점차 개념들이 하나하나 등장하기 시작하네요! 오늘은 탐색의 대표격인 이분탐색(Binary Searching)입니다. 저는 Python을 이용할 때도 이분탐색은 직접구현해서 썻기 때문에 이분탐색은 직접구현해서 써야지! 라는 척화비가 있었습니다. 하지만, C++ STL이 훨씬훨씬 쓰기 편하게 되어있고, 이분탐색을 직접 구현하는데 실수가 발생할 수 있기 때문에, 되도록이면 STL에 있는걸 쓸 예정입니다.

이분탐색(Binary Search)
이분탐색에는 1가지 조건이 붙습니다. 아주아주 중요합니다. 정렬이 되어있어야합니다.
- 정렬이 되어있는 상태에서 중간값을 기점으로 특정원소를 찾기위해서
탐색 범위를 절반씩 줄여나가는 개념입니다. - O(logN)만에 원하는 원소를 탐색할 수 있게 됩니다.
이분탐색을 문제를 풀 때, 신경써야하는건 3가지입니다. 은근히 문제를 읽으면서 막막한 경우가 많고 자칫 잘못해서 다른 풀이로 빠져버릴 수 있기 때문에, 3가지를 기준으로 생각하면 편하더라구요!
- 탐색범위를 설정해야합니다.(Start , End)
- 탐색할 대상이 무엇인지 생각해야합니다.
- 탐색할 대상과 mid값의 대소관계에 따라서 탐색범위를 어떻게 정해줄 것인지 생각해야합니다.
- 선택한 Mid 값이 이분적으로 범위를 잘 나누는지 확인해야합니다.(무한루프 방지)
정렬이 되어있는 원소에서 특정원소를 찾기
예를들어, 배열 A=[1,2,5,8,10,13,20,28,29]에서 5를 탐색한다고 생각해봅시다. 탐색범위는 처음부터 배열의 끝원소를 가리킨다고 생각합시다. 우리가 탐색 하고자 하는 원소는 "5"입니다.
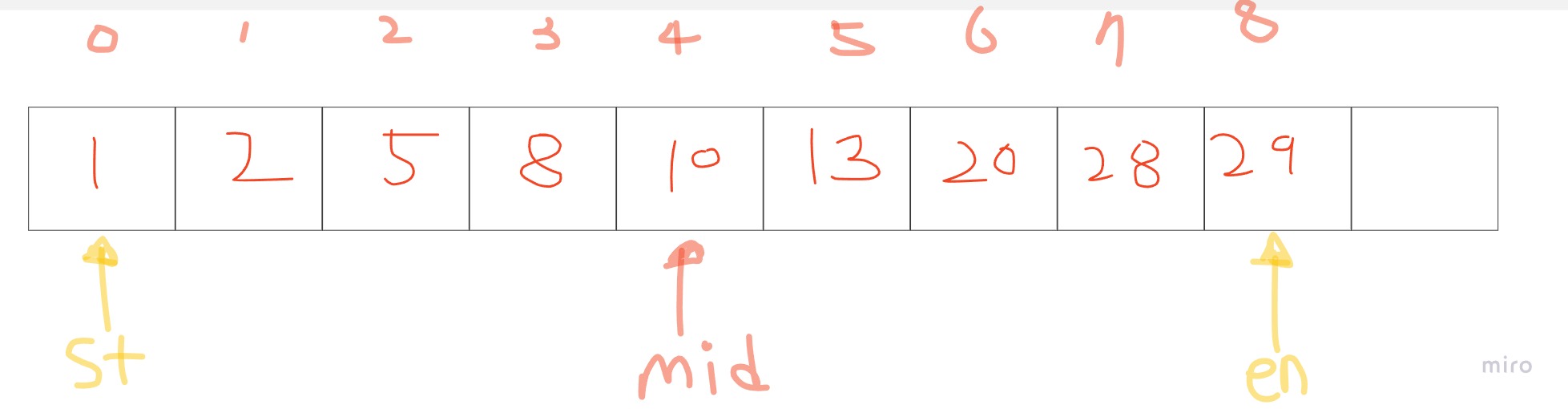
위 그림에서, Mid가 가리키는 값은 현재 5보다 큽니다. 정렬되어있는 상황이기 때문에, 5는 mid보다 왼쪽에 있다는 사실이 자명하게 됩니다. 그렇다면, en을 mid -1로 옮겨 다시 탐색을 하면 되겠죠!(그림에서는 하늘색 범위를 가리킵니다.)
if) mid가 5보다 작다면? -> st를 mid 다음범위로 옮겨줍니다.(그림에서 노란 범위를 탐색 )
if) mid가 5였다면? -> 그 값을 return 해주면 됩니다. (그림에서 빨간색 범위)
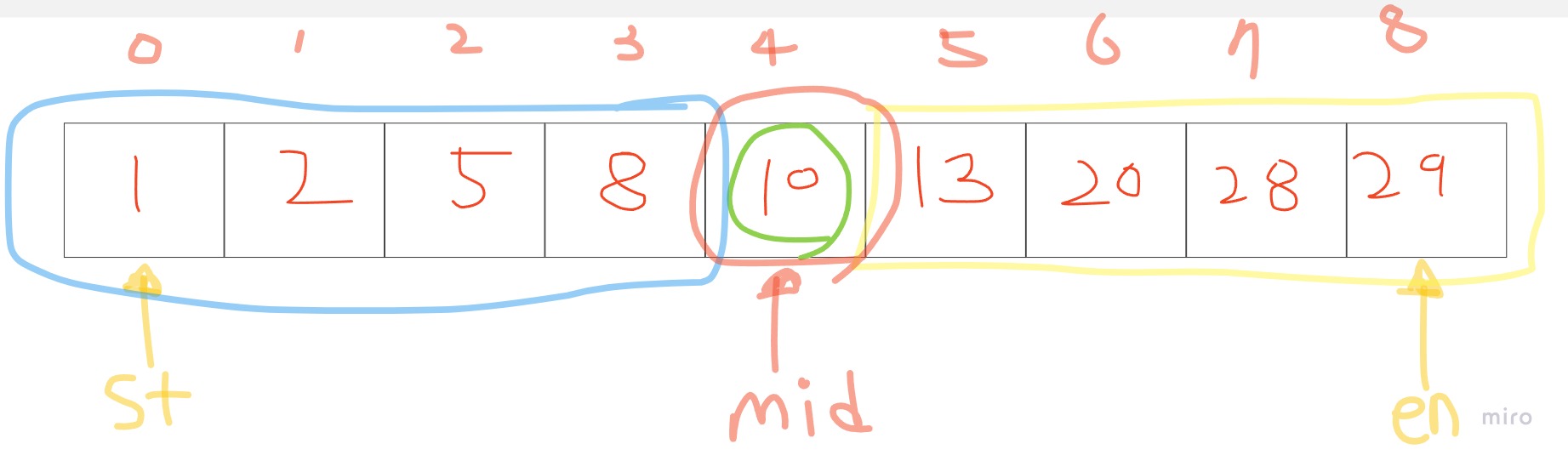
이런식으로 구간이 3개로 나누어진 상태로 st가 en를 넘어설 때 까지 탐색을 쭉 진행해가면 됩니다.
직접 구현하기
#include<bits/stdc++.h>
using namespace std;
int A[10]={1,2,5,8,10,13,20,28,29}
int main(){
int st = 0;
int en = 9; //A.size() -1
int target = 5;
while(st<=en){
int mid = (st+en)/2;
if(A[mid]<target)
st=mid+1;
else if(A[mid]>target)
en = mid -1;
else{
cout<<"Find!"<<'\n';
cout<<"idx: "<<mid<<'\n';
break;
}
}
return 0;
}STL을 이용하기
C++의 binary_search() 함수를 이용할 수 있습니다. 해당 배열/STL에 원소가 있는지 'true/false'를 반환해줍니다.
#include <bits/stdc++.h>
using namespace std;
int A[10] = {1, 2, 5, 8, 10, 13, 20, 28, 29};
int main()
{
int st = 0;
int en = 9; // A.size() -1
int target = 5;
cout << binary_search(A, A + 10, target) << '\n';
// while (st <= en)
// {
// int mid = (st + en) / 2;
// if (A[mid] < target)
// st = mid + 1;
// else if (A[mid] > target)
// en = mid - 1;
// else
// {
// cout << "Find!" << '\n';
// cout << "idx: " << mid << '\n';
// break;
// }
// }
return 0;
}중복된 원소 갯수 찾기(범위 이분 탐색하기)
배열에 중복되는 원소들이 있다면 어떻게 될까요? 그리고, 그 중복되는 원소들을 좀 더 정확하게 파악하고 싶다면 어떤 방법을 쓸 수 있을까요?
이 아이디어 자체를 떠올리는건 매우매우 힘들기 때문에, 이 상황에서도 이분탐색을 이렇게 이용할 수 있다는 개념을 체화시켜 봅시다.

아이디어의 출발은 이렇다고 합니다. 우리가 현재 알고있는 값은 Target이 되는 값과 정렬된 Array,배열의 시작점과 끝점(중간지점)을 알 수 있습니다. 이때, 이분탐색을 응용해서 A[mid]값과 우리가 갖고있는 target을 이용해서 Target이 시작되는 지점을 찾으려고 합니다.
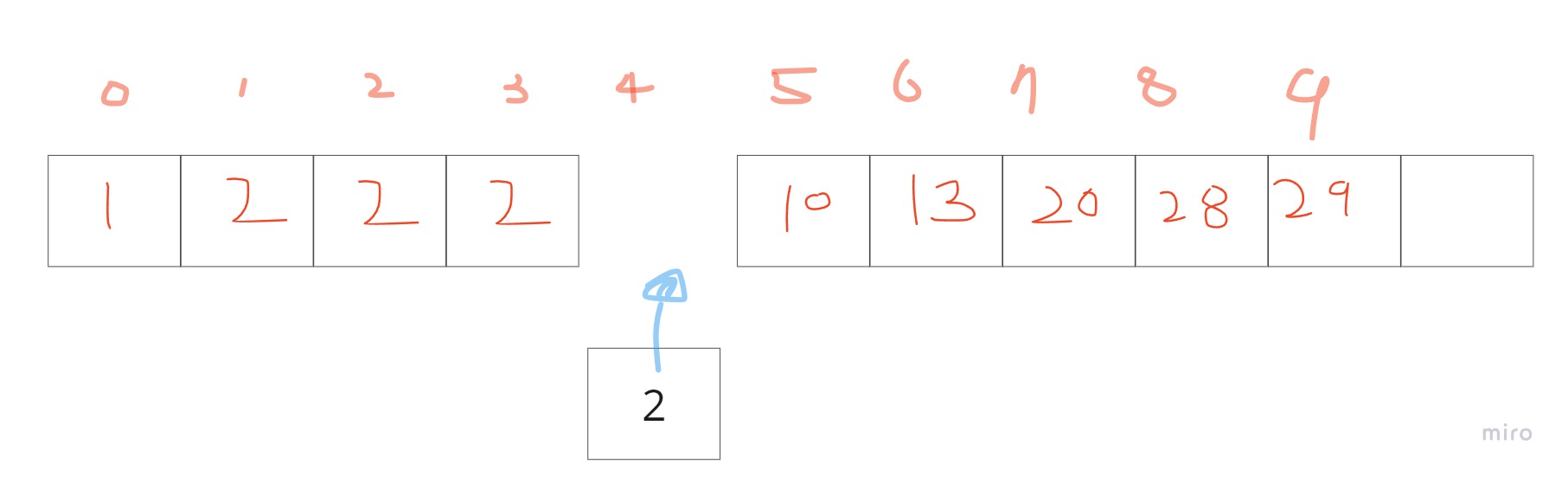
만약 Target이 배열의 중간지점에 들어가면 어떻게 될까요? 다행스럽게도 정렬이 깨진 상태가 되지 않습니다.(이분탐색을 계속할 수 있습니다). 이때, A[mid]는 Target보다 큽니다.
즉, A[mid]>target이 성립한다면,우리는 적어도 A[mid]의 index이하에서 2가 시작한다는건 보장받을 수 있게 됩니다. 즉, 이하라는 이야기는 A[mid]에서 2가 시작될 수도 있습니다. 예를들어, A=[1,1,1,1,10...]이었다면, 10의 자리에 2가 들어갈 수 있기 때문입니다.
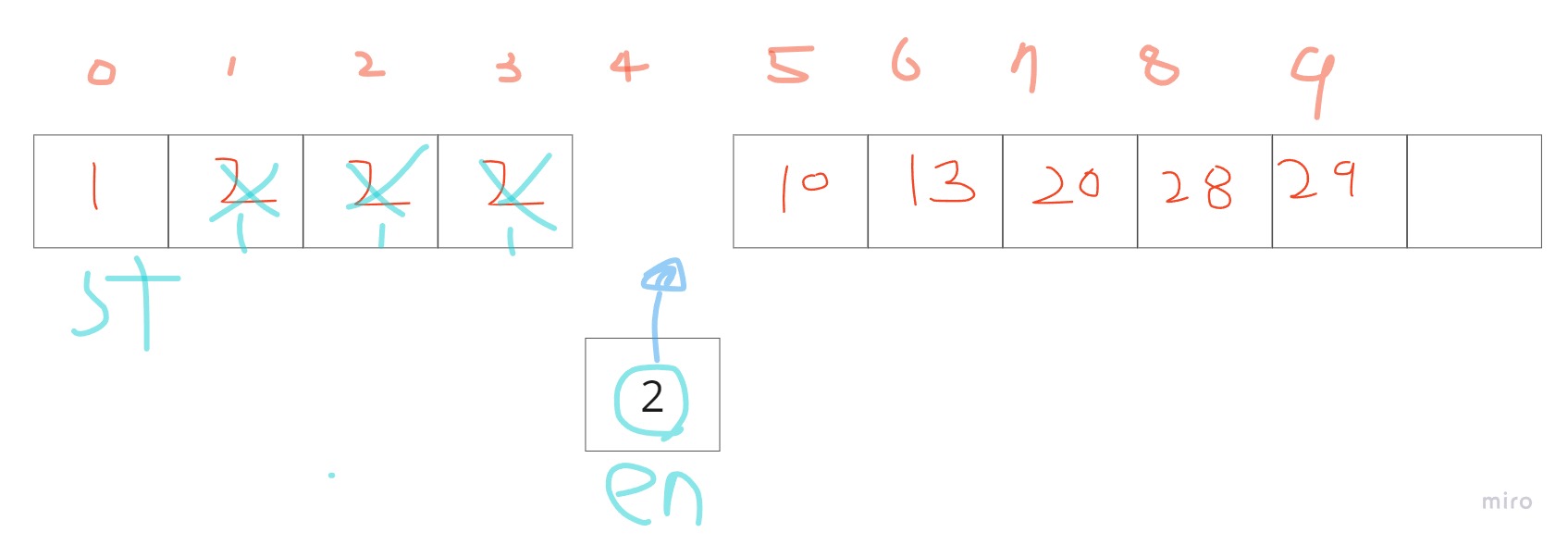
즉, A[mid]>=target이라면,en을 mid로 옮깁니다.
만약, A[mid]<target 이라면 어떨까요? 이때는 2의 시작위치는 mid보다 오른쪽에 있다는게 보장이됩니다. 왜냐하면, 정렬이 되어있는 상태니까요! 즉, A[mid] <target이면, st = mid+1로 옮겨주면 됩니다.
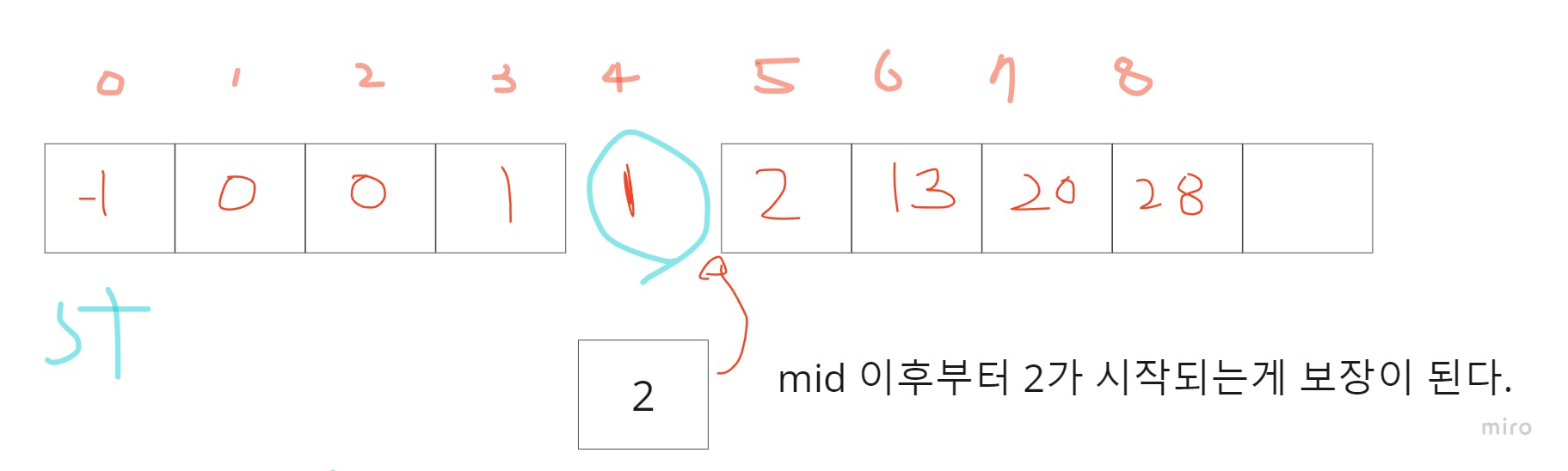
이 과정을 en이 st를 넘어설 때까지 반복해주면 됩니다.st<en입니다. st와 en이 겹치는 구간이 생겼을 때, st가 시작지점을 가리키게 하기 위해서 en을 왼쪽으로 계속 옮기게 됩니다. 따라서, 같을때 연산을 넣게되면 연산이 꼬이므로, 조건을 st<en인 점을 꼭 명심해야합니다.
처음 등장하는 Idx
void lower_idx(int target){
int st =0;
int en = N;
while(st<en){
int mid=(st+en)/2;
if(A[mid]>=mid)
en = mid;
else st = mid+1;
}
return st;
}마지막으로 등장하는 Idx
마찬가지로, 마지막으로 등장하는 Index를 찾기위해서는 st를 계속 앞으로 옮기기 때문에, 코드는 아래와 같이 됩니다.
void upper_idx(int target){
int st=0;
int en = N;
while(st<en){
int mid=(st+en)/2;
if(A[mid]>target)
en =mid;
else st=mid+1;
}
return en;
}하지만, 이 코드를 긴장된 상태에서 코테에서 풀게 된다면 엄청 헷갈리고 실수할 가능성도 매우 높습니다. 제가 말을 하면서 구현을 해도 지금 헷갈리는 포인트가 많아서 거의 외우다 싶이 기계적으로 짭니다.

그래서, STL을 적극적으로 사용하면 됩니다!
lower_bound, upper_bound를 적극적으로 사용하자.
lower_bound는 lower Idx함수와 똑같은 역할을 합니다. 제일 왼쪽에 있는 Idx를 반환합니다.
Upper_bound는 upper Idx 함수와 똑같은 역할을 합니다. 제일 오른쪽에 있는 Idx를 반환합니다.
upper_bound(B,B+N,target) - lower_bound(A,A+N,target) 하면, 해당 원소가 몇개가 있는지 알아낼 수 있게 됩니다.
결론 : upper_bound(A,A+N,target) - lower_bound(A,A+N,target) 하면, 해당 원소가 몇개가 있는지 알아낼 수 있게 됩니다. STL을 적극적으로 씁시다.
좌표압축
종종 좌표를 압축해야할 필요가 있다고 합니다.(아직 한번도 못느껴보긴 했습니다만, 다음과 같은 상황을 상상해봅시다!)
일반적으로, 입력받는 갯수보다 입력범위가 매우매우 클 때 유용하게 쓸 수 있다고 합니다.
예를들어, 입력범위가 int범위이고, 500,000개를 입력받을 때, A[-212355214,-200003,-3,10,20,5] 라는 배열을 입력받았다고 합시다. 입력된 값 2개(x,y) x~y 구간에 있는 점의 갯수를 출력하는 함수를 만들고 싶다고할 때, 진짜 (x,y)의 범위를 모두 탐색하는 것은 굉장히 비효율적일 수 있습니다.
예를들어, -200003 ~ 20사이의 값 중 가진 값이 -3,5,10으로 3개입니다. 그럼 for(x~y)까지으 ㅣ범위를 다 도는 것보단, 정렬을 해서 순서를 이용하면 쉬워집니다. 각각의 순서는 정해져있으므로, 모두를 탐색하는 것보다는 우리는 순서에 관심이 있기 때문에, idxB - idxA -1 로 해주면 됩니다!
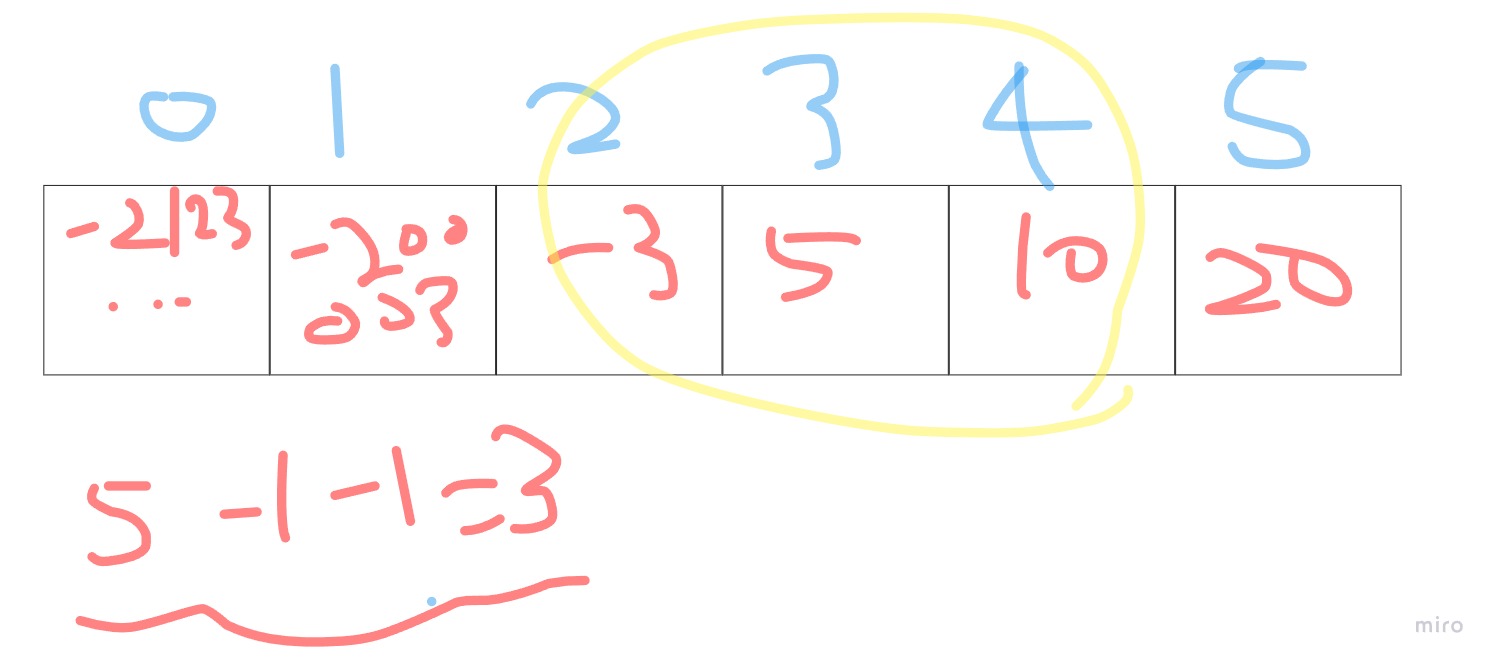
이때, 해당 원소 X,Y를 찾기 위해서 이분탐색을 이용하고, 중복을 제거하는 과정까지 거치면 이제 진정한 좌표압축이 완료됩니다.

주의점) 이분탐색의 무한루프의 가능성
이분 탐색을 구현할 때, 특히 직접 Parametric Search 문제를 구현할 때 , 적절한 mid 값을 선택하는 것이 매우 중요하다. 이때는 , 범위를 어떻게 선택하는지 정했다면 해당 범위를 선택하는 과정에서 탐색범위가 1:1로 균등하게 나누어지는지 확인해야한다. 위의 예시들은 모두 1개를 빼거나 1개를 추가해서 탐색 범위를 보장시켜주었지만 , 직접구현을 하면서 탐색범위를 직접 조절할 때는 mid값을 신중하게 선택 해야한다.
예를들어, boj1654에서 mid값은 (st+en+1)/2를 선택해야합니다. 왜냐하면, st =1 , en =랜선의 최대길이 로 시작하게 될 건데, 예시로 Lan={1,2,3,4}라고 한다면, st =1,en=4가 될 것이고, mid =2가 될 것이다. 이때, 탐색 범위를 생각해주면 랜선의 갯수가 K보다 크다면 오른쪽을 탐색할 것이고, K보다 작다면 왼쪽을 탐색할 건데, "문제에서는 K개 이상인것도 K개라고 친다." 때문에, st=mid과정이 들어가게된다.
따라서, 오른쪽의 탐색범위는 3개이지만, 왼쪽의 탐색범위는 1개로 불균형이 일어나고 이는 곧 무한루프의 가능성을 내포합니다.
