
단층 퍼셉트론 VS 다중 퍼셉트론
📌 개요
퍼셉트론은 생물학적 뉴런을 모방한 인공 뉴런 모델로, 입력의 가중합을 계산한 뒤
비선형 활성화 함수를 통해 출력을 생성하는 기초적인 신경망 구조입니다.
📎 수식:
- : 입력값
- : 가중치
- : 바이어스
- : 활성화 함수
- : 출력값
단층 퍼셉트론 (Single-Layer Perceptron)
✅ 구조
- 입력층 → 출력층 (은닉층 ❌ 없음)
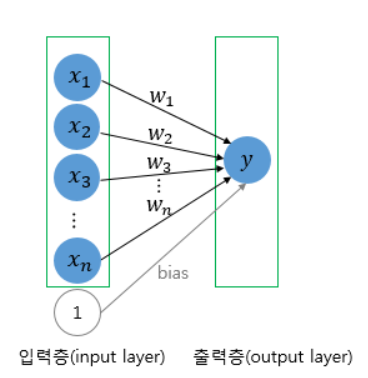
✅ 특징
- 선형 분리 문제만 해결 가능 (예: AND, OR)
- XOR 같은 비선형 문제는 해결 불가능 ❌
- 가중치 갱신은 퍼셉트론 학습 규칙 사용
다층 퍼셉트론 (Multi-Layer Perceptron, MLP)
✅ 구조
- 입력층 → 은닉층 (1개 이상) → 출력층
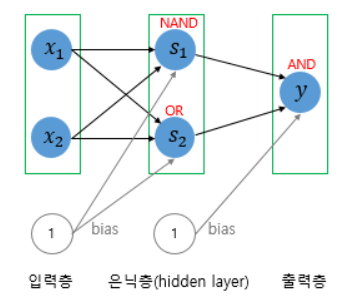
✅ 특징
- 비선형 문제도 해결 가능 (예: XOR 문제)
- 은닉층을 통해 복잡한 함수 근사
- 학습은 역전파 알고리즘 + 경사하강법 사용
퍼셉트론 학습 방식
-
순전파 (Forward Propagation)
입력값이 은닉층과 출력층으로 전달되며 출력 생성 -
역전파 (Backpropagation)
출력 오차를 바탕으로 각 가중치들을 업데이트
단층 vs 다층 퍼셉트론 비교
| 항목 | 단층 퍼셉트론 | 다층 퍼셉트론 (MLP) |
|---|---|---|
| 층 구조 | 입력 → 출력 | 입력 → 은닉 → 출력 |
| 해결 가능 문제 | 선형 문제 | 선형 + 비선형 문제 |
| XOR 해결 | ❌ 불가능 | ✅ 가능 |
| 학습 방식 | 퍼셉트론 규칙 | 역전파 (Backpropagation) |
| 대표 클래스 | Perceptron() | MLPClassifier() |
워드 임베딩 (Word Embedding)
1️⃣ 워드 임베딩이란?
워드 임베딩은 단어를 밀집된 실수 벡터(Dense Vector)로 표현하는 기법입니다.
기존의 원-핫 인코딩 (One-hot encoding) 방식은 다음과 같은 한계가 있습니다:
- 📏 벡터 차원이 단어 수만큼 커짐 → 희소 벡터 (Sparse Vector)
- 🧠 단어 간 의미적 유사도 반영 불가
📌 워드 임베딩은 단어를 저차원 연속 공간에 매핑하여
의미적으로 유사한 단어들이 벡터 공간에서 가깝게 위치하도록 합니다.
2️⃣ 워드 임베딩을 얻는 방법
✅ 랜덤 초기화 임베딩
- 임베딩 행렬을 무작위로 초기화
- 특정 과제를 수행하면서 모델 학습 과정에서 함께 최적화
✅ 사전 훈련된 임베딩 (Pre-trained Embedding)
- Word2Vec, GloVe, FastText 등의 사전 학습된 임베딩 사용
- 대규모 말뭉치 기반 학습 → 모델 성능 향상에 도움
⚠️ 단점:
- 문맥에 따라 의미가 달라지는 동형이의어, 다의어 처리에 한계 있음
3️⃣ Word2Vec
🔍 특징
- 벡터 연산을 통해 의미적 유추가 가능
구조
📌 CBOW (Continuous Bag of Words)
- 주변 단어들로 중심 단어를 예측
- 입력: 주변 단어 평균 벡터
- 출력: 중심 단어
📌 Skip-gram
- 중심 단어로 주변 단어들을 예측
- 희귀 단어에 대해 더 뛰어난 성능
성능 향상 기법: Negative Sampling
- 다중 클래스 분류를 이진 분류로 단순화
- 실제 단어 vs 가짜 단어(negative sample)를 구분
*대표 방식: SGNS (Skip-gram with Negative Sampling)
4️⃣ GloVe (Global Vectors for Word Representation)
💡 핵심 아이디어
동시 등장 행렬(Co-occurrence Matrix) 생성
→ 특정 단어 기준 윈도우 내에서 다른 단어가 몇 번 등장했는지 기록
두 단어 벡터의 내적이 동시 등장 확률의 로그값과 비슷하게 학습됨
수식:
, : 단어 , 의 임베딩 벡터
: 단어 , 의 동시 등장 횟수
