알고리즘에 대한 개념을 다루기 전, 필요한 기반 지식들 정리글 입니다.
시간복잡도 측정하기
알고리즘 개념을 공부하기 전, 알고리즘 문제를 풀기위해서 가장 먼저 해야하는 일이 있다. 바로 , 입력값의 갯수를 보고, 시간 복잡도를 측정하는 과정이다. 왜냐하면, 알고리즘은 제한시간 안에 결과값을 도출해내는 로직을 짜야한다. 내가 문제를 풀었다고 해도, 시간초과가 나면 그 문제는 틀린것 이기 때문에 시간복잡도를 먼저 생각할 줄 알아야한다.
알고리즘 성능평가
알고리즘의 효율성은 데이터 개수(n)가 주어졌을 때 덧셈, 뺄셈, 곱셈 같은 기본 연산의 횟수를 의미한다. 보통 문제의 시간제한은 1초~2초, 5초 등 수 초 내이다. 컴퓨터는 1초에 약 3~5억번 정도의 계산을 한다고 한다. 즉, 제한시간이 1초라면 내가 짠 로직은 3~5억번 정도의 "연산 횟수"를 가져야한다는 의미이다. 아래의 함수가 자료의 개수에 따라서, 몇번의 연산횟수를 가졌는지 보자.
int countEven(int arr[],int n){
1//int cnt = 0;
2//for (int i=0;i<n;i++){
3// if(arr[i] %2==0){
4// cnt++;
}
}
return cnt;
}- 1번줄에서 '할당'이라는 연산을 한다.
- 2번~ 4번 줄을 n번 반복하게 됩니다.(loop)
- 3번 - 짝수인지 아닌지 판단합니다.
- 4번 - cnt 변수를 증가시켜줍니다. - 5번 return (반환)을 해줍니다.
따라서, 1(할당) + n*(1+1) +1(반환) =2n+2 번의 연산을 하게됩니다. 즉, 자료의 개수가 만개면, 20002번의 연산을 하게된다는 의미입니다. 알고리즘은 일반적으로 최악의 성능을 기준으로 표기하는데, 이러한 표기방법을 빅-오 표기법 이라고 합니다.
O(2n+2) = O(n)이므로, 위의 알고리즘은 O(n) 시간복잡도를 가진다고 합니다.
빠르게 눈으로 성능평가하기(눈평가)
위의 과정대로 정석대로 한다면 정확하게 성능을 평가할 수 있지만 보통은 위와 같은 방법으로 하지 않습니다. 예를들어 봅시다. 다이어트를 할 때, 매번 인바디를 재지는 않습니다. 거울을 보고 '눈바디'를 한다고 하죠. 또, 건강검진을 매일매일 하지 않죠. 그날의 '컨디션'이나 '안색'과 같은 정보들로 판단을 하죠.
마찬가지로, 문제를 풀 때 빠르게 성능평가 를 해야합니다. 그래서 저는 이 과정을 '눈평가' , '눈고리즘','스카우터' 등으로 부릅니다. 2가지를 가장 중점적으로 보면 됩니다.
-
자료의 갯수 -
알고리즘 안의
for문의 갯수int countEven(int arr[],int n){ 1//int cnt = 0; 2//for (int i=0;i<n;i++){ 3// if(arr[i] %2==0){ 4// cnt++; } } return cnt; }
이 코드 같은 경우는 만약, N의 범위가 100,000이라고 하면, "1초에 3~5억개 정도의 연산이 가능하니까, O(N)은 가능할거고 O(N^2)은 불가능하겠구나"라고 판단을 빠르게 내리는거죠! 그렇다면, 우리가 짜야할 코드에는 이중반복문과 같은 N^2의 시간복잡도를 가지는 친구를 사용하면 안되는거죠!
공간복잡도
백준 문제를 보면, 메모리 제한이라는 영역 또한 있습니다. 문제를 풀 때는 공간복잡도 때문에, 에러가 나는 경우는 희박합니다.저도 메모리 부족을 한번도 겪어보진 못했습니다. 메모리 부족보다는 메모리에 수를 표현하는 방식 때문에 에러가 자주 발생합니다.
사실 현실에서는 매우 중요한 영역입니다. 특히, 임베디드 개발과 같은 하드웨어의 아주
제한적인 메모리상에 프로그래밍을 하는 경우나게임 그래픽과 같이 한 데이터 단위가 클때는 매우 중요한 영역이 됩니다.
정수형
C++언어에서는 Int는 4byte , char은 1byte , long long은 8byte와 같이 각각의 자료형 마다 메모리의 크기가 정해져 있다.
Char으로 예시를 들어보자. char a; 라고 선언하면 1byte = 8bit이므로, 아래와 같이 메모리 공간이 잡힌다. 여기서, 맨 앞 bit는 부호를 나타내기 위한 비트로 쓰이고, 실질적으로 쓰는 비트는 까지 영역이다. ( 이 부분은 , 2's complement를 찾아보면 더 이해가 잘 된다.)
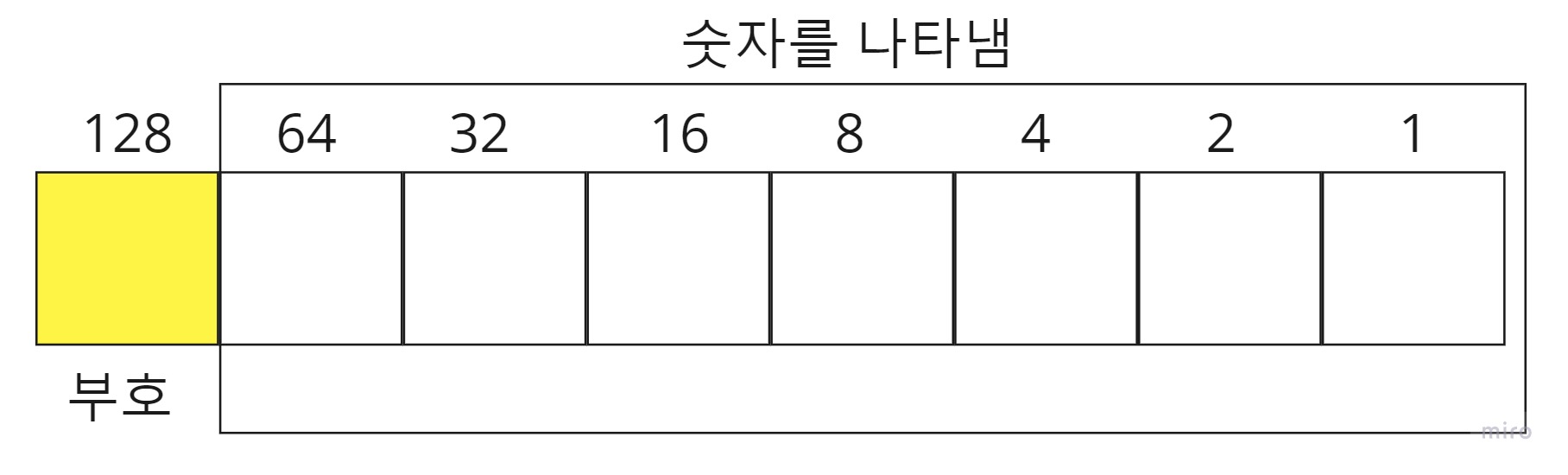
중요한건 , 이 바이트의 숫자에 따라서, 숫자의 표현 범위가 정해진다는 점이다. 숫자를 나타내는건 6개의 비트로 나타낼 수 있다. 최대는 0111111<2>으로 127이고, 최솟값은 11111111<2> 이므로, -128까지 표현이 가능하다.
OverFlow
위의 숫자의 표현 범위를 넘는 에러를 OverFlow라고하는데, 정말정말 많이 발생시키는 에러 중 하나이다. 왜나하면, char a =128과 같이 직접적으로 에러를 선언하는 경우는 매우 적고 찾기도 쉽지만, 계산과정 중 선언한 자료형에서 표현할 수 있는 숫자를 넘어서는 경우가 많기 때문이다. 예를들어, Factorial계산을 할 때, 18!만 되어도 6402373705728000와 같이 엄청 커져버릴 수 있기 때문이다.
따라서, 각각의 자료형의 표현범위를 잘 알고있어야한다. 표현범위를 넘어서는 경우에는 문자열로 나타낸다던지, 배열에 하나하나 숫자를 넣는다던지, Mod연산을 통해서 자릿수를 줄인다던지 등의 테크닉이 필요하게 된다.
실수형
실수형은 정수형보다 더 어렵다. 부동소수점 방식으로 소수를 나타내는데, 이 과정에서 오차가 발생하게 되고 아래와 같은 대표적인 현상들이 나타나게 된다.
- 실수형은 오차가 발생할 수 밖에 없다.
- double에 longlong 범위의 정수를 함부로 담으면 안된다.
- 실수를 비교할 떄는 등호를 사용하면 안된다. 유효범위 내에 있다면, 같은 값으로 처리하면 된다.
아래의 예시에서 극명하게 드러난다. 0.1+ 0.1+0.1 = 0.3이라고 생각해서, 0.3과 같다는 어쩌면 당연한 로직을 짯는데, 어라 false가 출력이 된다.
#include <bits/stdc++.h>
using namespace std;
int main()
{
double a = 0.1 + 0.1 + 0.1;
double b = 0.3;
if (a == b)
{
cout << "true" << '\n';
}
else
{
cout << "false" << '\n';
}
return 0;
}
이는 실수의 표현방식 땜에 발생하는 오류인데, 0.3의 값을 정확하게 표현하지 못하기 때문이다. 그러므로, 실수는 "유효범위"라는 것을 갖고있는데 float은 아래 6자리까지, double은 아래 15자리까지는 유효하다라고 한다. 그러므로, 보통은 1e-12과 같이 아주 작은 숫자범위 안에 둘의 차이가 있다면 같다라고 하면된다.
만약,매우매우 정말한 측정을 요구하는 서비스(실험장비, 정밀기계, 의료기계..등)를 만든다면위와 같은 특성은 매우매우 중요할 수 있다.
#include <bits/stdc++.h>
using namespace std;
int main()
{
double a = 0.1 + 0.1 + 0.1;
double b = 0.3;
if (abs(a - b) < 1e-12)
{
cout << "true" << '\n';
}
else
{
cout << "false" << '\n';
}
return 0;
}
