

mongoDB란?
- mongoDB는 관계형 데이터베이스가 아니라 도큐먼트 지향 데이터베이스
- 분산 확장을 쉽게 할 수 있다.
- 내장 도큐먼트와 배열을 허용한다. --> 복잡한 계층 관계를 하나의 레코드로 표현 가능
- 도큐먼트의 키와 값을 미리 정의하지 않는다 --> 고정된 스키마가 없다 --> 필요할 때마다 쉽게 필드를 추가하거나 제거가능
mongoDB의 다양한 기능
인덱싱 :
일반적인 보조 인덱스를 지원
고유(unique), 복합(conpound), 공간 정보, 전문(full-text) 인덱싱 기능 제공
중접된 도큐먼트(nested document) 및 배열과 같은 계층 구조의 보조 인덱스 지원
집계 :
데이터 처리 파이프라인 개념을 기반으로 한 집계 프레임워크를 제공
집계 파이프라인(aggregation pipeline)은 데이터베이스 최적화를 최대한 활용 --> 서버 측에서 비교적 간단한 일련의 단계로 데이터 처리 --> 복잡한 분석 엔진(analytics engine) 구축
특수한 컬렉션 유형
유효 시간(Time-to-Live, TTL) 컬렉션 지원 :
로그와 같은 최신 데이터를 유지하고자 하는 세션이나 고정 크기 컬렉션(제한 컬렉션, capped collection)과 같이 특정 시간에 만료해야 하는 데이터에 대해 사용
부분 인덱스 지원 :
기준 필터(criteria filer)와 일치하는 도큐먼트에 한정된 일부에 적용 가능
파일 스토리지
큰 파일과 파일 메타데이터를 편리하게 저장하는 프로토콜을 지원
mongoDB 기본 개념
도큐먼트
MongoDB의 핵심은 정렬된 키와 연결된 값의 집합으로 이뤄진 도큐먼트다.
맵(Map), 해시(hash), 딕셔너리(dictionary) 등 다양한 자료구조로 표현 가능
좌변은 Key, 우변은 Value
{
"greeting" : "Hello world!",
"views" : 3
}"greeting" 이라는 키에 연결된 문자열 "Hello world!" 이라는 값을 가진다.
"views" 이라는 키에 연결된 정수 3 이라는 값을 가진다.
도큐먼트 키 특징 및 주의사항
- 어떤 UTF-8 문자든 사용 가능
- 키는 중복 불가
- 키는 문자열
- 키는 \0(null 문자)를 포함하지 않음. \n은 키의 끝을 나타내는 데 사용
- '.' 과 '$' 문자는 사용 금지
MongoDB는 데이터형과 대소문자를 구별한다.
다음은 서로 다른 도큐먼트이다
{"count":5}
{"count":"5"}다음도 마찬가지이다.
{"count":5}
{"Count":5}컬렉션
컬렉션은 도큐먼트의 모음. 도큐먼트가 RDB의 튜플에 대응된다면 컬랙션은 테이블에 대응된다고 볼 수 있다.
컬렉션 특징
동적 스키마
컬렉션은 동적 스키마를 가짐.
하나의 컬렉션 내 도큐먼트들이 모두 다른 구조를 가질 수 있음
{"greeting" : "Hello world!","views":3}
{"signoff" : "Good night!","count":6, "visited": 4}같은 컬렉션에 속해도 도큐먼트들의 키, 키의 개수, 데이터형 모두 다를 수 있음.
도큐먼트에 별도의 스키마가 필요 없는데 왜 하나 이상의 컬렉션이 필요할까?
- 같은컬렉션에 다른 종류의 도큐먼트를 저장하면 관리가 번거로움
- 컬렉션별로 목록을 뽑으면 한 컬렉션 내 특정 데이터형별로 쿼리해서 목록을 뽑을 때 보다 훨씬 빠름
- 같은 종류의 데이터를 하나의 컬렉션에 모아두면 데이터 지역성(data locallity)에도 좋음
- 인덱스를 만들면 도큐먼트는 특정 구조를 가져야함
- 같은 유형의 도큐먼트를 하나의 컬렉션에 넣음으로써 컬렉션을 효울적으로 인덱싱 가능
네이밍
컬렉션은 이름으로 식별.
어떤 UTF-8문자열이든 쓸 수 있음.
네이밍 시 주의사항
- 빈 문자열("")은 유효한 컬렉션명이 아니다.
- \n(null 문자)는 컬렉션명의 끝은 나타내는 문자. 사용 불가
- system. 으로 시작하는 컬렉션명 사용 불가. 시스템 컬렉션에서 사용하는 예약어이기 때문
- '$' 포함 불가.
서브컬렉션(subcollection)
서브컬렉션의 네임스페이스(namespace)에 '.' 문자를 사용해 컬렉션을 체계화 가능.
ex) blog.posts , blog.authors, blog.user
이는 단지 체계화를 위함이며 blog 컬렉션이나 자식 컬렉션(child collection)과는 아무런 관계가 없음. (심지어 blog 컬렉션이 없어도 됨)
여러 툴에서 유용. GridFS는 메타데이터를 저장하는 데 서브컬렉션 사용, 대부분의 드라이버는 특정 컬렉션의 서브컬렉션에 접근하는 몇 가지 편리한 문법을 제공
서브컬렉션은 MongoDB의 데이터를 체계화하는 훌륭한 방법.
데이터베이스
RDB로 따지면 SCHEMA.
MongoDB는컬렉션에 도큐먼트를 그룹화할 뿐 아니라 데이터베이스에 컬렉션을 그룹지어놓음.
단일 인스턴스는 여러 데이터베이스 호스팅 가능, 각 데이터베이스를 완전히 독립적으로 취급할 수 있음.
데이터베이스 네이밍 특징 및 주의사항
- 어떤 UTF-8 문자열이든 사용 가능
- 빈 문자열("") 앙대
- / \ . '' * < > : | ? $ \0 앙대
- 대소문자 구별
- 최대 64바이트
- 이미 예약된 데이터베이스명(admin, local, config 등) 앙대
admin 데이터베이스는 인증과 인가역할을 함
local 데이터베이스는 단일 서버에 대한 데이터를 저장, 복제 셋에서 복제 프로세스에 사용된 데이터를 저장.
config 데이터베이스는 샤딩된 몽고 클러스터를 이용해 각 샤드의 정보를 저장
몽고DB 셸
MongoDB는 명령행에서 MongoDB인스턴스와 상호작용하는 JS셸을 제공
셸은 관리 기능이나 실행 중인 인스턴스를 점검하는 등 간단한 기능을 시험하는 데 매우 유용.
shell 실행
mongojs 프로그램 실행 가능
x = 200;
x / 5;
Math.sin(Math.PI / 2)
new Date("2022/1/13");
"Hello World!".replace("World", "MongoDB");
function factorial(n) {
if(n<=1) return 1;
return n * factorial(n-1);
}
factorial(5)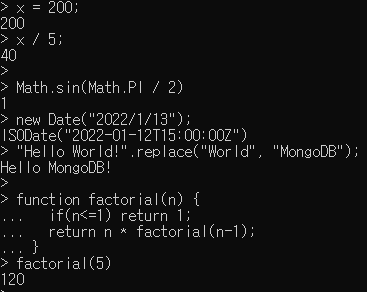
할당된 데이터베이스 확인
db데이터베이스 선택
use video //데이터베이스명기존에 있던 DB면 매핑, 아니면 새로 생성
컬렉션 접근
db.movies // 컬렉션명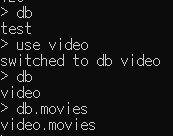
데이터 CRUD
Create
movie = {"title": "극한직업","director":"이병헌", "year":2019}
db.movies.insertOne(movie)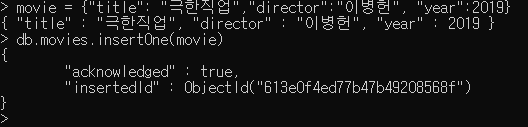
"_id" 키가 추가됐고, 다른 키/값 쌍들은 입력한 대로 저장됨.
Read
find와 findOne을 사용. 컬렉션에서 단일 도큐먼트를 읽으려면 findOne 사용.
db.movies.find()
pretty()를 붙이면 예뻐짐
db.movies.find().pretty()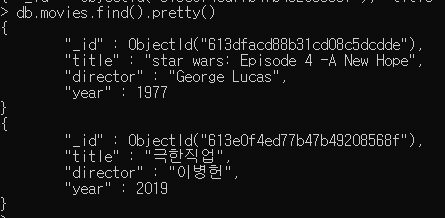
Update
updateOne사용.
매개변수는 최소 두 개임.
첫 번째는 수정할 도큐먼트를 찾는 기준, 두 번째는 갱신 작업을 설명하는 도큐먼트.
갱신 연산자 set을 이용
db.movies.updateOne({title : "극한직업"}, {$set : {reviews: []}})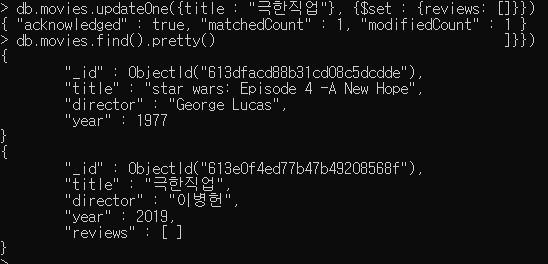
Delete
db.movies.deleteOne({title : "극한직업"})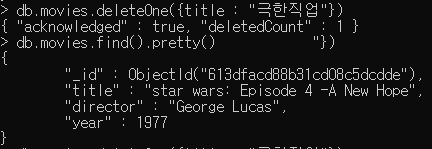
필터와 일치하는 모든 도큐먼트를 삭제하려명 deleteMany 사용
참조
몽고DB 완벽 가이드 3판 (한빛미디어) -
크리스티나 초도로, 새넌 브래드쇼, 오언 브라질 지음
