
SQL(Structured Query Language)
데이터 정의 언어 (DDL : Data Definition Language)
데이터베이스, 테이블, 뷰, 인덱스 등의 데이터베이스 개체를 생성/삭제/변경하는 역할
실행 즉시 MySQL에 적용(되돌리는게 불가함)
CREATE (데이터베이스 개체 (테이블, 인덱스, 제약조건 등)의 정의)
DROP (데이터베이스 개체 삭제)
ALTER (데이터베이스 개체 정의 변경)
데이터 조작 언어 (DML : Data Manipulation Language)
데이터를 조작(선택(SELECT), 삽입, 수정, 삭제)하는 데 사용되는 언어.
테이블의 데이터를 변경(입력/수정/삭제)할 때 실제 테이블에 완전히 적용하지 않고, 임시로 적용시키는 것이므로 취소 가능
INSERT INTO (행 데이터 또는 테이블 데이터의 삽입)
UPDATE ~ SET (표 업데이트)
DELETE FROM (테이블에서 특정 행 삭제)
SELECT ~ FROM ~ WHERE (테이블 데이터의 검색 결과 집합의 취득)
데이터 제어 언어 (DCL : Data Control Language)
사용자에게 어떤 권한을 부여하거나 빼앗을 때 주로 사용하는 구문
GRANT (특정 데이터베이스 사용자에게 특정 작업을 수행 권한을 부여)
REVOKE (특정 데이터베이스 이용자로부터 이미 준 권한을 박탈)
SET TRANSACTION (트랜잭션 모드 설정 (동시 트랜잭션 격리 수준 (ISOLATION MODE) 등))
BEGIN (트랜잭션 시작)
COMMIT (트랜잭션의 실행)
ROLLBACK (트랜잭션 취소)
SAVEPOINT (무작위로 롤백 지점을 설정)
LOCK (TABLE 등의 자원을 차지)
[ SQL의 언어적 특성 ]
- SQL은 대소문자를 구분하지 않는다.
(단, 서버 환경이나 DBMS 종류에 따라 데이터베이스 또는 필드명에 대해 대소문자를 구분하기도 한다.) - SQL 명령은 세미콜론(;)으로 끝나야 한다.
- 고유의 값은 따옴표('')로 감싸준다.
SELECT * FROM EMP WHERE NAME = ‘James’; - 주석은 일종의 도움말로, 주석 처리된 문장은 프로그램에서 동작하지 않는다. 한 줄 주석은 문장 앞에 -- 를
붙여서 사용한다. 여러 줄 주석은 /* */ 로 묶는다.
DDL
데이터베이스 생성과 삭제
- CREATE DATABASE 명령문은 새로운 데이터베이스를 생성하는 데 사용된다.
- DROP DATABASE 명령문은 데이터베이스를 삭제하는 데 사용된다. 이 명령을 실행하면 지정된 데이터베이스와 해당 데이터베이스에 포함된 모든 테이블, 뷰 및 데이터가 삭제된다.
CREATE DATABASE database_name;
DROP DATABASE database_name;테이블 생성과 삭제
CREATE TABLE Users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL
);AUTO_INCREMENT
- auto_increment는 주로 숫자형 컬럼에 사용되며, 해당 컬럼의 값을 자동으로 1씩 증가시키는 역할을 한다.
- 레코드를 삽입할 때 해당 컬럼에 값을 지정하지 않으면 데이터베이스 시스템이 자동으로 증가한 값을 할당한다.
- 주로 주요 키(primary key) 역할을 하며, 고유한 값을 갖는 필드에 사용된다.
PRIMARY KEY
- primary key는 데이터베이스 테이블에서 각 레코드를 고유하게 식별하는 데 사용되는 열(또는 열들)이다.
- primary key로 지정된 열은 중복된 값을 허용하지 않으며, NULL 값을 허용하지 않는다.
- 주로 검색 및 조인 작업에서 레코드를 신속하게 식별하기 위해 사용된다.
UNIQUE
SQL에서 사용되는 제약 조건(Constraint) 중 하나로, 특정 열(컬럼)에 있는 모든 값이 고유(unique)하다는 것을 보장한다. 다시 말해, 중복된 값을 가질 수 없다.
CREATE TABLE 테이블명 (
열명 데이터_유형,
FOREIGN KEY (참조_열명) REFERENCES 참조_테이블명(참조_열명)
);
CREATE TABLE Meeting (
meeting_id INT PRIMARY KEY,
meeting_name VARCHAR(255)
);
CREATE TABLE Participants (
participant_id INT PRIMARY KEY,
participant_name VARCHAR(255),
meeting_id INT,
FOREIGN KEY (meeting_id) REFERENCES Meeting(meeting_id) ON DELETE CASCADE
);
REFERENCES
- REFERENCES는 외래 키(Foreign Key)를 정의할 때 사용된다.
- REFERENCES 키워드 다음에는 외래 키가 참조하는 테이블과 해당 테이블에서 참조하려는 열(컬럼)을 지정한다.
- 위 예제에서 "meeting" 테이블의 "id" 열을 참조하는 외래 키를 생성한다는 의미이다.
ON DELETE CASCADE
- ON DELETE CASCADE는 외래 키 관계에서 사용되며, 부모 테이블의 레코드가 삭제될 때 자식 테이블에서 관련된 레코드도 자동으로 삭제되도록 정의한다.
- 즉, 부모 테이블의 행을 삭제하면 해당 부모 행과 관련된 자식 테이블의 모든 행이 함께 삭제된다.
- 이를 통해 데이터의 일관성과 무결성을 유지할 수 있다.
- 위 예제에서 "meeting" 테이블의 "id" 컬럼을 참조하는 외래 키 관계를 만들었고, 이 관계에서 ON DELETE CASCADE를 설정하면 "meeting" 테이블의 행이 삭제될 때 "id"를 참조하는 다른 테이블의 행도 삭제된다.
DML
SELECT문
원하는 데이터를 가져오는 구문
SELECT 열 이름
FROM 테이블 이름
WHERE 조건
GROUP BY
HAVING
ORDER BYWHERE 조건식
컬럼 = '';
컬럼 is null; 컬럼 is not null;
조건 연산자(=, <, >, <=, >=, <>[같지 않다], != 등)
관계 연산자(NOT, AND, OR 등)
BETWEEN ... AND ... / NOT BETWEEN ... AND ... : 특정 범위 내의 값들을 검색 / 밖의 값들을 검색
BETWEEN 10 AND 20 -> 10부터 20 사이의 값
IN( ) / NOT IN( ) : 주어진 목록 안에 있는 값들을 검색 / 없는 값들을 검색
IN(1, 2, 3) -> 값이 1, 2 또는 3인 레코드를 검색
LIKE : 특정 문자열을 검색하는 데 사용
"%"와 "_"와 같은 와일드카드 문자와 함께 사용하여 패턴 매칭을 수행
LIKE 'a%' -> 'a'로 시작하는 모든 문자열을 검색
LIKE '_a%' -> 두 번째 문자가 'a'인 모든 문자열을 검색
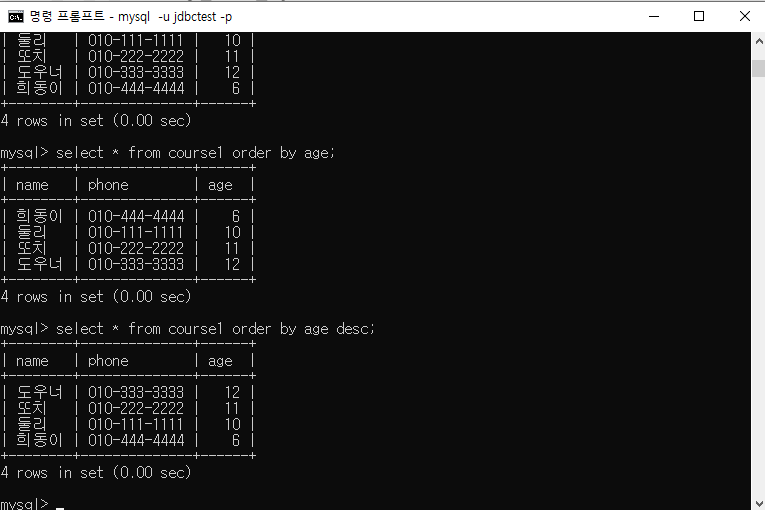
ORDER BY절 원하는 순서대로 정렬하여 출력
기본적으로 오름차순 (ASCENDING) 정렬
내림차순(DESCENDING)으로 정렬하려면 열 이름 뒤에 DESC
ORDER BY에 여러 컬럼을 지정하여 정렬기준을 복수 개 지정 가능
ex)
GROUP BY절
지정된 컬럼을 기준으로 하여 행 단위 그룹으로 묶어주는 역할
집계 함수(Aggregate Function)와 함께 사용
효율적인 데이터 그룹화 (Grouping)
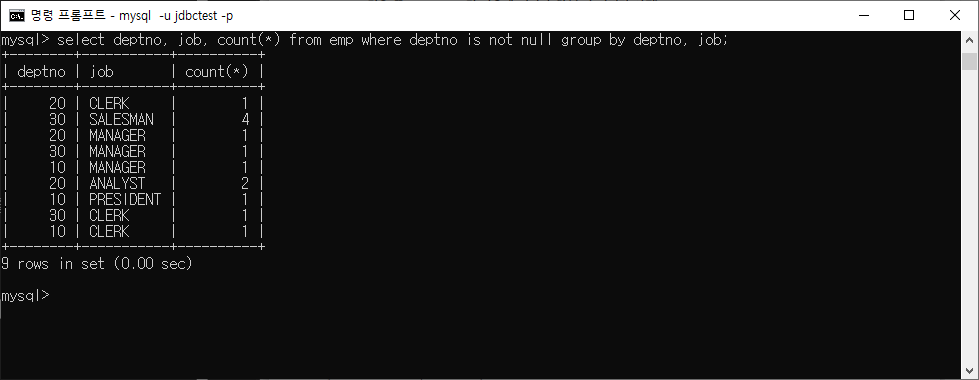
ex)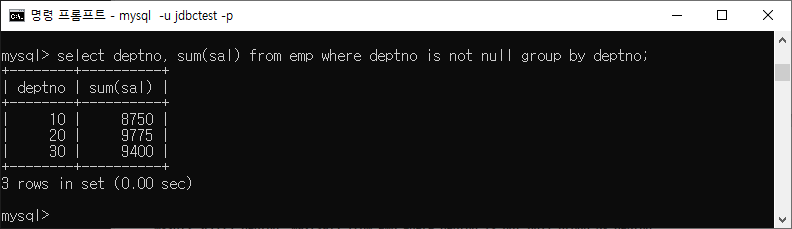 GROUP BY 절을 사용하는 경우에는 SELECT 절에 그룹핑 기준으로 사용된 컬럼외에 다른 컬럼이 왔을 때 오류가 발생하거나 무의미한 결과가 된다. 그러므로 그룹핑 기준으로 사용된 컬럼과 집계 함수만을 사용한다.
GROUP BY 절을 사용하는 경우에는 SELECT 절에 그룹핑 기준으로 사용된 컬럼외에 다른 컬럼이 왔을 때 오류가 발생하거나 무의미한 결과가 된다. 그러므로 그룹핑 기준으로 사용된 컬럼과 집계 함수만을 사용한다.
ex)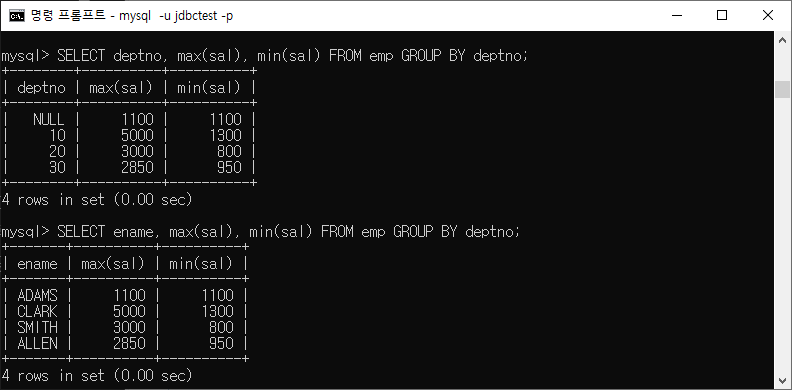
GROUP BY와 함께 사용되는 집계 함수
| 함수명 | 설명 |
|---|---|
| AVG( ) | 평균을 구한다. |
| MIN( ) | 최소값을 구한다. |
| MAX( ) | 최대값을 구한다. |
| COUNT( ) | 행의 개수를 센다. |
| COUNT(DISTINCT) | 행이 개수를 센다.(중복은 1개만) |
| STDEV( ) | 표준편차를 구한다. |
| VAR_SAMP( ) | 분산을 구한다. |
COUNT( ) 함수 활용
- COUNT(*) : 이 형식은 테이블의 모든 행을 세는 데 사용. 즉, 테이블에 있는 전체 레코드 수를 반환
- COUNT(column) : 이 형식은 특정 열의 값이 NULL이 아닌 행을 세는 데 사용. 특정 열의 값을 가진 행의 개수를 반환
- COUNT(DISTINCT column) : 이 형식은 특정 열의 중복되지 않는 값을 가진 행의 개수를 세는 데 사용
ex) GROUP BY와 COUNT( ) 사용 예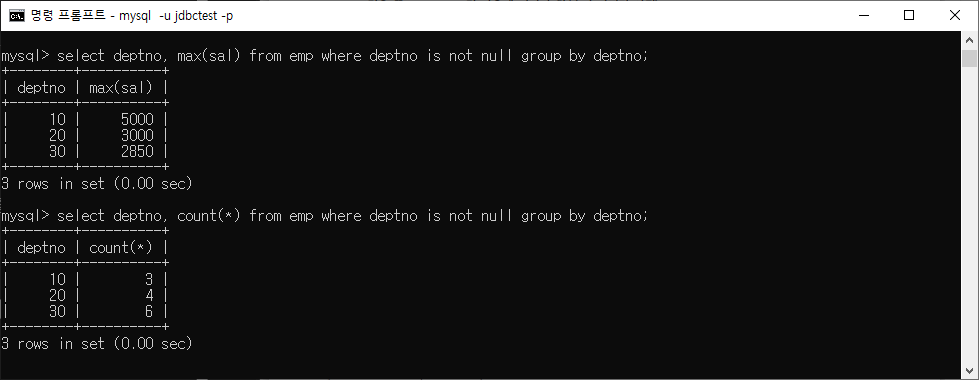
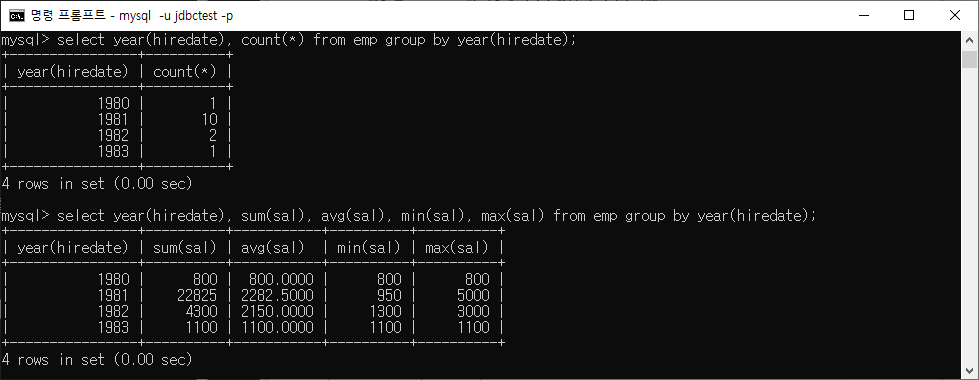
ROLLUP
총합 또는 중간 합계가 필요할 경우 사용
GROUP BY절과 함께 WITH ROLLUP문 사용
분류(groupName) 별로 합계 및 그 총합 구하기
ex) ROLLUP으로 합계 구함. 합계 표기 IFNULL 사용
mysql> select job, sum(sal) as '총 월급'
-> from emp
-> group by job
-> with rollup;
mysql> select ifnull(job, '합계') as '직무', sum(sal) as '급여'
-> from emp
-> group by job
-> with rollup;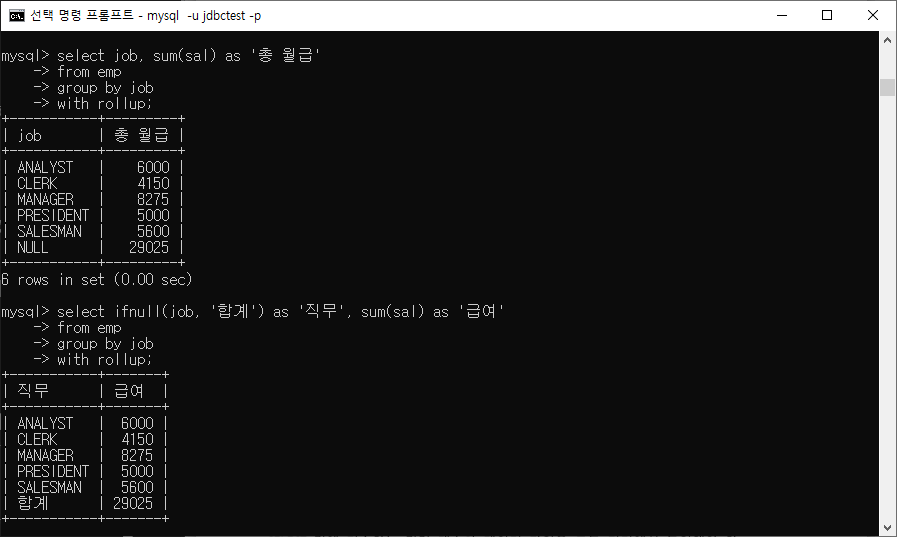 ex) 소합계, 총합계
ex) 소합계, 총합계
mysql> select ifnull(job, '모든 직무 합계'), ifnull(ename, '소합계'), sum(sal) as '급여'
-> from emp
-> group by job, ename
-> with rollup;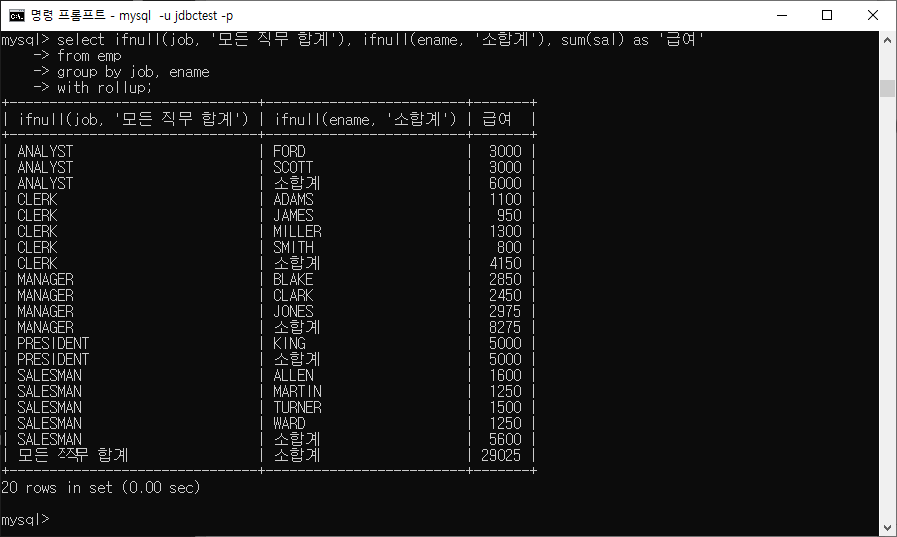
HAVING
WHERE와 비슷한 개념으로 조건 제한하는 것이지만, 집계 함수에 대해서 조건을 제한하는 것.
HAVING절은 꼭 GROUP BY절 다음에 나와야 함(순서 바뀌면 안됨)
ex)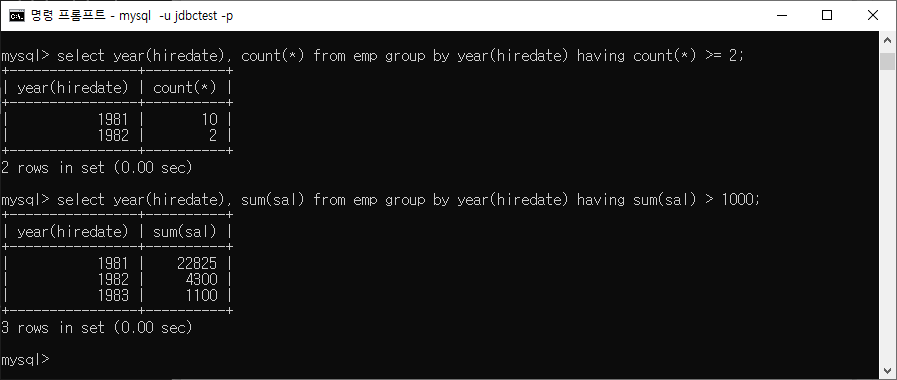
SET Operator
두 개 이상의 쿼리 결과를 하나로 결합시키는 연산자
SELECT 절에 가술하는 컬럼 개수와 데이터 타입은 모든 쿼리에서 동일해야 함
| 유형 | 설명 | 도식 |
|---|---|---|
| UNION | 양쪽 쿼리 결과를 모두 포함(중복 결과는 1번만 표현) |  |
| UNION ALL | 양쪽 쿼리 결과를 모두 포함(중복 결과도 모두 표현) | 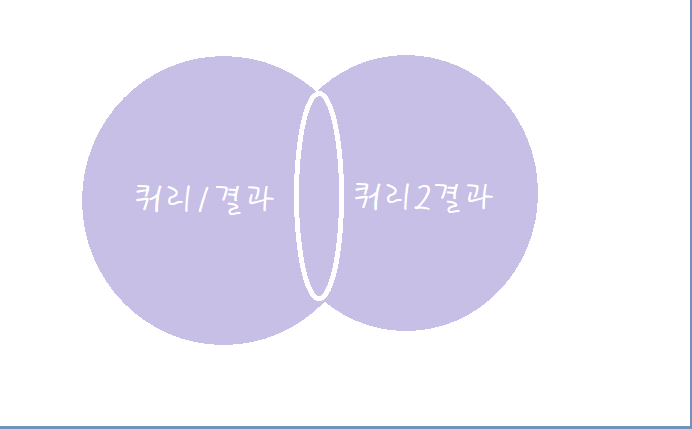 |
| INTERSECT | 양쪽 쿼리 결과에 모두 포함되는 행만 표현 | 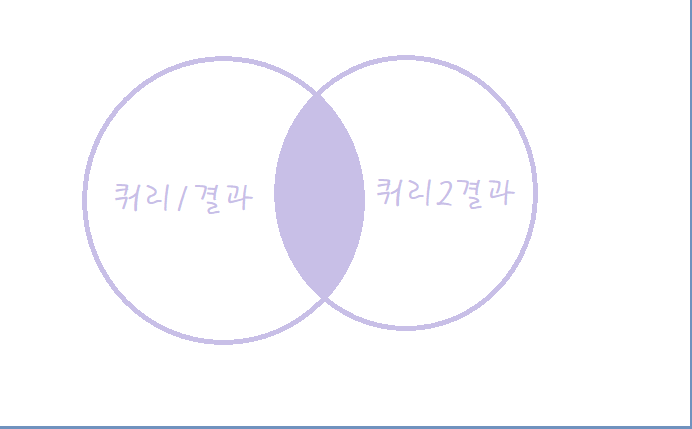 |
| MINUS | 쿼리1 결과에만 포함되고 쿼리2 결과에는 포함되지 않는 행만 표현 |  |
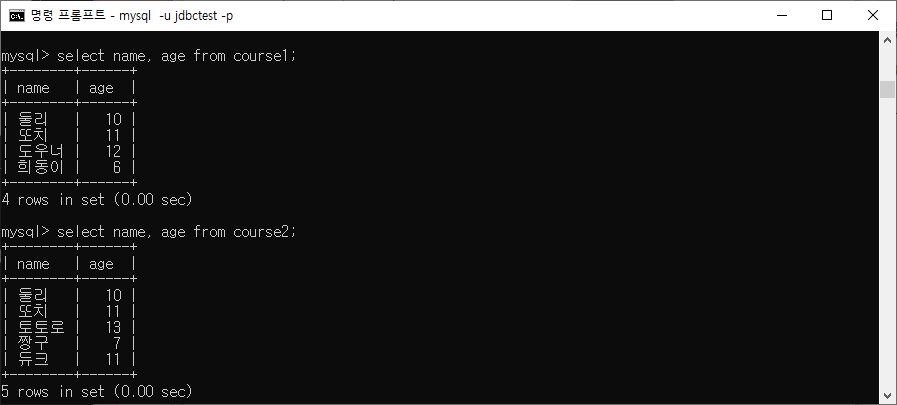
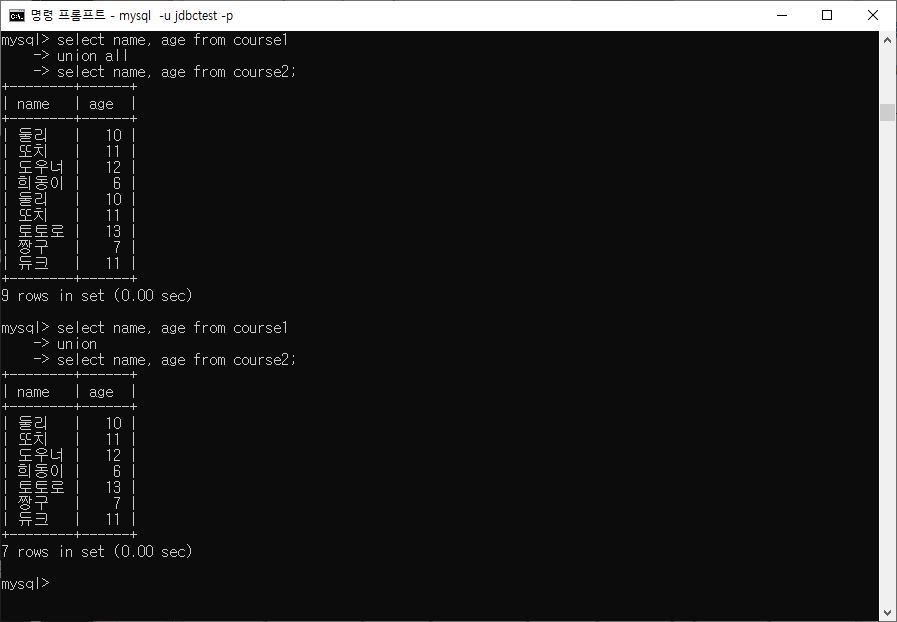
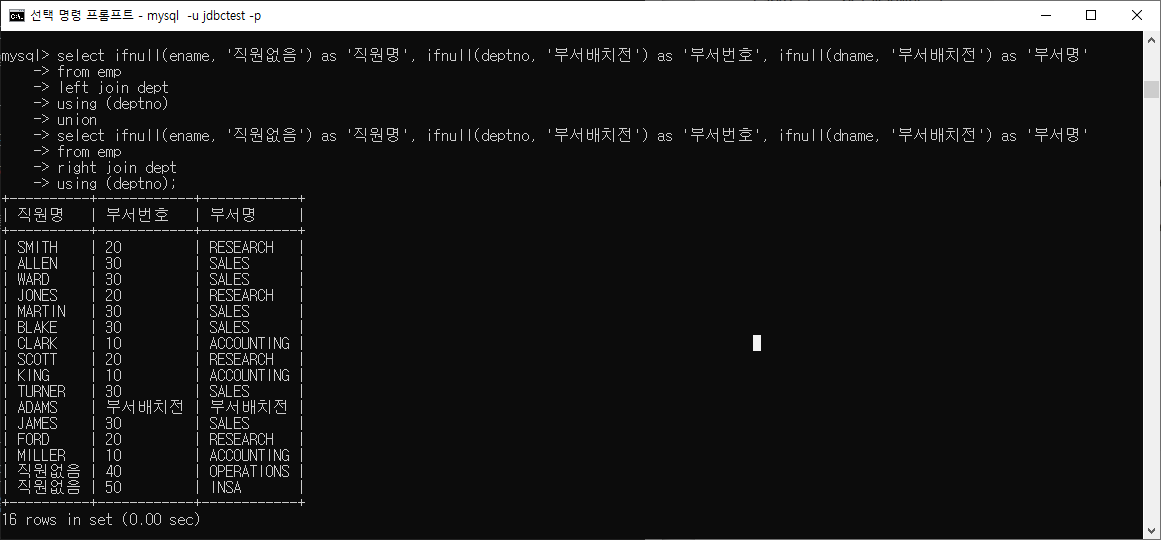
UNION/UNION ALL
두 쿼리의 결과를 행으로 합치는 것(세로로 묶는다)
SELECT column1 FROM table1
UNION [ALL]
SELECT column2 FROM table2;ex) 첫번째 이미지의 내용을 union all/union을 이용해 합친게 두번째 이미지의 내용
INTERSECT
INTERSECT 연산자는 두 개 이상의 SELECT 문의 결과 집합 간에 교집합을 구한다. 중복된 결과를 제거하고 공통된 값을 반환한다.
SELECT column1 FROM table1
INTERSECT
SELECT column2 FROM table2;MINUS
MINUS 연산자는 첫 번째 SELECT 문의 결과에서 두 번째 SELECT 문의 결과를 뺀다. 즉, 첫 번째 집합에서 두 번째 집합에는 없는 데이터를 반환한다.
SELECT column1 FROM table1
MINUS
SELECT column2 FROM table2;JOIN
두 개 이상의 테이블을 가로로 묶어서 하나의 결과 집합으로 만들어 내는 것
종류 : INNER JOIN, OUTER JOIN, CROSS JOIN, SELF JOIN
데이터베이스의 테이블은
중복과 공간 낭비를 피하고 데이터의 무결성을 위해서 여러 개의 테이블로 분리하여 저장.
분리된 테이블들은 서로 관계(Relation)를 가짐.
1대 다 관계가 보편적.
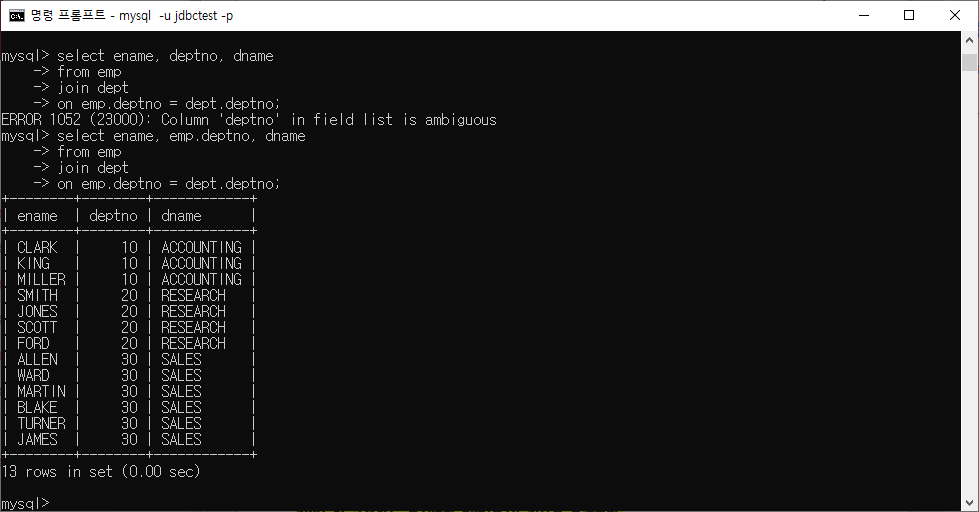
INNER JOIN
INNER JOIN은 관계형 데이터베이스에서 두 개 이상의 테이블을 결합하고 특정 조건을 충족하는 행만 선택하는 데 사용되는 SQL 명령문이다. 이 조인 유형은 조인 조건을 만족하는 행만 결과 집합에 포함되므로 관련된 두 테이블 간의 공통된 데이터만 반환된다.
SELECT
column1, column2, ...
FROM
table1
INNER JOIN
table2 ON table1.column_name = table2.column_name;
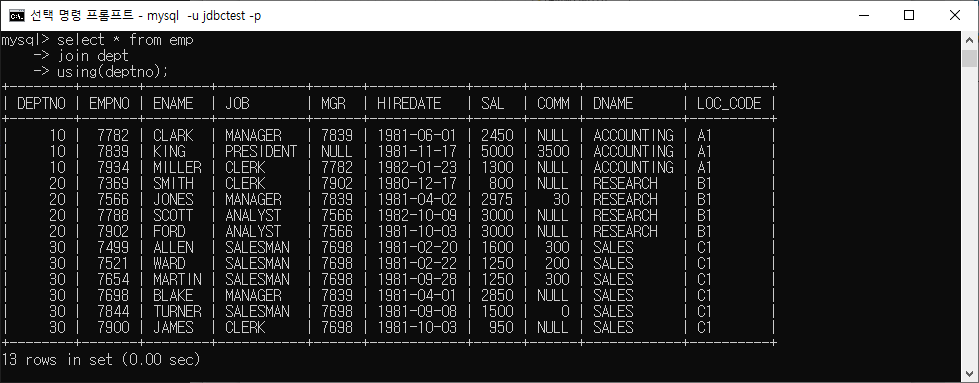
INNER JOIN에서 USING 절은 두 개의 테이블 간에 공통 열(필드)의 이름이 같을 때 사용되는 조인 방법 중 하나이다. 이 절을 사용하면 조인 조건을 명시적으로 지정하지 않고도 공통 열을 기반으로 두 테이블을 결합할 수 있다.
ex) 두 개의 테이블 orders와 customers가 있다. 이 두 테이블은 고객 정보와 주문 정보를 저장하고 있으며, customer_id 열이 두 테이블 간에 공통 열이다. 이때 USING을 사용하여 INNER JOIN을 수행하면 다음과 같이 될 수 있다 :
SELECT *
FROM orders
INNER JOIN customers
USING (customer_id);ex) on 사용 예와 using 사용 예
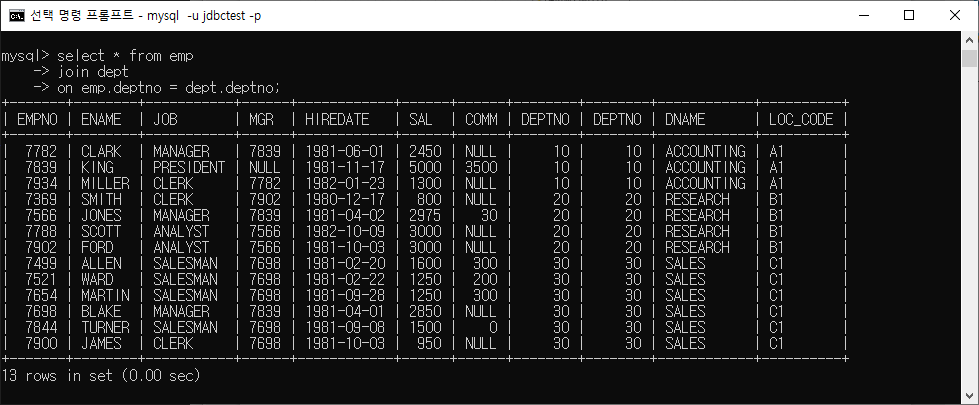
ex) 컬럼으로 JOIN할 때 클래스.컬럼명으로 표기해줘야 한다.
USING을 이용할 경우 컬럼명만 표기해도 된다.

NATURAL [INNER] JOIN
NATURAL JOIN은 SQL에서 사용되는 조인 유형 중 하나로, 두 테이블 간에 공통 열 이름을 사용하여 조인하는 방식이다. 이 조인은 특별한 조인 조건을 명시적으로 지정하지 않고, 두 테이블 간에 열 이름이 동일한 경우 자동으로 조인을 수행한다.
NATURAL JOIN의 기본 동작은 다음과 같다 :
- 두 테이블 간에 공통 열 이름을 찾는다.
- 이 공통 열 이름을 기반으로 두 테이블을 조인한다.
- 공통 열의 값이 일치하는 행만 반환한다.
ex) 두 개의 테이블 employees와 departments가 있다고 가정
employees
+----+--------+---------+
| ID | Name | DeptID |
+----+--------+---------+
| 1 | Alice | 101 |
| 2 | Bob | 102 |
| 3 | Carol | 101 |
+----+--------+---------+
departments
+-------+----------+
| DeptID | DeptName |
+-------+----------+
| 101 | HR |
| 102 | Finance |
+-------+----------+
SELECT *
FROM employees
NATURAL JOIN departments;+----+-------+--------+----------+
| ID | Name | DeptID | DeptName |
+----+-------+--------+----------+
| 1 | Alice | 101 | HR |
| 2 | Bob | 102 | Finance |
| 3 | Carol | 101 | HR |
+----+-------+--------+----------+
OUTER JOIN
-
LEFT OUTER JOIN 또는 LEFT JOIN : 왼쪽 테이블의 모든 행을 포함하고 오른쪽 테이블과 일치하는 행을 포함한다. 오른쪽 테이블의 일치하지 않는 행은 NULL 값으로 표시된다.
-
RIGHT OUTER JOIN 또는 RIGHT JOIN : 왼쪽 테이블과 오른쪽 테이블의 역할이 LEFT JOIN과 정반대입니다. 오른쪽 테이블의 모든 행을 포함하고 왼쪽 테이블과 일치하는 행을 포함한다. 왼쪽 테이블의 일치하지 않는 행은 NULL 값으로 표시된다.
-
FULL OUTER JOIN : 왼쪽 테이블과 오른쪽 테이블의 모든 행을 포함하며, 서로 일치하지 않는 행은 NULL 값으로 표시된다.
SELECT * FROM 테이블1
LEFT/RIGHT/FULL [OUTER] JOIN 테이블2 ON 테이블1.열 = 테이블2.열;ex)
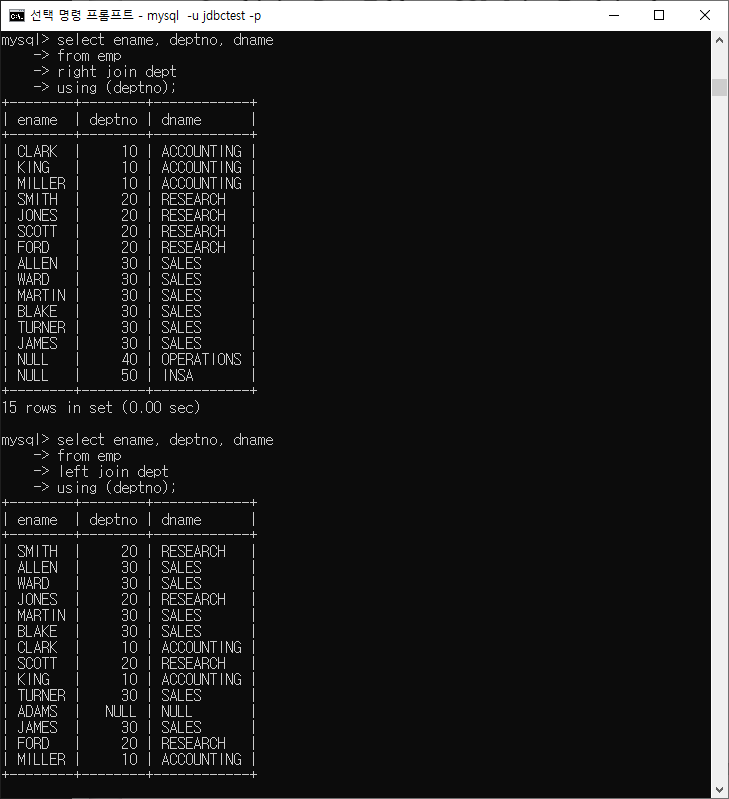
CROSS JOIN
CROSS JOIN은 두 개 이상의 테이블을 조합하여 모든 가능한 조합을 만들어낸다. 다른 조인 유형과 달리 조인 조건이 필요하지 않으며, 간단히 모든 행을 결합한다. 이로 인해 CROSS JOIN은 주로 작은 테이블의 모든 행을 큰 테이블의 모든 행과 결합하는 데 사용된다.
SELECT * FROM table1
CROSS JOIN table2;SELF JOIN
Self Join은 SQL에서 자체 테이블 내에서 조인을 수행하는 것을 의미한다. 이것은 하나의 테이블에 있는 데이터를 다른 테이블처럼 취급하여 데이터를 결합하는 데 사용된다. Self Join은 특히 계층 구조 데이터를 다룰 때 유용하다.
SELECT A.column1, B.column2
FROM table AS A, table AS B
WHERE A.common_column = B.common_column;ex)
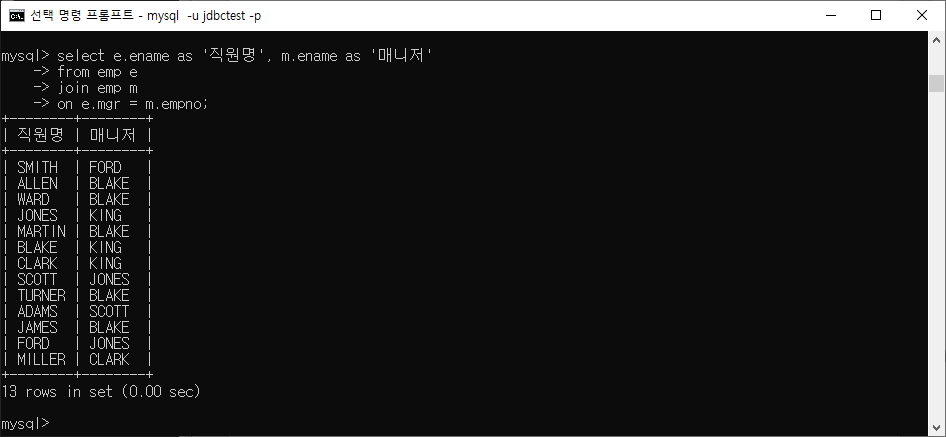
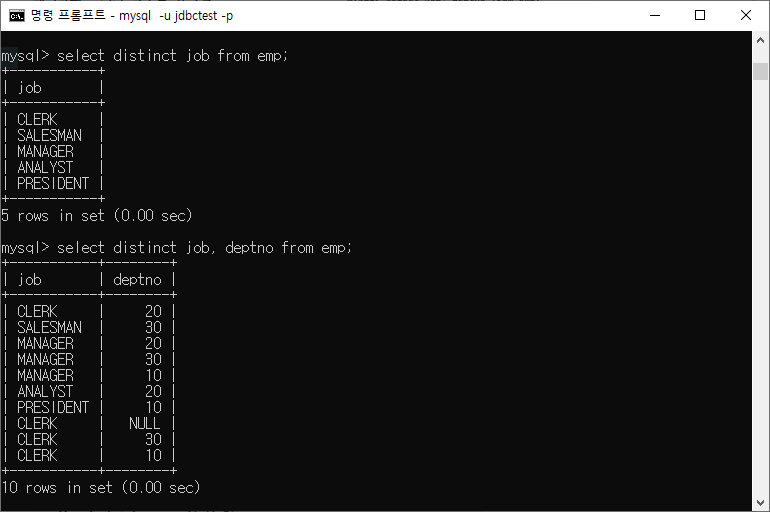
DISTINCT
중복된 것은 1개씩만 보여주면서 출력
ex)
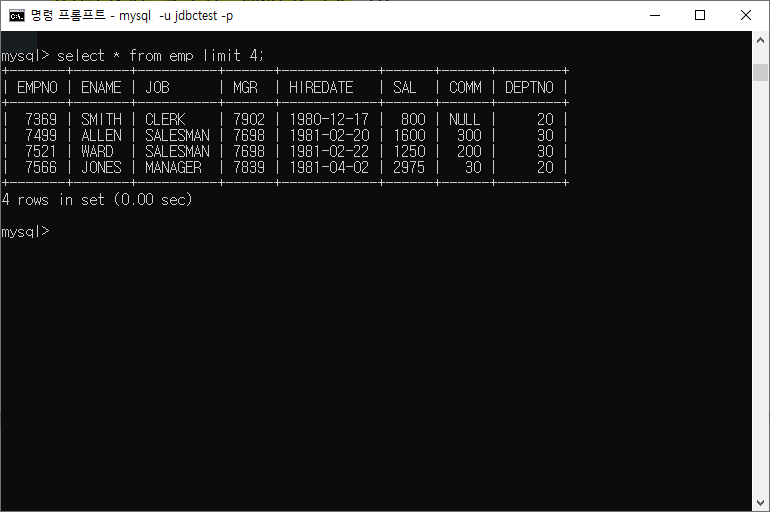
LIMIT N구문
출력하는 개수를 제한
ex)
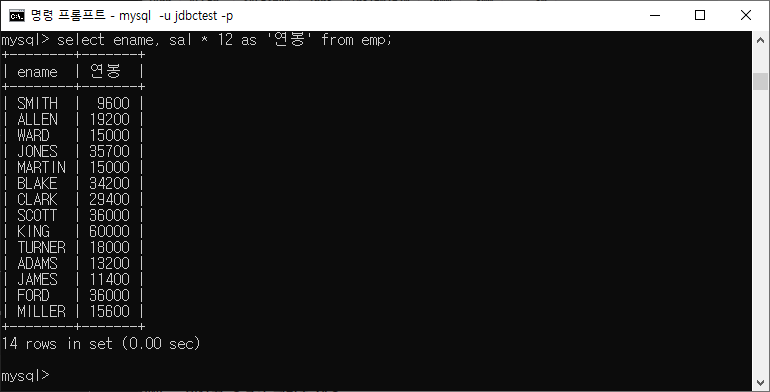
as 사용
ex)
INSERT문(데이터의 삽입)
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);INSERT INTO ... SELECT 문은 하나의 테이블에서 데이터를 선택하여 다른 테이블로 복사하거나 이동할 때 사용하는 SQL 문이다.
INSERT INTO target_table (column1, column2, column3, ...)
SELECT source_column1, source_column2, source_column3, ...
FROM source_table
WHERE condition;UPDATE문(데이터의 수정)
기존에 입력되어 있는 값 변경하는 구문
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;DELETE문(데이터의 삭제)
DELETE FROM table_name WHERE condition;테이블을 삭제하는 경우의 속도 비교
- DML문인 DELETE는 트랜잭션 로그 기록 작업 때문에 삭제 느림
- DDL문인 DROP과 TRUNCATE문은 트랜잭션 없어 빠름
- 테이블 자체가 필요 없을 경우에는 DROP 으로 삭제
- 테이블의 구조는 남겨놓고 싶다면 TRUNCATE로 삭제하는 것이 효율적
MYSQL 내장 함수
숫자 관련 함수
| 함수 | 기능 |
|---|---|
| ABS(숫자) | 절대값 출력 |
| CEILING(숫자) | 값보다 큰 정수 중 가장 작은 수 |
| FLOOR(숫자) | 값보다 작은 정수 중 가장 큰 수 (실수를 무조건 버림(음수일 경우는 제외)) |
| ROUND(숫자) | 숫자를 소수점 이하 자릿수에서 반올림 (자릿수는 양수, 0, 음수) |
| TRUNCATE(숫자) | 숫자를 소수점 이하 자릿수에서 버림 |
| POW(X, Y) or POWER(X,Y) | X의 Y승 |
| MOD(분자, 분모) | 분자를 분모로 나눈 나머지를 구한다. (%연산자와 같음) |
| GREATEST(숫자1, 숫자2, 숫자3 …) | 주어진 수 중 제일 큰 수 리턴 |
| LEAST(숫자2, 숫자2, 숫자3 …) | 주어진 수 중 제일 작은 수 리턴 |
| format(숫자, 소수점이하 자리수) | 주어진 숫자에 천 단위 쉼표 구분과 소숫점 이하의 자리수 설정 |
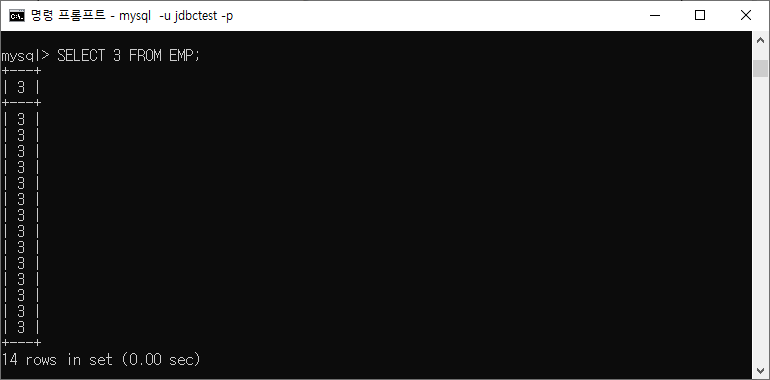
ex) emp row의 숫자만큼 3이 찍힌다
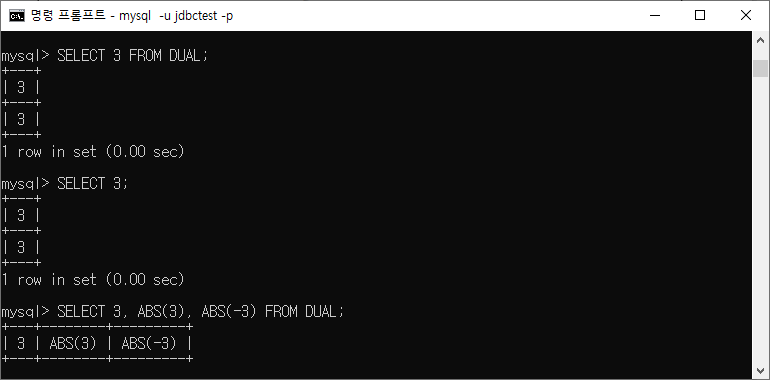
ex) dummy table, DUAL
문자 관련 함수
| 함수 | 기능 |
|---|---|
| ASCII(문자) | 문자의 아스키 코드값 리턴 |
| CONCAT(‘문자열1’,’문자열2’,’문자열3’,…) | 문자열들을 이어준다. |
| CONCAT_WS(‘구분자’,‘문자열1’,’문자열2’,’문자열3’,…) | 문자열 구분자와 함께 문자열을 이어준다. |
| INSERT(‘문자열’,’시작위치’,’길이’,’새로운 문자열’) | 문자열의 시작위치부터 길이만큼 새로운 문자열로 대치 |
| REPLACE(‘문자열’,’기존문자열’,’바뀔문자열’) | 문자열 중 기존 문자열을 바뀔 문자열로 바꾼다. |
| INSTR(‘문자열’,’찾는문자열’) | 문자열 중 찾는 문자열의 위치값을 출력 |
| MID(‘문자열’,시작위치, 개수) | 문자열 중 시작위치부터 개수만큼 출력 |
| SUBSTRING(‘문자열’,시작위치,개수) | 문자열 중 시작위치부터 개수만큼 출력 |
| LTRIM(‘문자열’) | 문자열 중 왼쪽의 공백을 없앤다. |
| RTRIM(‘문자열’) | 문자열 중 오른쪽의 공백을 없앤다. |
| TRIM(‘문자열’) | 양쪽 모두의 공백을 없앤다. |
| LCASE(‘문자열’) or LOWER(‘문자열’) | 소문자로 바꾼다. |
| UCASE(‘문자열’) or UPPER(‘문자열’) | 대문자로 바꾼다. |
| REVERSE(‘문자열’) | 문자열을 반대로 나열한다. |
| LEFT(‘문자열’, 개수) | 문자열 중 왼쪽에서 개수만큼 추출 |
| RIGHT(‘문자열’, 개수) | 문자열 중 오른쪽에서 개수만큼 추출 |
| CHAR_LENGTH(‘문자열’ ) | 문자의 개수 반환 |
| LENGTH(‘문자열’) | 할당된 Byte 수 반환 |
날짜 관련 함수
| 함수 | 기능 |
|---|---|
| NOW(), SYSDATE(), CURRENT_TIMESTAMP() | 현재 날짜와 시간 출력 |
| CURDATE(), CURRENT_DATE() | 현재 날짜 출력 |
| CURTIME(), CURRENT_TIME() | 현재 시간 출력 |
| DATE_ADD(날짜, 기준값) | 날짜에서 기준 값만큼 더한다. |
| DATE_SUB(날짜, 기준값) | 날짜에서 기준 값만큼 뺀다. |
| YEAR(날짜) | 날짜의 연도 출력 |
| MONTH(날짜) | 날짜의 월 출력 |
| MONTHNAME(날짜) | 날짜의 월을 영어로 출력 |
| DAYNAME(날짜) | 날짜의 요일을 영어로 출력 |
| DAYOFMONTH(날짜) | 날짜의 월별 일자 출력 |
| DAYOFWEEK(날짜) | 날짜의 주별 일자 출력 |
| WEEKDAY(날짜) | 날짜의 주별 일자 출력 |
| DAYOFYEAR(날짜) | 일년을 기준으로한 날짜까지의 날 수 |
| WEEK(날짜) | 일년 중 몇 번째 주 |
| FROM_DAYS(날짜) | 숫자 -> 날짜 |
| TO_DAYS(날짜) | 날짜 -> 숫자 |
| DATE_FORMAT(날짜,’형식’) | 날짜를 형식에 맞게 출력 |
| DATEDIFF(날짜1, 날짜2) | 날짜1과 날짜2의 일자 수 차이 출력 |
| TIMESTAMPDIFF(시간 간격, 날짜1, 날짜2) | 두 날짜의 차이를 시간 간격 단위로 표시 |
-- DATE_ADD 예시
select date_add(curdate(), interval 10 day);
-- DATE_FORMAT 예시
select date_format(now(), '%Y년 %m월 %d일 %h시 %i분');
-- TIMESTAMPDIFF 예시
TIMESTAMPDIFF(interval, datetime_expr1, datetime_expr2) --형식
SELECT TIMESTAMPDIFF(DAY, '2023-08-01', '2023-08-10'); -- 결과: 9FORMAT
| FORMAT | 출력 |
|---|---|
| %M | 월(January, Febuary...) |
| %m | 월(01, 02, 03...) |
| %W | 요일(Sunday, Monday...) |
| %D | 월(1st, 2nd...) |
| %Y | 연도(1999, 2000, 2001...) |
| %y | 연도(99, 00, 01...) |
| %H | 시(00, 01, 24) 24시간 형태 |
| %h | 시(01, 02, 12) 12시간 형태 |
| %I(대문자 아이) | 시(01, 02, 12) 12시간 형태 |
| %l(소문자 엘) | 시(1, 2, 12) 12시간 형태 |
| %i | 분(00, 01, 59) |
| %r | hh:mm:ss AM/PM |
| %T | hh:mm:ss |
| %d | 일(00, 01, 02) |
| %e | 일(0, 1, 2) |
| %c | 월(1, 2, 3) |
| %b | 월(Jan, Feb...) |
논리 관련 함수
| 함수 | 기능 |
|---|---|
| IF(논리식, 참일때 값, 거짓일 때 값) | 논리식이 참이면 참일 때 값을 출력하고 거짓이면 거짓일 때 값을 출력 |
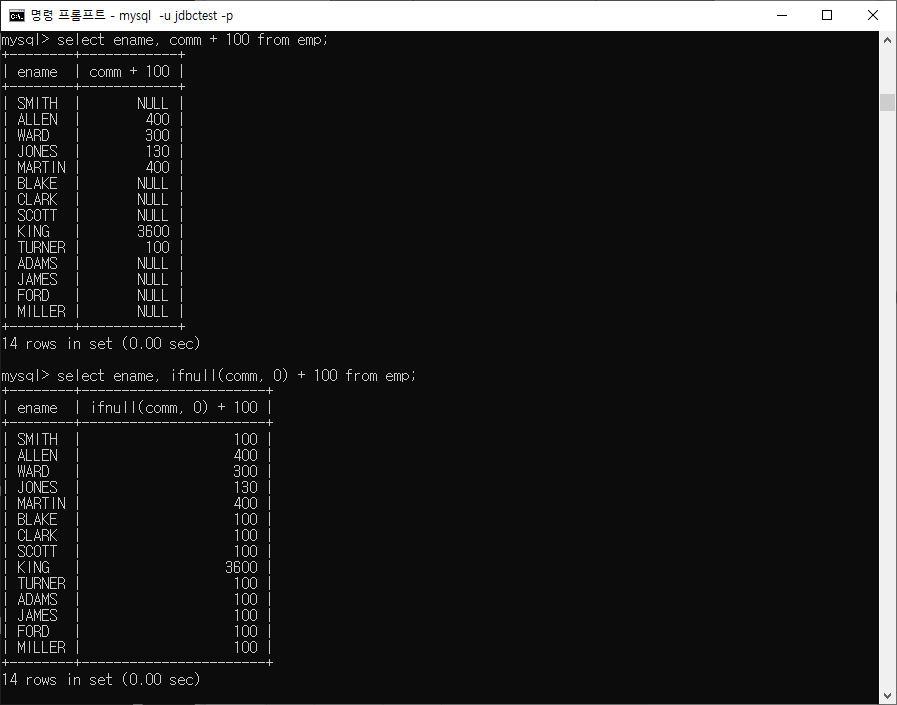
| IFNULL(값1, 값2) | 값1이 NULL이면 값2로 대치하고 그렇지 않으면 값1을 출력 |
| CASE |
|---|
| CASE value WHEN compare_value THEN result [WHEN compare_value THEN result ...] [ELSE result] END |
| CASE WHEN condition THEN result [WHEN condition THEN result ...] [ELSE result] END |
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE else_result
ENDex) IFNULL( )활용
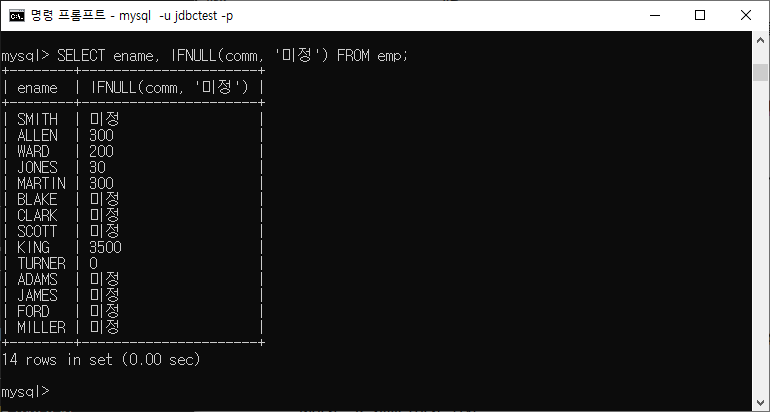 comm이 NULL인 경우 IFNULL( )로 오류 방지
comm이 NULL인 경우 IFNULL( )로 오류 방지
ex) Case 활용
mysql> select ename, sal, case
-> when sal > 4000 then 'T1'
-> when sal > 3000 then 'T2'
-> when sal > 2000 then 'T3'
-> when sal > 1000 then 'T4'
-> else 'T5' end as grade
-> from emp;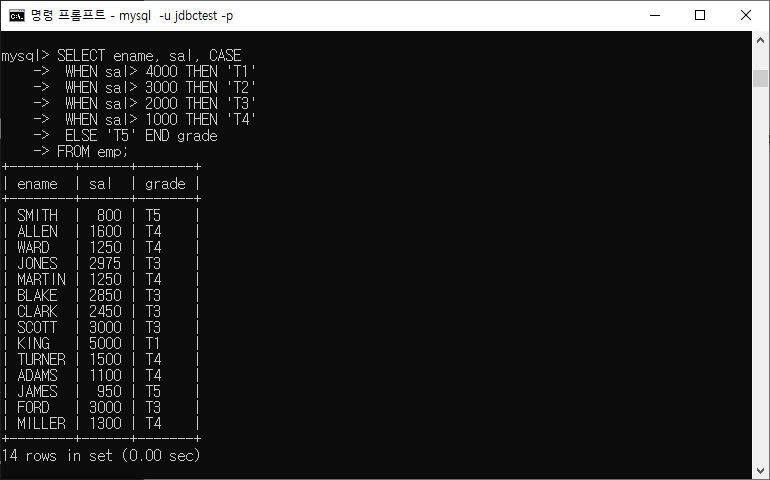
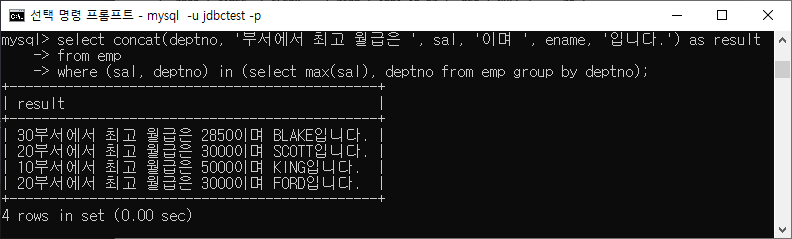
서브쿼리(SubQuery, 하위쿼리, 내부쿼리)
서브쿼리
쿼리문 안에 포함되는 쿼리
ex) SMITH 와 동일한 부서에서 근무하는 직원들이 누구인지 알고 싶다
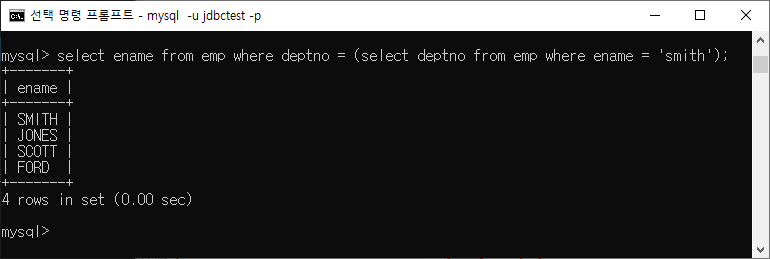
서브쿼리 유형
- 단일 행 서브쿼리
- 단일 행 반환
- 단일 행 비교 연산자(=, <, >, <=, >=,<> 등) 사용
- 다중 행 서브쿼리
- 여러 행 반환
- 다중 행 비교 연산자(IN, ANY, ALL 등) 사용
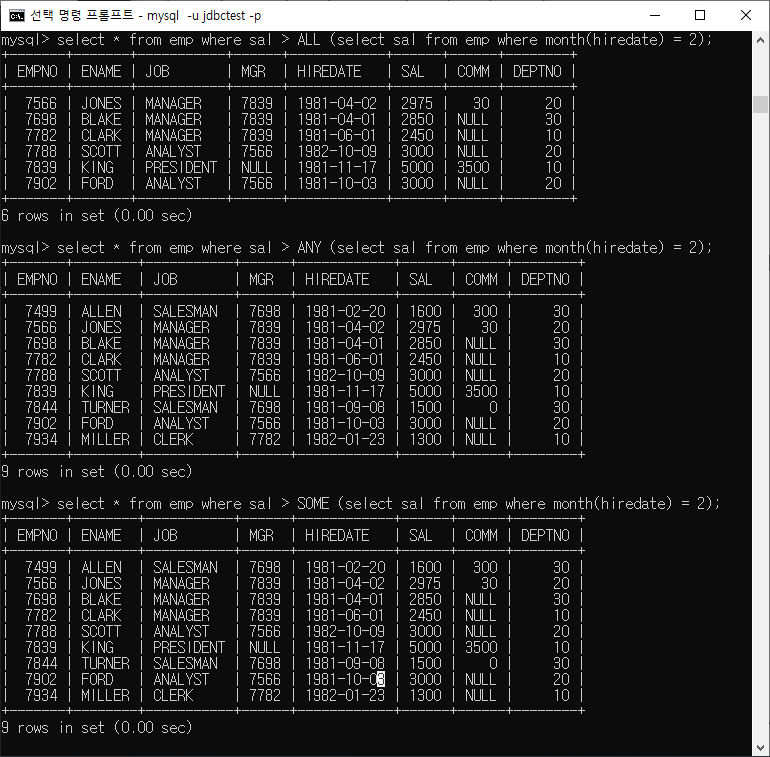
ex) ALL, ANY, SOME 활용
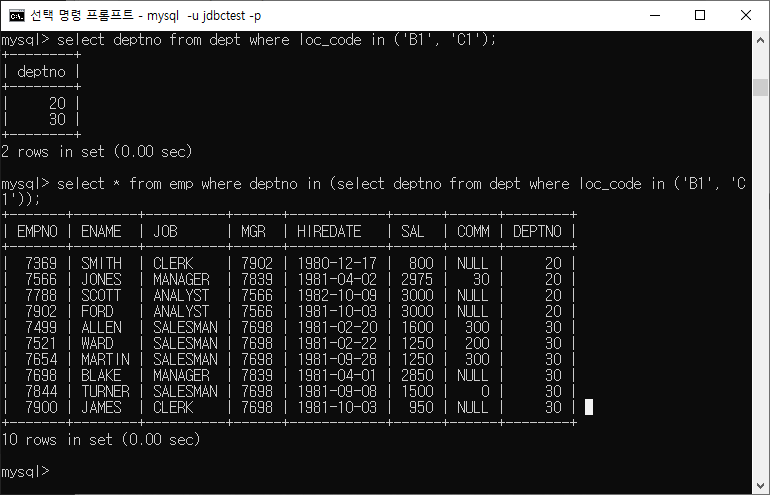
 ex) In 활용
ex) In 활용
ANY
서브쿼리의 여러 개의 결과 중 한 가지만 만족해도 가능
SOME은 ANY와 동일한 의미로 사용
‘= ANY(서브쿼리)’는 ‘IN(서브쿼리)’와 동일한 의미
ALL
서브쿼리의 결과 중 여러 개의 결과를 모두 만족해야 함
USE 구문
사용할 데이터베이스 지정
USE 데이터베이스 이름;조회
SHOW DATABASES; 현재 서버 DB 조회
SHOW TABLE STATUS; 데이터베이스에 있는 TABLE 조회
SHOW TABLES; 테이블 이름만 간단히 조회
DESC 테이블명; 테이블 열 확인MySQL의 데이터 형식
MySQL에서 지원하는 데이터 형식의 종류
숫자 데이터 형식
| 데이터 형식 | 바이트 수 | 숫자 범위 | 설명 |
|---|---|---|---|
| BIT{N} | N/8 | 1~64bit를 표현, b'0000'형식으로 표현 | |
| TINYINT | 1 | -128~127 | 정수 |
| SMALLINT | 2 | -32,768~32,767 | 정수 |
| MEDIUMINT | 3 | -8,388,608~8,388,607 | 정수 |
| INT/INTEGER | 4 | 약 -21억~+21억 | 정수 |
| BIGINT | 8 | 약 -900경~+900경 | 정수 |
| FLOAT | 4 | -3.40E+38~3.40E-38 | 소수점 아래 7자리까지 표현 |
| DOUBLE REAL | 8 | -1.79E-308~1.79E+308 | 소수점 아래 15자리까지 표현 |
| DECIMAL(m, [d])/NUMERIC(m, [d]) | 5~17 | 최대 65자리 지원 | 전체 자릿수(m)와 소수점 이하 자릿수(d)를 가진 숫자형 |
문자 데이터 형식
| 데이터 형식 | 바이트 수 | 설명 | |
|---|---|---|---|
| CHAR(n) | 1~255 | 고정 길이 문자형. n을 1~255까지 지정. 그냥 CHAR만 쓰면 CHAR(1)과 동일 | |
| VARCHAR(n) | 1~65535 | 가변길이 문자형. n을 1~65,535까지 지정. | |
| BINARY(n) | 1~255 | 고정길이의 이진 데이터 값 | |
| VARBINARY(n) | 1~255 | 가변길이의 이진 데이터 값 | |
| TEXT 형식 | TINYTEXT | 1~255 | 255크기의 TEXT 데이터 값 |
| TEXT 형식 | TEXT | 1~65535 | N 크기의 TEXT 데이터 값 |
| TEXT 형식 | MEDIUMTEXT | 1~16777215 | 16777215 크기의 TEXT 데이터 값 |
| TEXT 형식 | LONGTEXT | 1~4,294,967,295 | 최대 4GB 크기의 TEXT 데이터 값 |
| BLOB 형식 | TINYBLOB | 1~255 | 255크기의 BLOB 데이터 값 |
| BLOB 형식 | BLOB | 1~65535 | N 크기의 BLOB 데이터 값 |
| BLOB 형식 | MEDIUMBLOB | 1~16777215 | 16777215 크기의 BLOB 데이터 값 |
| BLOB 형식 | LONGBLOB | 1~4,294,967,295 | 최대 4GB 크기의 BLOB 데이터 값 |
| ENUM('vaue1', 'vaue2'...) | 1또는 2 | 최대 65535개의 열거형 데이터 값 | |
| SET('value1', 'value2'...) | 1, 2, 3, 4, 8 | 최대 64개의 서로 다른 데이터 값 |
날짜와 시간 데이터 형식
| 데이터 형식 | 바이트 수 | 설명 |
|---|---|---|
| DATE | 3 | 날짜는 1001-01-01~9999-12-31까지 저장되며 날짜 형식만 사용. 'YYYY-MM-DD'형식으로 사용됨. |
| TIME | 3 | -838:59:59.000000~838:59:59.000000까지 저장되며, 'HH:MM:SS'형식으로 사용 |
| DATETIME | 8 | 날짜는 1001-01-01 00:00:00~9999-12-31 23:59:59까지 저장되며 형식은 'YYYY-MM-DD HH:MM:SS'로 사용 |
| TIMESTAMP | 4 | 날짜는 1001-01-01 00:00:00~9999-12-31 23:59:59까지 저장되며 'YYYY-MM-DD HH:MM:SS'형식으로 사용. time_zone 시스템 변수와 관련이 잇으며 UTC 시간대 변환하여 저장 |
| YEAR | 1 | 1901~2155까지 저장. 'YYYY'형식으로 사용 |
기타 데이터 형식
| 데이터 형식 | 바이트 수 | 설명 |
|---|---|---|
| GEOMETRY | N/A | 공간 데이터 형식으로 선, 점 및 다각형 같은 공간 데이터 개체를 저장하고 조작 |
| JSON | 8 | JSON(JavaScript Object Notation) 문서를 저장 |
데이터 형식과 형 변환
데이터 형식 변환 함수
CAST( ), CONVERT( ) 함수를 가장 일반적으로 사용
BINARY, CHAR, DATE, DATETIME, DECIMAL, JSON, SIGNED INTEGER, TIME, UNSIGNED INTEGER 사용 가능
CAST(expression AS data_type)
CONVERT(data_type, expression)ex)
CAST(42 AS VARCHAR(10)) -- 숫자 42가 문자열 "42"로 변환
CONVERT(VARCHAR(10), 42) -- 동일암시적인 형 변환
CAST( )나 CONVERT( ) 함수를 사용하지 않고 형이 변환되는 것
SELECT '100' + '200'; -- 문자와 문자를 더함(정수로 변환되서 연산됨)
SELECT CONCAT('100', '200'); -- 문자와 문자를 연결(문자로 처리)
SELECT CONCAT(100, '200'); -- 정수와 문자를 연결(정수가 문자로 변환되서 처리)
SELECT 1 > '2mega'; -- 정수인 2로 변환되어서 비교
SELECT 3 > '2MEGA'; -- 정수인 2로 변환되어서 비교
SELECT 0 = 'mega2'; -- 문자는 0으로 변환됨TIP
별칭을 지정할때는 ''를, ORDER BY 등 로직에서 별칭을 사용할 때는 ``를 사용해야 한다.
MYSQL
