Moving between Storage Classes
- 스토리지 클래스 간에 객체를 이동시킬 수 있다.
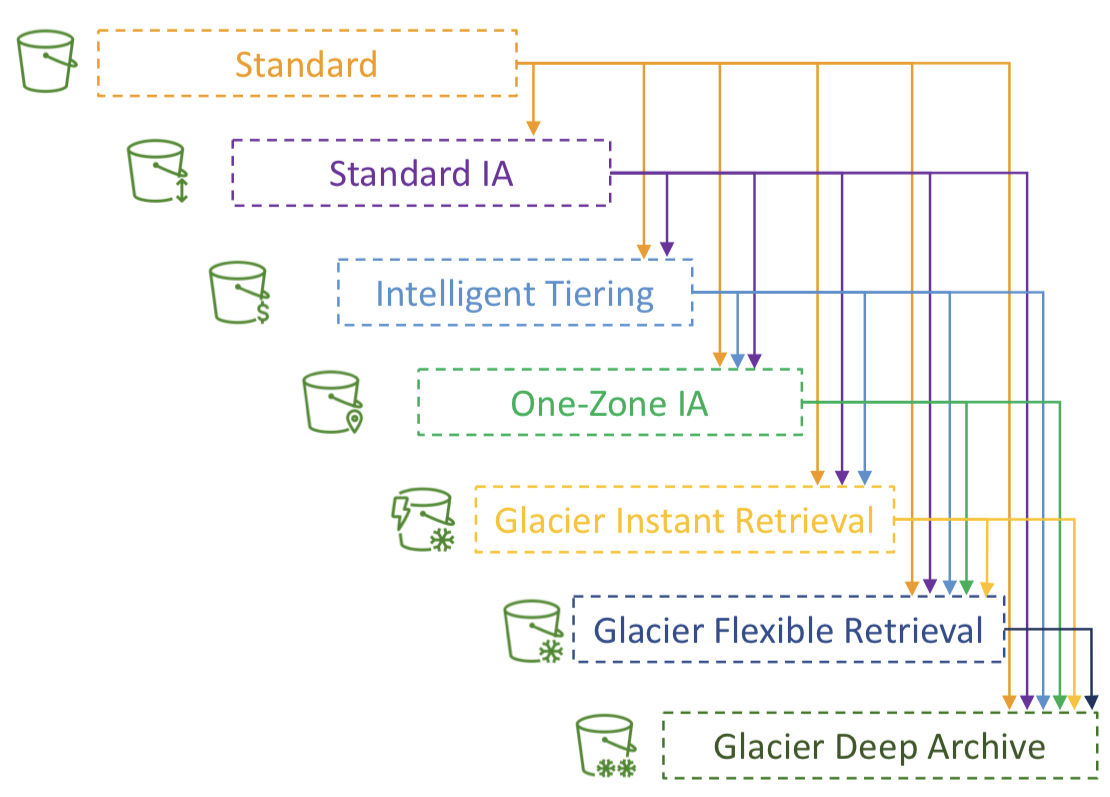
- 자주 액세스되지 않는 객체는 Standard IA로
- 빠른 액세스가 필요하지 않은 아카이브 객체는 Glacier 또는 Glacier Deep Archive 티어로 옮기기.
- 객체는 수동으로 옮기거나 수명 주기 규칙을 이용해서 자동화할 수 있다.
Lifecycle Rules
Transition Actions 전환 작업: 객체를 다른 스토리지 클래스로 전환하기 위해 구성
- 객체 생성 후 60일이 지나면 Standard IA로 이동
- 6개월 후 아카이빙을 위해 Glacier로 이동
Expiration Actions 만료 작업: 일정 시간 후에 객체를 삭제 또는 만료되도록 구성
- 365일 후에 액세스 로그 파일을 삭제
- 버전 관리가 활성화된 경우 이전 버전의 파일을 삭제하도록 설정
- 완료되지 않은 멀티파트 업로드를 삭제하도록 구성
- 특정 접두사에 대한 규칙을 생성할 수 있음 (ex. s3://mybucket/mp3/*)
- 특정 객체 태그에 대한 규칙을 생성할 수 있음 (ex. Department: Finance)
Lifecycle Rules Scenario 1
프로필 사진이 Amazon S3에 업로드된 후 썸네일이 생성됨. 썸네일은 원본 사진에서 재생성하기 쉬우므로 60일간 보관. 소스 이미지는 이 60일 동안은 바로 검색할 수 있어야하며, 그 이후에는 사용자가 6시간까지 기다릴 수 있음. 어떻게 설계하면 좋은가?
- 접두사를 이용하여 썸네일과 소스 이미지를 구분
- 소스 이미지를 Standard에 두고 수명 주기 구성을 한 다음 60일 이후에 Glacier로 전환
- 썸네일은 One-Zone IA에 두고 수명 주기 구성을 통해 60일 이후 만료 또는 삭제
Lifecycle Rules Scenario 2
S3 객체 삭제 후 30일 이내에는 즉시 복구가 가능해야 함. 그로부터 365일 동안은 삭제된 객체를 48시간 이내에 복구할 수 있어야 함.
- S3 버저닝을 활성화하여 "삭제된 객체"가 실제로는 "삭제 마커"에 의해 숨겨제고 복구할 수 있도록 함
- 객체의 이전 버전(noncurrent versions)은 Standard IA로 이동
- 이동 후 객체의 이전 버전(noncurrent versions)은 Glacier Deep Archive로 이동
Amazon S3 Analytics - Storage Class Analysis
- 객체를 적절한 스토리지 클래스로 전환할 때 도움
- Standard 및 Standard IA용 권장 사항 제공
- One-Zone IA 또는 Glacier에는 해당되지 않음
- 보고서는 매일 업데이트 됨
- 데이터 분석을 시작하는데 24-48시간이 소요됨
- 수명 주기 규칙을 작성하거나 개선하는 데 좋은 첫 번째 단계!
S3 - Requester Pays
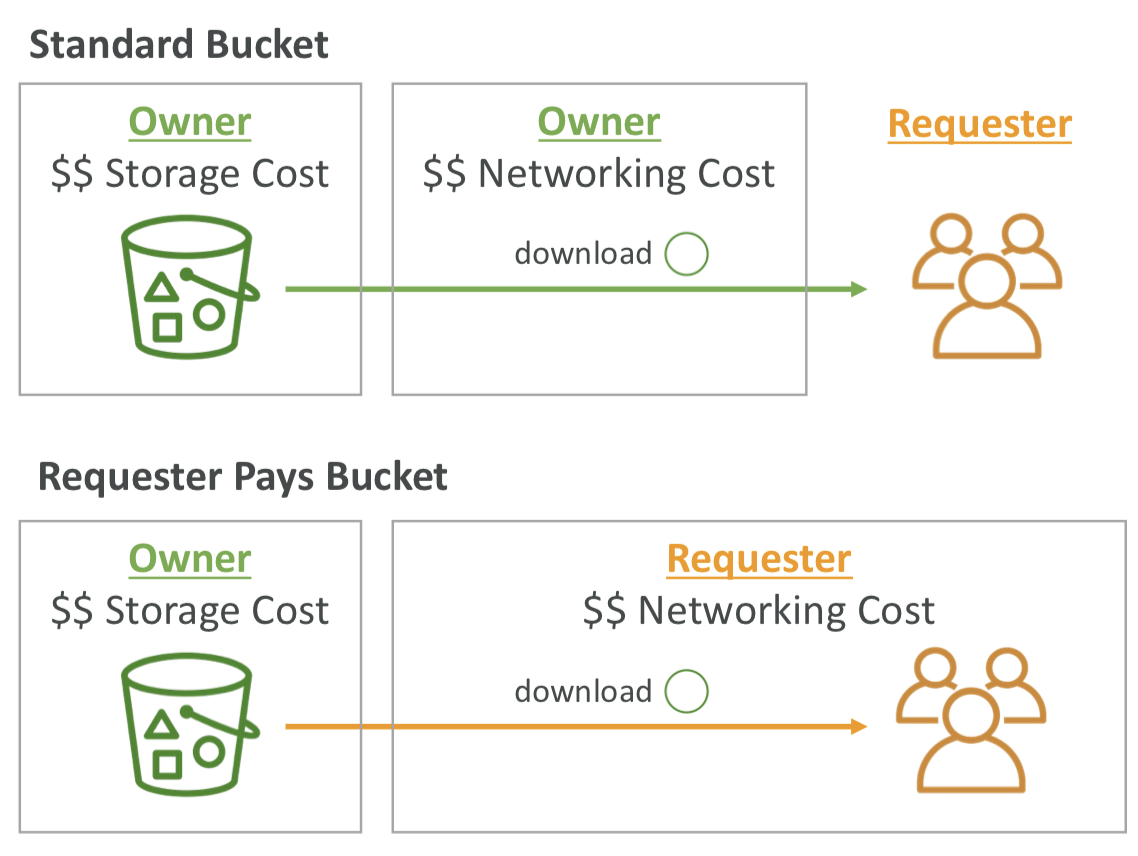
- 일반적으로, 버킷 소유자는 버킷과 관련된 모든 Amazon S3 스토리지 및 데이터 전송 비용을 부담한다.
- 요청자가 비용을 부담하는 Requester Pays 버킷의 경우, 버킷 소유자 대신 요청자가 요청 및 버킷에서 객체 데이터 다운로드 비용을 지불함
- 다른 계정과 대규모 데이터셋을 공유하려는 경우 유용함
- 요청자는 AWS에서 인증을 받아야하며 (익명으로는 불가), 인증된 상태여야 함.
S3 Event Notifications
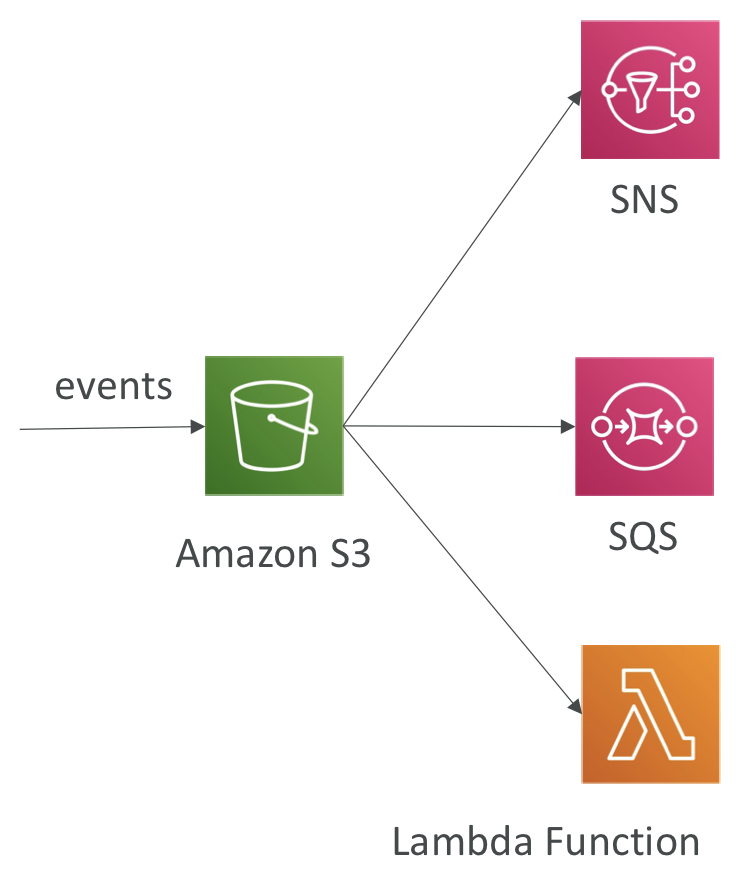
- S3:ObjectCreated, S3:ObjectRemoved, S3:ObjectRestore, S3:Replication 등의 이벤트 유형 필터링
- 객체 이름 필터링 (ex. .jpg로 끝나는 객체 필터링)
- 사용 사례: S3에 업로드된 이미지의 썸네일 생성
- 원하는 만큼 많은 "S3 이벤트"를 생성할 수 있음
- S3 이벤트 알림은 일반적으로 몇 초 내에 이벤트를 전달하지만 때로는 1분 이상 걸릴 수 있음
S3 Event Notifications with Amazon EventBridge
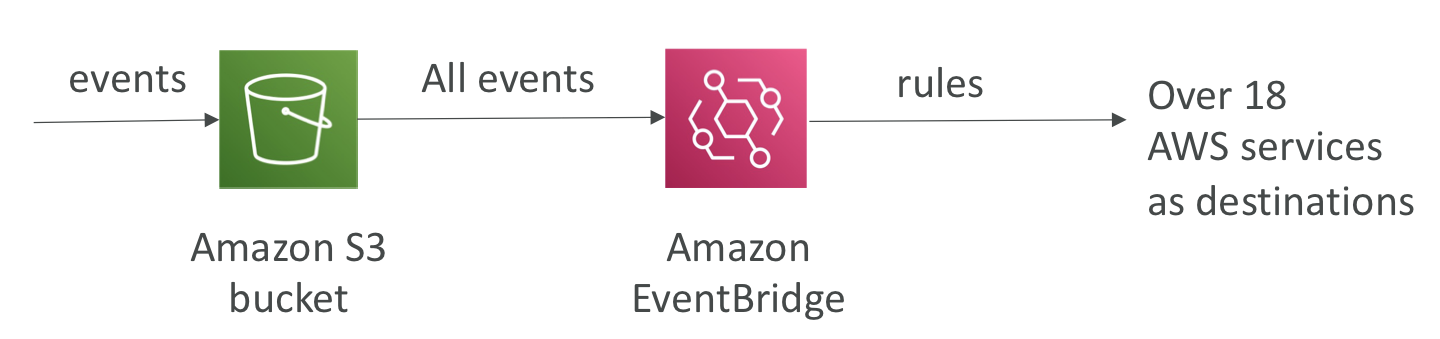
- JSON 규칙을 사용한 Advanced filtering 옵션 (메타데이터, 객체 크기, 이름 등)
- Multiple Destinations: ex. Step Functions, Kinesis Streams / Firehose 등
- EvnetBridge Capabilities: 이벤트 아카이브, 이벤트 재생, 안정적인 전송
S3 - Baseline Performance
- Amazon S3는 요청이 아주 많을 때 자동으로 확장되며, 지연 시간도 100-200ms 수준으로 아주 짧음.
- 버킷 내 접두사(prefix)당 초당 적어도 3,500개의 PUT/COPY/POST/DELETE 요청 또는 5,500개의 GET/HEAD 요청을 처리할 수 있음
- 버킷 내 접두사의 수에는 제한이 없음
- exmaple (객체 경로 → 접두사)
- bucket/folder1/sub1/file → /folder1/sub1/
- bucket/folder1/sub2/file → /folder1/sub2/
- bucket/1/file → /1/
- bucket/2/file → /2/
- 모든 네 개의 접두사에 대해 읽기 요청을 균등하게 분산하면 GET/HEAD 요청을 초당 22,000개 처리할 수 있음
S3 Performance
Multi-Part upload:
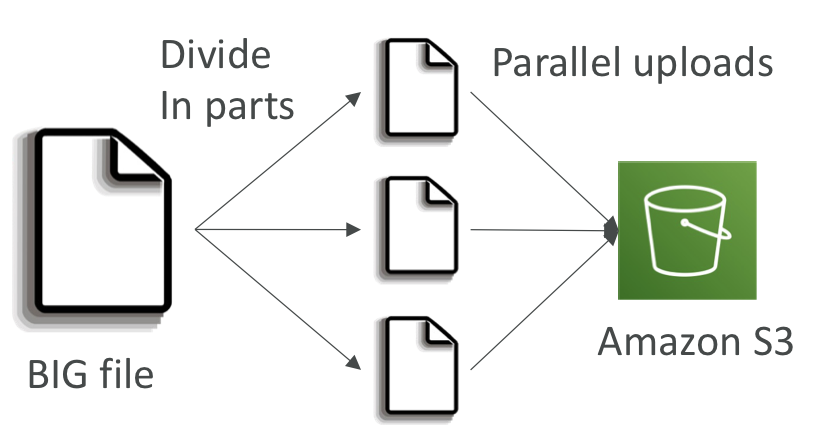
- recommended for files > 100MB, must use for files > 5GB
- 업로드를 병렬화하여 전송 속도를 높여 대역폭을 최대화할 수 있음
- 모든 파트가 업로드되면 자동으로 모든 파트를 다시 합쳐 다시 하나의 큰 파일로 만듦
S3 Transfer Acceleration
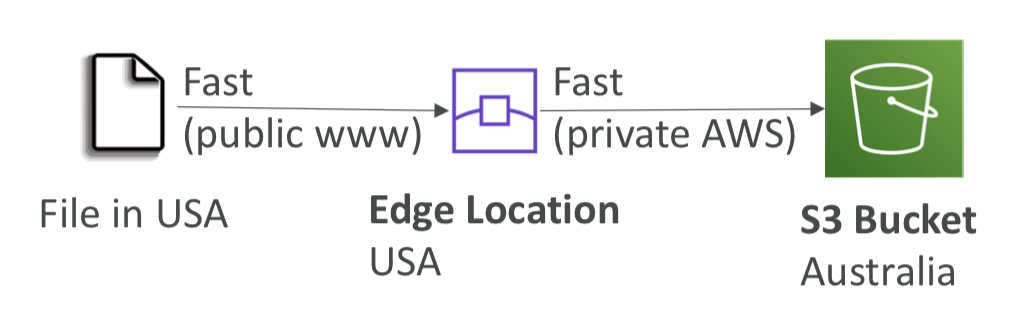
- 파일을 AWS 엣지 로케이션으로 전송하고 해당 데이터를 대상 지역의 S3 버킷으로 전달함
- 엣지 로케이션으로 전송하여 전송 속도를 높임. (엣지 로케이션은 리전보다 더 많음)
- 멀티파트 업로드와 호환됨
S3 Byte-Range Fetches
- 특정 바이트 범위를 요청함으로써 GET을 병렬화하여 수행함.
- 특정 바이트 범위를 가져오는데 실패한 경우에도 더 작은 바이트 범위에서 재시도함. 따라서 실패의 경우에도 복원력이 높음
- 다운로드 속도를 높일 수 있음
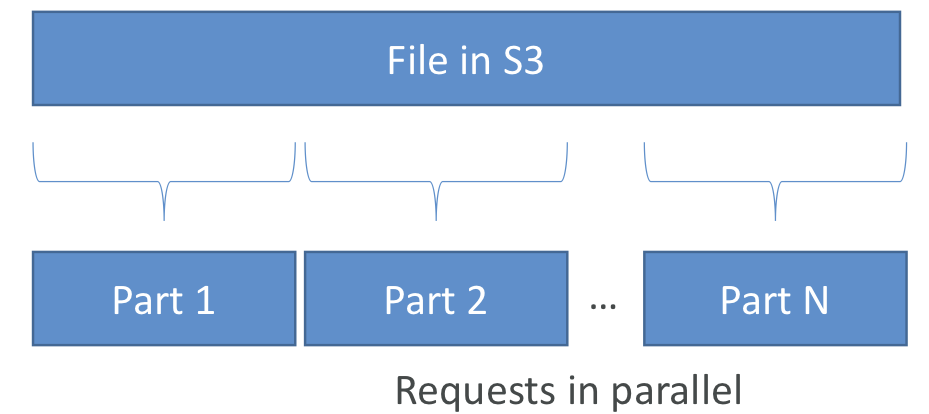
- 파일의 일부만 검색하는 데 사용할 수 있음 (ex. 파일의 header 부분)

S3 Select & Glacier Select
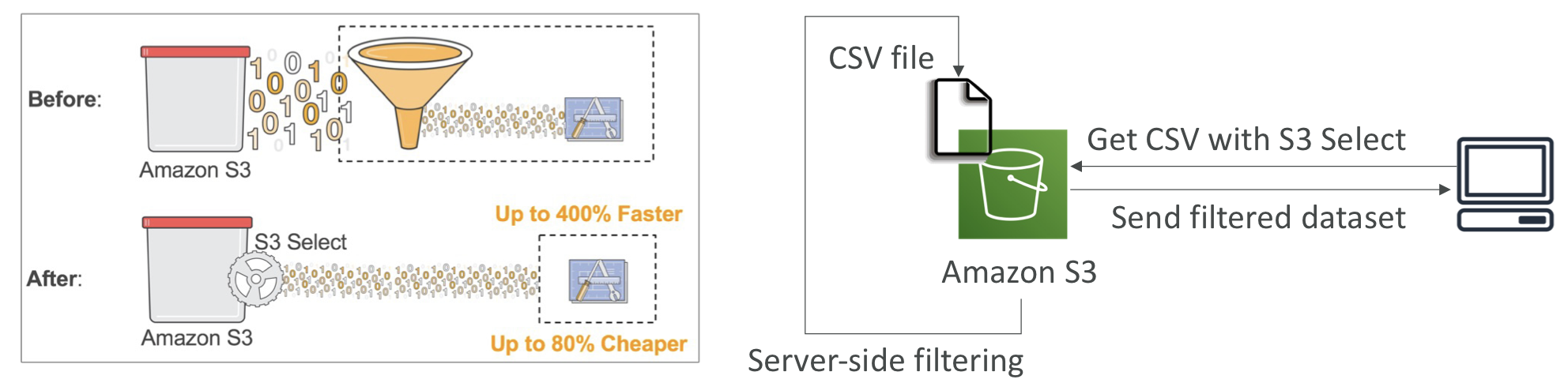
- server-side filteringdmf 통해 SQL을 사용하여 데이터의 일부를 검색할 수 있음
- 간단한 SQL문을 사용하여 행 및 열로 필터링할 수 있음
- 데이터 전송량을 줄이고 클라이언트 측의 CPU 비용을 절감할 수 있음
간단한 필터링에는 S3 Select나 Glacier Select를 추천함.
S3 Batch Operations
- 단일 요청으로 기존 S3 객체에 대한 대량 작업을 수행하는 서비스.
- 객체 메타데이터 및 속성 수정
- S3 버킷 간 객체 복사
- 암호화되지 않은 객체 암호화
- ACL, 태그 수정
- S3 Glacier에서 객체 복원
- Lambda 함수를 호출하여 사용자 지정 작업 수행
- 작업은 객체의 목록, 수행할 작업 및 옵션 매개 변수로 구성됨
- 직접 스크립팅 하지 않고 S3 Batch Operations를 사용하는 이유?
- 재시도 관리
- 진행 상황을 추적
- 작업 완료 알림
- 보고서 생성
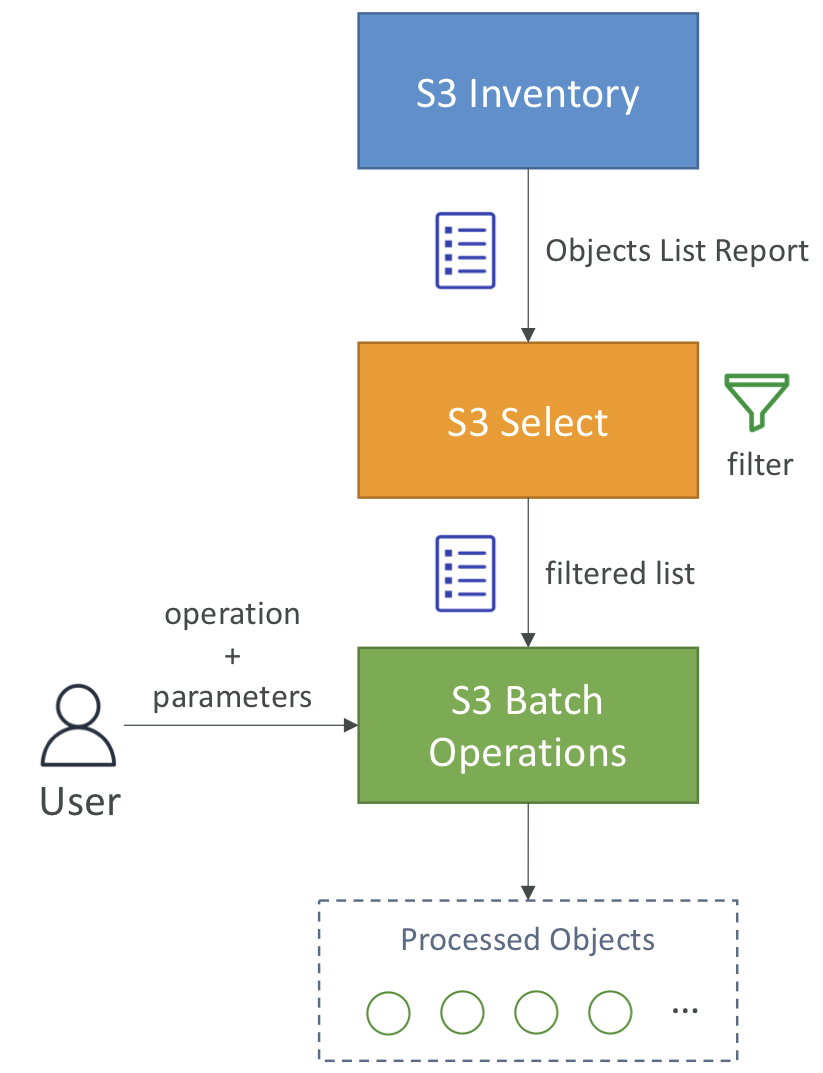
- S3 Inventory를 사용하여 객체 목록을 가져오고 S3 Select를 사용하여 객체를 필터링한 후 S3 Batch Operations에 수행할 작업, 매개 변수와 함께 객체 목록을 전달하면 S3 배치가 작업을 수행하고 객체를 처리한다.
- 사용 사례: S3 Inventory를 사용해 암호화되지 않은 객체를 찾은 다음 S3 Batch Operations를 사용해 한번에 모두 암호화하기

안녕하세요