퀵 정렬(Quick Sort)
- 평균적으로 가장 빠른 정렬 방법
- 리스트를 기준값을 기준으로 2개의 부분리스트로 비균등 분할하고, 각각의 부분리스트를 다시 퀵정렬
- 퀵 정렬 분할/정복
- 분할(divide)
- 정렬할 자료들을 기준값을 중심으로 2개의 부분 집합으로 분할하기
- 기준 값(Pivot: 피벗) : 전체 원소 중 처음 또는 가운데에 위치한 원소
- 정복(conquer)
- 기준값보다 작은 원소들은 왼쪽으로, 기준값보다 큰 원소들은 오른쪽으로 이동
- 부분 집합의 크기가 1 이하로 충분히 작지 않으면 순환호출(recursion)을 이용하여 다시 분할
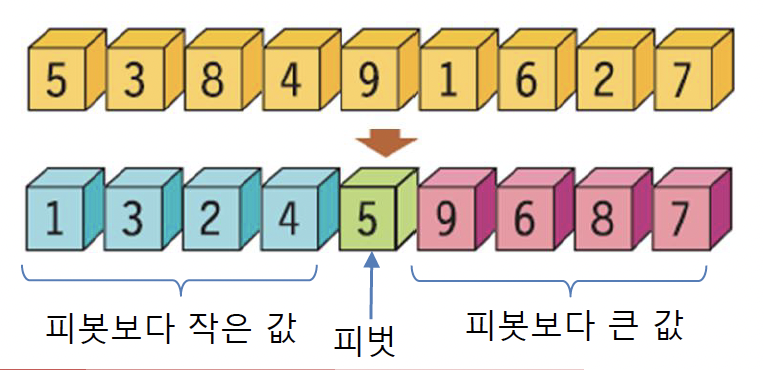
- 분할(divide)
- 퀵 정렬 알고리즘
- 정렬할 데이터가 2개 이상이면
- partition 함수 호출로 피벗을 기준으로 2개의 리스트로 분할
partition 함수의 반환값이 피벗의 위치 - left에서 피벗 바로 앞까지를 대상으로 순환호출(피벗 제외)
- 피벗 바로 다음부터 right까지를 대상으로 순환호출(피벗 제외)
void quick_sort(int list[], int left, int right) { if(left<right){ int q=partition(list, left, right); quick_sort(list, left, q-1); quick_sort(list, q+1, right); } }
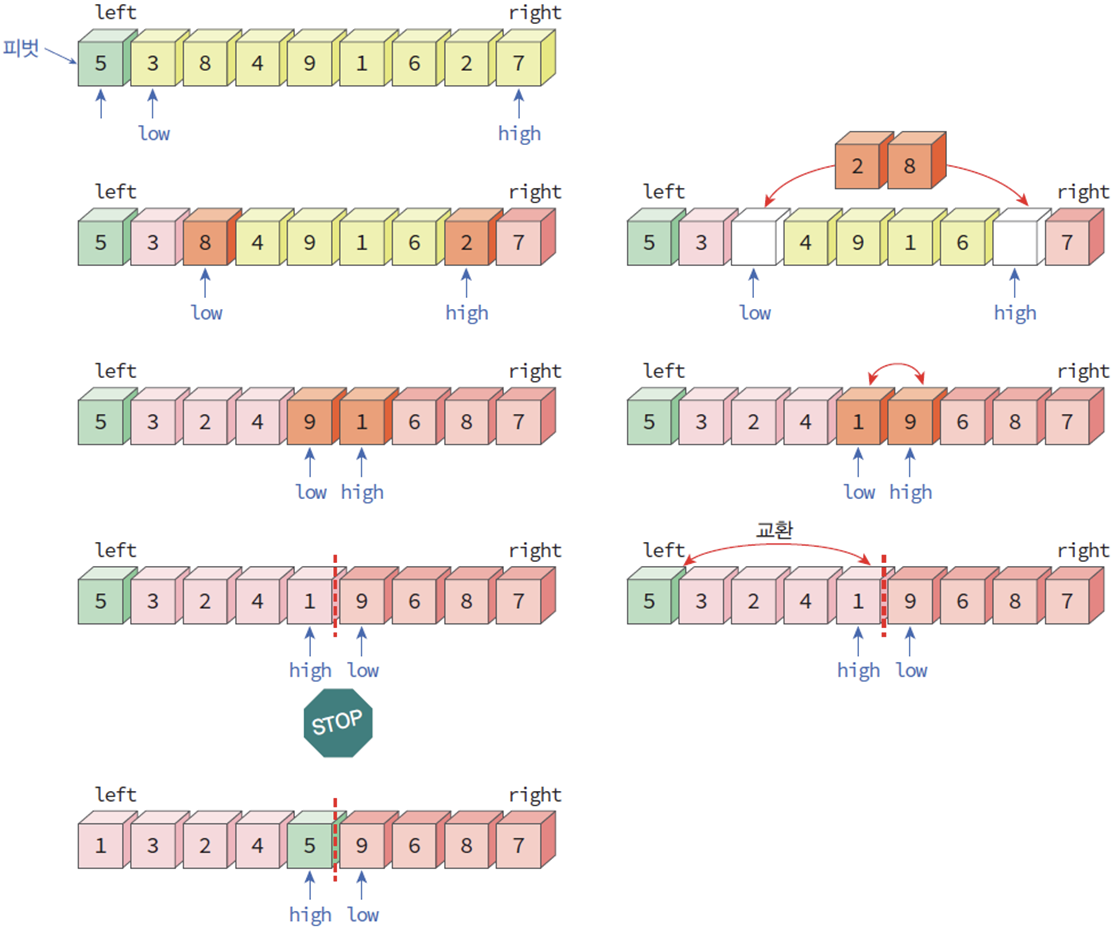
- 분할(partition) 알고리즘
0) 피벗(pivot): 가장 왼쪽 숫자라고 가정
0) 두 개의 변수 low와 high를 사용한다.
low는 피벗보다 큰 숫자를, high는 피벗보다 작은 숫자를 체크하여 이들을 서로 교환하기 위한 첨자
1) 초기화
low는 리스트의 가장 왼쪽 인덱스, high는 리스트의 가장 오른쪽 인덱스
2) low는 피벗보다 작으면 통과(증가), 크면 정지
3) high는 피벗보다 크면 통과(감소), 작으면 정지
4) 정지된 위치의 숫자를 교환
5) 2)부터 반복
6) low와 high가 교차하면 종료
7) 피벗과 high의 원소를 교환
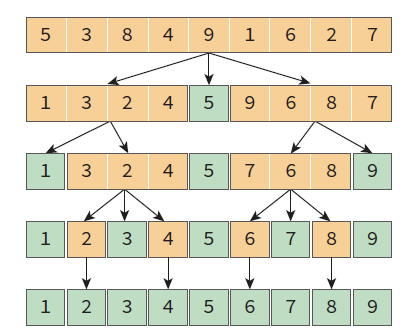
- 퀵 정렬 전체 과정
- 퀵 정렬 복잡도 분석
- 최선의 경우(정확히 좌우 균등한 리스트로 분할)
- 패스 수: log(n)
2 -> 1
4 -> 2
8 -> 3
…
n -> log(n) - 각 패스 안에서의 비교횟수: n
- 총 비교횟수: n*log(n)
- 총 이동횟수: 비교횟수에 비하여 적으므로 무시 가능
- 패스 수: log(n)
- 최악의 경우(극도로 불균등한 리스트로 분할되는 경우)
- 패스 수: n
- 각 패스 안에서의 비교횟수: n
- 총 비교횟수: n2
- 총 이동횟수: 무시 가능
(예) 이미 정렬된 리스트를 정렬할 경우 - 중간값(medium)을 피벗으로 선택하면 불균등 분할 완화 가능
- 최선의 경우(정확히 좌우 균등한 리스트로 분할)
기수 정렬(Radix Sort)
- 대부분의 정렬 방법들은 레코드들을 비교함으로써 정렬 수행
- 기수 정렬(radix sort)은 레코드를 비교하지 않고 정렬 수행
- 비교에 의한 정렬의 하한인 O(n*log(n)) 보다 좋을 수 있음
- 기수 정렬은 O(dn) 의 시간적 복잡도를 가짐(대부분 d<10 이하)
- 여기에서 d는 자리수를 의미
- 기수 정렬의 단점
- 정렬할 수 있는 레코드의 타입 한정(실수, 한글, 한자 등은 정렬 불가)
- 레코드의 키들이 동일한 길이를 가지는 숫자나 단순 문자(알파벳 등) 이어야만 함
- 원소의 키값을 일부분을 나타내는 기수를 이용한 정렬 방법
- 정렬할 원소의 키 값에 해당하는 버킷(bucket)에 원소를 분배하였다가 버킷의 순서대로 원소를 꺼내는 방법을 반복하면서 정렬
- 원소의 키를 표현하는 기수만큼의 버킷 사용
- 예) 10진수로 표현된 키 값을 가진 원소들을 정렬할 때에는 0부터 9까지 10개의 버킷 사용
- 키 값의 자리수 만큼 기수 정렬을 반복
- 키 값의 일의 자리에 대해서 기수 정렬을 수행하고,
- 다음 단계에서는 키 값의 십의 자리에 대해서,
- 그리고 그 다음 단계에서는 백의 자리에 대해서 기수 정렬 수행
- 한 단계가 끝날 때마다 버킷에 분배된 원소들을 버킷의 순서대로 꺼내서 다음 단계의 기수 정렬을 수행해야 하므로 큐를 사용하여 버킷을 만든다
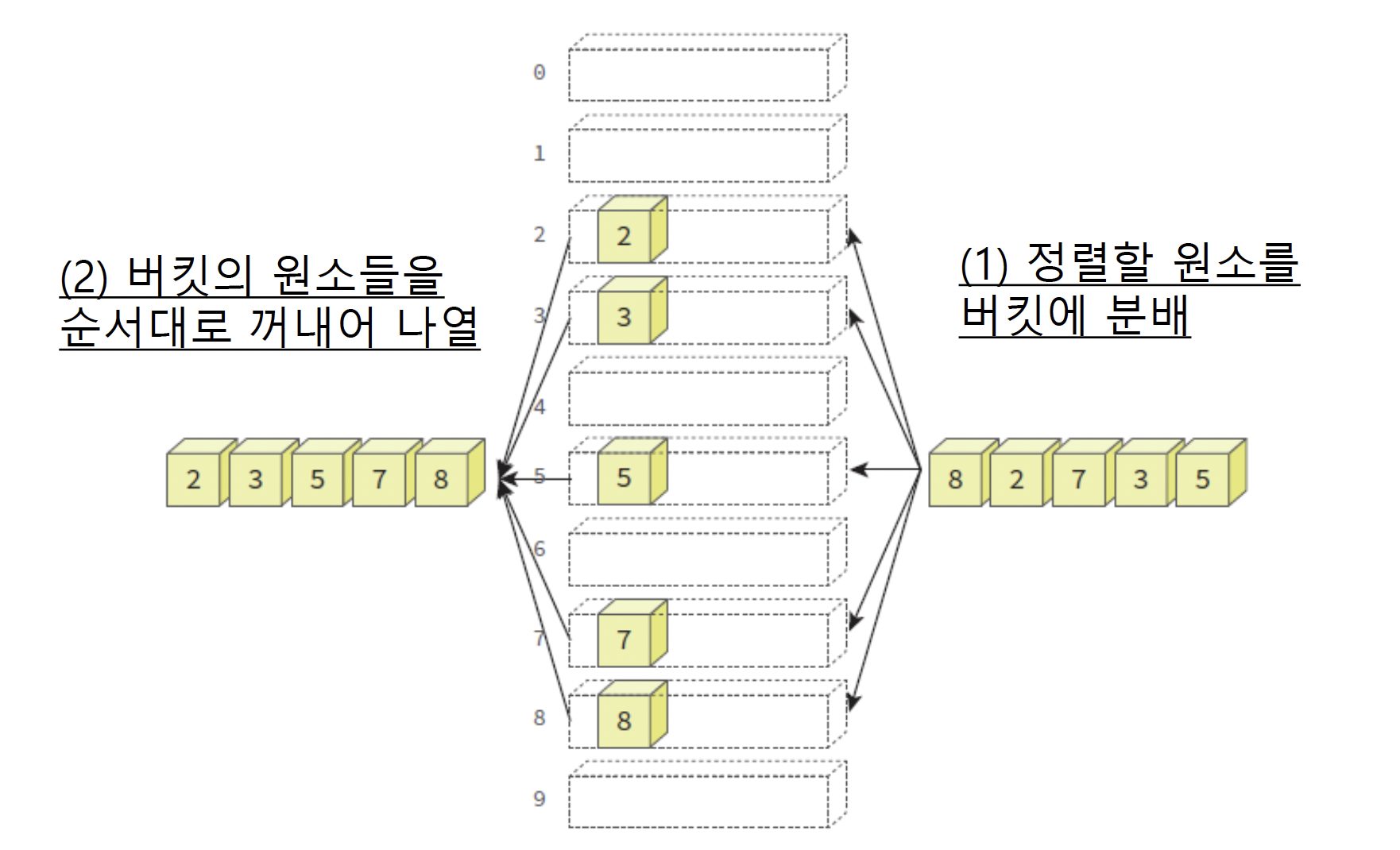

- 버켓은 큐로 구현
- 버켓의 개수는 키의 표현 방법과 밀접한 관계
- 이진법을 사용한다면 버켓은 2개
- 알파벳 문자를 사용한다면 버켓은 28개
- 십진법을 사용한다면 버켓은 10개
- 기수 정렬 소스코드
// 큐 단원에서 다른 큐 관련 소스코드 복사 필요.
#define BUCKETS 10 // 십진수 정렬
#define DIGITS 4 // 4자리숫자 정렬
void radix_sort(int list[], int n) {
int i, b, d, factor=1;
QueueType queues[BUCKETS];
for(b=0 ; b<BUCKETS ; b++) // 버켓들의 초기화
init(&queues[b]);
for(d=0 ; d<DIGITS ; d++){ // 자리수 만큼 반복 수행
for(i=0 ; i<n ; i++) // 데이터들을 자리 수에 따라 큐에 입력
enqueue( &queues[(list[i]/factor)%10], list[i]);
for(b=i=0 ; b<BUCKETS ; b++) // 버켓에서 꺼내어 list로 합친다.
while( !is_empty(&queues[b]) )
list[i++] = dequeue(&queues[b]);
factor *= 10; // 그 다음 자리수로 간다.
}
}- 기수정렬 복잡도 분석
- n개의 레코드, d개의 자릿수로 이루어진 키를 기수정렬 할 경우
- 메인 루프는 자릿수 d번 반복
- 큐에 n개 레코드 입력 수행
- O(dn) 의 시간적 복잡도
- 키의 자릿수 d는 10 이하의 작은 수이므로 빠른 정렬임
- n개의 레코드, d개의 자릿수로 이루어진 키를 기수정렬 할 경우
힙 정렬(Heap Sort)
- 히프 트리를 이용한 정렬방법
- 힙 정렬 알고리즘
- 주어진 원소를 최소 히프 트리에 삽입한 후, 삭제하면 됨
- 히프정렬 알고리즘의 복잡도
- O(n*log n)
트리 정렬(Tree Sort)
- 이진 탐색 트리를 이용한 정렬 방법
- 트리 정렬 알고리즘
- 주어진 원소를 이진 탐색 트리에 삽입한 후, 중위순회
- 트리 정렬 알고리즘의 복잡도
- O(n*log n)
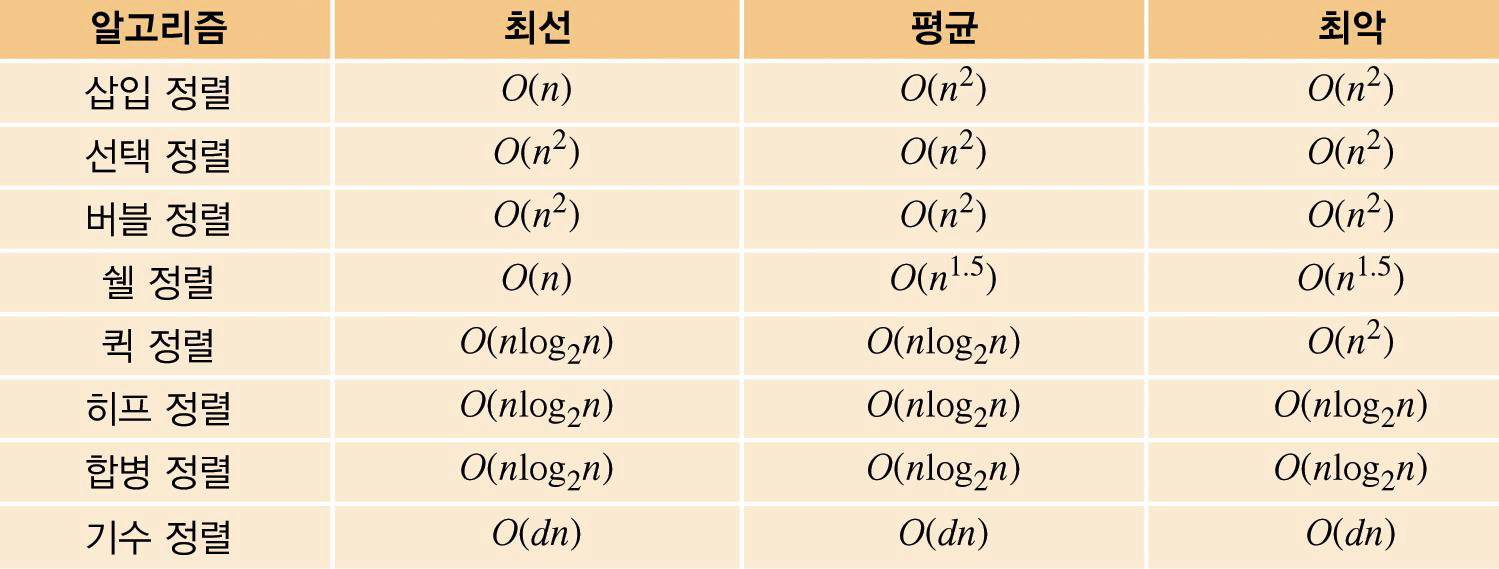
정렬 알고리즘의 비교

개발새발 밸로그˙ᵕ˙
많은 도움이 되었습니다, 감사합니다.