
버블 정렬(bubble sort)
데이터의 인접 요소끼리 비교하고, swap 연산을 수행하며 정렬하는 방식
시간 복잡도는 O(n2)

예제
선택 정렬(selection sort)
대상에서 가장 크거나 작은 데이터를 찾아가 선택을 반복하면서 정렬하는 방식
시간 복잡도는 O(n2)
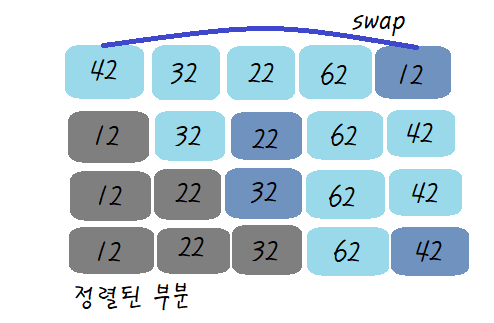
예제
삽입 정렬(insertion sort)
대상을 선택해 정렬된 영역에서 선택 데이터의 적절한 위치를 찾아 삽입하면서 정렬하는 방식
시간 복잡도는 O(n2)
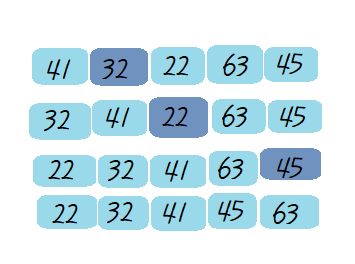
예제
퀵 정렬(quick sort)
pivot(기준값)을 선정해 해당 값을 기준으로 정렬하는 방식
시간 복잡도는 평균 O(nlogn)
1. 데이터를 분할하는 pivot을 설정한다.
2. pivot을 기준으로 다음 a~e 과정을 거쳐 데이터를 2개의 집합으로 분리한다.
2-a start가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start를 오른쪽으로 1 칸 이동한다.
2-b end가 가리키는 데이터가 pivot이 가리키는 데이터보다 크면 end를 왼쪽으로 1 칸 이동한다.
2-c start가 가리키는 데이터가 pivot이 가리키는 데이터보다 크고, end가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start, end가 가리키는 데이터를 swap하고 start는 오른쪽, end는 왼
쪽으로 1 칸씩 이동한다.
2-d start와 end가 만날 때까지 a~c를 반복한다.
2-e start와 end가 만나면 만난 지점에서 가리키는 데이터와 pivot이 가리키는 데이터를 비교하여 pivot이 가리키는 데이터가 크면 만난 지점의 오른쪽에, 작으면 만난 지점의 왼쪽에 pivot이 가리키는 데이터를 삽입한다.
3. 분리 집합에서 각각 다시 pivot을 선정한다.
4. 분리 집합이 1 개 이하가 될 때까지 과정을 반복한다.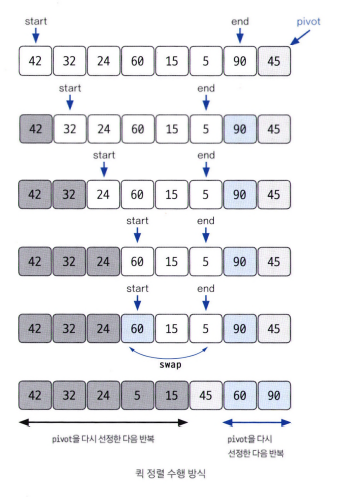
예제
병합 정렬(merge sort)
이미 정렬된 부분 집합들을 효율적으로 병합해 전체를 정렬하는 방식(분할 정복, divide and conquer)
시간복잡도 평균값은 O(nlogn)
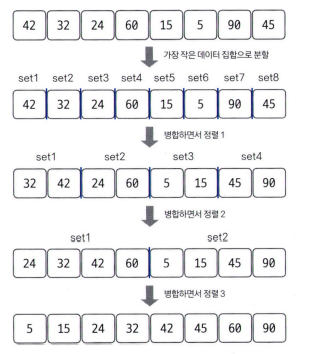
투 포인터 개념을 사용하여 왼쪽, 오른쪽 그룹을 병합한다. 왼쪽 포인터와 오른쪽 포인터의 값을 비교하여 작은 값을 결과 배열에 추가하고 포인터를 오른쪽으로 1칸 이동시킨다.
예제
기수 정렬(radix sort)
데이터의 자릿수를 바탕으로 비교해 데이터를 정렬하는 방식
값을 놓고 비교할 자릿수를 정한 다음 해당 자릿수만 비교한다. 시간복잡도는 O(kn)으로, 여기서 k는 데이터의 자릿수이다.
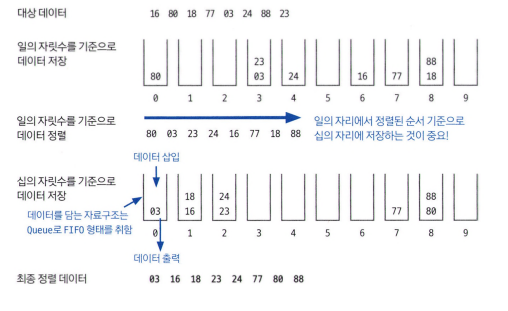
10개의 큐를 이용한다. 각 큐는 값의 자릿수를 대표한다.
기수 정렬은 시간복잡도가 가장 짧은 정렬이다. 만약 코딩 테스트에서 정렬해야하는 데이터의 개수가 너무 많으면 기수 정렬 알고리즘을 활용해 보자.
예제
참고 : 알고리즘 코딩테스트\[김종관]
