
딥러닝을 이용한 자연어 처리: BERTopic과 메모리 네트워크(MemN)
BERTopic (버토픽)
BERTopic은 BERT 임베딩과 c-TF-IDF(클래스 기반 TF-IDF)를 활용하여 문서 집합에서 토픽을 효과적으로 추출하는 토픽 모델링 기술입니다. 기존의 LDA와 같은 모델을 뛰어넘는 성능으로 많은 주목을 받고 있습니다.
BERTopic의 핵심 알고리즘은 다음과 같은 세 단계로 구성됩니다.
-
문서 임베딩 (Document Embedding)
- SBERT(Sentence-BERT)를 사용하여 각 문서를 고차원의 벡터로 변환합니다.
- 주로 영어는
"paraphrase-MiniLM-L6-v2", 다국어 환경에서는"paraphrase-multilingual-MiniLM-L12-v2"모델이 기본으로 사용됩니다.
-
문서 군집화 (Document Clustering)
- UMAP을 이용해 임베딩된 벡터의 차원을 축소합니다.
- HDBSCAN 알고리즘을 사용하여 의미적으로 유사한 문서들을 그룹(클러스터)으로 묶습니다.
-
토픽 표현 생성 (Topic Representation)
- c-TF-IDF를 각 클러스터에 적용하여 해당 토픽(클러스터)을 가장 잘 대표하는 단어들을 추출합니다.
한국어 데이터 적용 Tip!
한국어 데이터를 다룰 때는 기본CountVectorizer대신 Mecab과 같은 형태소 분석기를 사용하고, SBERT 모델 역시 한국어 또는 다국어를 지원하는 모델로 교체해야 좋은 성능을 얻을 수 있습니다.
메모리 네트워크 (Memory Network, MemN)
메모리 네트워크(MemN)는 이름 그대로 메모리라는 구성 요소를 도입하여 질의응답(Question Answering) 과제를 수행하는 딥러닝 모델입니다. 페이스북(현 메타)에서 제안한 babi QA 데이터셋을 통해 그 능력을 입증했습니다.
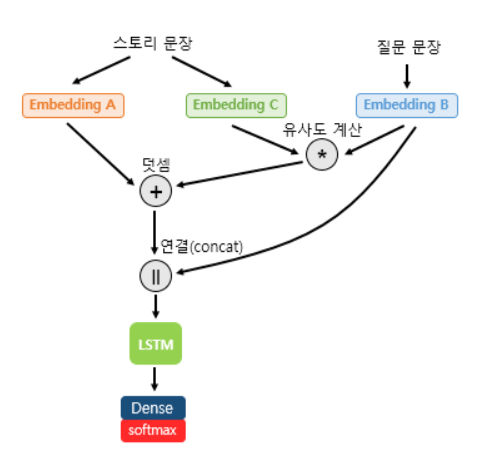
메모리 네트워크의 구조는 다음과 같습니다.
-
입력 (Input)
- 모델은 스토리(Story)와 질문(Question), 두 가지 형태의 텍스트를 입력으로 받습니다.
-
임베딩 (Embedding)
- 스토리의 각 문장은 서로 다른 임베딩 층(Embedding A, C)을 통해 벡터로 변환됩니다.
- 질문 문장 또한 별도의 임베딩 층(Embedding B)을 통해 벡터화됩니다.
-
어텐션 메커니즘 (Attention Mechanism)
- 임베딩된 질문(Query)과 스토리의 각 문장(Key) 사이의 유사도(주로 내적)를 계산합니다.
- 이 유사도에 소프트맥스 함수를 적용하여 어텐션 가중치를 얻습니다.
- 이 가중치를 스토리(Value)에 곱하여, 질문과 관련성이 높은 정보가 강조된 새로운 스토리 표현을 만듭니다.
-
출력 생성 (Output Generation)
- 어텐션을 통해 얻은 스토리 표현과 임베딩된 질문 표현을 연결(concatenate)합니다.
- 이 연결된 벡터를 LSTM과 Dense 레이어를 통과시켜 최종적으로 질문에 대한 정답을 예측합니다.
