
로지스틱 회귀
로지스틱 회귀는 분류(Classification) 문제를 해결하기 위한 대표적인 통계 모델이자 머신러닝 알고리즘입니다. 이름에 ‘회귀’가 붙어 있지만 실제로는 특정 범주에 속할 확률을 예측하는 분류 모델입니다.
주로 이진 분류 문제 (예: 생존/사망, 스팸/정상, 성공/실패 등)에 사용됩니다.
핵심 원리
로지스틱 회귀는 선형 회귀의 한계를 극복하기 위해 등장했습니다. 선형 회귀는 예측값이 음의 무한대부터 양의 무한대까지 나올 수 있어 확률을 예측하는 분류 문제에는 부적절합니다.
이를 해결하기 위해 시그모이드(Sigmoid) 함수를 사용하여 예측값을 0과 1 사이의 확률로 변환합니다.
✅ 시그모이드 함수 (로지스틱 함수)
📌 시그모이드 함수 (Logistic Function)
📌 용어 설명
- : 입력 에 대해 결과가 1(참)일 확률
- : 모델이 학습하는 가중치(계수)
- : 입력 변수
✅ 분류 기준
💡 예시
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
model = LogisticRegression()
model.fit(X, y)
✅ 장점
- 해석 용이성: 각 변수의 계수를 통해 결과에 미치는 영향 해석 가능
- 계산 효율성: 학습이 빠르고 비용이 적음
- 사용성: 오랜 기간 널리 사용되었고 관련 자료 풍부
❌ 단점
- 선형성 가정: 입력 변수와 로그 오즈(Log-Odds) 간의 선형 관계 가정
- 복잡한 문제에 약함: 비선형 관계나 대규모 데이터에서는 트리 계열 모델, 신경망 등 최신 알고리즘에 비해 성능이 낮을 수 있음
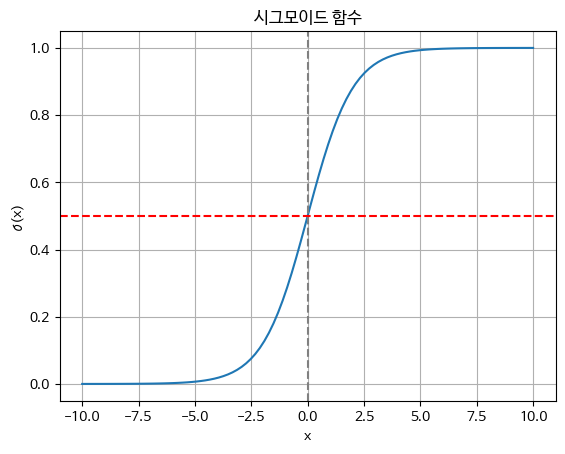
시그모이드 함수
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 시그모이드 함수 정의
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# x값 범위 설정
x = np.linspace(-10, 10, 100)
y = sigmoid(x)
# 시각화
plt.plot(x, y)
plt.title("시그모이드 함수")
plt.xlabel("x")
plt.ylabel("σ(x)")
plt.grid(True)
plt.axvline(0, color='gray', linestyle='--') # x=0 축
plt.axhline(0.5, color='red', linestyle='--') # y=0.5 기준선
plt.show()
지도 학습과 비지도 학습의 차이
1. 기본 개념
| 구분 | 지도 학습 (Supervised Learning) | 비지도 학습 (Unsupervised Learning) |
|---|---|---|
| 정의 | 정답(Label)이 있는 데이터를 학습 | 정답 없이 데이터를 스스로 학습 |
| 목표 | 입력 → 정답(출력) 예측 | 데이터 내부 패턴이나 구조 파악 |
2. 입력과 출력 구조
✅ 지도 학습
입력 (X) + 출력 (Y) → 모델 학습
예: X = 날씨 정보 / Y = 내일 기온✅ 비지도 학습
입력 (X)만 존재 → Y는 없음
예: X = 고객 구매 기록 → 유사한 그룹 찾기3. 예시
| 구분 | 예시 |
|---|---|
| 지도 학습 | 이메일 분류 (스팸/정상), 주택 가격 예측, 이미지 → 고양이/개 |
| 비지도 학습 | 고객 군집화, 추천 시스템, 차원 축소 (PCA) |
4. 대표 알고리즘
지도 학습
- 선형 회귀
- 로지스틱 회귀
- SVM (서포트 벡터 머신)
- 결정 트리 / 랜덤 포레스트
- 인공 신경망
비지도 학습
- K-Means 클러스터링
- DBSCAN
- PCA (주성분 분석)
- AutoEncoder
- 계층적 군집화
선형 회귀 모델
✅ 단변량 선형회귀
✅ 다변량 선형회귀
1️⃣ 단변량 선형회귀분석 (Simple Linear Regression)
정의
- 독립변수(feature) 1개와 종속변수(target) 1개 간의 선형 관계를 모델링하는 회귀 분석 기법입니다.
- 즉, 하나의 변수로 결과를 예측하는 가장 단순한 회귀 모델입니다.
수식
- : 예측값
- : 독립변수
- : 가중치(기울기)
- : 절편
손실 함수 (Mean Squared Error)
- : 실제값
- : 예측값
목표
데이터를 가장 잘 설명하는 직선을 찾는 것 → 잔차 제곱합 최소화
2️⃣다변량 선형회귀분석 (Multiple Linear Regression)
정의
- 2개 이상의 독립변수를 사용하여 종속변수를 예측하는 선형 회귀 기법입니다.
수식
- : 독립변수들
- : 각 특성에 대한 가중치
- : 절편
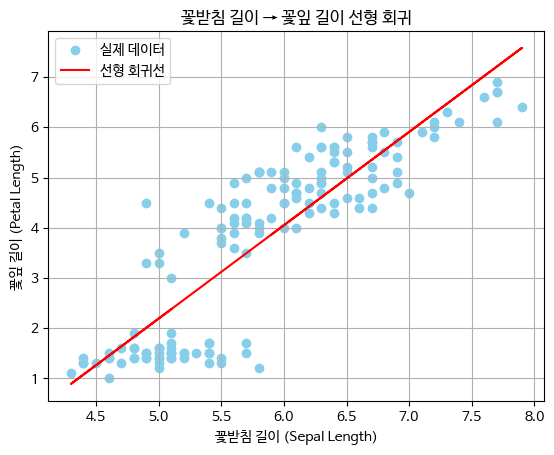
Iris 데이터 기반 선형 회귀
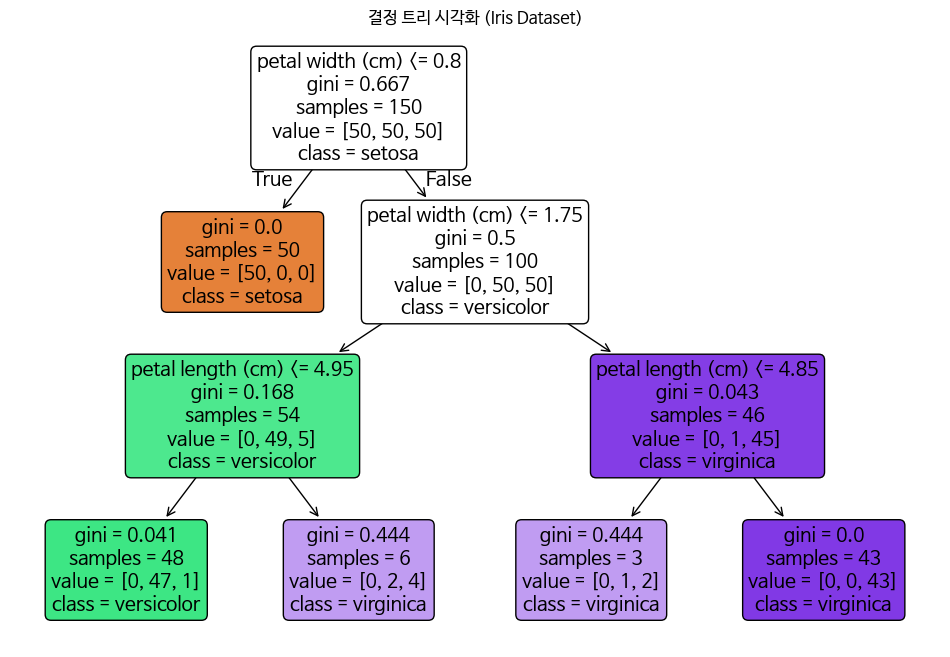
결정트리 알고리즘
결정 트리는 데이터를 기준(feature)으로 분할하여
의사결정 규칙을 트리(Tree) 구조로 표현하는 지도 학습(Supervised Learning) 알고리즘입니다.
- 분류(Classification), 회귀(Regression) 문제 모두 사용 가능
- 전처리가 거의 필요 없고, 해석이 쉬움
작동 방식
- 전체 데이터에서 최적의 분할 기준(feature)을 선택
- 해당 기준으로 데이터를 둘로 나눔
- 각 그룹에서 위 과정을 반복
- 더 이상 나눌 수 없으면 리프 노드 생성
분할 기준 (불순도)
✅ 지니 불순도 (Gini Impurity)
✅엔트로피 (Entropy)
✅정보 이득 (Information Gain)
- : 클래스 에 속할 확률
- Gini 값이 작을수록 노드가 더 순수함
- 정보 이득(IG)은 분할 전후의 엔트로피 차이
구성 요소
| 구성 요소 | 설명 |
|---|---|
| 루트 노드 | 트리의 시작점 |
| 내부 노드 | 데이터를 분할하는 노드 |
| 리프 노드 | 더 이상 분할되지 않고 예측값을 출력하는 노드 |
| 가지(Edge) | 노드 간의 분기 조건 |
최근접 이웃(k-NN) 알고리즘 이해하기
1️⃣ 훈련 데이터 저장
- KNN은 모델 훈련 단계에서 학습을 하지 않음
- 단순히 데이터를 저장해 놓기만 함
- 그래서 Lazy Learning (게으른 학습) 알고리즘이라 불림
2️⃣예측할 데이터와 기존 데이터 간 거리 계산
- 새로운 데이터 포인트가 들어오면, 모든 훈련 데이터와의 거리를 계산
- 주로 사용하는 거리:
유클리드 거리:
3️⃣가장 가까운 K개의 이웃 선택
계산된 거리 중에서 가장 가까운 K개의 데이터를 선택
4️⃣ K 값 설정의 중요성
- K가 너무 작으면: 과적합(Overfitting) 위험
- K가 너무 크면: 과소적합(Underfitting) 위험
일반적으로 홀수를 사용 (클래스 간 tie 방지)
회귀 평가지표
머신러닝에서 회귀 모델을 평가할 때는 분류 모델과 달리 오차(예측값 - 실제값)의 크기를 기반으로 성능을 측정합니다.
1️⃣ MAE (Mean Absolute Error)
평균절대오차
오차의 절댓값 평균
- 모든 예측 오차를 절댓값으로 바꾸고 평균을 계산
- 오차 크기에 대한 직관적인 지표
- 이상치에 덜 민감
📌 수식
- : 실제값
- : 예측값
- : 샘플 수
2️⃣ MSE (Mean Squared Error)
평균제곱오차
오차를 제곱한 후 평균
- 제곱을 하기 때문에 큰 오차에 더 민감
- 수학적으로 계산이 간단하고 미분이 쉬워 모델 최적화에 자주 사용
📌 수식
3️⃣ RMSE (Root Mean Squared Error)
평균제곱근오차
MSE에 루트를 씌워 단위를 원래대로 복원
- 단위가 실제 값과 동일하여 해석이 쉬움
- 여전히 큰 오차에 민감
📌 수식
4️⃣ 결정계수 R² (R-squared)
전체 변동성 중 예측 가능한 비율을 설명
- 0 ~ 1 사이의 값 (1에 가까울수록 좋은 모델)
- 예측값이 평균값만큼도 못할 경우 음수가 될 수 있음
📌 수식
- : 실제값의 평균
🔸 R² = 1: 완벽한 예측
🔸 R² = 0: 모델이 아무런 설명력 없음
🔸 R² < 0: 평균으로 예측하는 것보다 못함
혼동 행렬
| 예측: Normal (0) | 예측: Heart Disease (1) | |
|---|---|---|
| 실제: Normal (0) | ✅ (True Negative) | ❌ (False Positive) |
| 실제: Heart Disease (1) | ❌ (False Negative) | ✅ (True Positive) |
✅ 정확도 (Accuracy)
✅ 정밀도 (Precision)
✅ 재현율 (Recall)
✅ F1 점수 (F1 Score)
나이브 베이즈 분류기
1️⃣ 개요
- 나이브 베이즈는 확률 기반 지도 학습 분류 알고리즘입니다.
- 베이즈 정리를 기반으로 하며, 특성 간 조건부 독립성(naive assumption)을 가정합니다.
2️⃣ 베이즈 정리 (Bayes' Theorem)
- 데이터 가 주어졌을 때, 클래스 일 확률은 다음과 같습니다.
- 여기서,
- : posterior (사후 확률)
- : likelihood (가능도)
- : prior (사전 확률)
- : evidence (증거 데이터의 확률)
3️⃣ 나이브 가정 (조건부 독립)
- 각 특성 이 서로 독립적이라고 가정합니다.
- 따라서 베이즈 정리는 다음처럼 단순화됩니다.
4️⃣ 분류 과정 요약
- 각 클래스 에 대해
을 계산합니다.
- 그 중 가장 큰 값을 갖는 클래스를 선택하여 예측합니다.
5️⃣ 나이브 베이즈 분류기의 종류
| 종류 | 설명 |
|---|---|
| Gaussian Naive Bayes | 연속형 특성이 정규분포를 따른다고 가정 |
| Multinomial Naive Bayes | 단어 등장 횟수 기반 텍스트 분류 |
| Bernoulli Naive Bayes | 특성이 이진(0 또는 1)일 때 사용 |
6️⃣ 장점과 단점
✅ 장점
- 매우 빠르고 효율적
- 고차원 데이터에 적합 (예: 텍스트)
- 적은 데이터로도 효과적
❌ 단점
- 특성 간 독립이라는 가정은 현실적이지 않을 수 있음
- 예측 확률이 왜곡될 수 있음
