
3. Micro Service
비즈니스 민첩성
사용자 피드백을 반영해 끊임없이 서비스를 개선
- 아마존의 배포 속도: 초당 1.5번 배포
- Cloud 인프라의 등장
- 전형적인 시스템 인프라 구축 과정을 살펴보면 서버를 도입하고 네트워크를 구축한 뒤, 각 서버마다 운영체제를 설치하고 서비스에 필요한 소프트웨어를 설치하는 과정으로 진행되고 전 과정을 완료하기까지 적게는 며칠에서 길게는 몇달이 걸리기도 함
- Cloud 인프라에 어울리는 애플리케이션의 조건
- 스케일업 & 스케일 아웃
- Cloud Friendly & Cloud Native
Monolithic 과 Micro Service
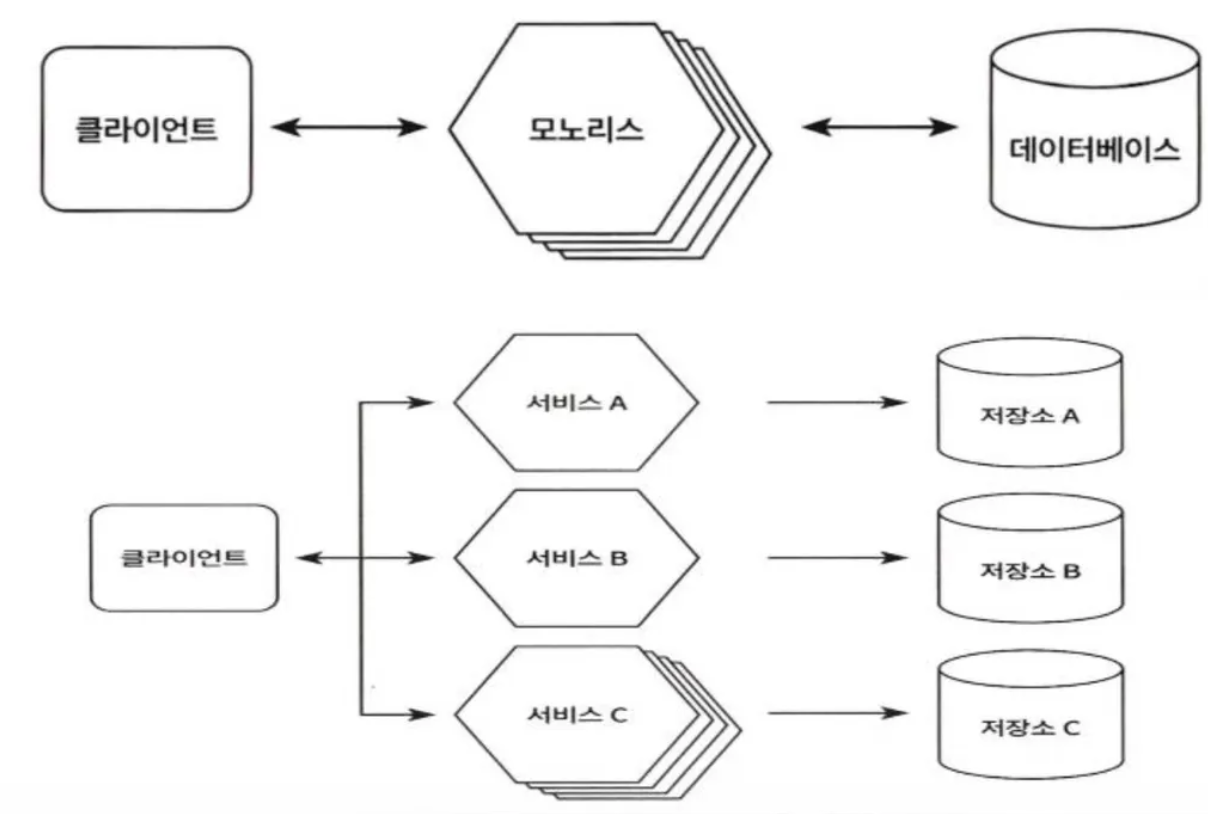
Monolithic
- 하나의 단위로 개발되는 일체식 애플리케이션
- 보통 3-Tier 로 구성을 많이 하는데 사용자 인터페이스, 데이터베이스 그리고 서버 쪽 애플리케이션으로 나누어 개발
- 서버측 애플리케이션이 일체. 즉, 논리적인 단일체로서 아무리 작은 변화에도 새로운 버전으로 전체를 빌드해서 배포해야 함
- 일체식은 단일 프로세스에서 실행되기 때문에 확장이 필요할 경우 특정 기능만 확장할 수 없고, 반드시 전체 애플리케이션을 동시에 확장해야 하는데 보통 로드 밸런서를 앞에 두고 여러 인스턴스 위에 큰 덩어리를 복제해 수평으로 확장
- 변경이 발생할 때 모놀리식 시스템의 단점이 극대화 됨
Micro Service
- 서버 측이 여러 개의 조각으로 구성되어서 각 서비스가 별개의 인스턴스로 로딩되는데 여러 서비스 인스턴스가 모여 하나의 비즈니스 애플리케이션을 구성하고 각기 저장소가 다르므로 업무 단위로 모듈 경계를 명확하게 구분
- 확장시에는 특정 기능별로 독립적으로 확장할 수 있고, 특정 서비스를 변경할 필요가 있다면 해당 서비스만 빌드해서 배포하면 됨
- 각 서비스가 독립적이어서 서로 다른 언어로 개발하는 것도 가능하므로 각 서비스의 소유권을 분리해 서로 다른 팀이 개발 및 운영할 수 있음
SOA 와 Micro Service
- 모듈화의 발전 흐름
- 구조적 방법론(기능을 하향식 분해, 설계) → 객체지향 방법론 → CBD(Component Based Development) → SOA(Service Oriented Architecture)
Micro Service를 위한 조건
배포 파이프라인 자동화
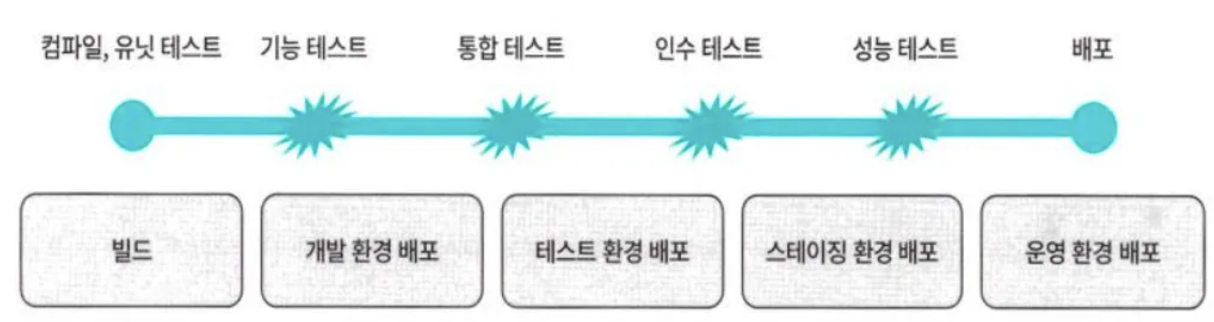
IaC(Infrastructure as Code)- 인프라 구성, 애플리케이션 빌드, 배포를 코드를 이용하여 수행
저장소의 변화: 통합 저장소가 아닌 분권 데이터 관리
- 저장소를 여러 개 사용하게 되면 각 서비스에 담긴 데이터의 비즈니스 정합성을 맞춰야 하는 데이터 일관성 문제가 발생할 수 있음
- 데이터 일관성 처리를 위해서는 보통 2단계 커밋 같은 분산 트랜잭션 기법을 이용하는데, 각각 다른 서비스를 하나의 트랜잭션으로 묶다보면 각 서비스의 독립성도 침해되고 NoSQL 저장소처럼 2단계 커밋을 지원하지 않는 경우도 있음
비동기 이벤트- 두 서비스의 데이터가 일시적으로 불일치하는 시점에 있고 일관성이 없는 상태지만 결국에는 두 데이터가 같아진다는 개념
- 여러 트랜잭션을 하나로 묶지 않고 별도의 로컬 트랜잭션으로 각각 수행하고 일관성이 달라진 부분은 보상 트랜잭션으로 일관성을 맞추는 개념
위기 대응 방식의 변화: 실패를 고려한 설계
fault tolerance- 소프트웨어는 언제든 실패할 수 있으며, 실패해서 더는 진행할 수 없을 때도 자연스럽게 대응할 수 있도록 설계해야 한다는 의미.
리액티브 선언문(The Reactive Manifesto)
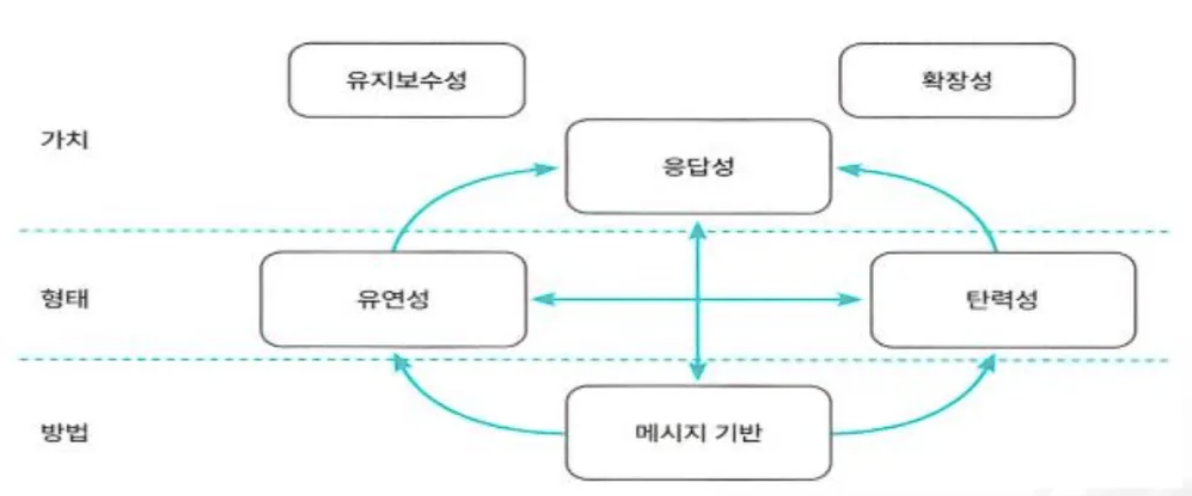
Responsive (응답성)- 사용자에게 신뢰성 있는 응답을 빠르고 적절하게 제공하는 것
Resilient (탄력성)- 장애가 발생하거나 부분적으로 고장나더라도 시스템 전체가 고장 나지 않고 빠르게 복구하는 능력
Elastic (유연성)- 시스템의 사용량에 변화가 있더라도 균일한 응답성을 제공하는 것을 의미하며 시스템 사용량에 비례해서 자원을 늘리거나 줄이는 능력
Message Driven (메시지 기반)- 비동기 메시지 전달을 위해 위치 투명성, 느슨한 결합, 논블로킹 통신(요청을 보내고 결과가 올 때까지 멈춰있지 않는 통신)을 지향하는 것
강 결합에서 느슨한 결합의 아키텍처로의 변화
(레이어 별로 선택된 애플리케이션)
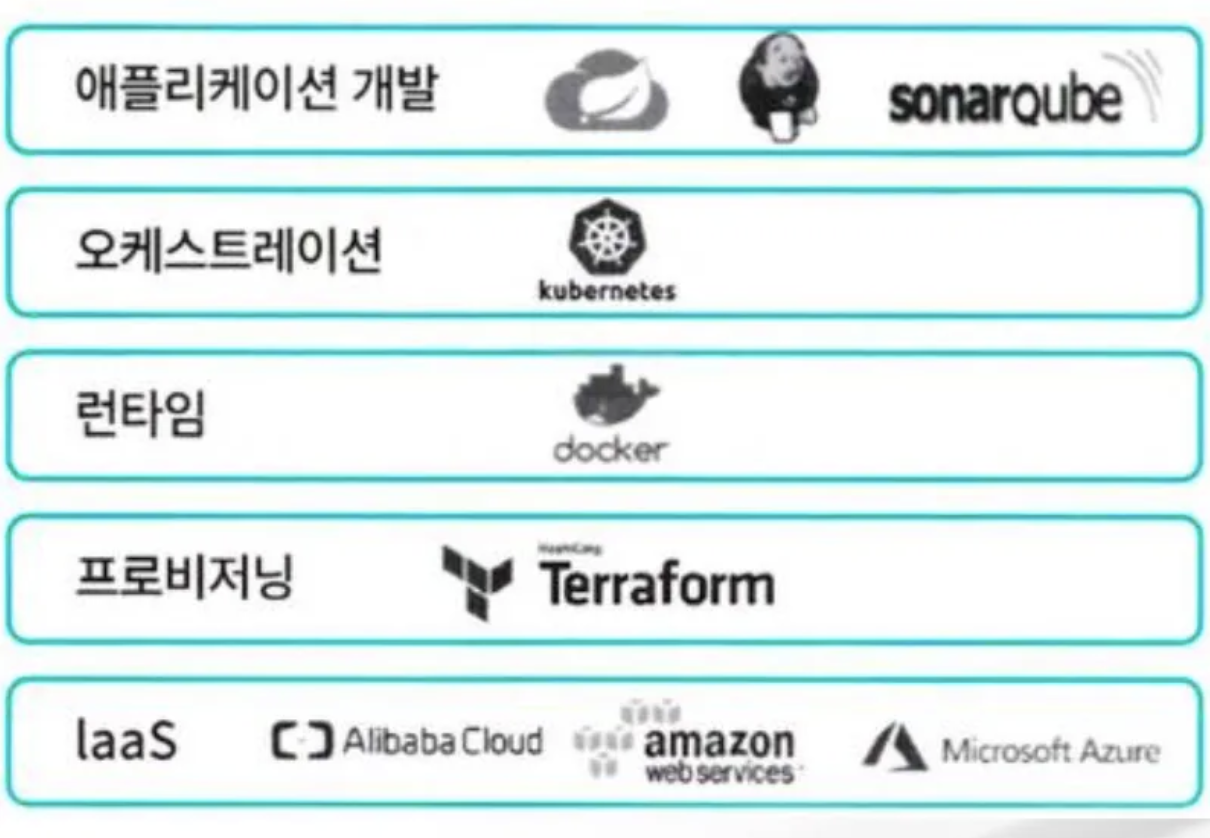
MSA 구성 요소 및 MSA 패턴
인프라 구성 요소
Public Cloud,Private Cloud,BareMetalVM,Container컨테이너 오케스트레이션- K8s
Backing Service- 데이터 관련
- Persistence Store - RDBMS, NoSQL, …
Cache- 데이터 캐시를 정의
- Redis
Message Broker- Queue 등을 이용한 메시지 전달 매체와 방법을 의미
- RabbitMQ, Kafka, …
Telemetry- 마이크로서비스는 각 서비스들이 분리되어 있기 때문에 각 서비스 간의 로그를 한데 모아야 하는 이유,
- 각 서비스가 어떻게 호출되는지 추적해야하는 이슈,
- 각 서비스에 대한 모니터링 이슈가 있음
- → 이러한 Logging, Trace, Monitoring을 의미
Logging- ELK, EFK
Trace- sluth/zipkin
Monitoring- prometheus/grafana
CI/CD- 개발, 배포, 테스트 와 같은 많은 부분을 자동화시켜 통합과 배포를 지원
플랫폼 패턴
- 개발 지원 환경: 데브옵스 인프라 구성
- 빌드/배포 파이프라인 설계
- 서비스 단일 진입을 위한 API Gateway 패턴
- BFF(Backend For Frontend) 패턴: Frontend 별로 서버를 별도로 두는 방식
- 외부 구성 저장소 패턴: 접속해야 하는 저장소의 설정 내용을 별도의 파일로 만들어서 보관
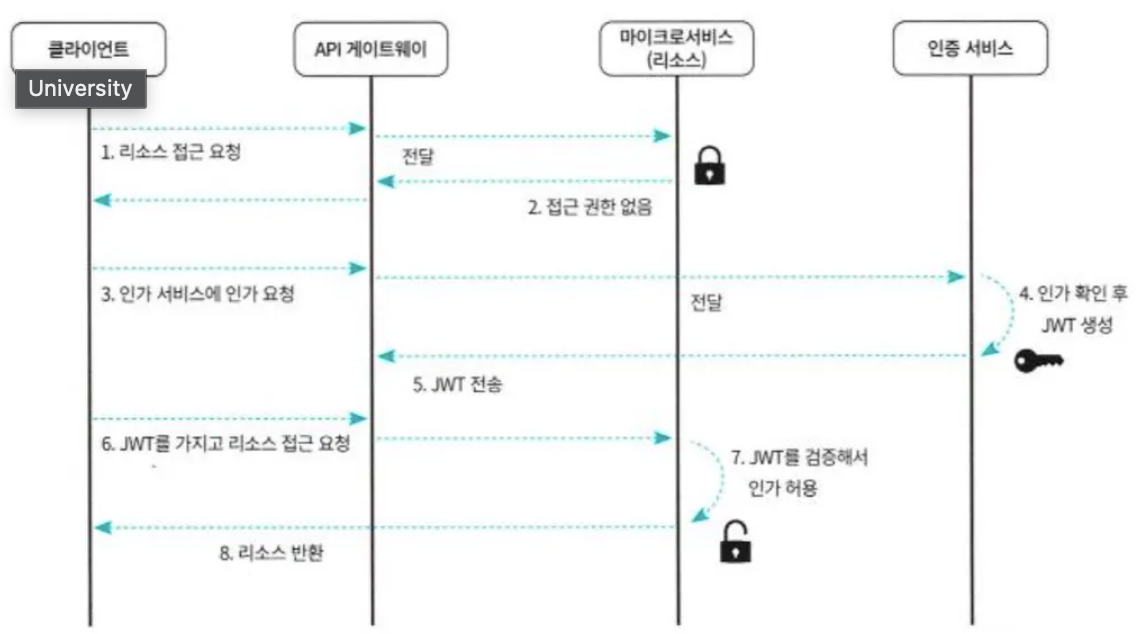
인증/인가 패턴
- 각 서비스가 모두 인증/인가를 중복으로 구현한다면 비효율적
- 중앙 집중식 세션 관리
- 클라이언트 토큰
- API 게이트웨이를 사용한 클라이언트 토큰
장애 및 실패 처리를 위한 서킷 브레이커 패턴
모니터링과 추적 패턴
중앙화 된 로그 집계 패턴
서비스 매시 패턴
- Istio
CQRS
1) Docker 설치
- 패키지 업데이트 및 도커 설치
sudo apt update && sudo apt upgrade -y
# 도커 설치를 위한 필수 패키지
sudo apt install -y ca-certificates curl gnupg lsb-release
# 도커 공식 GPG 키 추가 및 저장소 설정 후 설치
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh- 사용자 권한 설정: sudo 없이 도커를 사용하기 위해 계정을 docker 그룹에 추가
sudo usermod -aG docker $USER
# 적용을 위해 로그아웃 후 다시 로그인하거나 아래 명령 수행
newgrp docker- Docker Compose 설치: Kafka 와 마이크로서비스 구동에 필수
sudo apt install -y docker-compose-plugin2) Kafka
-
LinkedIn 에서 파편화된 데이터 수집 및 분배 아키텍처를 운영하는데 큰 어려움을 겪어서 이를 해결하기 위해서 만든 시스템
-
내부 데이터 흐름을 개선하기 위해 개발
-
Kafka는 각각의 애플리케이션끼리 연결해서 데이터를 처리하는 것이 아니고, 한 곳에 모아 처리할 수 있는 중앙 집중화 방식을 사용하는 것이 가능
-
Kafka를 통해 웹 사이트, 애플리케이션, 센서 등에서 취합한 데이터 스트림을 한 곳에서 실시간으로 관리할 수 있게 됨
-
대용량 데이터를 수집하고 이를 사용자들이 실시간 스트림으로 소비할 수 있게 만들어주는 일종의 중추 신경으로 동작
-
Kafka를 중앙에 배치해서 소스 애플리케이션과 타겟 애플리케이션 사이의 의존도를 최소화해서 커플링을 완화
-
기존에 1:1 매칭으로 개발하고 운영하던 데이터 파이프라인은 커플링으로 인해 한쪽의 이슈가 다른 한쪽의 애플리케이션에 영향을 미치곤 했지만 카프카는 이러한 의존도를 타파
-
소스 애플리케이션에서는 어떤 애플리케이션으로 데이터를 보낼지 고민하지 않고, 카프카로 넣으면 카프카 내부에 데이터를 저장하고 타겟 애플리케이션은 이 데이터를 소비
-
데이터가 저장되는 자료구조는 Queue(FIFO) 방식
-
큐에 데이터를 보내는 것을 프로듀서, 큐에서 데이터를 가져가는 것이 컨슈머
-
Kafka를 통해 전달받을 수 있는 데이터 포맷은 제한이 없음
-
상용 환경에서는 최소 3대 이상의 서버에서 분산 운영하여 프로듀서를 통해 전송받은 데이터를 파일 시스템에 안전하게 기록
- 넷플릭스의 경우에는 36개 이상의 클러스터에 브로커가 4000개 이상으로 운영
-
사용 이유
높은 처리량확장성- Scale In & Out 이 쉬움
- 카프카의 Scale In / Out 은 무중단 서비스
영속성- 파일 시스템에 데이터 저장 가능
- 카프카에 문제가 생겨서 재부팅 되더라도 카프카는 데이터를 소유하고 있음
고가용성
-
docker-compose.yml 작성
services:
kafka:
image: apache/kafka:3.7.0
container_name: developowl-kafka-1
ports:
- "9092:9092"
environment:
# 1. KRaft 모드 활성화 (가장 중요)
- KAFKA_NODE_ID=1
- KAFKA_PROCESS_ROLES=broker,controller
- KAFKA_CONTROLLER_QUORUM_VOTERS=1@localhost:9093
# 2. 리스너 설정 (컨트롤러와 브로커 통로 분리)
- KAFKA_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT
# 3. 클러스터 초기화 설정
- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1
- KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS=0
- KAFKA_TRANSACTION_STATE_LOG_MIN_ISR=1
- KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=1
# 4. 주키퍼 미사용 명시 (일부 이미지에서 필요)
- CAN_ELIDE_ZNODE_CHECK=true- docker
# docker-compose 실행
docker compose up -d
# 명령어로 확인
docker ps
# 컨테이너 내부로 들어가서 설정을 수정
docker exec -it kafka /bin/bash- 파일 복사
# 도커 컨테이너에서 호스트 컴퓨터로 파일을 복사
docker cp [컨테이너 이름]:[컨테이너 내부 경로] [호스트 파일 경로]
# 호스트 컴퓨터에서 도커 컨테이너로 파일을 복사
docker cp [호스트 파일 경로] [컨테이너 이름]:[컨테이너 내부 경로]