
🤔 품사 태깅이란?
품사 태깅(POS Tagging)은 형태소 분석을 하기 위한 방법으로, 형태소의 품사를 지정해줍니다. 때문에 품사 태깅을 사용하기 위해서는 토큰화가 우선되어야하죠.
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
nltk.download('averaged_perception_tagger') # pos_tag를 사용하기 위해 다운로드가 필요합니다.
txt = "hey, what is going on?"
tokens = word_tokenize(txt) # 토큰화
tags = pos_tag(tokens)
print(tags)
# 결과
# [('hey', 'NN'), (',', ','), ('what', 'WP'), ('is', 'VBZ'), ('going', 'VBG'), ('on', 'IN'), ('?', '.')]위의 코드를 보면 NLTK의 pos_tag 함수는 ('hey', 'NN')과 같이 각 형태소와 품사를 짝지은 튜플들을 리스트로 반환하는 것을 알 수 있습니다. 하지만, NN이 어떤 품사를 뜻하는지 바로 알아채기에는 무리가 있습니다.
때문에 nltk에서는 품사 태깅과 관련한 태그 리스트를 제공합니다.
import nltk
nltk.download('tagsets')
nltk.help.upenn_tagset() 해당 코드를 실행시키면 태그들에 대한 설명을 볼 수 있습니다. 별도로 살펴보자면 다음과 같습니다.
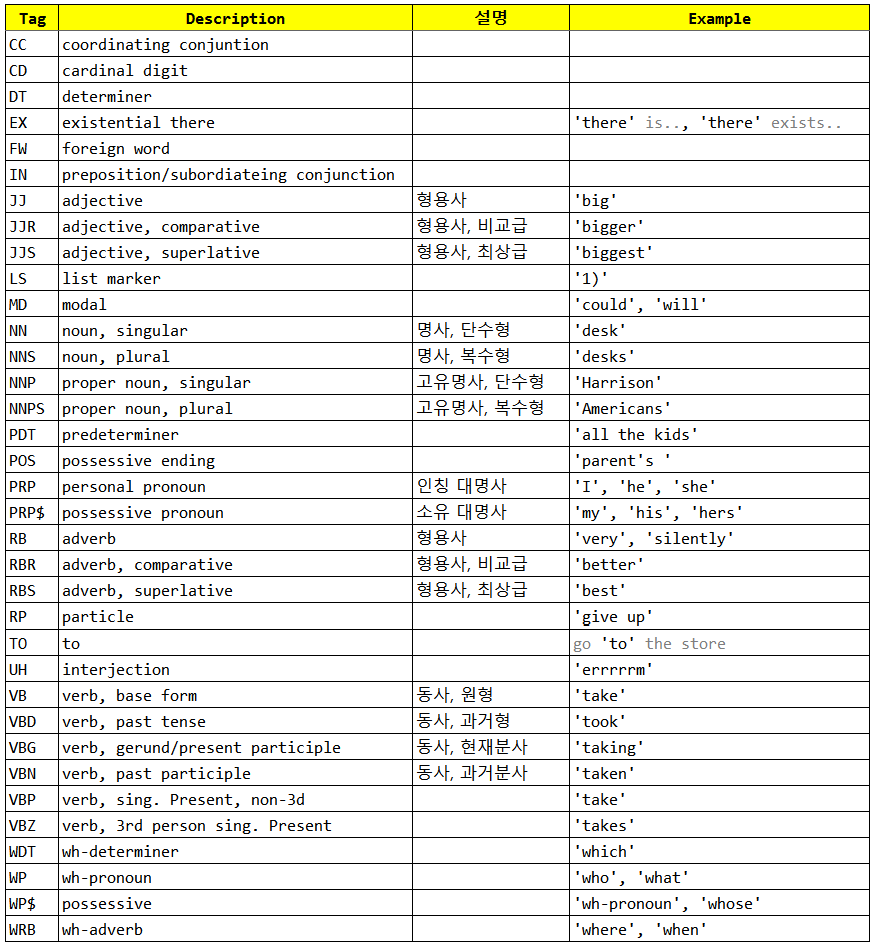
해당 표는 NLTK에서 사용하는 Penn Treebank POS tag입니다. 품사 태깅 또한 토큰화와 같이 형태소를 특정 품사로 정하는 기준이 다양하기 때문에 어느 기준을 사용하냐에 따라 차이가 있습니다.
🔥 품사 태깅의 활용
품사 태깅을 활용한다면 특정 품사에 해당하는 형태소를 추출할 수 있습니다.
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
txt = "It's important to know that words don't move mountains. Work, exacting work moves mountains."
tokens = word_tokenize(txt)
tags = pos_tag(tokens)
result = []
for token, tag in tags:
if tag == 'VB':
result.append((token, tag))
print(result)
# 결과
# [('know', 'VB'), ('move', 'VB')]위의 코드는 문장에서 VB, 즉 동사원형에 해당하는 형태소만 리스트로 반환하는 코드입니다. 이처럼 품사 태깅을 활용하면 원하는 품사에 해당하는 형태소를 가져올 수 있죠.
혹은 다음과 같이 변형도 가능합니다.
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
def check_pos(txt, pos='NN'):
tokens = word_tokenize(txt) # 토큰화 작업
tags = pos_tag(tokens)
count = 0
for token, tag in tags:
if tag == pos:
count += 1
return count
user_input = input("영어 문장을 입력해주세요!")
print(check_pos(user_input, 'VB'))해당 코드는 사용자의 입력을 받아서 해당하는 품사가 몇 개 있는지 반환하는 함수입니다. 이러한 방식처럼 품사 태깅은 다양한 방면으로 활용이 가능합니다.

글쓰는 개발자입니다.
많은 도움이 되었습니다, 감사합니다.