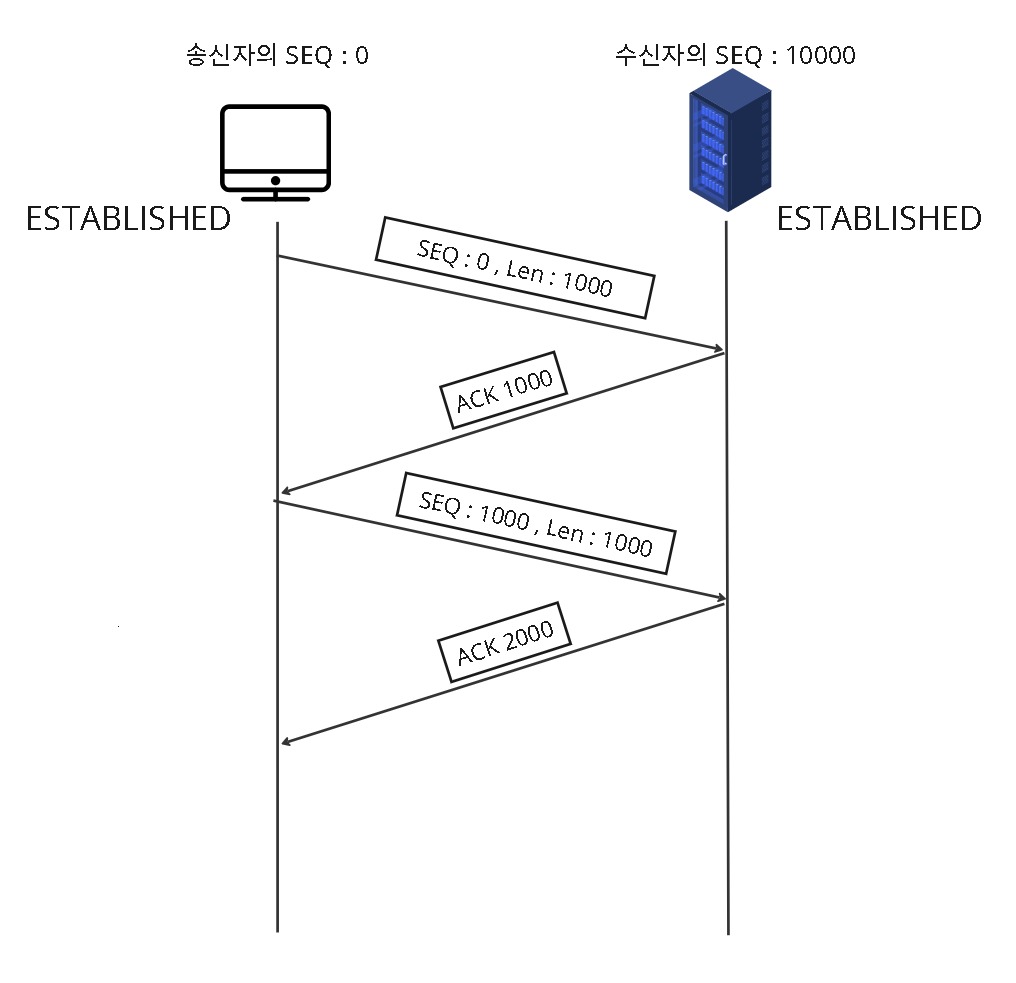
현재의 TCP는 데이터 한 개를 보내고, ACK를 받고 그 후에 자신의 다음 데이터를 보내고 이렇게 동작하지 않습니다.
효율적으로 발전시키는 과정
이해와 설명을 쉽게하기 위해서 한쪽을 송신 다른 한쪽을 수신측으로 가정하겠습니다. 하지만, TCP는 Duplex이기 때문에, 양측이 모두 송/수신이 가능한 프로토콜 입니다. 따라서 이 점을 유의 해주세요.
원하는 사항
- 한번에 여러 개의 데이터를 보내길 바람.
알아야하는 정보
- 송신측에서는 자신의 세그먼트를 어디까지 보냈고, 상대방이 어디까지 받았는지 알아야합니다. (재전송을 위해)
- 수신측에서는 자신이 어디까지 받았는지 확인 후, 송신측으로 ACK를 회신해야합니다.
sliding window
TCP에서 위 사항을 구현하기 위해 채택한 방법입니다. Window라는 또 하나의 버퍼를 만든 뒤, TCP 스트림에 씌우는 느낌입니다.
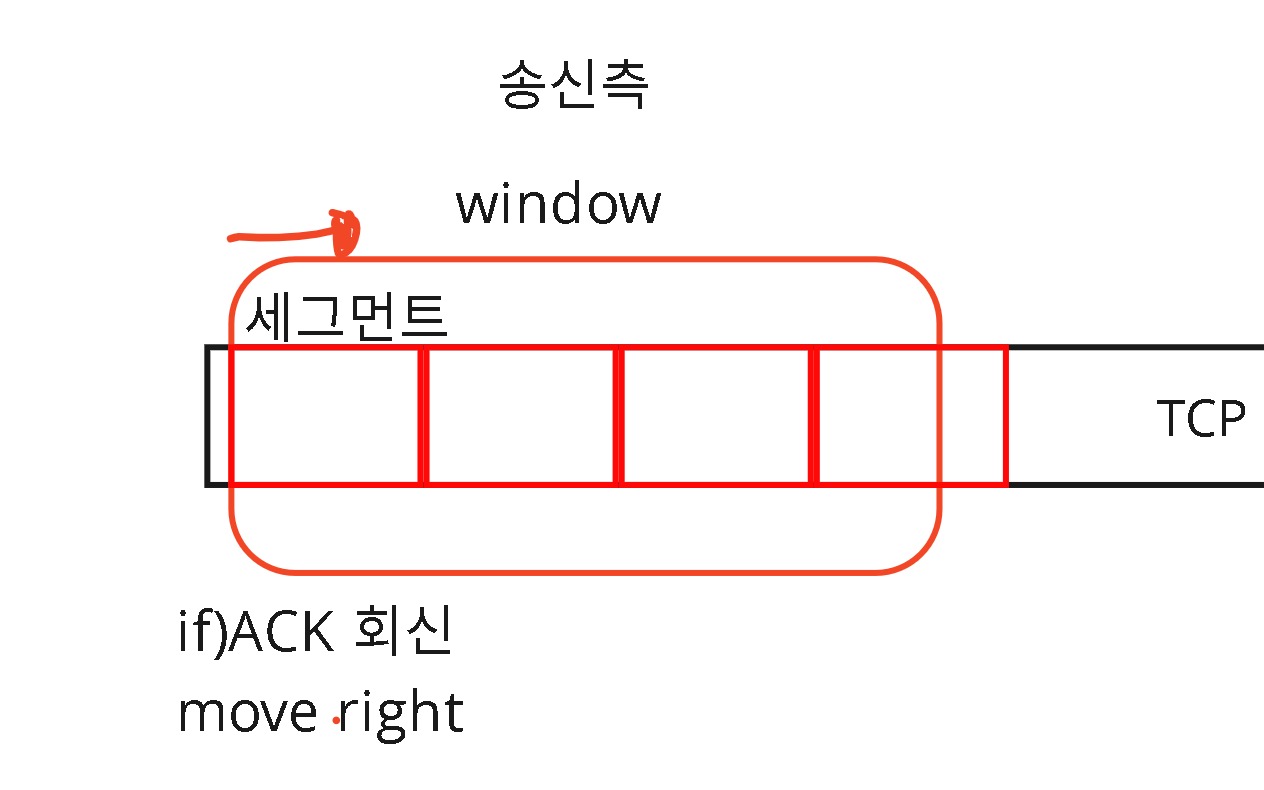
이렇게 했을 때, 송신측에서 알아야할 정보들을 다 알 수 있습니다.
-
정해진 크기만큼 송신측에서는 보내게 됩니다.
-
송신측에서 ACK를 회신했을 때, 윈도우의 왼쪽 끝을 오른쪽으로 움직여주면 됩니다.
- 누적 ACK(자신이 받은 데이터 중, 가장 큰 ACK)를 서로 사용하기 때문에 가능합니다.
- 이렇게 되면 자연스럽게, ACK를 받지 않았는데 송신측에서 버리는 경우는 없습니다.
-
윈도우 크기를 왼쪽에서 줄인만큼 오른쪽으로 늘려준다면 다음 전송시, 재전송 데이터 뿐만 아니라 새로운 데이터도 담아서 보낼 수 있습니다.
- 이게 Window가 옆으로 Sliding(스르륵~)하는 것 같다고 해서 Sliding Window라고 합니다.
예시
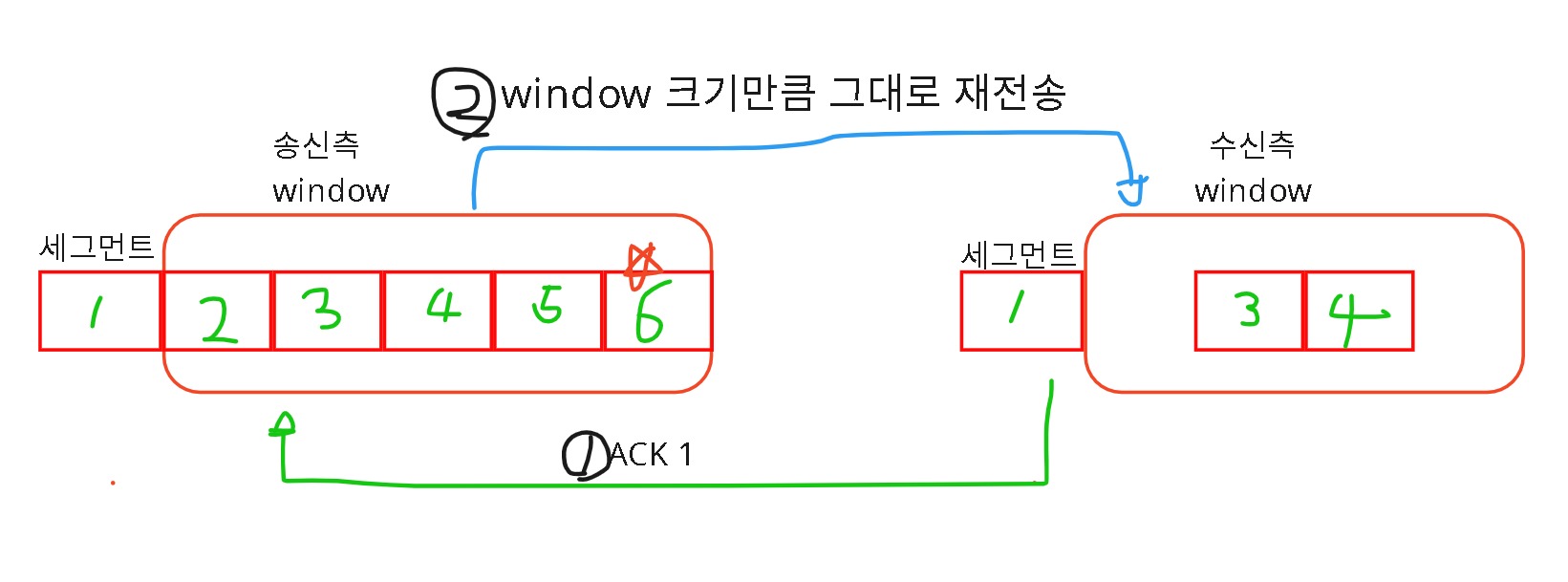
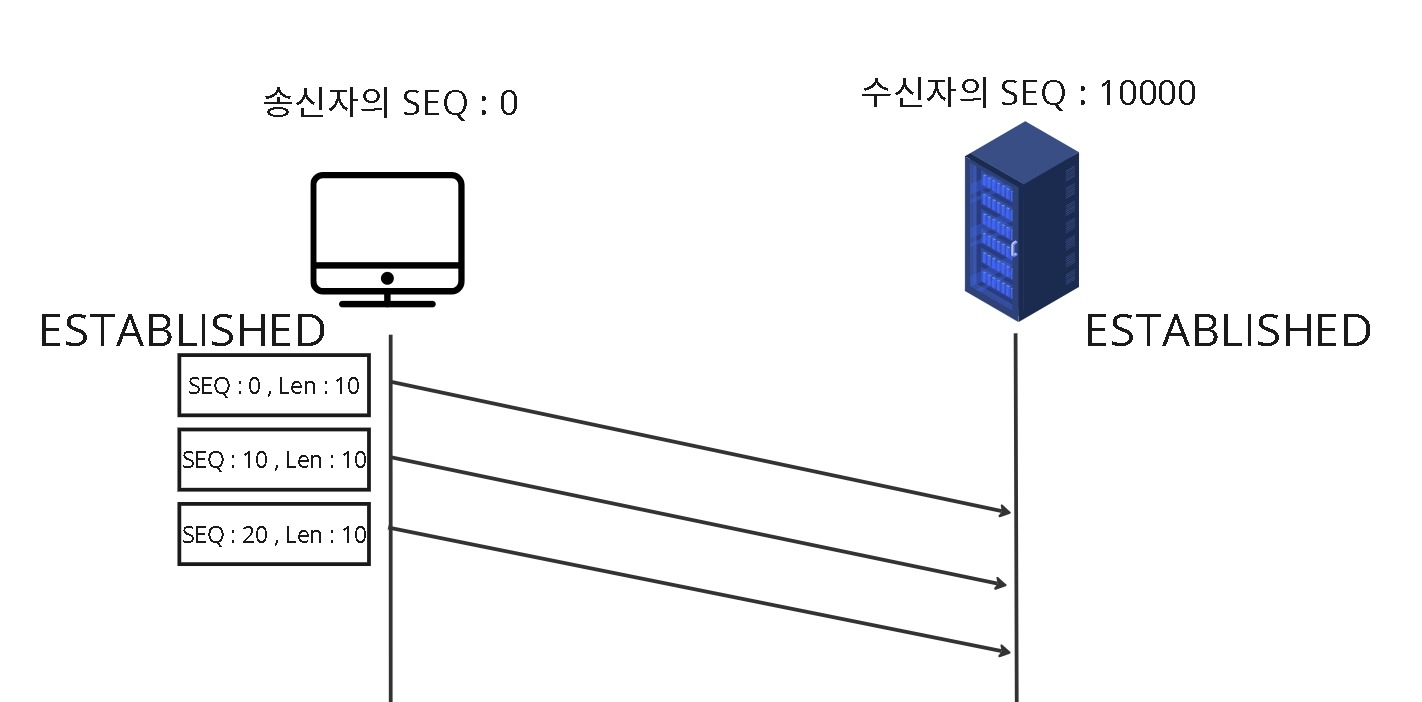
예를들어, Window크기가 5000이고, 5개의 세그먼트를 보냈다고 합시다. 이때, 상대방은 1,2,3,4,5 중 1,3,4을 받고 2,5는 어딘가에서 분실된 상황이라고 가정합시다.
-
수신측에서는 재조립을 할 때, 2에서 빈공간이 있으므로 ACK1을 회신하게 됩니다. ACK를 회신했기 때문에 받았다는게 확정이므로, window를 오른쪽으로 1칸 옮깁니다.
-
ACK를 수신한 송신측의 Window은 오른쪽으로 1칸 더 늘려서 winodow크기만큼 다시 재전송을 합니다.
-
수신측에서는 비어있는 곳은 채우고, 새롭게 받을 공간도 미리 확보해놨기 때문에 다 받았다는 가정하에 ACK6을 회신해주게 됩니다.
위와 같은 방법으로 TCP는 서로 송/수신을 진행하게 됩니다. 눈치가 빠르신 분들은 아셨겠지만 수신측의 window와 송신측의 window크기가 똑같습니다. TCP header의 windowsize가 바로 이 slide window의 크기를 이야기합니다. 서로 받을 수 있는 크기를 교환해서 수신할 능력만큼 TCP는 맞춰서 보내주게 됩니다.
flow Control
TCP 구현만 보자면, 송/수신입장에서 window크기를 굳이 맞춰줘야하나? 라는 생각이 들 수 있습니다. 하지만, 이건 네트워크 상황을 생각해보면 쉽게 알 수 있는 문제입니다.
네트워크로 서로 통신을 할 때, 상대방의 수신능력을 생각하지 않고 세그먼트들을 많이 부어버리면 어떻게 될까요? 수신측이 처리하는 속도보다 상대방이 보내서 쌓이는 속도가 빠르다면, 쌓이는 데이터들의 일부는 없어질 수 밖에 없습니다.
이러한 상황을 방지하는게 Flow Control입니다.
Flow control
수신측의 능력에 맞게 TCP가 설정하는 방법. 매번 WindowSize를 알려주는게 대표적임. WindowSize를 매번 알려준다고해서, 윈도우 광고(window advertisement)라고도함.
zero window상황
수신측에 처리가 느린 상황일 때, 수신버퍼가 점점 차오르다가 수신측의 윈도우가 꽉 차는 상황을 Zero Window라고 합니다. 이 상황에서, 수신측이 열심히 처리해서 윈도우 공간이 생겼을 때, 수신측이 송신측에게 알려야 합니다.
데이터를 보내는것은 아니기 때문에 ACK에 담아서 보내게 되는데, 이때까지 TCP의 동작은 모두 송신측에서 데이터를 재전송한 것이지, ACK를 재전송하는 메커니즘은 없습니다.
ACK가 중간에 없어져도, 추후에 받아야하는 ACK보다 큰 ACK가 왔다면 상관없는 일이고(누적ACK기 때문에, 앞에 있는 데이터는 모두 받았다는게 보장) 진짜 ACK가 없어졌다고 해도, ACK를 받기위해서 송신측이 재전송을 하도록 되어있습니다.

따라서, ZeroWindow상황에서도 송신측에서 수신측을 찔러보면서 ACK를 유도하여 windowSize를 보내도록 해야합니다. 이걸 zero window probe라고도 하는데,용어가 중요한게 아니라 송신측에서 수신측을 찌른다는 사실을 헷갈리면 안됩니다.
네이글 알고리즘
네이글 알고리즘은 TCP의 특징때문에 제안된 방법인데, TCP는 작은 데이터를 보낼수록 손해입니다. TCP는 기본적으로 Header가 큰편이기 때문입니다.
예를들어, 1byte데이터 40번 보낸다고 했을 때, 1 40 + 40 40 = 1640byte씩이나 소모되지만 40byte를 한번에 보내게되면 40 + 40 => 80byte면 됩니다. 약 20배정
도의 차이기 때문에 꽤 큰 차이라고 볼 수 있습니다.
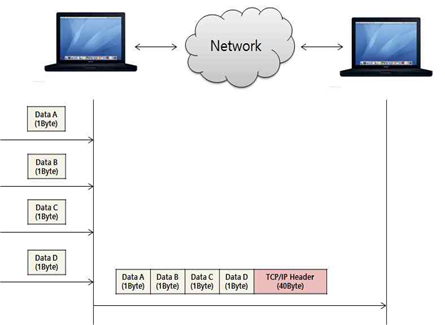
그러므로, TCP는 기본적으로 한 연결에 대해서 MSS까지 꽉꽉 채워서 보내려고 자체적으로 또 다른 버퍼링을 합니다. 물론, 옵션이기 때문에 끌 수도 있습니다.어플리케이션 입장에서는 반응성이 떨어진다는 단점이 있을 수 있지만.. 네트워크의 관점에서 볼 땐 모아서 보내는게 권장되기 때문에, 키는게 default(기본값)입니다.
여기에 ACK도 delay를 시키기 때문에 사실 반응성은 저희가 생각하는것 보다 더 느려질수도 있다고 경고를 하지만, 개인적으로 체감할 정도의 차이는 아니라고 봅니다.
MSS (Max Segment Size)
MTU(1500byte)에서 L3와 L4의 Header를 제외한 사이즈를 MSS라고 합니다.
네이글 알고리즘 보내는 조건
그렇다면, 만약에 만약에 MSS에 도달하지 않는 작은메시지를 여러번 보내는 송신자는 MSS에 도달되지 못한다면.. 영원히 송신이 안될까요?
- 10byte씩 3번 보내서, 총 30byte를 보낸다고 가정합시다.
- MSS에 도달하지 않았기 때문에, 언뜻보면 버퍼링을 하는 과정 중에 있지 않을까?라는 생각이 들 수 있습니다.
- ACK를 회신했다면, 상대방이 현재 원할하게 통신이 가능한 상황이라고 보고, 버퍼링을 하다가 Ack를 받으면 송신을 합니다.
- 슬라이딩 윈도우 위에 버퍼링을 따로하기 때문에, 슬라이딩 윈도우로 여러개의 세그먼트를 보내는건 항상 똑같습니다.
네이글 알고리즘 송신하는 조건
1. MSS에 도달한 경우
2. 이전 ACK를 회신하는 경우
TCP의 연결은 뭘까
TCP의 연결이라는 개념을 더 자세히 보도록 합시다.
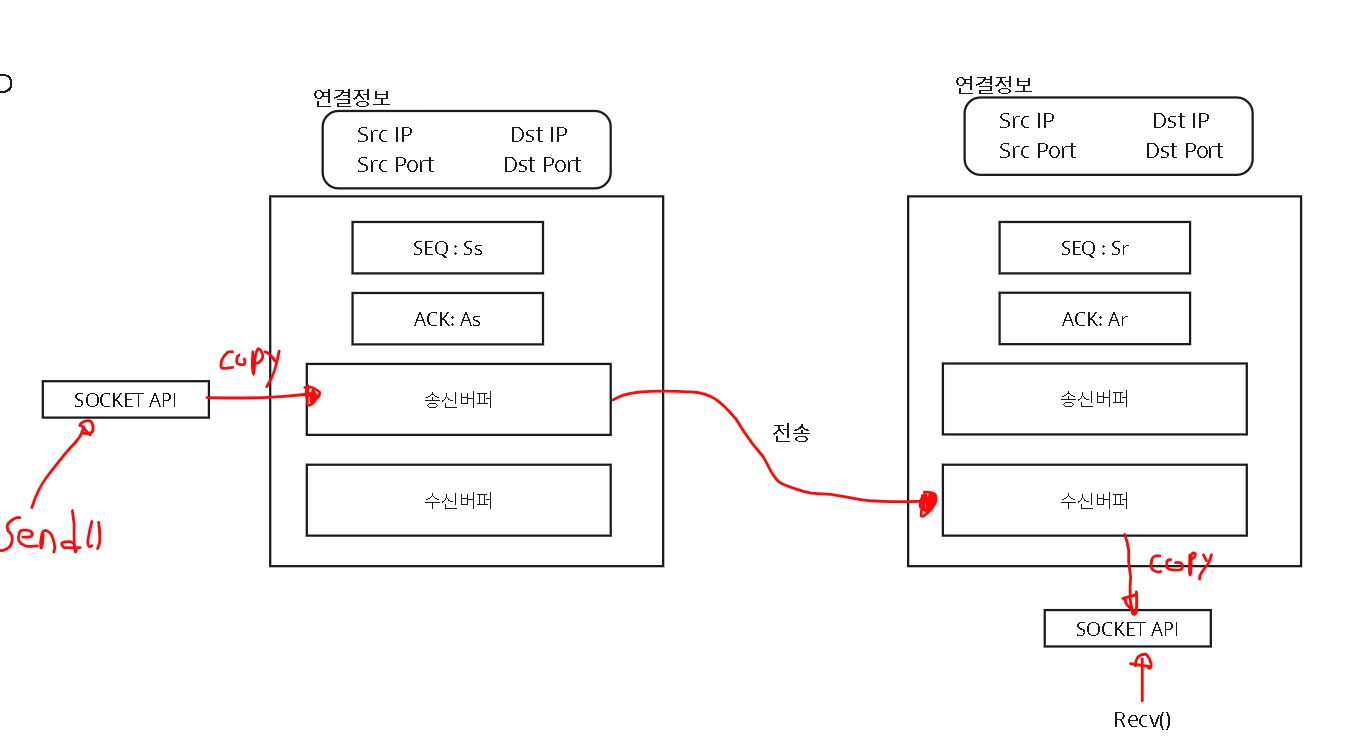
TCP에서의 연결은 진짜로 Connect되있다기 보다는, Connect에 대한 정보들을 서로 들고있는 상태입니다. 연결정보에는 대표적으로 IP와 PORT를 등록해놓고, 그 소켓에 송/수신 버퍼를 준비한 뒤, SEQ Number와 ACK Number를 지정해주게 됩니다.
굳이 글로 쓰는 이유는 TCP가 연결의 개념을 성립한다고 해서, 서로 주기적으로 통신한다거나, 진짜 전화선처럼 연결되어있다고 생각을 할 수 있는데, 아니기 때문입니다.
TCP는 서로 연결(handshake)만 해놓고 아무런 동작을 하지 않으면 그냥 그대로 정보를 갖고 가만히 있게 됩니다.
세그먼트도 나눠질까?
TCP를 다 공부하고 나면, 문득 그런생각이 들 수도 있습니다. L3(IP)가 MTU 때문에 파편화를 하는데..TCP는 이걸 어떻게 대응하는걸까? Header를 봤을 때, 이에 대한 대비책은 딱히 보이지 않기 때문입니다.
case1) L3가 정직하게 쪼갠다.
L3입장에서 봤을 때, L4의 헤더를 만들어낼 능력이 없기 때문에 L4에서 받은 segment를 그대로 쪼갠다고 쳤을 때, 아래그림 같은경우가 있을 수 있습니다.
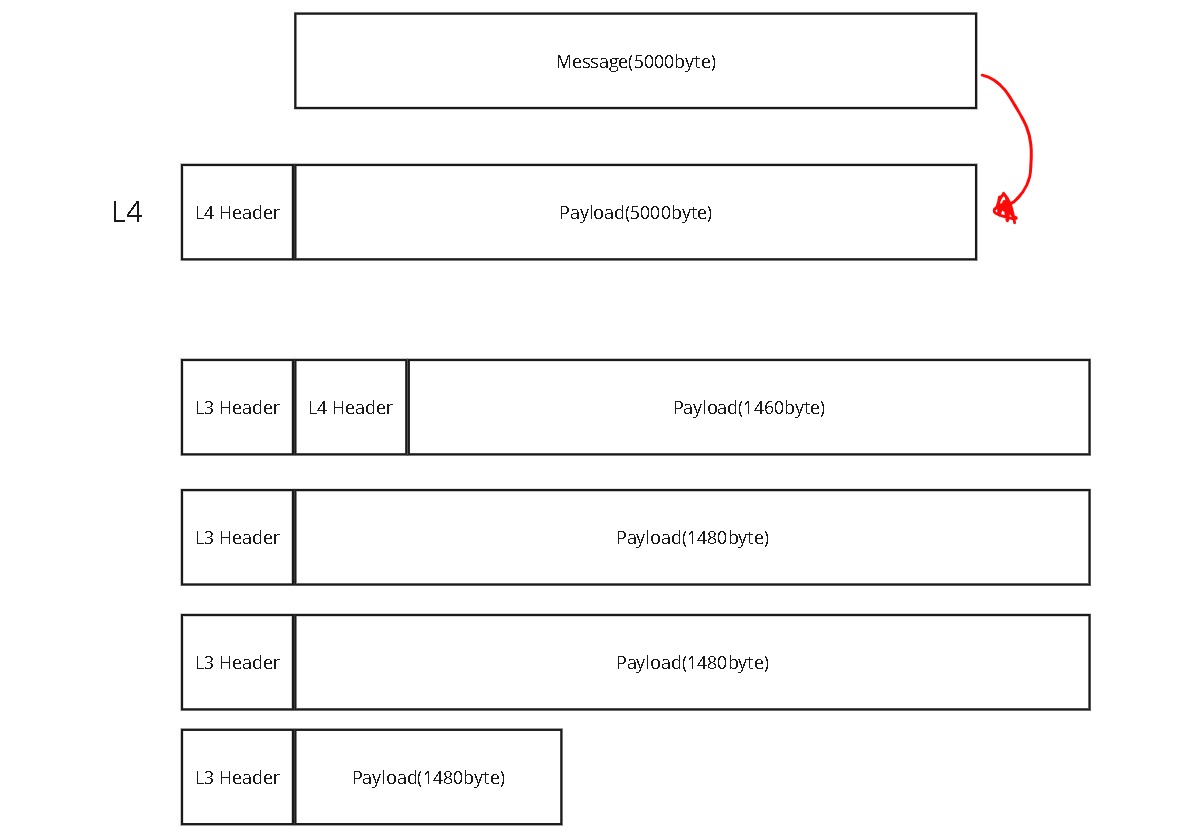
case2)L4가 미리 쪼갠다.
L3가 MTU에 맞게 쪼갠다면, L4에서 미리 쪼개서 Header를 다 붙이고 L3가 받으면 하나의 패킷에 대응될 수 있도록 미리 쪼개는 방법이 있을 수 있습니다.
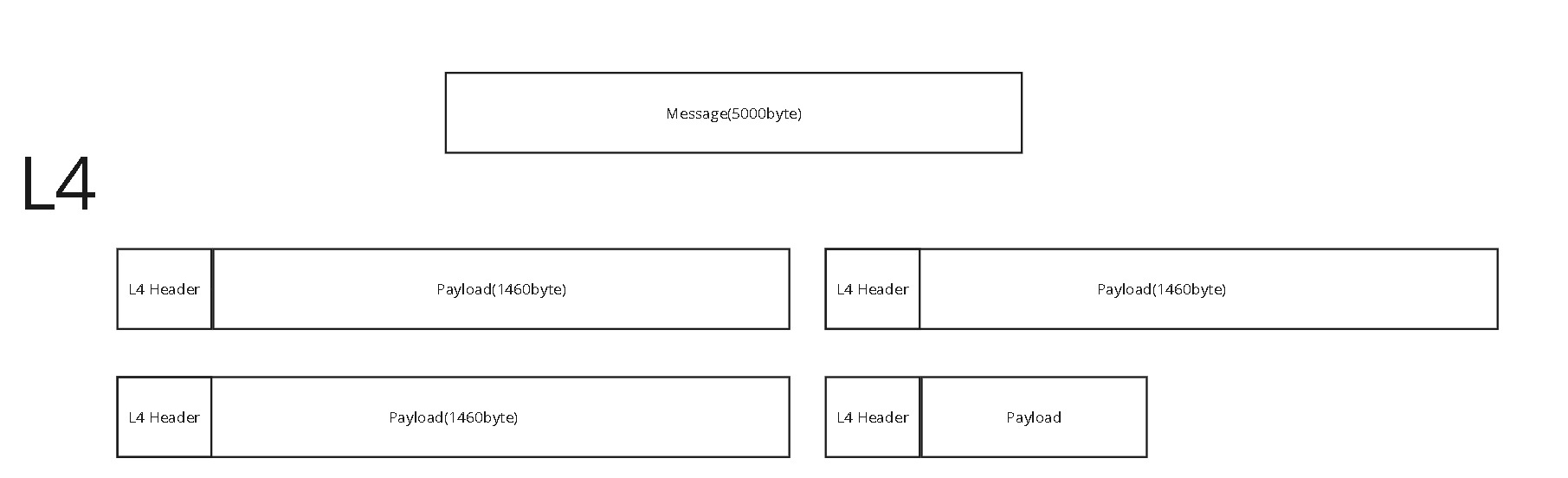
결론
TCP는 case2, UDP는 Case1을 이용합니다. 그래서, UDP도 작은 크기라면 전송이 비교적 안정적이라는 이유가 여기서 나오는 겁니다.
