자료구조
1.배열, 벡터, 연결리스트
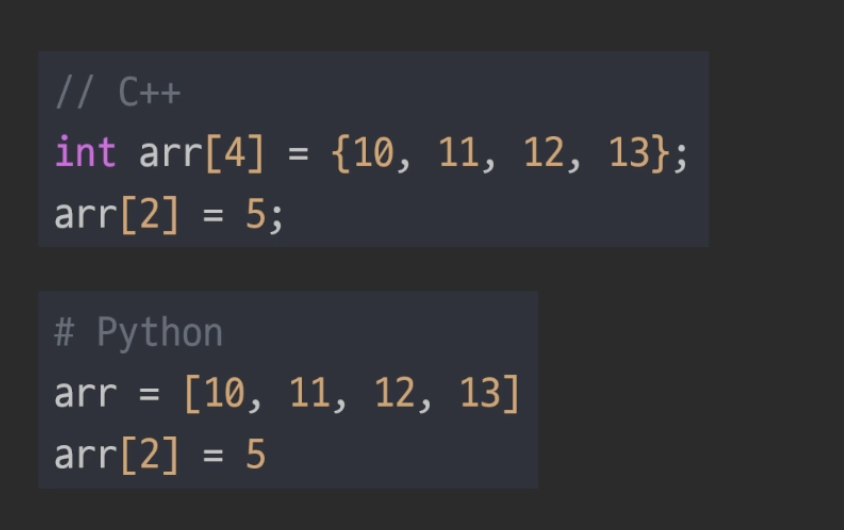
삽입 / 삭제 : O(N)탐색 : O(1)C++에서는 size 변경 불가python은 리스트를 사용
2.stack, Queue

stack
3.우선순위 큐 Priority Queue (Heap)
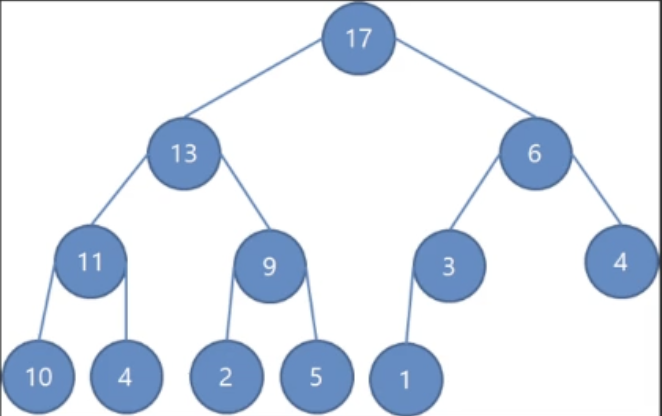
삽입 / 삭제 : O(log N)
4.맵 MAP (Dictionary), 집합(set)

Key, Value (JSON) key 중복 x, value 중복 o 삽입 / 삭제 c++ : O(log N)python : O(1)
5.완전탐색
장점 : 반드시 답을 찾을수 있다.단점 : 오래 걸린다. (리소스를 많이 잡아 먹는다.)trade-off 관계: 컴퓨팅 자원 <-> 시간
6.탐욕법

매 순간마다 최선의 경우만 골라간다다른 경우는 고려하지 않는다. 나중은 생각하지 않는다.
7.그래프
지도 , 내비게이션Sns / 메신저 VCS (Version control system) 버전 관리 시스템 역은 보통 Vertex(node) 라고 하고 연결은 edge라고 한다.(ex v개, e개)
8.트리(tree)
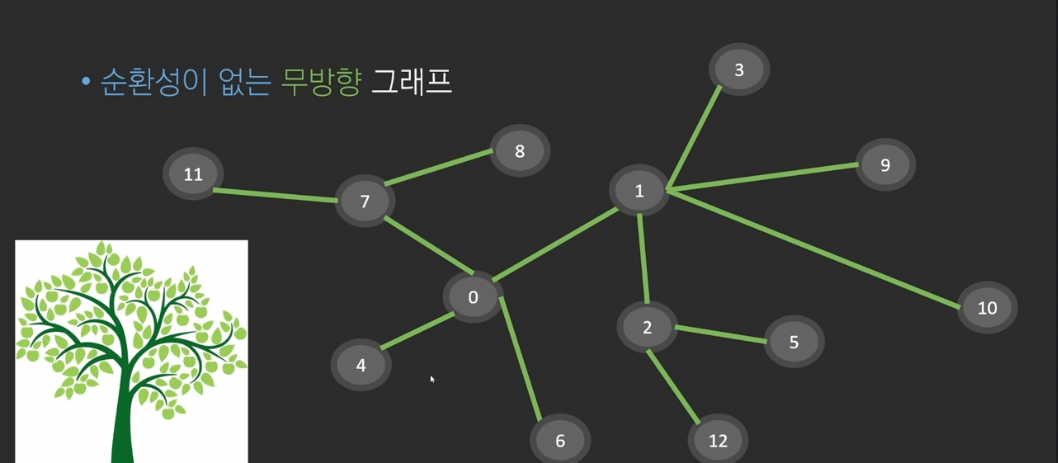
트리 tree
9.코드로 그래프를 나타내는 방법
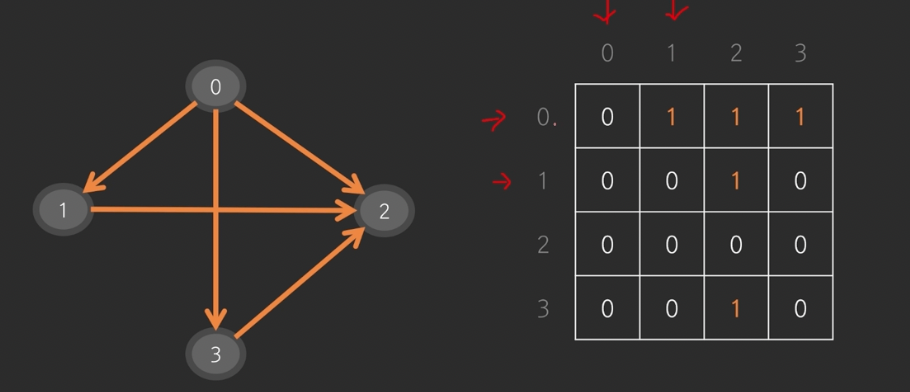
행은 시작 인덱스, 열은 도착 인덱스 간선이 있는 부분은 1로 표기
10.DFS
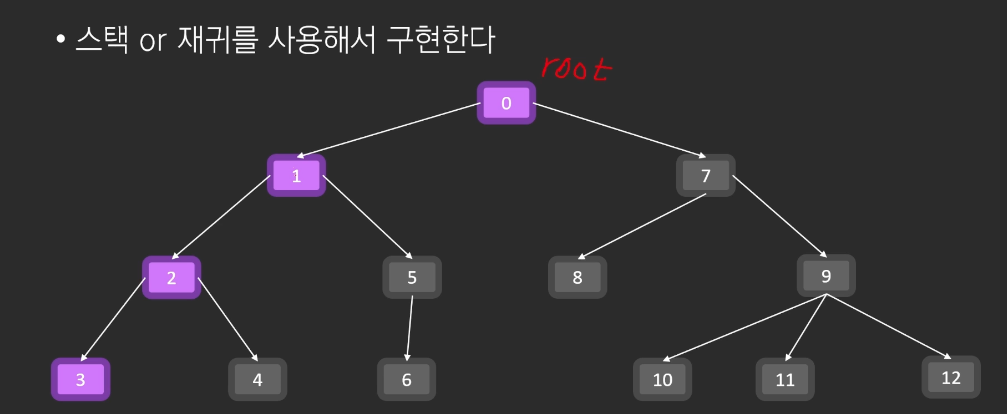
DFS는 깊이 우선 검색을 나타냅니다. 트리 또는 그래프 데이터 구조를 순회하거나 검색하는 데 사용되는 알고리즘입니다. 알고리즘은 루트라고 하는 특정 노드에서 시작하여 역추적하기 전에 각 분기를 따라 가능한 멀리 탐색합니다.DFS는 재귀 또는 명시적 스택을 사용하여 구
11.BFS
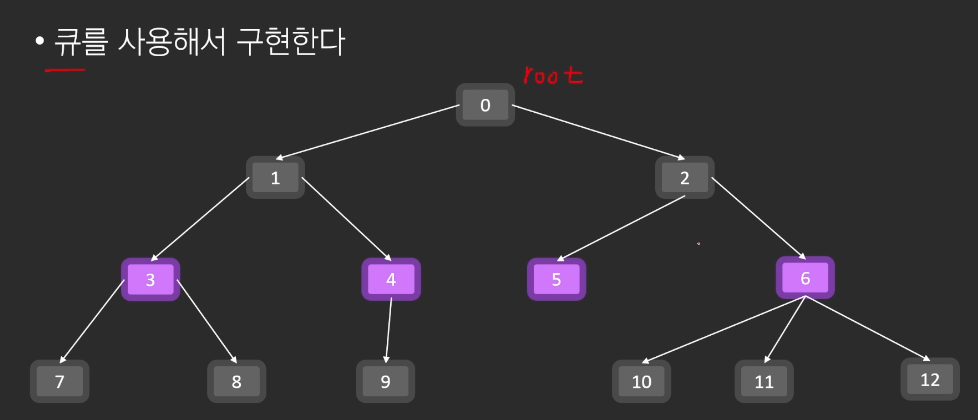
BFS 는 DFS 똑같이 완전탐색 알고리즘의 한 종류인데 다른접이 있습니다. BFS 같은 경우 너비우선탐색이라고 큐를 사용해서 탐색한다.ex) DFS (Parent Node기준 무조건 작은 Child Node가 먼저)0 > 1 > 3 > 73 > 81 > 4 > 90
12.DFS VS BFS

공통점: 그래프 탐색 알고리즘, 모든 경우의 수를 살펴봄 (완전탐색), 모든 경우의 수를 다 찾을수 있지만 단점은 느리다. 차이점: 탐색 순서가 다르다.
13.길찾기 문제
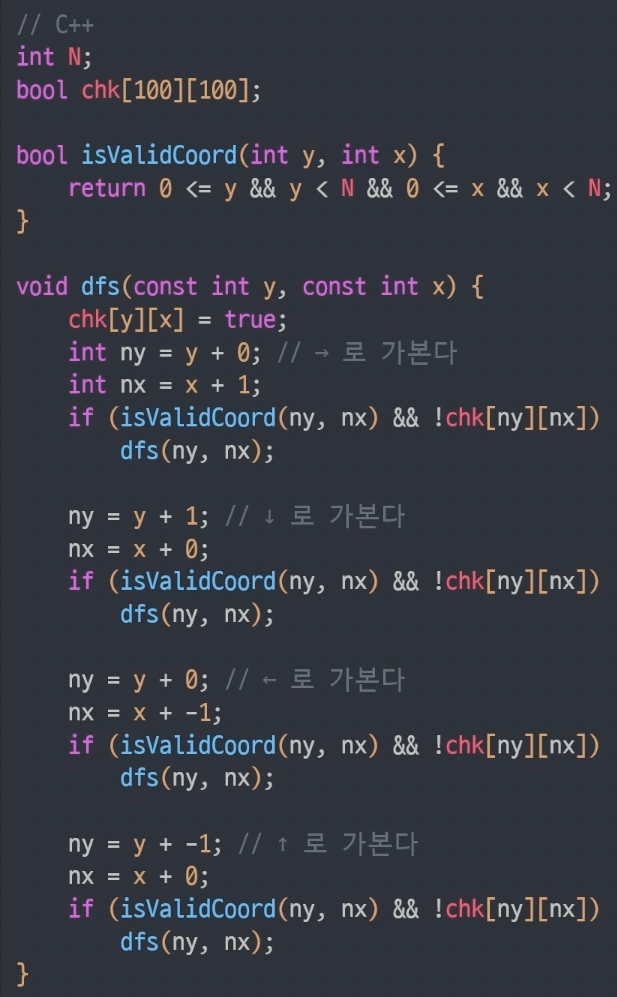
길찾기 문제 c++ 예제 (dfs) 길찾기 탐색문제는 항상 방문체크를 해줘야 한다. python 예제(bfs) 방문체크 필요 각 칸이 노드 상하좌
14.백트래킹

백트래킹 (퇴각검색)
15.DFS, BFS, 백트래킹 - 정리

그래프는 node와 edge로 이루어져 있다.방향성과 순환성이 각각 있거나 없거나 수많은 그래프 / 트리 종류와 알고리즘들이 존재한다.인접행렬edge 가 많은 그래프일 때 쓰는데 좋다edge 탐색이 빠르다.인접리스트edge 가 적은 그래프일 때 쓰는게 좋다.메모리 적게
16. 이진탐색

Í
17.이진탐색 - 라이브러리
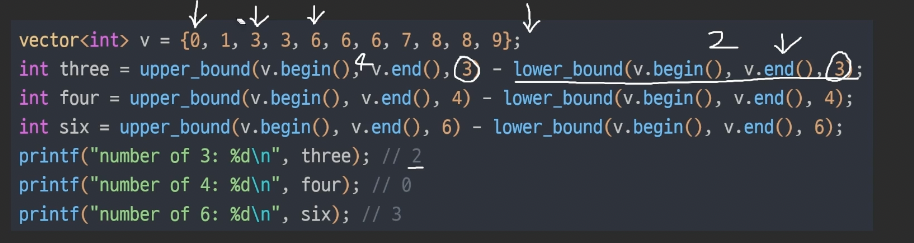
v.begin 0이고 v.end는 존재하지 않는 위치three upper_bound > index 4three lower_bound > index 24 - 2 = 2 (3은 2개)four upper_bound > index 4four lower_bound > index
18.이진탐색 - 파라메트릭 서치

최적화 문제를 결정 문제로 바꿔서 이진탐색으로 푸는 방법이다.
19.동적 계획법
문제를 쪼개서 작은 문제의 답을 구하고, 그걸로 더 큰 문제의 답을 구하는 걸 반복분할정복과 비슷한 느낌
20.동적계획법 - 메모이제이션, 타뷸레이션

한 번 구한 답들은 저장함 - Memoization부분 문제들의 답을 한 번 구했으면 또 구하지 않도록 (중복연산 방지) cache에 저장해두고 다음부터 갖다 쓰자메모라이제이션이 아니고 메모이제이션임
21.동적계획법 - 피보나치 수열
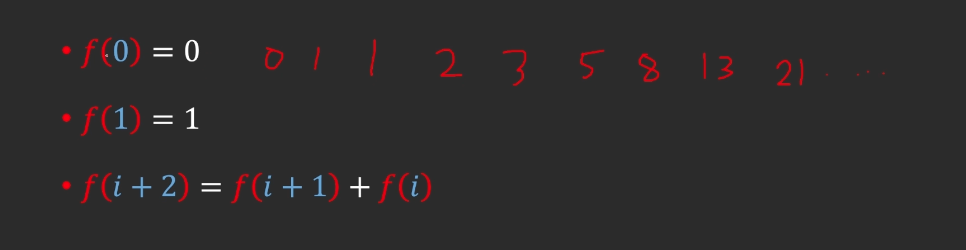
22.동적계획법 - 이항계수
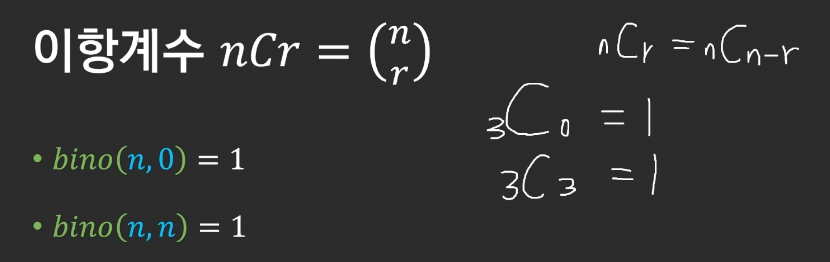
https://www.acmicpc.net/problem/11051