
개발 환경 설정은 아래 링크를 참고하자.
https://velog.io/@pikamon/OpenCL-1
1. 행렬 곱셈
행렬 A(NxP)와 B(PxM)의 곱 AB를 행렬 C라고 할 때, 행렬 C의 원소의 값은 아래와 같다. (0 ≤ r ≤ N, 0 ≤ c ≤ M)
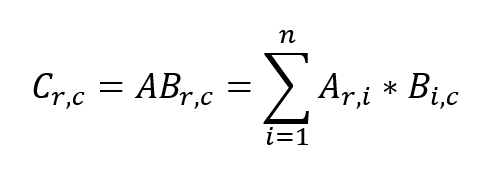
2. 일반적인 구현
행렬의 원소가 32비트 정수형이라고 할 때, 행렬 A(NxP), B(PxM)의 곱 AB를 구하는 프로그램을 C언어로 구현하면 아래와 같다.
- mulMatrix.c
#include <stdio.h>
#include <stdlib.h>
#define N 5
#define M 5
#define P 5
int main(void)
{
int arr[N][P] = {
{ 1, 1, 1, 1, 1, },
{ 1, 1, 1, 1, 1, },
{ 1, 1, 1, 1, 1, },
{ 1, 1, 1, 1, 1, },
{ 1, 1, 1, 1, 1, },
};
int brr[P][M] = {
{ 2, 2, 2, 2, 2, },
{ 2, 2, 2, 2, 2, },
{ 2, 2, 2, 2, 2, },
{ 2, 2, 2, 2, 2, },
{ 2, 2, 2, 2, 2, },
};
int crr[N][M] = { 0, };
// calculate 1
for (int i = 0; i < N; i++)
{
for (int j = 0; j < M; j++)
{
int acc = 0;
for (int k = 0; k < P; k++)
{
acc += arr[i][k] * brr[k][j];
}
crr[i][j] = acc;
}
}
// print result
for (int i = 0; i < N; i++)
{
for (int j = 0; j < M; j++)
{
printf("%d ", crr[i][j]);
}
printf("\n");
}
system("pause");
return 0;
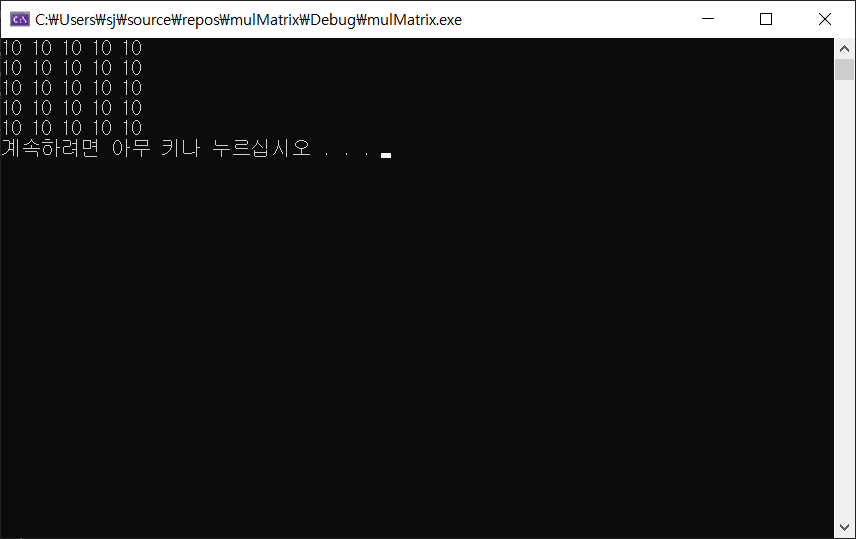
}컴파일 후 실행하면 아래와 같이 행렬곱이 출력되는 것을 볼 수 있다.
위 코드보다 훨씬 더 최적화된 형태의 코드도 많이 있는 것 같으니, 찾아보면 좋을 것 같다.
3. OpenCL 구현
위의 코드를 OpenCL을 이용해 재구성할 수 있다. 여러 가지 방법으로 만들 수 있지만, 가장 단순한 형태를 예로 들어보자.
아래의 그림은 우리가 위에서 다룬 행렬의 곱셈을 그림으로 나타낸 것이다. (마치 상자를 전개해놓은 것 같다.)
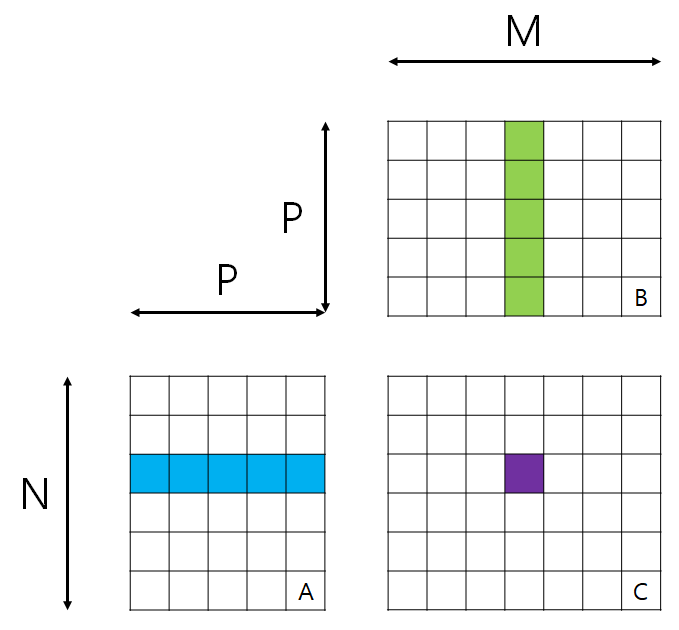
행렬 C의 원소 C(i, j)를 구하기 위해서는 행렬 A의 i번째 행의 원소들과 행렬 B의 j번째 열의 원소들을 곱하여 더하면 되는 것을 알 수 있다.
그림을 조금 고쳐보자.
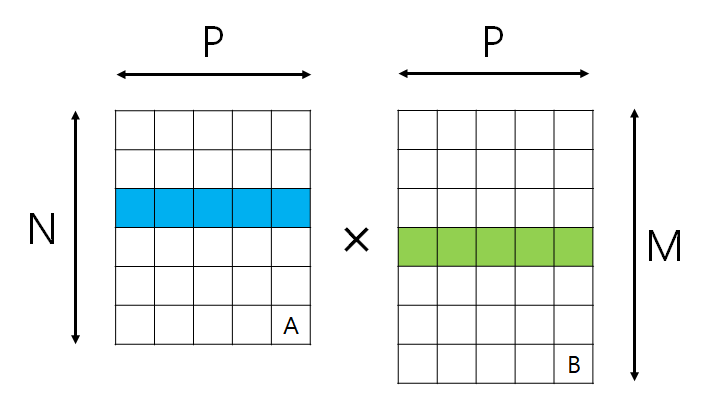
우리가 일반적인 구현에서 다루었던 코드는 for문을 N*M*P만큼 돌면서 각 원소를 곱해서 더한 것이었다.
이를 그대로 OpenCL 커널로 변환할 수 있다. 커널 인스턴스를 N*M개 생성하고, 커널 함수 내에서 for문을 P번 반복하도록 하면 멀티코어 환경에서 병렬처리시키기 용이해진다.
1. 커널 및 호스트 코드 구현
위 내용을 토대로 작성한 커널 함수는 아래와 같다.
- mulMatrix.cl
// TODO: Add OpenCL kernel code here.
__kernel void mulMatrix(__global int *A, __global int *B, __global int *C, int N, int M, int P)
{
int i = get_global_id(0);
int j = get_global_id(1);
int acc = 0;
for (int k = 0 ; k < P; k++)
{
acc += A[i * P + k] * B[k * P + j];
}
C[i * N + j] = acc;
}호스트 코드는 아래와 같다.
- host.cpp
// Add you host code
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <CL/cl.h>
#include <fstream>
#include <string>
#include <sstream>
#define N 5
#define M 5
#define P 5
int main(void)
{
// 0. 사용자 데이터 정의
int platformNum = 0;
int deviceNum = 0;
const char* sourceFile = "mulMatrix.cl";
const char* kernelName = "mulMatrix";
int arrayA[N][P] = {
{ 1, 1, 1, 1, 1, },
{ 1, 1, 1, 1, 1, },
{ 1, 1, 1, 1, 1, },
{ 1, 1, 1, 1, 1, },
{ 1, 1, 1, 1, 1, },
};
int arrayB[P][M] = {
{ 2, 2, 2, 2, 2, },
{ 2, 2, 2, 2, 2, },
{ 2, 2, 2, 2, 2, },
{ 2, 2, 2, 2, 2, },
{ 2, 2, 2, 2, 2, },
};
int arrayC[N][M] = { 0, };
// 입력 데이터 출력
printf("Array A:\n");
for (int i = 0; i < N; i++)
{
for (int k = 0; k < P; k++)
{
printf("%d ", arrayA[i][k]);
}
printf("\n");
}
printf("\n");
printf("Array B:\n");
for (int k = 0; k < P; k++)
{
for (int j = 0; j < M; j++)
{
printf("%d ", arrayB[k][j]);
}
printf("\n");
}
printf("\n");
// 1. platform 가져오기
cl_uint platformCount;
clGetPlatformIDs(0, NULL, &platformCount);
cl_platform_id* platforms = (cl_platform_id*)malloc(sizeof(cl_platform_id) * platformCount);
clGetPlatformIDs(platformCount, platforms, NULL);
// 2. device 가져오기
cl_uint deviceCount;
clGetDeviceIDs(platforms[0], CL_DEVICE_TYPE_ALL, 0, NULL, &deviceCount);
cl_device_id* devices = (cl_device_id*)malloc(sizeof(cl_device_id) * deviceCount);
clGetDeviceIDs(platforms[platformNum], CL_DEVICE_TYPE_ALL, deviceCount, devices, NULL);
cl_device_id device = devices[deviceNum];
// 3. context 생성하기
cl_context context = clCreateContext(NULL, 1, &device, NULL, NULL, NULL);
// 4. command queue 생성하기
cl_command_queue queue = clCreateCommandQueue(context, device, 0, NULL);
// 5. source 가져오기
FILE* fp = fopen(sourceFile, "rb");
cl_int status = fseek(fp, 0, SEEK_END);
long int size = ftell(fp);
rewind(fp);
char* source = (char*)malloc(sizeof(char) * (size + 1));
fread(source, sizeof(char), size, fp);
source[size] = '\0';
// 6. program 빌드하기
cl_program program = clCreateProgramWithSource(context, 1, (const char**)&source, NULL, NULL);
cl_int build_status = clBuildProgram(program, 1, &device, NULL, NULL, NULL);
// 7. kernel 생성하기
cl_kernel kernel = clCreateKernel(program, kernelName, NULL);
// 8. memory buffer 생성하기
cl_mem bufferA = clCreateBuffer(context, CL_MEM_READ_WRITE, N * P * sizeof(int), NULL, NULL);
cl_mem bufferB = clCreateBuffer(context, CL_MEM_READ_WRITE, P * M * sizeof(int), NULL, NULL);
cl_mem bufferC = clCreateBuffer(context, CL_MEM_READ_WRITE, N * M * sizeof(int), NULL, NULL);
// 9. command queue에 memory buffer 삽입하기
clEnqueueWriteBuffer(queue, bufferA, CL_TRUE, 0, N * P * sizeof(int), arrayA, 0, NULL, NULL);
clEnqueueWriteBuffer(queue, bufferB, CL_TRUE, 0, P * M * sizeof(int), arrayB, 0, NULL, NULL);
// 10. kernel argument 설정하기
int size_N = N;
int size_M = M;
int size_P = P;
clSetKernelArg(kernel, 0, sizeof(cl_mem), &bufferA);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &bufferB);
clSetKernelArg(kernel, 2, sizeof(cl_mem), &bufferC);
clSetKernelArg(kernel, 3, sizeof(int), &size_N);
clSetKernelArg(kernel, 4, sizeof(int), &size_M);
clSetKernelArg(kernel, 5, sizeof(int), &size_P);
// 11. command queue에 kernel 삽입하기
size_t globalSize[2] = { N, M };
clEnqueueNDRangeKernel(queue, kernel, 2, NULL, globalSize, NULL, 0, NULL, NULL);
// 12. 연산 완료될 때까지 대기하기
clFinish(queue);
// 13. 출력 버퍼에 결과 반환하기
clEnqueueReadBuffer(queue, bufferC, CL_TRUE, 0, N * M * sizeof(int), arrayC, 0, NULL, NULL);
// 결과 데이터 출력
printf("Array C:\n");
for (int i = 0; i < N; i++)
{
for (int j = 0; j < M; j++)
{
printf("%d ", arrayC[i][j]);
}
printf("\n");
}
printf("\n");
system("pause");
clReleaseMemObject(bufferA);
clReleaseMemObject(bufferB);
clReleaseMemObject(bufferC);
clReleaseKernel(kernel);
clReleaseProgram(program);
free(source);
fclose(fp);
clReleaseCommandQueue(queue);
clReleaseContext(context);
clReleaseDevice(device);
free(devices);
free(platforms);
return 0;
}globalSize의 N, M이 전체 커널 인스턴스의 크기가 되어 총 N*M개의 인스턴스를 생성하는 것 같다.
※ 위의 코드는 0번째 플랫폼의 0번째 디바이스를 고정적으로 선택하도록 되어있다는 점에 주의하자. (필자의 해당 디바이스는 Intel UHD Graphics이다.)
2. 실행 결과
Ctrl + F5 를 눌러 실행하면 아래와 같이 행렬 곱셈이 정상적으로 이루어진 것을 볼 수 있다.

4. 최적화 기법 적용
커널별 작업량 증가, 지역 메모리 사용, 캐싱 등의 방법으로 더 효과적인 프로그램을 만들 수 있다고 한다. (시간 나면 추가로 작성 예정)
5. 솔루션 첨부
글을 쓰면서 직접 작성한 Visual Studio 솔루션을 깃허브에 푸시하였다.
https://github.com/pikamonvvs/OpenCL-MatrixMultiplication
필요하면 내려받아서 실행해보면 될 것 같다.
6. 참고 문헌
- OpenCL 프로그래밍 가이드 (저자: 아프탑 문시) - 책 링크
- Yunmorning님의 블로그 - https://yunmorning.tistory.com/37
- Cedric Nugteren's home - https://cnugteren.github.io/tutorial/pages/page2.html
