Label Propagation digits active learning
우리는 mnist 의 digits data set을 이용하여 손글씨를 예측하는 active learning을 이용할 것이다.
ACTIVE LEARNING
전통적으로 passive한 maching learning은 라벨링되지 않은 데이터에 대해 사람이 라벨을 부여하면 사람이 직접 라벨링하여 기계가 학습하는 방식을 의미한다. 즉, supervised learning이다.
하지만 active leanring이란 기계가 스스로 unsupervised learning을 통해 active하게 스스로 학습ㅇ르 하는 것이다.
step of active learning
- data collection
- data 분할
- model learning
- choice of unlabel data
- stop condition making
여기서 중요한 점은 언제나 과도하게 학습하게 되면 정확도가 떨어진다는 사실이다.
우리는 먼저 10개의 라벨 (1~10)까지 설정하고 5개의 후보를 설정할 것이다.
이후 15개의 라벨으로 학습을 진행한다.
이렇게 과정을 4번 반복하게 되면 30개의 라벨링이 된 데이터에 학습시킬 수 있다.
하지만 이는 max_iterations 의 함수를 조정하여 파라미터를 조절할 수 있다.
라벨링이 30번 이상 진행되는 것은 active learning 기술에서 수렴을 하는 데 가장 중요한 요소이다.
다음의 그림은 모호한 5개의 텍스트 중에서 가장 높은 확률로 학습을 통해 인지된 5개의 셋을 보여준다. 이 결과는 실수를 포함할 수 있지만 다음에는 이러한 이슈를 없엔다.
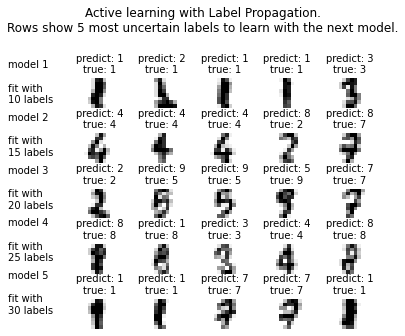
Demonstrating performance
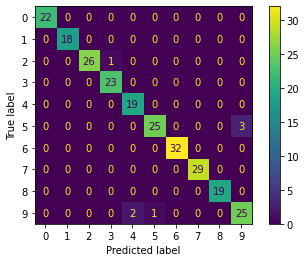
다음으로 확인할 수 있는 부분은 비지도 학습으로 학습된 데이터를 얼마나 잘 학습하였는지 확인할 수 있는 confusion matrix이다.
손글씨 데이터 셋은 총 1797개의 데이터가 있다. 모든 데이터를 학습하지만 오직 30개만 라벨을 진행하게 된다. 결과적으로 confusion matrix와 series matrix는 매우 좋은 성능을 보일 것이다. 결국 우리가 보는 것은 가장 모호한 예측인 10개가 보이게 되는 것이다.
일단 가장먼저 340개의 샘플에서 40개만 라벨에 관련이 되어있다.따라서 우리는 300개의 다른 샘플을 indices에 저장되어 라벨에 영향을 미치지 않는다.
semi- supervised learning
LabelSpreading을 진행하게 되면 모르는 라벨에 대하여 예측을 할 수 있는 라이브러리이다.
결국 다음의 코드를 진행시키면 40개의 라벨링된 데이터와 그렇지 않은 300개의 데이터를 얻는 것이다. -> 즉 학습데이터와 그냥 데이터를 구분하는 것이다.
Confusion matrix
이제 confusion matrix을 확인해보면 diagonal 한 부분에서만 큰 값이 나온 것을 알 수 있고 이는 우리의 예측과 동일하다.
Plot the most uncertain predictions
자 이제 10개의 가장 모호한 예측을 골랐다면 이를 플롯하여 실제로 맞는 지 확인하는 것이다.