Snowflake는 스토리지(저장) 와 컴퓨팅(처리) 을 완전히 분리하고, 여러 독립 클러스터가 동일 데이터를 동시에, 서로 간섭 없이 처리할 수 있도록 설계된 클라우드 네이티브 데이터 웨어하우스다.
📋 목차
- 왜 이 아키텍처가 탄생했는가
- 전체 구조 한눈에 보기
- Cloud Services Layer — 두뇌
- Query Processing Layer — 실행 엔진
- Data Storage Layer — 중앙 저장소
- Cloud Agnostic Layer
- 전체 쿼리 흐름 (처음→끝)
- 전통 DB vs Snowflake 비교표
1. 왜 이 아키텍처가 탄생했는가
전통적인 데이터 웨어하우스는 스토리지와 컴퓨팅이 하나로 묶여 있었다.
이 구조의 문제는 명확하다.
[문제 상황]
재무팀이 무거운 분석 쿼리 실행
↓
서버 CPU · 메모리가 꽉 참
↓
다른 팀의 ETL 파이프라인 · BI 대시보드도 동시에 느려짐
↓
데이터 1TB 더 저장하려면 컴퓨팅도 늘려야 함 → 비용 폭발💡 Snowflake의 해답
스토리지(저장 비용)와 컴퓨팅(처리 비용)을 완전히 분리.
각각 독립적으로 확장 · 축소 가능.
2. 전체 구조 한눈에 보기
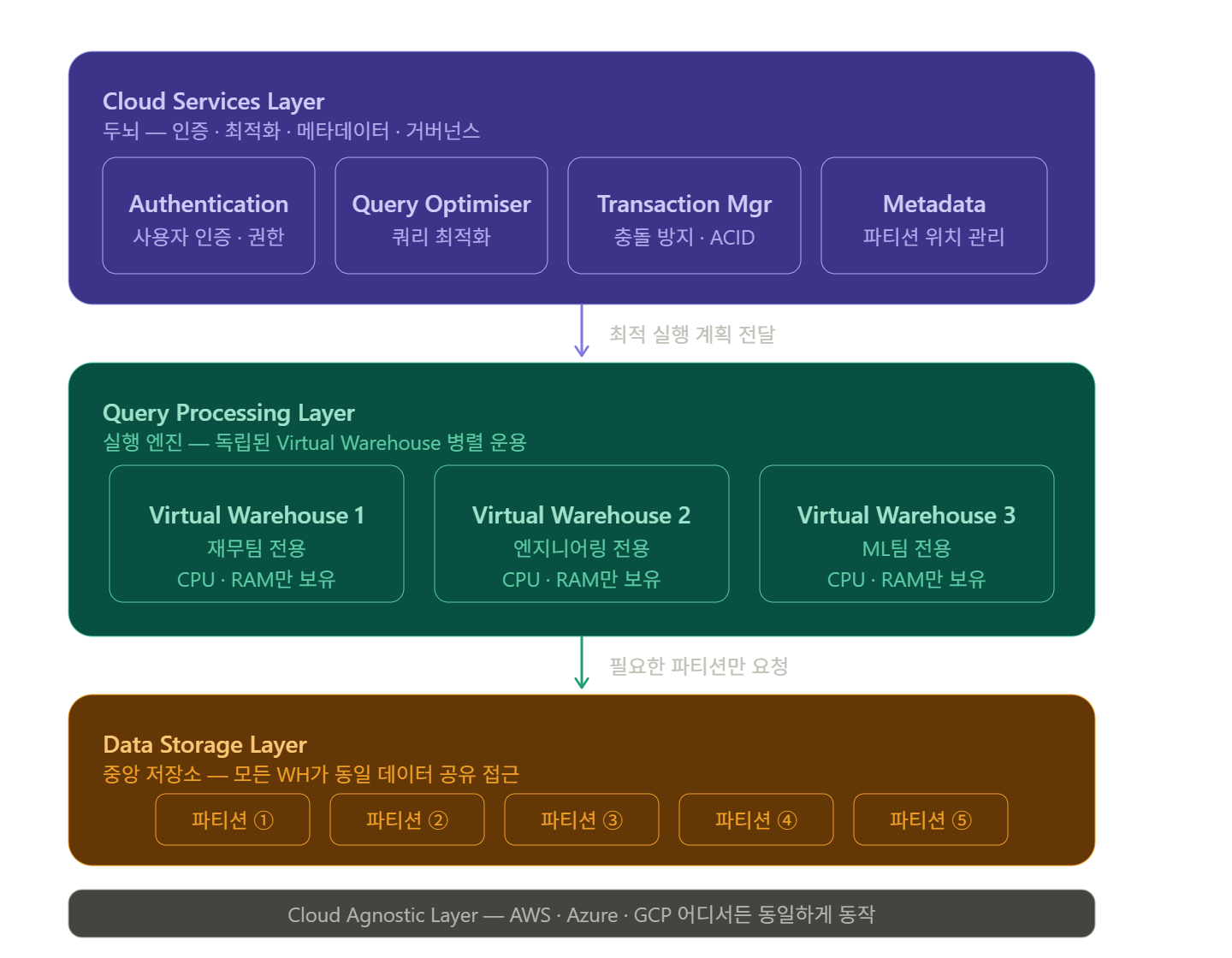
3. Cloud Services Layer — 두뇌
모든 요청이 이 레이어를 거친다.
"생각"은 여기서 다 하고, 아래 레이어는 실행만 한다.
구성 요소 4가지 + Metadata
① Authentication & Access Control
사용자 로그인 요청
↓
자격증명 검증
↓
세션 토큰 발급 + 권한 태그 부착
↓
권한 없는 데이터는 아예 쿼리 계획에 포함하지 않음② Query Optimiser
SQL 수신
↓
Metadata의 테이블 통계 참조
↓
최적 실행 계획 생성 (어느 파티션을 읽을지 결정)
↓
Virtual Warehouse에 전달 → WH는 생각 없이 바로 실행③ Transaction Manager
여러 WH가 동시에 같은 데이터를 쓰려 할 때
↓
충돌 방지 (ACID 트랜잭션 보장)
↓
데이터 일관성 유지④ Metadata (Infrastructure Management)
- "2023년 1월 매출 데이터는 파티션 #447에 있음" 같은 위치 정보 저장
- 쿼리 시 전체 스캔 없이 필요한 파티션만 읽음 → 속도 폭발적 향상
⚠️ 포인트
Cloud Services Layer는 컴퓨팅 인스턴스를 Snowflake가 직접 운용 → 사용자가 관리할 것 없음
이 레이어가 꺼지면 WH가 켜져 있어도 쿼리 실행 불가 = 두뇌가 없으면 몸이 못 움직임
4. Query Processing Layer — 실행 엔진
Virtual Warehouse(VW)란?
Virtual Warehouse = CPU + RAM으로 구성된 독립 컴퓨팅 클러스터
| 특성 | 내용 |
|---|---|
| 데이터 저장 여부 | ❌ 저장 안 함 |
| 자원 공유 여부 | ❌ 다른 WH와 공유 없음 |
| 동시 접근 | ✅ 여러 WH가 같은 Storage 동시 읽기 가능 |
| 비용 | 실제 사용 초(秒) 단위 과금 |
-- 팀별로 별도 Virtual Warehouse 운용 예시
CREATE WAREHOUSE finance_wh -- 재무팀 전용
WAREHOUSE_SIZE = 'LARGE';
CREATE WAREHOUSE eng_wh -- 엔지니어링 전용
WAREHOUSE_SIZE = 'MEDIUM';
-- 두 WH가 동시에 같은 테이블을 읽어도 서로 무관Multi-cluster의 인과관계
[Auto-scale 모드 작동 원리]
쿼리 동시 요청이 현재 클러스터 처리 용량 초과
↓
쿼리 대기 줄 발생
↓
Snowflake가 추가 클러스터 자동 시작 (Scale-out)
↓
대기 쿼리들이 새 클러스터로 분산 처리
↓
트래픽 감소 감지 → 추가 클러스터 자동 종료 (비용 절약)
↓
항상 최대 자원을 켜두지 않아도 피크 타임 처리 가능두 가지 스케일링 모드 비교
| 모드 | 설명 | 적합한 상황 |
|---|---|---|
| Auto-scale | 수요에 따라 클러스터 자동 증감 | 트래픽 변동이 클 때 (비용 효율) |
| Maximized | 처음부터 최대 클러스터 수 고정 | 동시 사용자가 항상 많을 때 |
5. Data Storage Layer — 중앙 저장소
실제 데이터가 저장되는 곳.
Virtual Warehouse가 꺼져도 데이터는 여기에 안전하게 존재한다.
Micro-partition이란?
데이터를 50~500MB 크기의 불변(immutable) 조각으로 잘라 저장하는 방식.
각 조각에는 해당 데이터의 통계 정보가 내장되어 있다.
[Micro-partition이 쿼리 성능을 높이는 원리]
저장 시
→ 데이터를 컬럼 단위로 압축
→ 각 파티션의 min/max 값 등 통계 생성
→ Metadata에 등록
쿼리 실행 시 (예: WHERE date = '2023-01')
→ Query Optimiser가 Metadata 확인
→ 해당 날짜가 없는 파티션은 아예 안 읽음 (Partition Pruning)
→ 필요한 파티션만 Virtual Warehouse로 전송
결과
→ 수십 TB 테이블도 빠른 응답 가능
→ 스캔량 ↓ → 비용 ↓ → 속도 ↑저장 위치: Amazon S3 / Azure Blob Storage / Google Cloud Storage
→ 클라우드 오브젝트 스토리지 위에 올라가므로 내구성이 높고 무한에 가깝게 확장 가능.
6. Cloud Agnostic Layer
다이어그램 맨 아래의 라인.
Snowflake는 특정 클라우드에 종속되지 않는다.
| 클라우드 | 컴퓨팅 | 스토리지 |
|---|---|---|
| AWS | EC2 | Amazon S3 |
| Azure | Virtual Machines | Azure Blob Storage |
| GCP | Compute Engine | Google Cloud Storage |
AWS, Azure, GCP 어디서든 동일한 방식으로 동작.
서로 다른 클라우드에 걸쳐 데이터 복제·분석도 지원 (Snowgrid).
7. 전체 쿼리 흐름 (처음→끝)
사용자가 SELECT 쿼리를 날렸을 때 일어나는 일
① Cloud Services — Authentication
사용자 신원 확인 → 권한 검사 → 세션 유효성 확인
↓
② Cloud Services — Query Optimiser
SQL 파싱 → Metadata 조회 → 필요한 Micro-partition 목록 생성
→ 최적 실행 계획 수립
↓
③ Query Processing — Virtual Warehouse
실행 계획 수신 → Storage에서 해당 파티션만 읽어옴
→ MPP(병렬 처리)로 연산 → 결과 생성
↓
④ Data Storage Layer
VW의 요청에 따라 필요한 Micro-partition만 전송
(전체 테이블 스캔 없음)
↓
⑤ 결과 반환
결과 캐싱 (24시간)
→ 동일 쿼리 재요청 시 WH 가동 없이 즉시 반환8. 전통 DB vs Snowflake 비교표
| 항목 | 전통 데이터 웨어하우스 | Snowflake |
|---|---|---|
| 스토리지 / 컴퓨팅 | 결합 (함께 확장해야 함) | 완전 분리 (독립 확장) |
| 동시 작업 격리 | 자원 공유 → 서로 간섭 | Virtual Warehouse별 격리 |
| 확장 방식 | 수직 확장 (서버 업그레이드) | 수평 확장 (클러스터 추가) |
| 비용 모델 | 항상 최대 자원 유지 비용 | 사용 초 단위 과금 |
| 데이터 읽기 | 전체 테이블 스캔 多 | Partition Pruning으로 최소 읽기 |
| 인프라 관리 | 직접 관리 필요 | Snowflake가 완전 관리 (SaaS) |
| 클라우드 종속 | 특정 클라우드 의존 | Cloud Agnostic (AWS/Azure/GCP) |
| 아키텍처 유형 | Shared-Disk 또는 Shared-Nothing | 둘의 하이브리드 |
키워드 10가지
① 3레이어 구조
- Cloud Services (두뇌) / Query Processing (실행) / Data Storage (저장)
- 각 레이어의 역할을 독립적으로 설명할 수 있어야 함
② 스토리지·컴퓨팅 분리 (Decoupled)
- Snowflake의 핵심 설계 원칙
- 왜 분리했는지(비용 절감, 독립 확장) 설명 가능해야 함
③ Virtual Warehouse
- 데이터를 저장하지 않음 (컴퓨팅 자원만 보유)
- 독립 클러스터 → 서로 자원 공유 없음
④ Multi-cluster 두 모드
- Auto-scale = 수요에 따라 자동 증감
- Maximized = 고정 최대 클러스터 수
⑤ Micro-partition
- 크기: 50~500MB
- 특성: 불변(immutable), 컬럼 통계 내장
- 효과: Partition Pruning으로 불필요한 스캔 제거
⑥ Metadata
- 위치: Cloud Services Layer
- 역할: 어느 파티션에 어떤 데이터가 있는지 위치 정보 관리
⑦ 결과 캐시 (Result Cache)
- 동일 쿼리 24시간 내 재요청 → WH 가동 없이 즉시 반환
⑧ Cloud Agnostic
- AWS / Azure / GCP 모두 지원
- 특정 클라우드에 종속되지 않음
⑨ MPP (Massively Parallel Processing)
- Virtual Warehouse 내에서 쿼리를 병렬로 처리하는 방식
⑩ 하이브리드 아키텍처
- Shared-Disk (단순하지만 느림) + Shared-Nothing (빠르지만 독립적)
- 두 방식의 장점만 결합한 것이 Snowflake
자주 틀리는 포인트
Virtual Warehouse는 데이터를 "저장"하지 않는다.
컴퓨팅 자원(CPU·RAM)만 갖고 있으며, 필요할 때 Storage Layer에서 데이터를 가져온다.
WH를 종료해도 데이터는 사라지지 않는다.
