
앞서 소개한 one-hot encoding이나 BoW와 같은 기법들은 단어 간의 의미적 유사성을 표현할 수 없는 한계가 있습니다.
예를 들어 감성 분석 같은 task를 진행하려면 '좋아하다'라는 단어와 '싫어하다'라는 단어를 구분해야하는데, 앞선 방법들로는 그것이 불가능하다는 말이죠.
🤔 Sparse representation
one-hot encoding의 경우 단어를 희소 표현(sparse representation)으로 나타냅니다. 즉, 0과 1로만 구성된 벡터로 구성하는 것입니다.
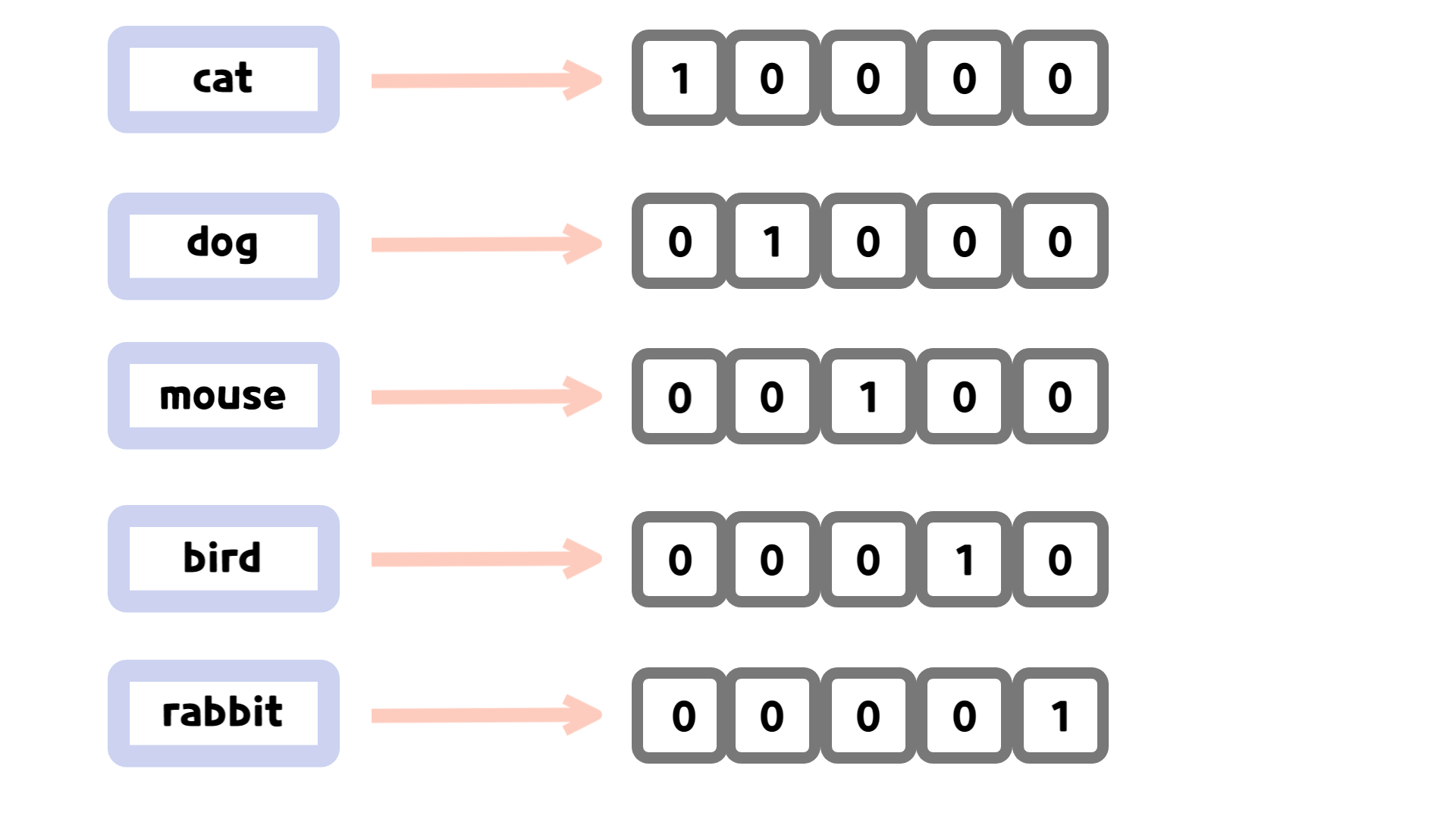
위와 같은 예시에서는 5개의 단어가 제시되어 있으므로 5차원의 벡터로 표현되었습니다. 하지만, 코퍼스의 수가 늘어난다면 벡터의 차원 역시 늘어날 것입니다. 만약 코퍼스가 10000개의 단어를 가지고 있는 경우 각 단어는 10000 차원의 벡터로 표현될 수 있는 것이죠. 이는 공간적인 비효율을 낳습니다.
🤔 Dense representation
밀집 표현(dense representation)은 사용자가 설정한 크기로 차원을 맞추게 됩니다. 이 과정에서 값들은 희소 표현과 달리 실수로 표현됩니다.
💡 Word Embedding
word embedding(단어 임베딩)은 단어를 밀집 벡터의 형태로 표현하는 과정입니다. 밀집 벡터는 상대적으로 저차원에 연속적이므로 단어 간의 코사인 유사도를 사용하기 쉽습니다. 때문에 word embedding의 방법론들은 통해 비슷한 의미를 가진 벡터들은 비슷한 위치에 있도록 학습을 진행합니다.
✔️ 코사인 유사도(cosine similarity)?
값이 1에 가까울수록 서로의 방향이 비슷함.

글쓰는 개발자입니다.