
Heart Failure Prediction Dataset
| 항목 | 설명 |
|---|---|
| Age | 환자의 나이 (단위: 세) |
| Sex | 환자의 성별 M: 남성 F: 여성 |
| ChestPainType | 가슴 통증의 유형 TA: 전형적 협심증 (Typical Angina) ATA: 비전형적 협심증 (Atypical Angina) NAP: 비협심증성 통증 (Non-Anginal Pain) ASY: 무증상 (Asymptomatic) |
| RestingBP | 안정 시 혈압 (단위: mm Hg) |
| Cholesterol | 혈중 콜레스테롤 수치 (단위: mg/dl) |
| FastingBS | 공복 혈당 1: 120 mg/dl 초과 0: 120 mg/dl 이하 |
| RestingECG | 안정 시 심전도 검사 결과 Normal: 정상 ST: ST-T파 이상 (T파 역전, ST 상승 또는 하강 등) LVH: 좌심실 비대 (Estes 기준에 따른 가능성 있음) |
| MaxHR | 운동 중 도달한 최대 심박수 (범위: 60~202) |
| ExerciseAngina | 운동 유발 협심증 여부 Y: 있음 N: 없음 |
| Oldpeak | ST 분절의 하강 정도 (운동 후 심전도에서 측정된 수치, 단위: 숫자) |
| ST_Slope | 운동 시 ST 분절의 기울기 Up: 상승형 Flat: 평평함 Down: 하강형 |
| HeartDisease | 심장 질환 여부 (예측 대상 클래스) 1: 심장 질환 있음 0: 정상 |
📁 데이터 개요
Kaggle의 Heart Failure Prediction Dataset을 활용하여 환자의 여러 생체 신호와 검사 결과를 기반으로 심장 질환 여부(HeartDisease)를 예측합니다.
데이터 불러오기 및 전처리
import pandas as pd
import numpy as np
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/딥다이브/heart.csv')
df.info()
df.shape# 불필요한 컬럼 제거
# Cholesterol 컬럼은 정보가 부족하거나 중요하지 않다고 판단되어 제거
df = df.drop(['Cholesterol'], axis=1)# 범주형 변수 인코딩
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for col in ['Sex', 'ChestPainType', 'RestingECG', 'ExerciseAngina', 'ST_Slope']:
df[col] = le.fit_transform(df[col])2. 시각화를 통한 EDA
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 8))
corr = df.corr(numeric_only=True)
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title("Heatmap")
plt.show()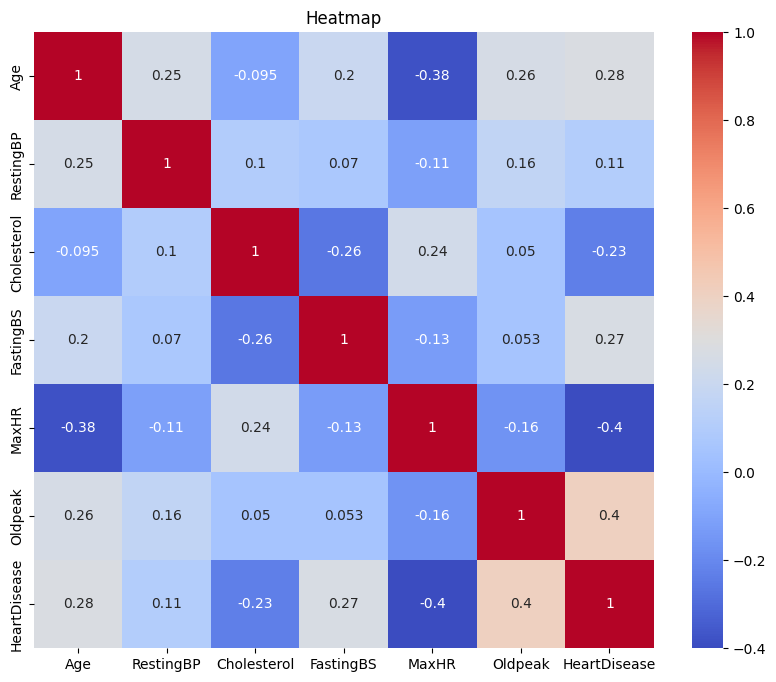
| 변수 쌍 | 상관계수 | 해석 |
|---|---|---|
| Age - HeartDisease | 0.28 | 나이가 많을수록 심장질환 위험 증가 |
| Oldpeak - HeartDisease | 0.40 | ST 분절 하강 정도가 클수록 심장질환과 연관 있음 |
| MaxHR - HeartDisease | -0.40 | 최대 심박수가 낮을수록 심장질환과 관련됨 |
| FastingBS - HeartDisease | 0.27 | 공복혈당이 높을수록 심장질환과 관련 있음 |
| Cholesterol - HeartDisease | -0.23 | 콜레스테롤은 다소 음의 상관 (일반적 해석과는 다를 수 있음 → 왜? 데이터 분포 확인 필요) |
📂 3. 데이터 분할 및 스케일링
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = df[['Age', 'Sex', 'ChestPainType','RestingBP']]
y = df['HeartDisease']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)StandardScaler는 데이터를 표준 정규 분포로 변환합니다.
🤖 4. 여러 분류 모델 학습 및 평가
✅ RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)✅ LogisticRegression
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)✅ SVM (Support Vector Machine)
from sklearn.svm import SVC
model = SVC(kernel='rbf', C=1.0, gamma='scale', probability=True)
model.fit(X_train, y_train)
y_pred = model.predict(X_test) ✅ Decision Tree
✅ Gradient Boosting
✅ XGBoost
✅ LightGBM
5. 모델 성능 평가 및 시각화
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report
print("정확도:", accuracy_score(y_test, y_pred))
print("정밀도:", precision_score(y_test, y_pred))
print("재현율:", recall_score(y_test, y_pred))
print("F1 점수:", f1_score(y_test, y_pred))
print(classification_report(y_test, y_pred))혼동 행렬 (Confusion Matrix)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()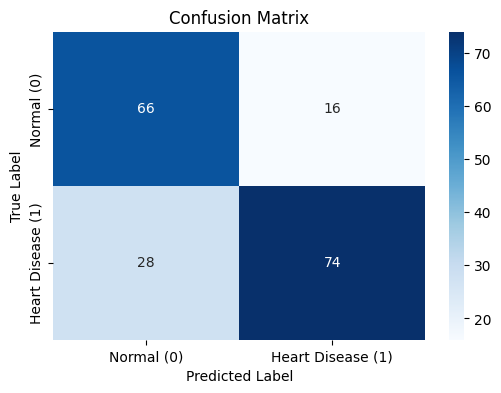
| 예측: Normal (0) | 예측: Heart Disease (1) | |
|---|---|---|
| 실제: Normal (0) | ✅ 66 (True Negative) | ❌ 16 (False Positive) |
| 실제: Heart Disease (1) | ❌ 28 (False Negative) | ✅ 74 (True Positive) |
✅ 정확도 (Accuracy)
✅ 정밀도 (Precision)
✅ 재현율 (Recall)
✅ F1 점수 (F1 Score)
ROC Curve
from sklearn.metrics import roc_curve, roc_auc_score
y_pred_prob = model.predict_proba(X_test_scaled)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
roc_auc = roc_auc_score(y_test, y_pred_prob)
plt.plot(fpr, tpr, label=f"AUC = {roc_auc:.3f}")
plt.plot([0,1], [0,1], linestyle='--')
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.title("ROC Curve")
plt.legend()
plt.grid(True)
plt.show()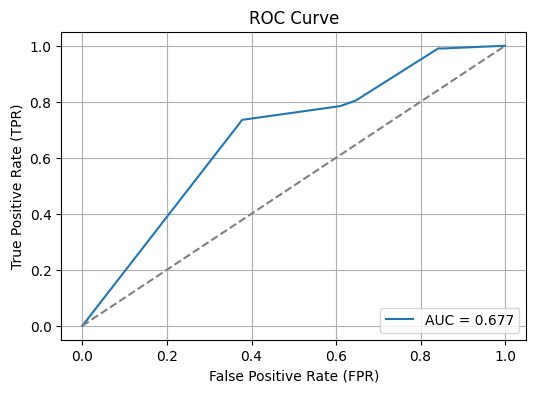
- FPR (False Positive Rate)
- TPR (True Positive Rate, 재현율/민감도)
✅ X축 (FPR): 거짓 양성률
✅ Y축 (TPR): 참 양성률 (재현율, Recall)
✅ AUC (Area Under the Curve)
ROC 곡선 아래 면적을 의미
범위: 0.5 ~ 1.0
- 1.0: 완벽한 분류기
- 0.5: 랜덤 예측과 동일
- 0.677: 평균보다 나은 모델 성능
AUC가 0.677이라는 것은:
모델이 무작위보다는 낫지만, 성능이 그리 높지는 않다는 것을 의미합니다.
✅ 성능 판단 기준
| AUC Score | 의미 |
|---|---|
| 0.90 ~ 1.0 | 매우 우수 |
| 0.80 ~ 0.90 | 우수 |
| 0.70 ~ 0.80 | 보통 |
| 0.60 ~ 0.70 | 부족 |
| 0.50 ~ 0.60 | 거의 랜덤 |
| < 0.50 | 오히려 잘못된 분류 |
자세한 코드는 깃허브
