
⭐️ 데이터베이스의 종류
👉 관계형 데이터베이스(RDMS)
- 행과 열을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스
- SQL이라는 언어를 써서 조작
- MySQL, PostgreSQL, 오라클, SQL Server, MSQL 등이 존재
- 관계형 데이터베이스의 경우 표준 SQL은 지키기는 하지만, 각각의 제품에 특화시킨 SQL을 사용
-> ex) 오라클의 경우 PL/SQL, SQL Server의 경우 T-SQLm MySQL의 경우 SQL 사용
MYSQL
- MYSQL은 대부분의 운영체제와 호환되며 현재 가장 많이 사용하는 데이터베이스
- C, C++로 만들어졌으며 MyISAM 인덱스 압축 기술, B-트리 기반의 인덱스, 스레드 기반의 메모리 할당 시스템, 매운 빠른 조인, 최대 64개의 인덱스를 제공
- 대용량 데이터베이스를 위해 설계되어 있고 롤백, 커밋, 이중 암호 지원 보안 등의 기능을 제공하며 많은 서비스에서 사용
MySQL의 스토리지 엔진 아키택처
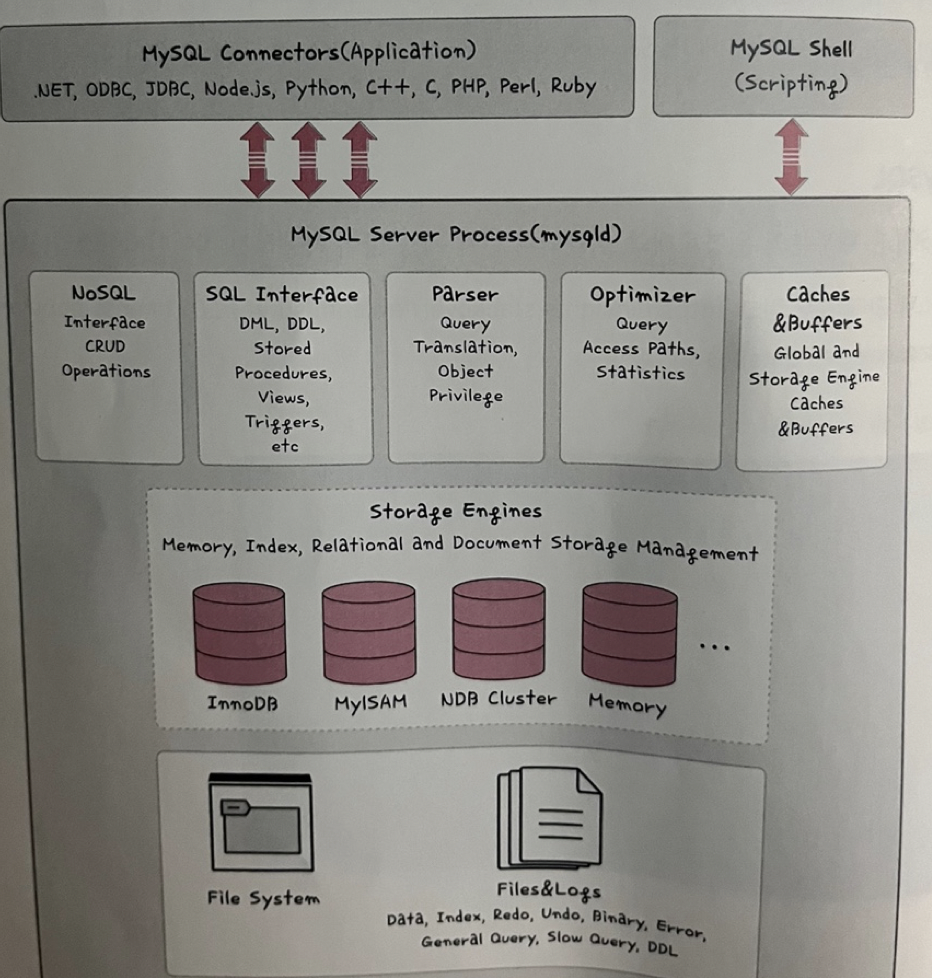
- 스토리지 엔진: 데이터베이스의 심장과도 같은 역할
- 모듈식 아키텍처로 쉽게 스토리지 엔진을 바꿀 수 있으며 데이터 웨어하우징, 트랜잭션 처리, 고가용성 처리에 강점
- 스토리지 엔진 위에는 커넥터 API 및 서비스 계층을 통해 MySQL 데이터베이스와 쉽게 상호 작용 가능
- MySQL은 쿼리 캐시를 지원해서 입력된 쿼리 문에 대한 전체 결과 집합을 저장하기 때문에 사용자가 작성한 쿼리가 캐시에 있는 쿼리와 동일하면 서버는 단순히 구문 분석, 최적화 및 실행을 건너뛰고 캐시의 출력만 표시
PostgreSQL
- MySQL 다음으로 개발자들이 선호하는 데이터베이스 기술
- 디스크 조작이 차지하는 영역을 회수할 수 있는 장치인 VACUUM이 특징
- 최대 테이블의 크기는 32TB이며 SQL뿐만 아니라 JSON을 이용해서 데이터에 접근 가능
- 저장 시간에 복구하는 기능, 로깅, 접근 제어, 중첩된 트랜잭션, 백업 등이 가능
👉 NoSQL 데이터베이스
- Not only SQL 이라는 슬로건에서 생겨난 데이터베이스
- SQL을 사용하지 않는 데이터베이스를 말하며, 대표적으로 MongoDB와 redis 등 존재
MongoDB
- JSON을 통해 데이터에 접근할 수 있고, Binary JSON 형태(BSON)로 데이터가 저장
- 와이어드타이거 엔진이 기본 스토리지 엔진으로 장착된 키-값 데이터 모델에서 확장된 도큐먼트 기반의 데이터베이스
- 확장성이 뛰어나며 빅데이터를 저장할 때 성능이 좋고 고가용성과 샤딩, 레플리카셋을 지원
- 스키마를 정해 놓지 않고 데이터를 삽입할 수 있기 때문에 다양한 도메인의 데이터베이스를 기반으로 분석하거나 로깅 등을 구현할 때 강점
- 도큐먼트를 생성할 때마다 다른 컬랜션에서 중복된 값을 지니기 힘든 유니크한 값인 ObjectID가 생성
-> 타임스탬프(4바이트), 랜덤값(5바이트), 카운터(3바이트)로 구성 (:유닉스 시간 기반)
redis
- 인메모리 데이터베이스
- 키-값 데이터 모델 기반의 데이터베이스
- 기본적인 데이터타입은 문자열이며 최대 512MB까지 저장 가능
- set, hash 등을 지원
- pub/sub 기능을 통해 채팅 시스템, 다른 데이터베이스 앞단에 두어 사용하는 캐싱 계층, 단순한 키-값이 필요한 세션 정보 관리, 정렬된 셋 자료 구조를 이용한 실시간 순위표 서비스에 사용
⭐️ 인덱스
👉인덱스의 필요성
- 인덱스는 데이터를 빠르게 찾을 수 있는 하나의 장치
- 인덱스를 설정하면 테이블 안에 찾고자 하는 데이터를 빠르게 찾기 가능
👉 B - 트리
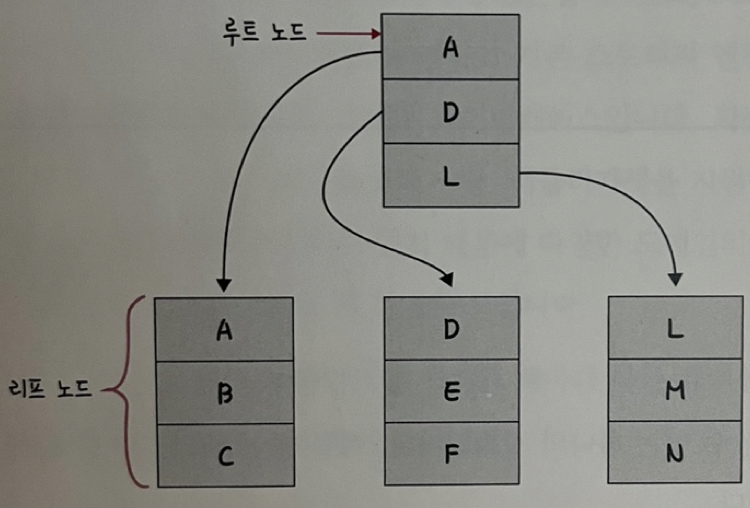
- 인덱스는 보통 B-트리라는 자료 구조로 이루어짐
-> 루트 노드, 리프 노드, 브랜치 노드로 나뉜다.
ex) E를 찾는다?
- 자료 구조 없이 E를 탐색한다면 A,B,C,D,E 다섯번을 탐색해야 하지만, 아래와 같이 노드로 나누면 두번만에 리프 노드를 찾을 수 있다.
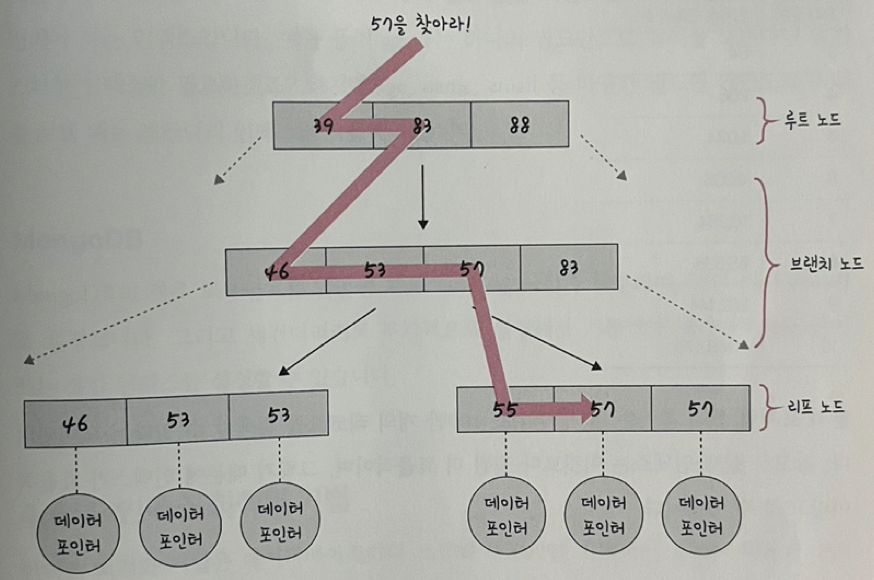
ex) 57을 찾는다?
- 트리 탐색은 맨 위 루트 노드부터 탐색이 일어나며 브랜치 노드를 거쳐 리프 노드까지 내려온다. '57보다 같거나 클때까지 <='을 기반으로 처음 루트 노드에서 39,83 이후로 아래 노드로 내려와 46,53,57 등 정렬된 값을 기반으로 탐색하는 것.
-> 이렇게 루트 노드부터 시작하여 마지막 리프 노드에 도달해서 57이 가리키는 데이터 포인터를 통해 결괏값을 반환
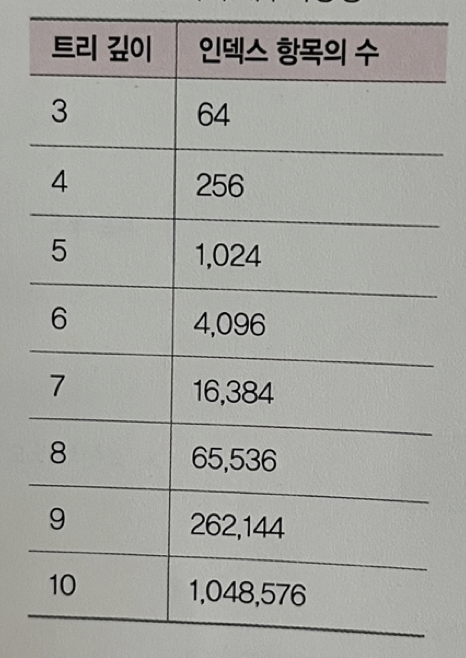
👉 인덱스가 효율적인 이유와 대수확장성
- 효율적인 단계를 가쳐 모든 요소에 접근할 수 있는 균형 잡힌 트리 구조와 트리 깊이의 대수확장성 때문
대수확장성
- 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것을 의미
- 기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 항목의 수는 4배씩 증가
- 아래와 같이 트리 깊이는 열개짜리로, 100만개 레코드를 검색 가능(실제 인덱슨느 이 것보다 훨씬 효율적)
👉 인덱스 만드는 방법
MySQL
- 클러스터형 인덱스와 세컨더리 인덱스가 존재
클러스터형 인덱스
- 테이블당 하나를 설정
- primary key 옵션으로 기본키로 만들면 클러스터형 인덱스를 생성 가능
- 기본키로 만들지 않고 unique not null 옵션을 붙이면 클러스터형 인덱스로 만들기 가능
- create index... 명령어를 기반으로 만들면 세컨더리 인덱스 만들기 가능
- 하나의 인덱슴나 생성할 것이라면 클러스터형 인덱스를 만드는 것이 성능에 좋다
세컨더리 인덱스
- 보조 인덱스로, 여러 개의 필드 값을 기반으로 쿼리를 많이 보낼 때 생성해야 하는 인덱스
- ex) age라는 하나의 필드만으로 쿼리를 보낸다면 클러스터형 인덱스만 필요. but, age,name,email 등 다양한 필드를 기반으로 쿼리를 보낼 때는 세컨더리 인덱스를 사용
MongoDB
- 도큐먼트를 만들면 자동으로 ObjectID가 형성되며, 해당 키가 기본키로 설정
- 세컨더리키도 부가적으로 설정해서 기본키와 세컨더리키를 같이쓰는 복합 인덱스를 설정 가능
👉 인덱스 최적화 기법
- 데이터베이스마다 조금씩 다르지만 기본적인 골조는 똑같다.(MongoDB 기반으로 설명)
1️⃣ 인덱스는 비용이다
- 인덱스는 두번 탐색하도록 강요한다.
- 인덱스 리스트, 그 다음 컬렉션 순으로 탐색하기 때문이고 관련 읽기 비용이 든다
- 컬렉션이 수정되었을 때 인덱스도 수정되어야 한다. ( = 책의 본문이 수정되면 목차가 수정되듯)
-> 이때 B-트리의 높이를 균형 있게 조절하는 비용도 들고, 데이터를 효율적으로 조회할 수 있도록 분산시키는 비용도 든다 - 따라서 쿼리에 있는 필드에 인덱스를 무작정 다 설정하는 것은 답이 X
- 컬렉션에서 가져와야 하는 양이 많을수록 인덱스 사용은 비효율적
2️⃣ 항상 테스트하라
- 인덱스 최적화 기법은 서비스 특징에 따라 다르다
-> 서비스에서 사용하는 객체의 깊이, 테이블의 양 등이 다르기 때문 - 따라서 테스팅이 항상 중요
-> explain() 함수를 통해 인덱스를 만들고 쿼리를 보낸 이후에 테스팅하며 걸리는 시간을 최소화해햐 한다.
ex) MySQL 테스팅
EXPLAIN
SELECT * FROM t1
JOIN t2 ON t1.c1 = t2.c13️⃣ 복합 인덱스는 같음,정렬,다중값,카디널리티 순
- 보통 여러필드를 기반으로 조회할 때 복합 인덱스를 생성하는데, 이 인덱스를 생성할 때는 순서가 있고 생성 순서에 따라 인덱스 성능이 다르다
-> 같음, 정렬, 다중값, 카디널리티 순
- 어떠한 값과 같음을 비교하는 ==이나 equal이라는 쿼리가 있다면 제일 먼저 인덱스로 설정
- 정렬에 쓰는 필드라면 그다음 인덱스로 설정
- 다중 값을 출력해야 하는 필드, 즉 쿼리 자체가 >이거나 <등 많은 출력해야 하는 쿼리에 쓰는 필드라면 나중에 인덱스를 설정
- 유니크한 값의 정도를 카디널리티라고 한다. 이 카디널리티가 높은 순서를 기반으로 인덱스를 생성해야 한다. ex) age, email 중 email이 더 높다. 즉, email이라는 필드에 대한 인덱스를 먼저 생성해야 한다.

기록하여 기억하고, 계획하여 실천하자. will be a FE developer (HOME버튼을 클릭하여 Notion으로 놀러오세요!)