
🟡문자열 포맷팅
- c언어 스타일 문자열 포맷팅
- python3 부터 지원하는 format 메서드 사용
- python3.6 부터 지원하는 f-string
name = "jane"
score = 89
print("%s의 수학 점수는 %d입니다" % (name, score))
name = "jane"
score = 89
print("{}의 수학 점수는 {}입니다".format(name, score))
name = "jane"
score = 89
print(f"{name}의 수학 점수는 {score}입니다")결과는 동일하게 jane의 수학 점수는 89입니다
🟡문자열
a = "abcdefg"
print(f"{a:10}") 결과: abcdefg____ ('_' 는 보이지 않는 공백이다)
🟡immutable과 mutable
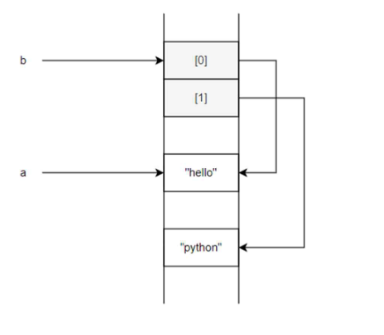
a = "hello"
b = ["hello", "goorm"]
print(id(a)) #135849556329712 <-주소
print(id(b)) #135849157497024
a는 문자열 객체를 바인딩, b는 리스트 객채를 바인딩 한다.
두개의 객체는 서로 다른 주소를 가진다는 것을 알 수 있다.
💡여기서 print(a), print(b[0])을 할 경우 같은 결과 hello가 나온다.
❓그럼 같은 객체 일까?
a = "hello"
b = ["hello", "goorm"]
print(id(a)) #135849556329712 <-주소
print(id(b[0])) #135849556329712❓ 결론
a와 b[0]은 같은 문자열 객체 "hello"를 가리킨다
그래서 id(a) == id(b[0])는 True
이건 값이 같아서가 아니라 가르키는 객체 자체가 같기 때문
Immutable, mutable
| 구분 | 타입 | 수정 여부 |
|---|---|---|
| Immutable | int, float, str, tuple | 객체 수정 불가능 |
| Mutalbe | list, dict | 객체 수정 가능 |
✅"객체를 만들고 나서, 그 내부 값을 바꿀 수 있느냐 없느냐"
ex)Mutalbe
a = [1, 2, 3]
print(id(a)) # 예: 1234
a.append(4)
print(a) # [1, 2, 3, 4]
print(id(a)) # 여전히 1234 (같은 객체)
ex)Immutable
s = "hi"
print(id(s)) # 예: 5678
s += "!"
print(s) # "hi!"
print(id(s)) # id 달라짐 (새로운 객체)🟡 list
리스트 컴프리헨셔
num =[]
for i in range(10):
if i %2 == 0:
num.append(i)
print(num)num = [i for i in range(10) if i%2 == 0]
print(num)
결과값: [0, 2, 4, 6, 8]
🟡튜플 팩킹, 언팩킹
- 튜플의 패킹 (Packing)
여러 개의 값을 하나의 튜플로 묶는 것
괄호 () 없이도 가능
t = 1, 2, 3 # 튜플 패킹
print(t) # (1, 2, 3)
t = (1, 2, 3)👉 1, 2, 3이라는 여러 값을 하나의 변수 t 안에 묶었다 → 이게 패킹!
- 튜플의 언패킹 (Unpacking)
튜플 안에 있는 여러 값을 각각의 변수로 풀어내는 것
t = (1, 2, 3)
a, b, c = t # 튜플 언패킹
print(a) # 1
print(b) # 2
print(c) # 3👉 t에 있던 값 (1, 2, 3)이 각각 a, b, c에 풀려 들어갔어
✨ 특별한 경우들
✅ 일부만 언패킹하고 싶을 때
t = (1, 2, 3, 4, 5)
a, b, *rest = t
print(a) # 1
print(b) # 2
print(rest) # [3, 4, 5]✅ 튜플을 반환하고 언패킹
def get_info():
return "pinggu", 25
name, age = get_info()
print(name) # pinggu
print(age) # 25🟡 zip
두개의 리스트를 묶어줘서 튜플 형태로 저장된다.
a = [1, 2, 3]
b = ['a', 'b', 'c']
z = zip(a, b)
print(list(z)) # [(1, 'a'), (2, 'b'), (3, 'c')]names = ["지민", "수연", "현우"]
grades = ["A", "B", "A+"]
for name, grade in zip(names, grades):
print(f"{name} 학생의 성적은 {grade}입니다.")
결과값:
지민 학생의 성적은 A입니다.
수연 학생의 성적은 B입니다.
현우 학생의 성적은 A+입니다.
🟡 딕셔너리
student = {
"name": "지민",
"age": 16,
"grade": "A"
}
print(student["name"]) # '지민' 출력
print(student["age"]) # 16 출력딕셔너리 zip활용
keys = ["name", "age", "city"]
values = ["지민", 16, "서울"]
# zip으로 묶고 dict()로 딕셔너리 생성
person = dict(zip(keys, values))
print(person)결과값: {'name': '지민', 'age': 16, 'city': '서울'}
여러 개의 리스트 → 딕셔너리 리스트로 만들기
name = ["지민", "수연", "현우"]
age = [16, 17, 16]
grade = ["A", "B", "A+"]
students = [{"name": k, "age": v, "grade": s} for k, v, s in zip(name, age, grade)]
for student in students:
print(f"{student['name']} 학생은 {student['age']}살이고, 성적은 {student['grade']}입니다.")
결과값:
지민 학생은 16살이고, 성적은 A입니다.
수연 학생은 17살이고, 성적은 B입니다.
현우 학생은 16살이고, 성적은 A+입니다
🟡 네임드 튜플
namedtuple은 튜플처럼 사용되지만, 이름(속성)으로 값에 접근할 수 있는 튜플이다.
❓ 왜 namedtuple을 쓰는 이유
기존의 일반 튜플은 인덱스로만 값에 접근할 수 있어요
person = ("지민", 16, "서울")
print(person[0]) # 이름person[0]의 값이 어떤 값인지 알기 어렵다.
→ 그래서 namedtuple을 쓰면 가독성도 좋아지며, dict처럼 이름 접근 가능
ex)
from collections import namedtuple
#네임드 튜플 정의
Student = namedtuple("Student", ["name", "age", "city"])
s1 = Student("지민", 16, "서울")
print(s1.name) # '지민'
print(s1.age) # 16
print(s1.city) # '서울'