referential stability
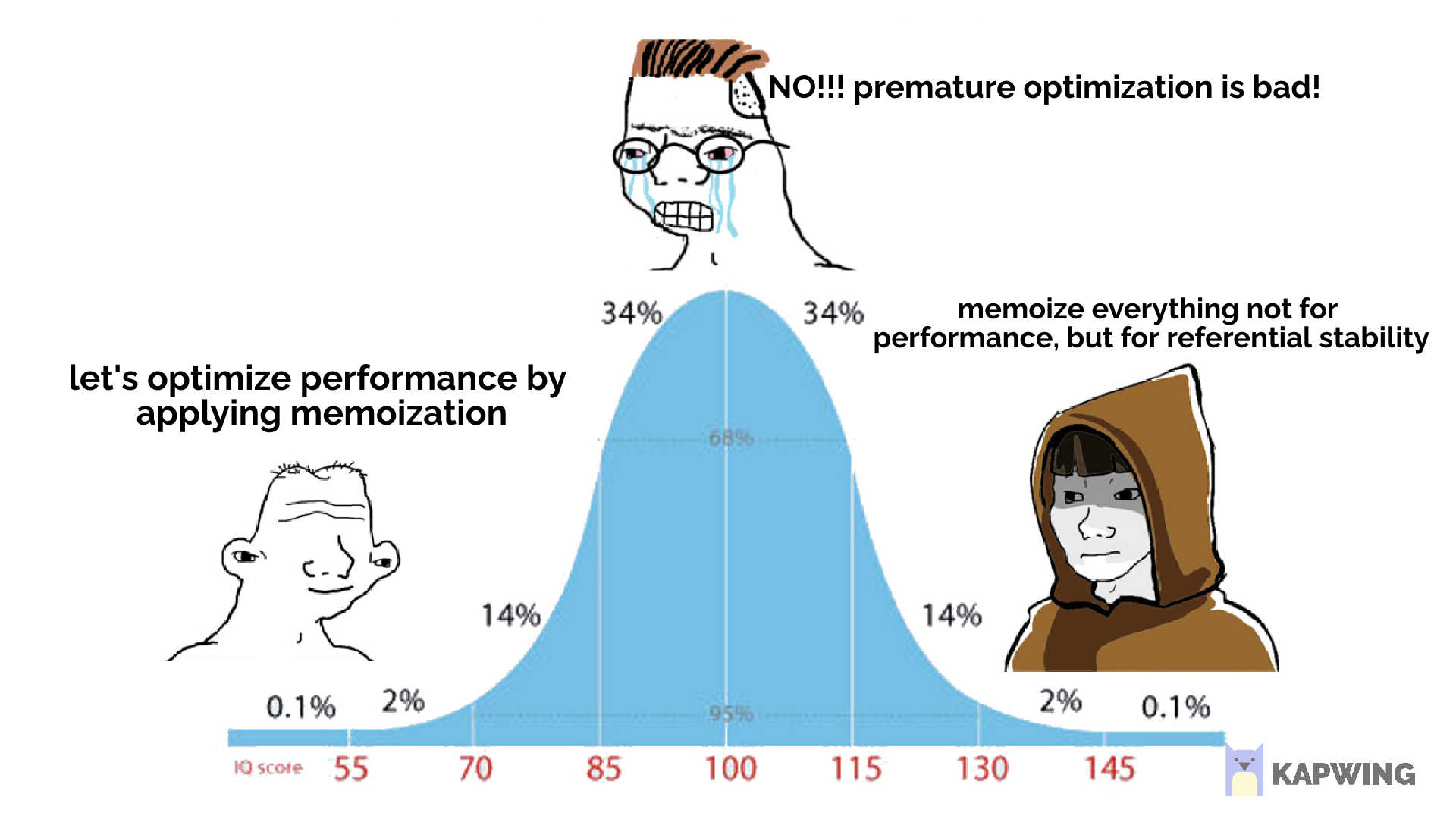
referential stability
みんなのReactニュービー時代に。。
- 「useEffect」が無限実行される現象を経験したことがある。
- 「useEffect」実行が望まないタイミングでできる
- depsをいじって解決したけど、できるまで触ったんだ。
既存の言語(特にOOP)は二つのオブジェクトが同じかどうかを以下のように検査するのが一般的でした。
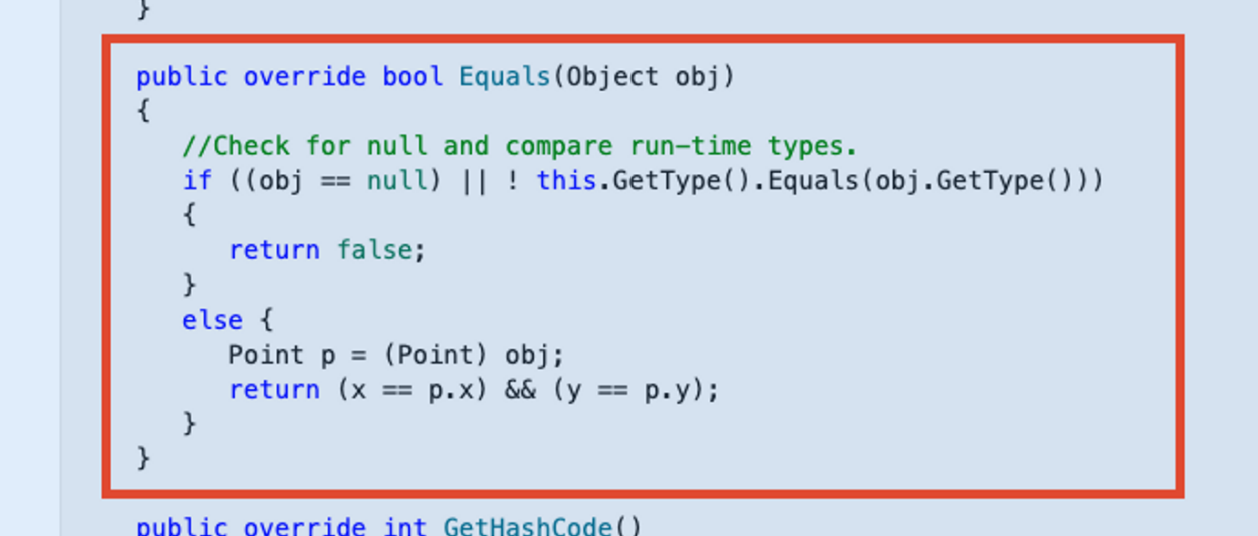
リアクトは上記のように検査するにはコストが大きすぎて、すでにjs自体が'Equals'の標準がないので何もできません。
const parkJunChul = { age: 13, name: 'Park' };
const parkJunSoo = { age: 13, name: 'Park' };
// 内容は同じだが、そのようなことはよく分からないが、ただインスタンスが違えば他の人と見る。
parkJunChul === parkJunSu;このようなequality check方式はReactで非常によく使われます。 (例:deps)
これで、以下のコードがなぜ非効率的なのかがわかります。
const Hello = React.memo(({ onClick }) => {
return <button onClick={onClick}>click me</button>
});
const App = () => {
const onClick = () => {
alert('clicked');
};
return (
<Hello onClick={onClick} />
);
};- 正解:onClickはAppが実行されるたびに異なるリファレンスを持つ関数が生成され続けるため、'React.memo'はまったく動作しなくなります。
もちろん、これを改善しなければならないほどHelloを再び実行させるのが遅くありません。
なので、あのコードは特に問題がないと言えますし、私も個人プロジェクトには全部そのようにしています。
さらに、「memo」関数の2番目の因子を使って以下のように作成すると、「onClick」が毎回生成されても正常に動作します。
const Hello = React.memo(({ onClick }) => {
return <button onClick={onClick}>click me</button>
}, }, (prev, next) => {
// onClickは無視して残りのpropsでequalityを検査するロジックを作成します。
});でも、関係ないからほっといて、実はreferential stabilityを守りながら組むのが正しいし、'memo'の2番目の因子を作成するのはとても面倒で、バグをよく作ります。. (スペックが増えるにつれフィールドをpropsには追加しましたが、memoでは抜けていると考えてみてください。 そしていつもロジックがあるのはロジックがないより複雑性が増加しバグを生み出します。)
また、会社で組むプロジェクトでは、個人プロジェクトよりもはるかに扱うデータが多いため、実際に「memo」を積極的に使用する必要があるかもしれません。 テーブルの方が遅いですね。
では、「onClick」が何をしても(unmount→mount状態は除く)、同じリファレンスを返すようにするのが「referential stability」です。
これをちゃんと守れば…
- '==='で自信を持って値を比較することができます。
- 「[deps]」を誤用して、effectが何度も実行されるのを防ぐことができます。
- 'memo' を追加的なコスト(2 番目の比較関数作成)なしで安心して書くことができます。
私が昨日これを他の人たちに話したことがあるんですが…
const func = useCallback(() => { /* ... */ */ }, [deps]);funcがどうして同じなのか、depsが変わったら当然ずっと変わるべきじゃないか。
と言ったんですが、僕が言った答えは
Reactを除いてすべてのフレームワークがそうではないのにReactがああいうのが当然なのでしょうか?
再びreferential stabilityに移って… 先ほど言った長所の一つである
「[deps]を誤用してeffectが何度も実行されるのを防ぐことができます。` への例示コードです。
const useMyProfile = () => {
return {
name: 'park',
age: 1
};
};const MyProfile = () => {
const profile = useMyProfile();
useEffect(() => {
// このコードは、プロファイルが実際に変更されようが変更されまいが、実行され続けます。
}, }, [profile]);
return null;
};今、私たちは安全な「useMyProfile」の作り方を学びましたので、以下のように変えてみます。
const useMyProfile = () => {
return React.memo(() => ({
name: 'park',
age: 1
}), []);
};リアルワールド例

関連テーマ
-
immutable.jsはなぜ使うのでしょうか?
-
immutable.jsでのデータ操作は、「ary.push」などの基本提供関数よりも遅く、
-
メモリ効率の高いトリックとアルゴリズムを使用したとしても、依然として基本js関数より速度とメモリ効率が良くありません。
-
答え: 書き方を遅くしても、読み方(比較)を早くするのがよく使われる戦略
-
レンダリング/比較演算は すごくたくさん起きて、ずっと起こるんですけど
-
書き込み演算はユーザインプットが発生したときのみ生成される(常にではなく、ほとんどが)
-
ゲームは関数型で組めないという話があります。 様々な理由がありますが、ゲームは読み取り/書き込みが同じように多く発生するからです。
他のトピックボーナス (雑誌式)
constr = 'asdfㅁㄴㅇㄹㅁㄴㅇㄹㄴㅇㄹㄴㅇㄹㄴㄹㄴㅁㅇㄹ';';
const ary = [1,2,3,4,5];
// O(1)
ary[n];
// 下のコードの時間複雑度はO(3n)です。
const c = str[n];では、私たちがもし何かをパーシングするコードを組むとしたら…。
for (int i=0;i<str.length;i++) {
if (str[i] === 'x') {
// // 'x'
}
}
// // { "asdf" : 1234 }
// 0
// // str = str.slice(offset);これはとても遅いコードになるかもしれません。
これをどう解決できますか。
https://github.com/v8/v8/blob/main/src/objects/string.cc#L1799
https://github.com/DuffsDevice/tiny-utf8/blob/master/include/tinyutf8/tinyutf8.h#L3530-L3598