들어가기에 앞서...
- 본 글은 쿠버네티스 시리즈 중의 하나로, kubernetes 실습을 위한 기본 환경 세팅이 이루어져 있지 않은 분은 시리즈 1편을 확인해주시길 바란다.
- 쿠버네티스 실습 시리즈는 아래 학습 자료를 참고하고 있다.
0. 블로깅 목적
- Namespace란 무엇인지 알고, Namespace 범위와 API 리소스의 관계에 대해 이해한다.
- 클러스터 기본 Namespace를 알고, 다른 Namespace의 서비스에 접근 방법을 이해한다.
- Namespace를 제한하는 방법인 ResourceQuota와 LimitRange를 이해한다.
1. Namespace란 무엇인지 알고, Namespace 범위와 API 리소스의 관계에 대해 이해한다.
1) Namespace란?
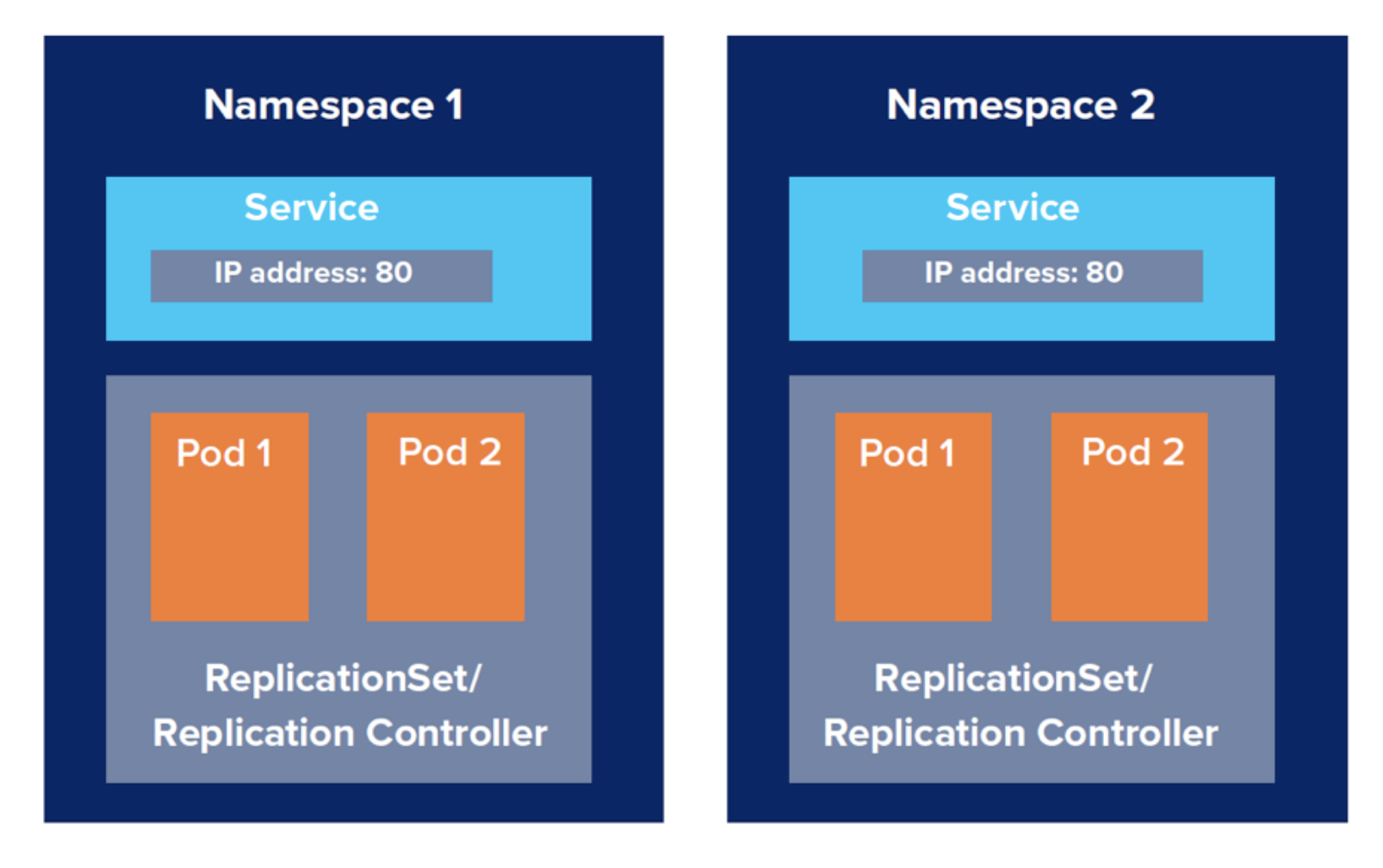
- 리소스를 논리적으로 나누기 위한 방법을 제공하는 것이라 할 수 있다.
- 가령 지금까지 살펴봤던 Pod, Deployment, Service와 같은 여러 오브젝트들을 하나의 Namespace로 그룹핑 해서 함께 관리할 수 있다. (논리적 그룹핑!)
- 사실 이전에 사용했던 label과 labelSelector라는 옵션을 통해서도 그룹핑을 할 수는 있다. 하지만 그것을 포함하는 더 넓은 영역의 기능이 있다고 이해하면 된다.
- Namespace는 쿠버네티스 상의 API 오브젝트를 논리적으로 구분하여 그룹핑한다.
- Namespace는 논리적인 그룹에 대하여 권한 관리, CPU & Memory 등 리소스 제한 등을 할 수 있다.
- Namespace의 단위는 사용자 목적에 맞추어 결정한다. 딱 이렇다할 정답이 있는 게 아니다. 가령 다음의 예시처럼 어떤 논리적 단위로 구분할지를 결정할 수 있는 것이다.
- 팀 단위 Namespace
- 환경 단위 Namespace
- 서비스 단위 Namespace
2) 클러스터 범위 API 리소스 vs Namespace 범위 API 리소스
- Namespace에 속할 수 있는 리소스를 Namespace 범위 API 리소스라고 하고, 속할 수 없는 리소스를 클러스터 범위 API 리소스라고 한다.
- 다른 말로, 해당 API 리소스가 Namespace에 종속적인가 아니면 Namespace에 종속적이지 않고 클러스터 범위에서 사용되는 리소스냐로 구분하는 것이다.
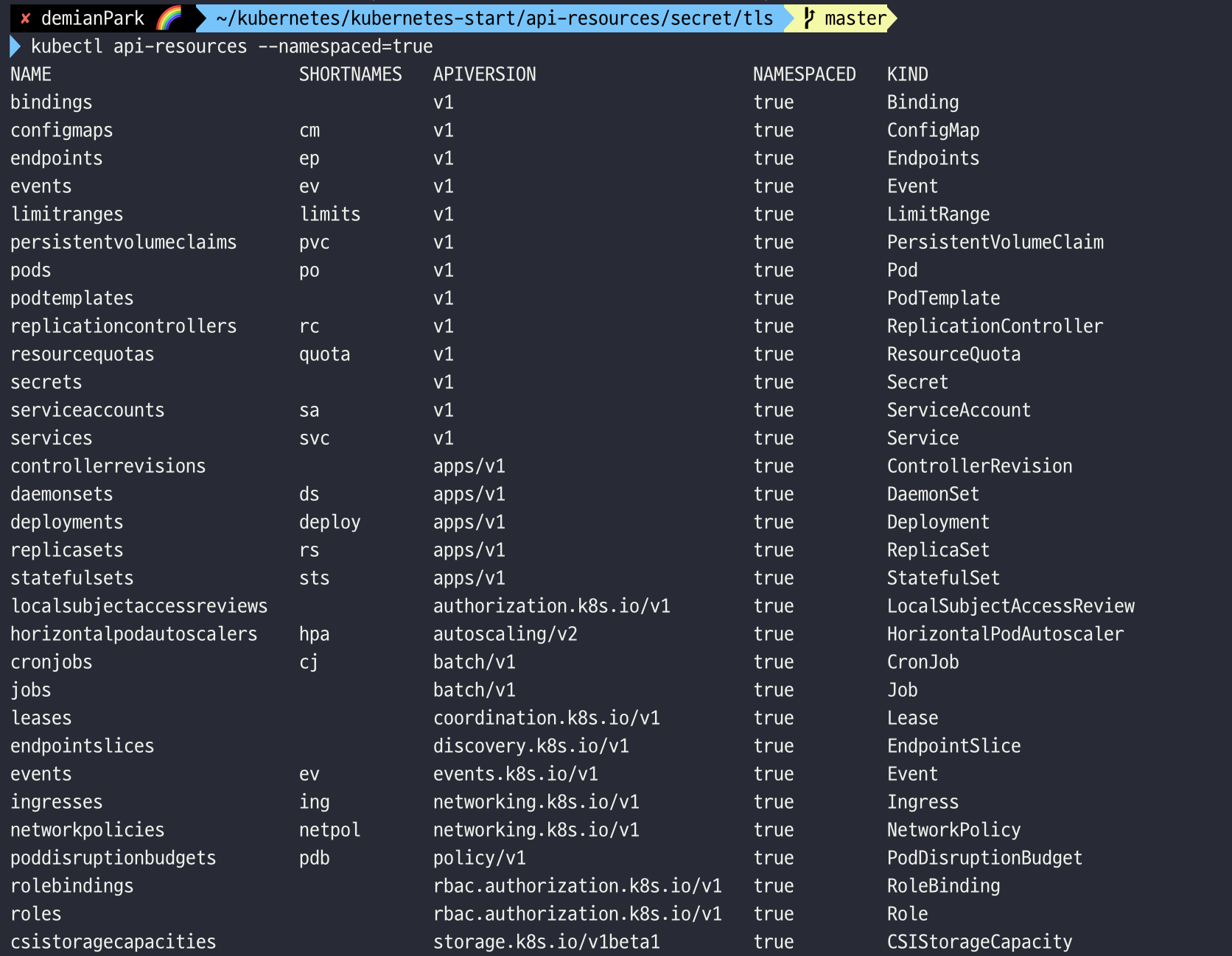
(1) 네임스페이스 범위 API 리소스
$ kubectl api-resources --namespaced=true
- 네임스페이스 범위 API 리소스를 확인할 수 있는 커맨드이다.
- Pod, Deployment, Service, Ingress, Secret, ConfigMap, ServiceAccount, Role, RoleBinding 등이 있다.
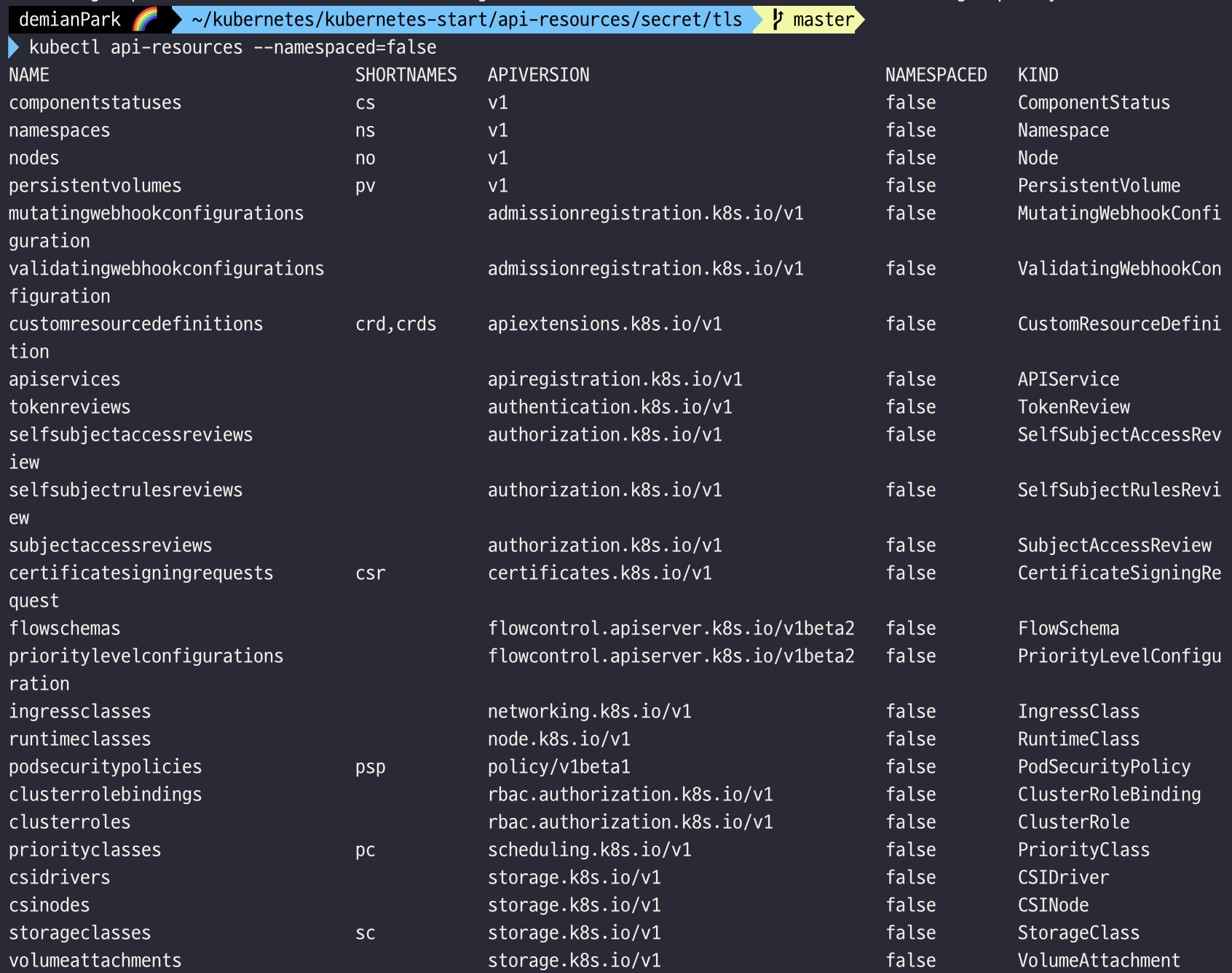
(2) 클러스터 범위 API 리소스
$ kubectl api-resources --namespaced=false
- 클러스터 범위 API 리소스를 확인할 수 있는 커맨드이다.
- Node, Namespace, IngressClass, PriorityClass, ClusterRole, ClusterRoleBinding 등이 있다.
2. 클러스터 기본 Namespace를 알고, 서로 다른 Namespace 서비스 접근 방법을 이해한다.
1) 클러스터 기본 Namespace
- 쿠버네티스 클러스터를 생성하고 나면 기본적으로 만들어져 있는 네임스페이스를 뜻한다.
- 총 4가지가 있다.
- default
- Namespace를 지정하지 않은 경우에 기본적으로 할당되는 Namespace이다.
- 지금까지 사용해왔던 방식이다. (지금까지 Namespace를 지정했던 적은 없었다.)
- kube-system
- 쿠버네티스 시스템에 의해 생성되는 API 오브젝트들을 관리하기 위한 Namespace이다.
- 클러스터 레벨의 관리자 영역의 Namespace라고 이해하면 좋다.
- kube-public
- 클러스터 내 모든 사용자로부터 접근 가능하고 읽을 수 있는 오브젝트들을 관리하기 위한 Namespace이다.
- 사용자가 직접 다루지는 않지만 누구든 접근 가능하기 때문에 주의할 필요는 있다.
- kube-node-lease
- 쿠버네티스 클러스터 내 노드의 연결 정보를 관리하기 위한 Namespace이다.
- 역시 사용자가 직접 다루기보단, 쿠버네티스 자체적으로 컨트롤플레인과 노드간의 연결을 잘 하기 위해서 lease라는 오브젝트를 관리하게 되는데 => 즉 lease를 잘 관리하기 위한 Namespace이다.
2) 다른 Namespace 서비스 접근
(1) Namespace 접근 방식
- 서비스명은 동일한데, Namespace가 다르다면 어떻게 접근할 수 있는지 이해한다.
- 서비스명은 같지만 각기 다른 Namespace로의 접근이 문제가 없도록 하는 2가지 방식이 있다. 바로 FQDN(Fully Qualified Domain Name: 전체 도메인 이름)과 Domain Search 옵션이다.
- FQDN 방식은 경로로 치면 절대 경로로서 모든 체이닝 경로를 기재하는 방식을 의미 한다. 모든 경로를 기재했기 때문에 접근에 문제가 발생할 일이 없다.
- 반면 Domain search는 절대 경로 전부를 적지 않고, 부분적으로만 기재해도 자동으로 search 기능이 체이닝을 다 합쳐서 접근 가능한 경로를 찾아주는 방식이다.
(2) Namespace 접근 예시
- 아래 예시를 보며 이해해보자.
1. $ curl {서비스명}.{네임스페이스명}.svc.cluster.local:{포트} 2. $ curl {서비스명}.{네임스페이스명}.svc:{포트} 3. $ curl {서비스명}.{네임스페이스명}:{포트} 4. $ curl {서비스명}:{포트}
- 1번은 FQDN, 즉 절대경로를 모두 다 적는 방식이다.
- 가령 특별히 Namespace를 지정하지 않고 hello라는 이름의 서비스를 배포하였다면, namespace는 자동으로 default가 된다.
- 만약, curl hello.default.svc.cluster.local:{포트}로 접근한다면 FQDN 방식으로 접근한 것이라 할 수 있다.
- 나머지 2,3,4번은 사실 전부 Domain search가 발동되는 예시라고 할 수 있다. Domain search는 부분만 기재해줘도 내부적으로 자동으로 체이닝을 완성해서 접근을 시켜준다.
- 가령 default 서비스를 배포했다면, curl hello:{포트}만 입력해도 접근이 가능하다. Domain search가 나머지를 자동 완성을 해주기 때문이다.
- 하지만 만약 커스텀 namespace를 a, b 1개씩 만들어 각각에 같은 이름의 service를 배포했다고 해보자. 그럴땐 2,3번처럼 namespace까지 확실하게 기재해줘야한다.
- curl hello.a:{포트}
- curl hello.b.svc:{포트}
- 즉, Domain search 덕에, 같은 서비스명을 가졌더라도 namespace만 잘 체이닝해주면 각각에 접근하는 건 문제가 아니다. 반면 4번처럼 namespace를 체이닝 하지 않는다면, default namespace 말고는 Domain search 옵션이 체이닝 완성을 해주지 못한다.
(3) Namespace 접근 실습
- 실습을 진행한다.
- yml을 준비해보자.
deployment.yml
apiVersion: apps/v1 kind: Deployment metadata: name: hello spec: replicas: 2 selector: matchLabels: app: hello template: metadata: name: hello labels: app: hello spec: containers: - name: nginx image: nginxdemos/hello:plain-text ports: - name: http containerPort: 80 protocol: TCP
- replicas가 2인 hello라는 이름의 nginx Deployment다.
service.yml
apiVersion: v1 kind: Service metadata: name: hello labels: app: hello spec: type: ClusterIP ports: - name: http protocol: TCP port: 8080 targetPort: 80 selector: app: hello
- ClusterIP 타입의 Service이다.
create.sh
kubectl create namespace a kubectl create namespace b kubectl apply -f . -n a kubectl apply -f . -n b
- namespace 정의 및 배포를 위해 미리 만든 쉘 스크립트다.
- 해석:
- 우선 namespace를 a, b 각 1개씩 만든다.
- 현재 디렉토리의 파일들을 모두 apply하는데, -n(namespace) 옵션을 줘서 위에서 만들어둔 a namespace와 b namespace에 각각 한번씩 적용한다는 의미이다.
- 즉 동일한 deploy와 service 객체를 a namespace에도 만들고, b namespace에도 만든다고 보면 된다.
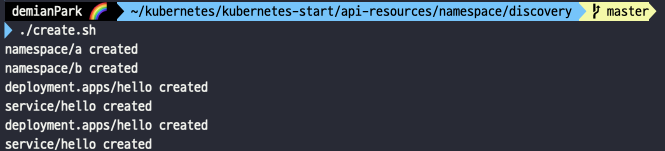
- ./create.sh
- namespace a, b가 만들어졌고, deployment와 service도 그에 맞게 각각 만들어졌다.
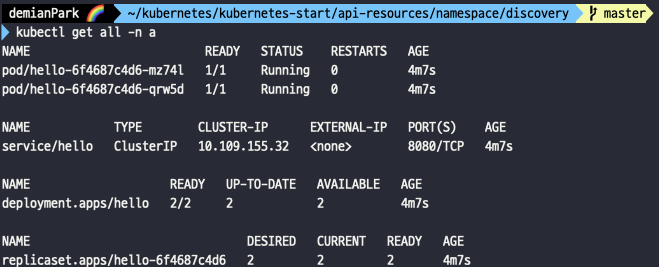
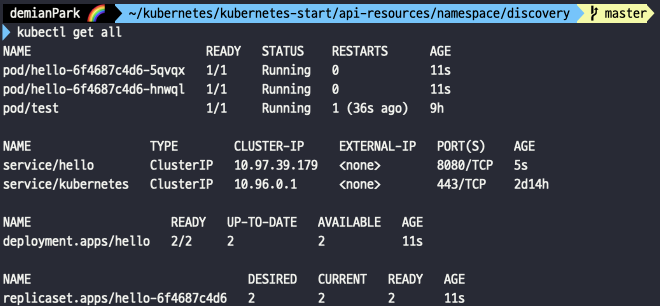
- kubectl get all -n a
- a namespace에 있는 pod, deployment, service, replicaset을 볼 수 있다.
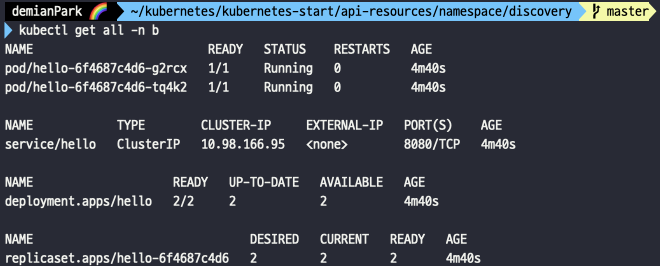
- kubectl get all -n b
- b namespace에서도 pod, deployment, service, replicaset을 볼 수 있다.
- kubectl get all
- namespace 커스텀하게 만들어 그곳에 배포했기때문에, get all 조회에는 아무것도 보이지 않는다. 여기에 조회되는 건 default namespace 서비스 뿐이다.
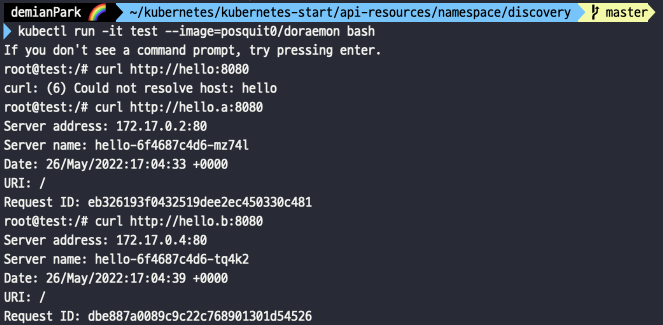
- kubectl run -it test --image=posquit0/doraemon bash
- curl http://hello:8080
- curl http://hello.a:8080
- curl http://hello.b:8080
- 새로운 test 파드를 만들고 쉘환경으로 바로 접속한다.
- 그곳에서 curl로 namespace 접근을 시도해본다.
- 그냥 hello라는 서비스명 만으로는(default namespace에 apply하지 않았기 때문에) 인식을 못하지만, a, b namespace는 생성 및 적용을 해두었기에 접근이 가능하다.
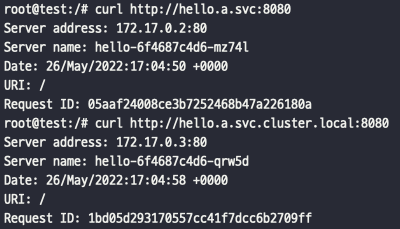
- curl http://hello.a.svc:8080
- curl http://hello.a.svc.cluster.local:8080
- Domain search 옵션을 통해 접근 가능한 것을 알 수 있다.
- FQDN 절대경로 방식으로도 접근이 가능한 것을 알 수 있다.
번외 실습
- kubectl apply -f deployment.yml
- kubectl apply -f service.yml
- default namespace로도 hello 서비스를 배포해보았다.
- kubectl get all
- default로 배포했기 때문에 이제 이 커맨드에도 보인다.
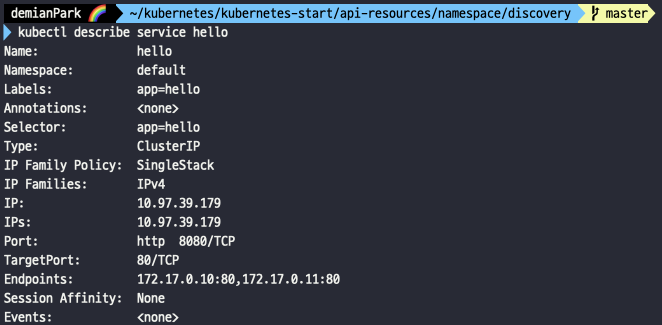
- kubectl describe service hello
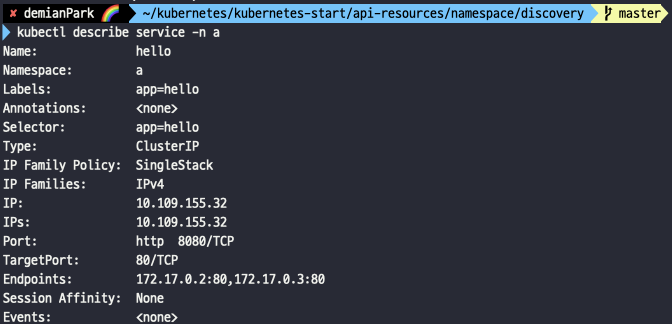
- kubectl describe service -n a
- namespace가 default인 걸 확인할 수 있다.
- 반면 이쪽은 namespace가 a이다.
- 각각 다른 namespace 영역으로 구분되었기 때문에 endpoints들도 당연히 다르다.
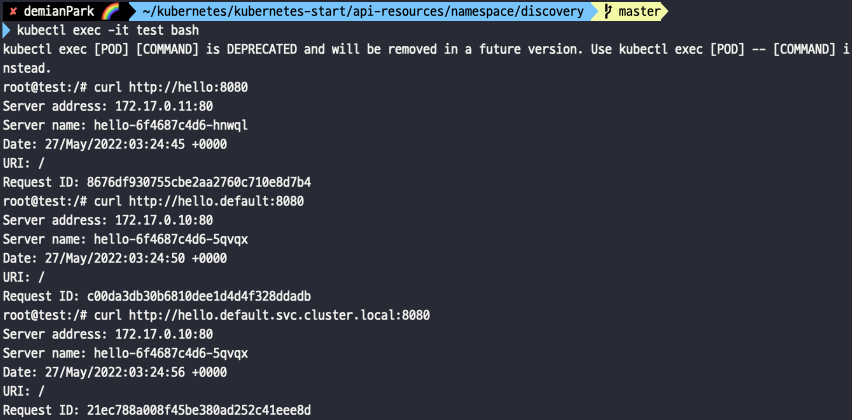
- kubectl exec -it test bash
- curl http://hello:8080
- curl http://hello.default:8080
- curl http://hello.default.svc.cluster.local:8080
- test pod에 접속하여 테스트해보았다.
- Domain search가 잘 작동하고, FQDN도 잘 적용되는 걸 알 수 있다.
- 중요한 포인트는 namespace를 체이닝하지 않으면 Domain search가 default namespace를 자동으로 체이닝해준다는 부분이다.


3. Namespace를 제한하는 방법인 ResourceQuota와 LimitRange를 이해한다.
1) ResourceQuota와 LimitRange란?
- ResourceQuota와 LimitRange 리소스는 Namespace 단위의 자원 사용량 관리할 수 있는 기능을 제공해준다.
(1) ResourceQuota
- Namespace에서 사용할 수 있는 자원 사용량의 합을 제한한다.
- 할당할 수 있는 자원(CPU, Memery, Volume 등)의 총합을 제한할 수 있다다.
- 생성할 수 있는 리소스(Pod, Service, Deployment 등)의 개수를 제한 할 수 있다.
(2) LimitRange
- Namespace에서 Pod 혹은 컨테이너가 만들어질 때, Pod나 컨테이너에 대하여 자원 기본 할당량 설정하거나, 혹은 최대 / 최소 할당량 등을 제한할 수 있다.
2) ResourceQuota와 LimitRange 실습
- 5개의 yml 파일을 준비한다.
namespace.yml
apiVersion: v1 kind: Namespace metadata: name: bakumando
- 적당한 이름의 namespace를 정의해준다.
limit-range.yml
apiVersion: v1 kind: LimitRange metadata: name: limit-range namespace: bakumando spec: limits: - type: Container default: memory: 128Mi cpu: 100m defaultRequest: memory: 64Mi cpu: 50m max: memory: 1Gi cpu: 1000m min: memory: 16Mi cpu: 10m - type: Pod - type: PersistentVolumeClaim max: storage: 1Gi min: storage: 100Mi
- spec limits 아래에 여러 타입(Container, Pod, PersistentVolumeClaim)을 볼 수 있다.
- 즉, 여러 타입마다 각각에 기본 설정과 최소, 최대 제한을 줄 수 있다는 것이다. 기본적으로는 Container 타입에 limit 설정을 많이 한다.
resource-quota.yml
apiVersion: v1 kind: ResourceQuota metadata: name: object-count-quota namespace: bakumando spec: hard: limits.cpu: "5000m" limits.memory: "8Gi" count/pods: 10 count/replicationcontrollers: 10 count/replicasets.apps: 10 count/deployments.apps: 10 count/statefulsets.apps: 10 count/jobs.batch: 3 count/cronjobs.batch: 3 count/services: 5 count/services.nodeports: 0 count/services.loadbalancers: 0 count/configmaps: 10 count/secrets: 10 count/persistentvolumeclaims: 5 count/resourcequotas: 3
- limits.cpu, limits.memory는 해당 Namespace에서 만들 수 있는 cpu, memory의 총량을 뜻한다.
- 나머지는 각 오브젝트 최대 개수를 제한하는 설정이다.
pod.yml
apiVersion: v1 kind: Pod metadata: name: test namespace: bakumando spec: containers: - name: nginx image: nginxdemos/hello:plain-text ports: - name: http containerPort: 80 protocol: TCP
- pod도 namespace 설정을 잘해줘야 한다.
unavailable-pod.yml
apiVersion: v1 kind: Pod metadata: name: unavailable namespace: bakumando spec: containers: - name: nginx image: nginxdemos/hello:plain-text ports: - name: http containerPort: 80 protocol: TCP resources: limits: cpu: 2 memory: 512Mi
- 제한 설정을 넘어가서 이용할 수 없는 pod도 만들어볼 것이다.
- 이름은 unavailable이고, limits에 cpu를 2로 크게 줘보았다.
- kubectl apply -f namespace.yml
- kubectl describe ns bakumando
- namespace를 만들고 조회해 보았다. 아직 ResourceQuota와 LimitRange 부분이 비어있음을 알 수 있다.
- kubectl apply -f limit-range.yml
- kubectl apply -f resource-quota.yml
- ResourceQuota와 LimitRange도 apply 하였다.
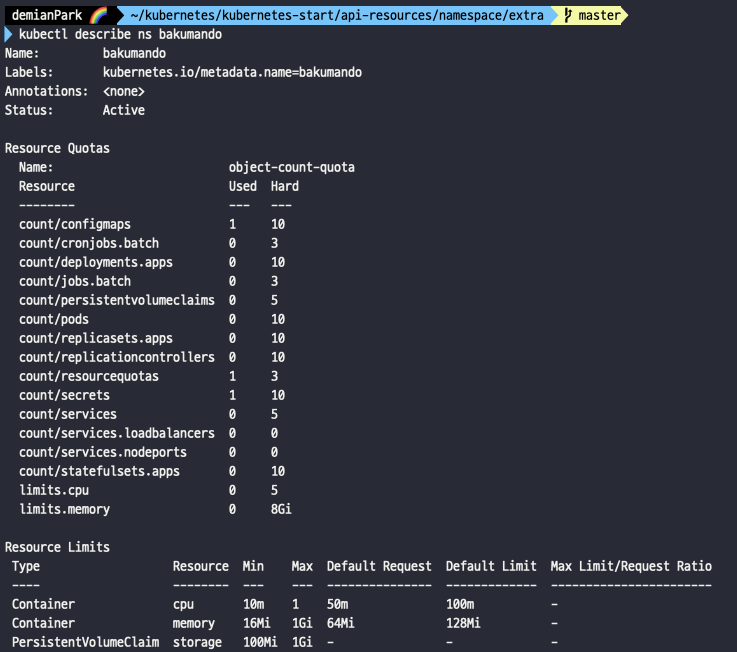
- kubectl describe ns bakumando
- ResourceQuota와 LimitRange가 추가되었다.
- ResourceQuota에 Used는 현재 사용량, Hard는 최대 사용량을 뜻한다.
- LimitRange에 각 타입별로 설정을 볼 수 있다.
- Container 타입은 cpu, memory 별로 기본값, 기본요청값, 최소 최대값을 볼 수 있다.
- PersistentVolumeClaim 타입도 storage 설정 값을 확인할 수 있다.
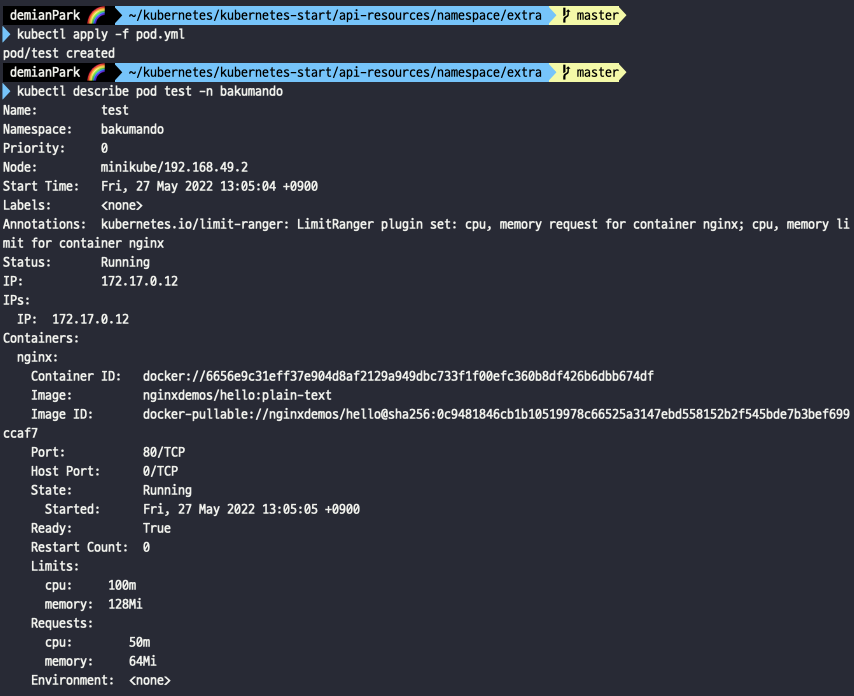
- kubectl apply -f pod.yml
- kubectl describe pod test -n bakumando
- pod를 생성하고, pod를 상세 조회해보았다.
- Limits와 Request 부분에 ResourceQuota와 LimitRange의 설정 값이 들어갔음을 확인할 수 있다.
- kubectl apply -f unavailable-pod.yml
- 최대 cpu는 1인데 2로 지정해서 에러가 났다는 메시지를 볼 수 있다.



그렇게 바쿠만도는 개발에 퐁당 빠지고 말았답니다.