
Overview
진행하고 있는 프로젝트 중 상품의 상세페이지 조회 시 조회수가 1 증가하는 로직이 있습니다. 매번 각각의 요청이 들어오게 되면 조회수가 정상적으로 증가하겠지만, 동시에 100개의 요청이 들어온다면 어떻게 될까요?
1-1. 테스트 코드
@DisplayName("상품의 상세 페이지를 여러명이 동시에 조회한다")
@Test
void itemDetails_V2() throws InterruptedException {
// given
Member member =
supportRepository.save(new Member("jenny","password", "profile"));
Principal principal = setPrincipal(member);
Category category = setCategory();
Item item1 = setItem(member, category, "1번 상품", "내용", ItemStatus.ON_SALE);
int threadCount = 8;
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
CountDownLatch countDownLatch = new CountDownLatch(100);
// when
for (int i = 0; i < 100; i++) {
executorService.execute(() -> {
try {
itemService.itemDetails(principal, item1.getId());
} finally {
countDownLatch.countDown();
}
});
}
countDownLatch.await();
// then
Thread.sleep(1000 * 90);
Item findItem = supportRepository.findById(item1.getId()), Item.class);
assertThat(findItem.getViewCount()).isEqualTo(100);
}결과 : 문제점 발생
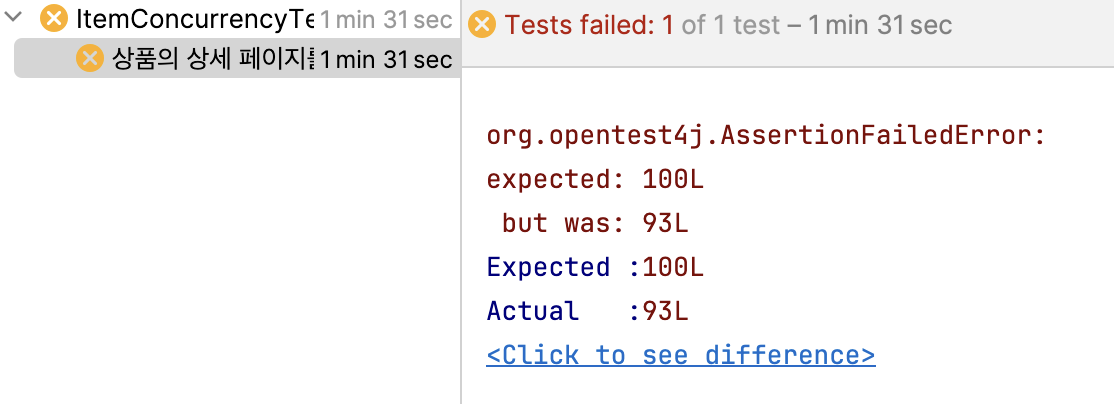
기대했던 조회수가 100이 아닌 93으로 나왔습니다. 왜 이런 상황이 발생할까요?
원인
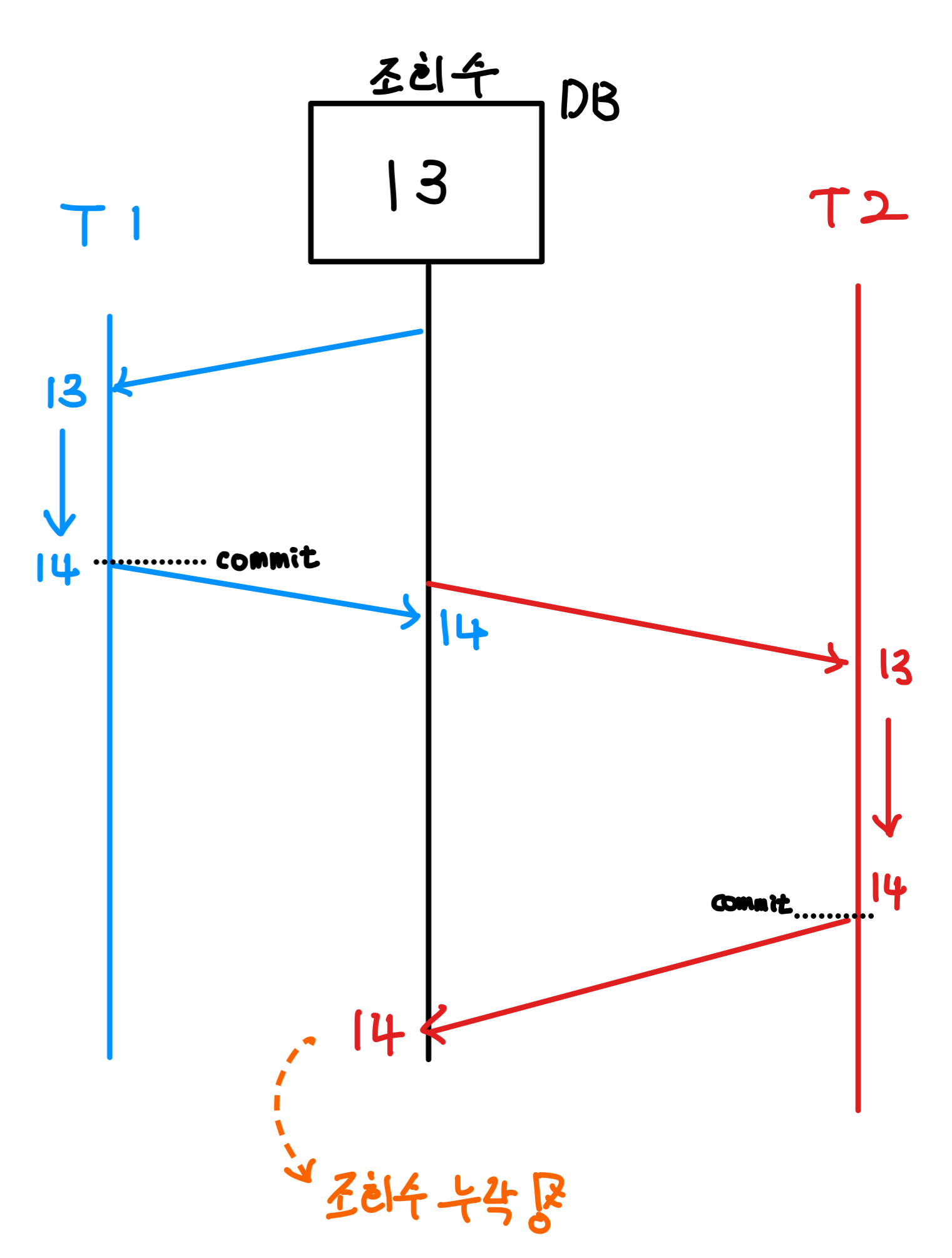
먼저 T1의 트랜잭션이 조회수가 13인 데이터를 가져와 증가시키고 커밋시키기 직전 T2 트랜잭션이 아직 업데이트 되기 전인 조회수를 읽어와 조회수를 증가시키며 조회수에 대한 누락이 발생하여 기대한 조회수 100이 아닌 93이 나오게 되었습니다.
이제 문제를 해결할 방법을 찾아보겠습니다.
해결1. syncronized 사용하기
첫 번째로 생각한 방법은 syncronized 키워드를 이용해 동시성을 제어 방법입니다.
💡 syncronized
syncronized는 멀티 스레드 환경에서 여러 스레드가 하나의 공유 자원에 동시에 접근하지 못하도록 막아주는 키워드.
조회수 증가로직
조회수를 증가 시키는 로직에 syncronized 키워드를 사용하여 작성해보았습니다.
@Transactional
public syncronized ItemDetailResponse ItemDetails(Long itemId) {
itemViewCountService.addViewCount(itemId);
...
}이후 동일한 테스트를 돌렸을 때 각각의 스레드가 이전 스레드의 작업이 완료될 때까지 대기하기 때문에 성공할 것이라 예상했지만? 실패했습니다. 이유는 왜일까요?
바로 스프링이 @Transactional을 처리하는 방식 때문 입니다.
스프링은 @Transactional 어노테이션을 AOP 방식으로 처리함으로써 @Transactional 어노테이션이 선언되어있는 클래스는 proxy 클래스를 만들고 기존 클래스(@Transactional 어노테이션이 선언되어 있는 클래스)를 상속 받아 트랜잭션을 처리하게 됩니다.
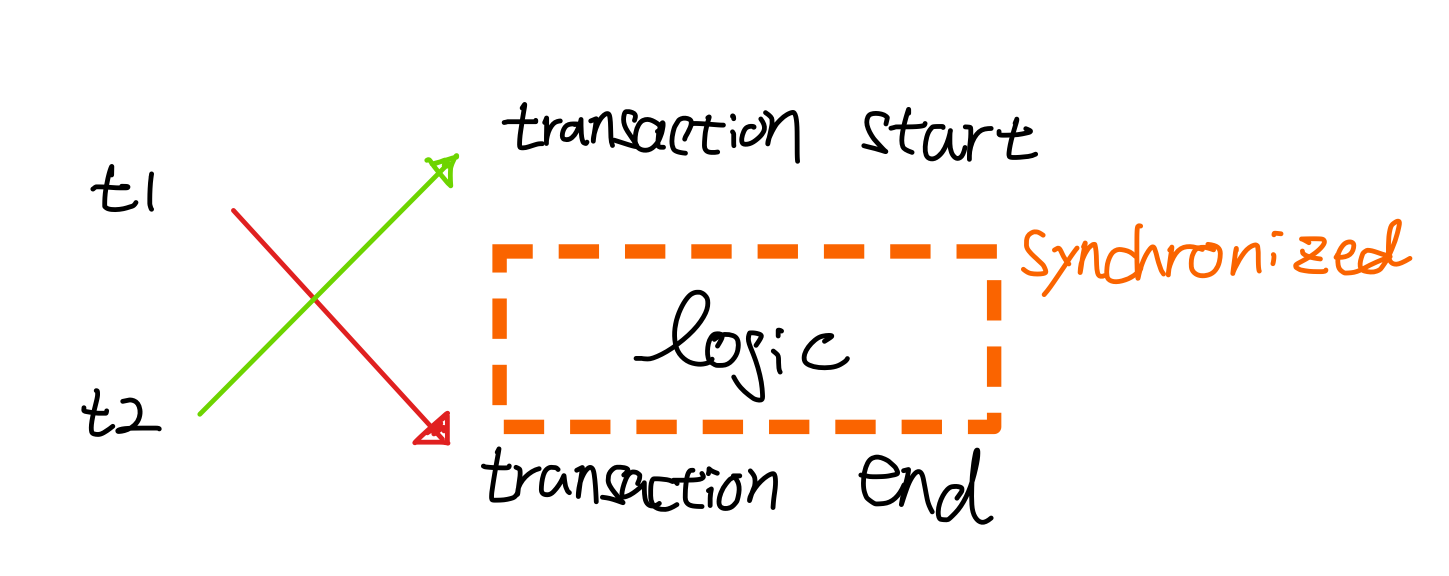
그림으로 살펴보면 t1 스레드가 조회수를 증가시키는 로직을 완료한 후 트랜잭션을 종료시키려는 시점에 t2 스레드가 접근해버려 문제가 발생했던 것입니다.
이상한 일이죠? 분명 이런 문제를 해결하기 위해 여러 개의 스레드가 하나의 공유 자원에 동시에 접근하지 못하도록 syncronized를 붙여놨는데도 왜 t2 스레드는 접근이 가능했을까요?
바로 syncronized가 실행되기 전에 트랜잭션이 먼저 실행되었기 때문입니다.
즉, syncronized는 트랜잭션보다 앞서 시작되어야 공유 자원에 동시에 접근하지 못하는 상황을 만들 수 있을 것 같습니다.
@RequiredArgsConstructor
@Component
public class SyncronizedService {
private final ItemService itemService;
public syncronized void increaseViewCount(Long itemId) {
itemService.itemDetails(itemId);
}
}@Transactional
public syncronized ItemDetailResponse itemDetails(Long itemId) {
itemViewCountService.addViewCount(itemId);
...
}그림으로 본다면 아래와 같은 형태가 됩니다.
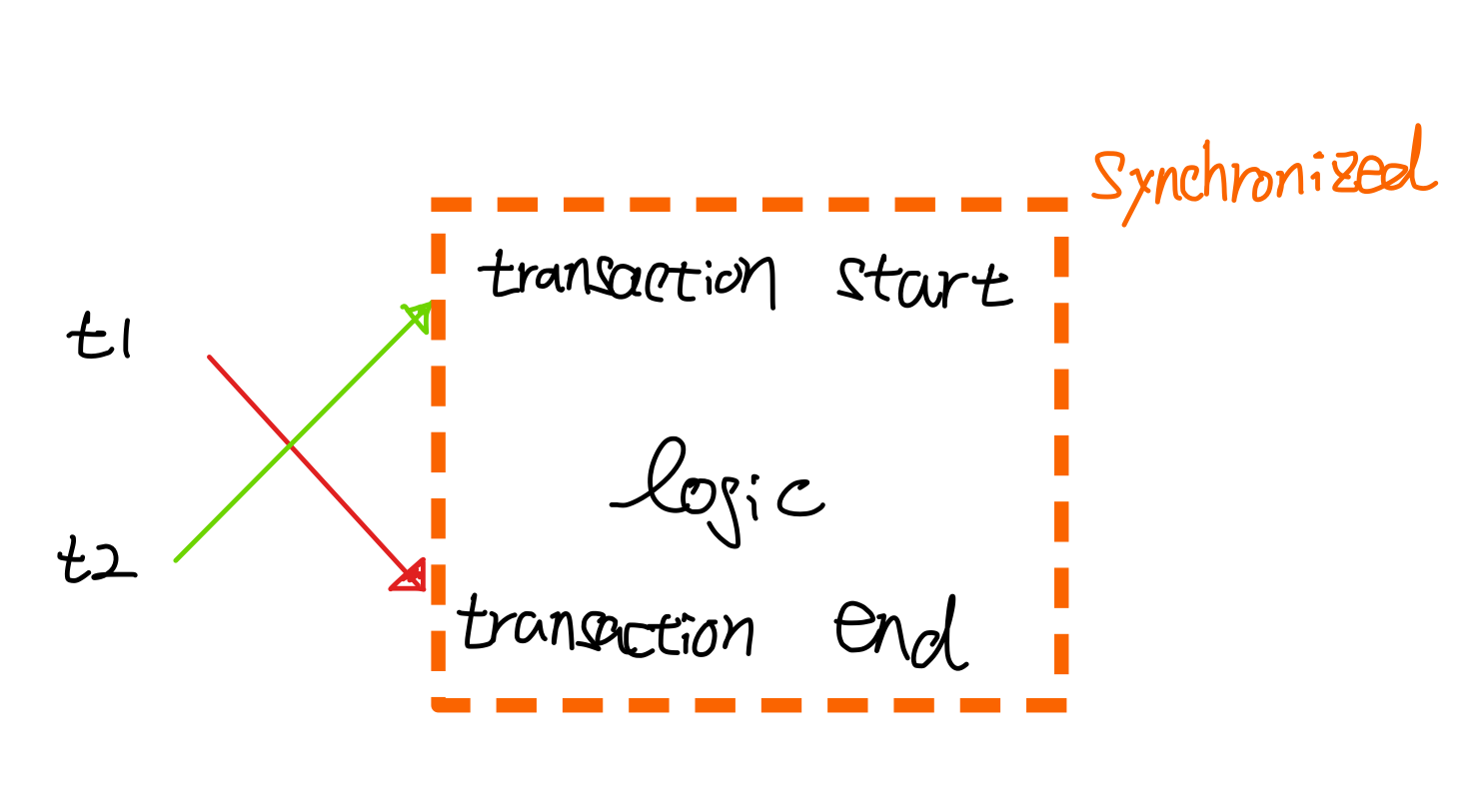
여전한 문제점
하지만 syncronized 키워드는 서버가 여러 대인 경우 문제가 생길 수 있습니다.
syncronized는 하나의 프로세서 안에서만 보장을 받을 수 있기 때문에 서버가 두 대 이상일 경우 데이터의 접근을 여러 곳에서 하게 되면 race condition 문제를 야기할 수 있습니다.
💡 race condition
두 개 이상의 프로세스가 공유 자원에 동시에 접근할 때 실행 순서에 따라 결과 값이 달라질 수 있는 현상을 의미
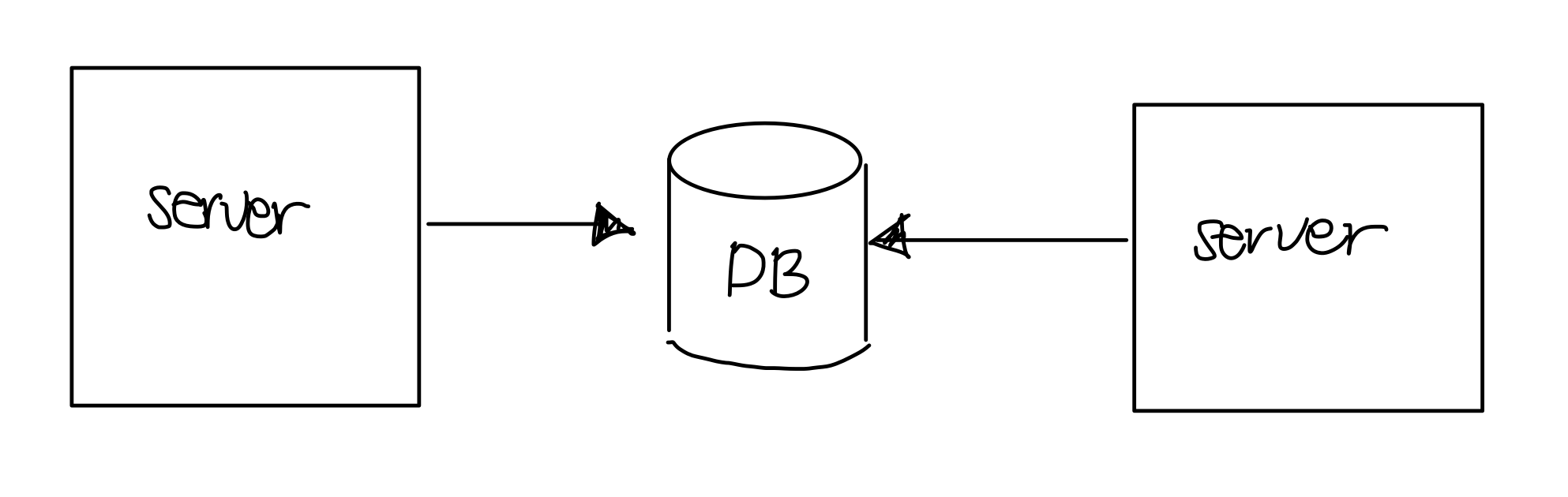
그렇다면 이 상황을 해결할 수 있는 다른 방법은 뭐가 있을까요?
해결 2. Locking
두 번째로 생각한 방법은 서버가 여러 대일 경우를 고안하여, DB에서 락을 활용해 동시성 문제를 해결할 수 있을 것 같습니다.
Locking 기법에는 여러가지가 존재하지만 그 중 다음 두가지를 살펴 보겠습니다.
- Pessimistic lock (비관적 락)
- Optimistic lock (낙관적 락)
Pessimistic lock
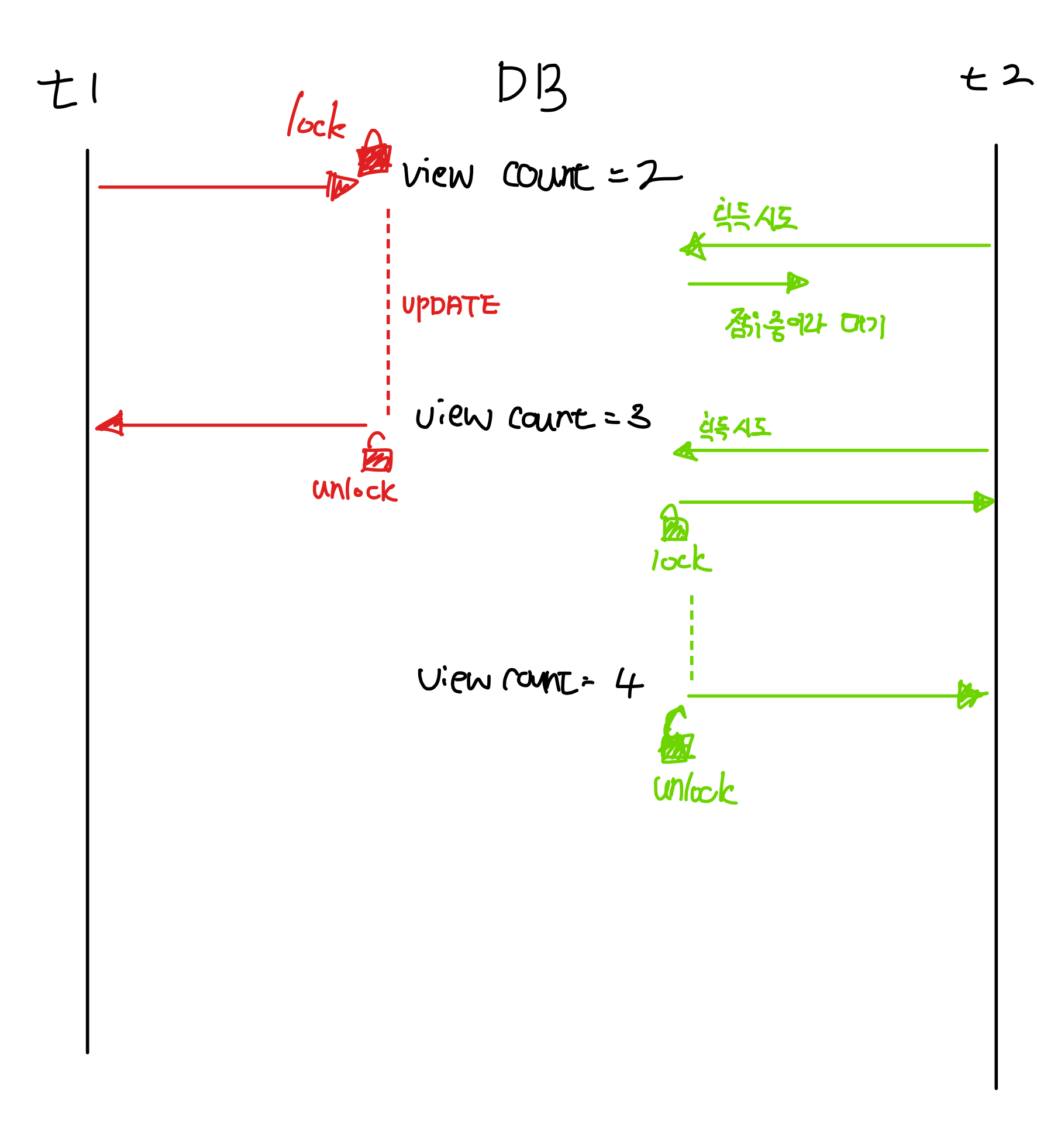
비관적 락은 DB의 실제 데이터에 락을 걸어 데이터의 정합성을 맞추는 방법입니다.
비관적 락은 트랜잭션이 시작할 때 X-lock 또는 S-lock을 걸게 됩니다.
코드를 통해 비관적 락을 적용하는 과정을 살펴보겠습니다.
public interface ItemRepository extends JpaRepository<Item, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT item FROM Item item WHERE item.id =: itemId")
Optional<Item> findByWithPessimisticLock(@Param("itemId") Long itemId);
}@Transactional
public syncronized ItemDetailResponse itemDetails(Long itemId) {
Item item = itemRepository.findByIdWithPessimisticLock(itemId)
.orElseThrow(() -> new NotFoundException());
itemViewCountService.addViewCount(itemId);
}JPA에서는 쉽게 락을 설정할 수 있는 @Lock 어노테이션을 제공해줍니다. 해당 어노테이션의 PESSIMISTIC_WRITE는 X-lock을 건다는 의미와 동일합니다.
위 그림처럼 조회수 증가 로직에 접근하는 동안 다른 프로세스에서 접근하지 못하게 하기 위해 사용하였습니다.
여전한 문제점?
비관적 락을 사용하는 것은 문제를 해결하는 하나의 방법이지만, 항상 좋은 방법은 아닙니다.
왜냐하면 하나의 트랜잭션이 작업을 완료할 때 까지 lock을 걸고 있기 때문에 다른 트랜잭션은 대기해야하며 그로 인한 처리 속도는 떨어지기 때문입니다.
또한, 단일 DB가 아닌 환경에서는 문제가 발생할 수 있습니다.
Optimistic lock
낙관적 락은 실제로 락을 이용하지는 않고 버전 정보를 통해 데이터의 정합성을 맞추는 방법입니다.
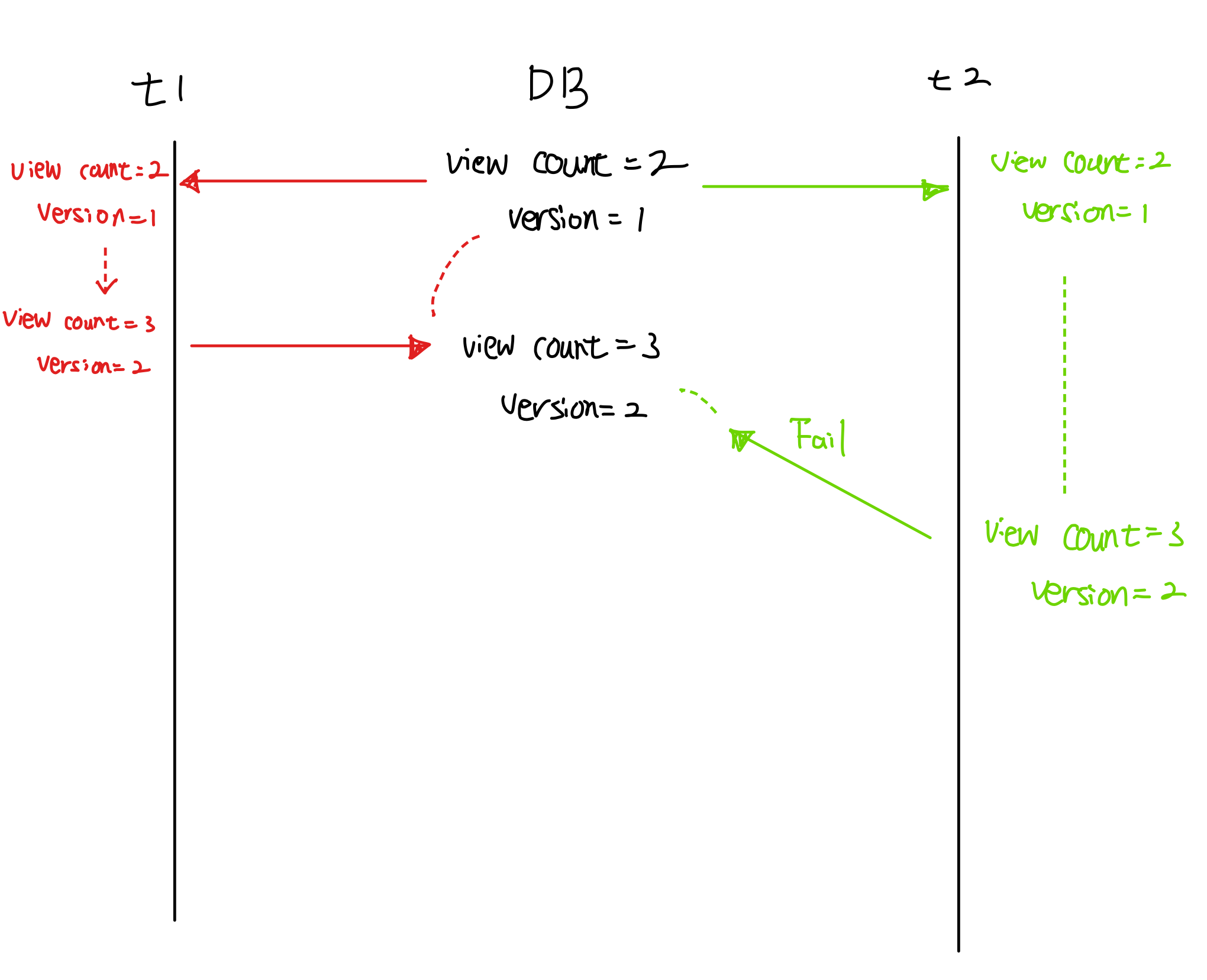
위 그림처럼 t1이 먼저 DB의 데이터를 변경하고 버전 정보를 수정한 뒤, t2가 version=1을 가지고 데이터를 수정한 후 DB에 반영하려 할 때 내가 가지고 있는 버전 정보와 DB에 반영되어 있는 버전 정보가 맞지 않아 업데이트에 실패하게 됩니다.
이처럼 내가 읽은 버전 정보에서 수정사항이 생겼을 경우 애플리케이션에서 다시 데이터를 읽은 후 업데이트를 시도해야 합니다.
그럼 바로 코드를 통해 살펴보겠습니다.
먼저 조회수 증가 요청이 오면 이벤트를 받는 리스너를 등록해줍니다.
@RequiredArgsConstructor
@Component
public class ItemEventListener {
private final OptimisticLockFacade optimisticLockFacade;
@TransactionalEventListener
public void addViewCount(Long itemId) throws InterruptedException {
optimisticLockFacade.addViewCount(itemId);
}
}낙관적 락의 경우 버전 정보가 일치하지 않을 때 재시도해야 하기 때문에 다음과 같이 while문을 통해 데이터를 수정하는 로직을 작성해 보았습니다.
@RequiredArgsConstructor
@Component
public class OptimisticLockFacade {
private final OptimisticLockViewCountService optimisticLockViewCountService;
public void addViewCount(Long itemId) throws InterruptedException {
while (true) {
try {
optimisticLockViewCountService.addViewCount(new ItemViewEvent(itemId));
break;
} catch (Exception e) {
Thread.sleep(50);
}
}
}
}@RequiredArgsConstructor
@Component
public class OptimisticLockViewCountService {
private final ItemRepository itemRepository;
private final ItemRepository itemRepository;
@Transactional
public void addViewCount(Long itemId) {
Item item = itemRepository.findByIdWithPessmisticLock(itemId).orElseThrow();
itemViewCountService.addViewCount(itemId);
...
}
}이처럼 낙관적 락의 경우 비관적 락과 달리 데이터에 락을 걸지 않고 버전 정보를 이용하기 때문에 상황에 따라 비관적 락보다 성능이 더 좋을 수 있습니다.
하지만 위처럼 업데이트가 실패했을 경우 개발자가 직접 재시도 로직을 작성해줘야 한다는 단점이 존재합니다.
결론
여기까지 동시성 문제를 해결하기 위한 방법으로 syncronized, 비관적 락, 낙관적 락에 대해 알아보았습니다.
현재 진행하고 있는 프로젝트는 다중 서버, 단일 DB 환경을 고려하고 있기 때문에 synchronized보다는 락을 활용한 동시성 제어를 사용하게 되었습니다.
또한 조회수 증가의 경우 데이터의 변경이 빈번하게 일어나고 race condition이 종종 발생할 수 있다 판단해 현재 가장 간단하게 적용할 수 있는 비관적 락을 선택하게 됐습니다.
추후 DB의 환경이 변경된다거나 다른 문제가 생긴다면 그때 다른 방법을 고려해 보겠습니다!
끝

