
⭐️ 시간 복잡도
- 효율적인 코드를 개선하는데 쓰이는 척도
- 문제를 해결하는데 걸리는 시간과 입력의 함수 관계
- 어떠한 알고리즘 로직이 '얼마나 오랜 시간'이 걸리는지를 나타내는데 쓰인다
- 빅오 표기법으로 나타낸다
빅오 표기법
입력 범위 n을 기준으로 해서 로직이 몇번 반복되는지를 나타내는 것
💡 잠깐) C++
#include <bits/stdc++.h> //1 using namespace std; // 2 String a; // 3 int main() { cin >> a; // 4 cout << a << "\n"; // 5 return 0; // 6 }코드설명
- 헤더 파일로써, STL 라이브러리를 import한다. 이 중 bit/stdc++.h는 모든 라이브러리가 포함된 헤더
- std라는 네임스페이스를 사용한다는 뜻이다. cin이나 cout 등을 사용할 때 원래는 std::cin 처럼 네임스페이스를 달아서 호출해야 하는데, 이를 기본으로 설정한다는 뜻.(네임스페이스는 같은 르래스를 이름 구별, 모듈화에 쓰이는 이름)
- 문자열을 선언, string이라는 타입을 가진 a라는 변수를 정의하였다.
- 입력(cin, scanf)
- 출력(cout, printf)
- return 0
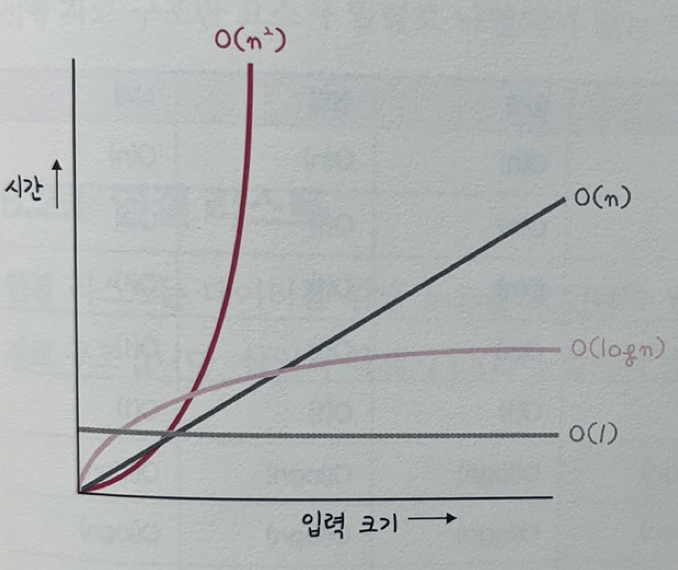
시간 복잡도의 속도 비교
O(1)과 O(n)은 입력 크기가 커질수록 차이가 많이나는 것을 확인 가능.
-> O(n^2)보다는 O(n)을. O(n)보다는 O(1)을 지향해야 한다.
자료구조에서의 시간 복잡도
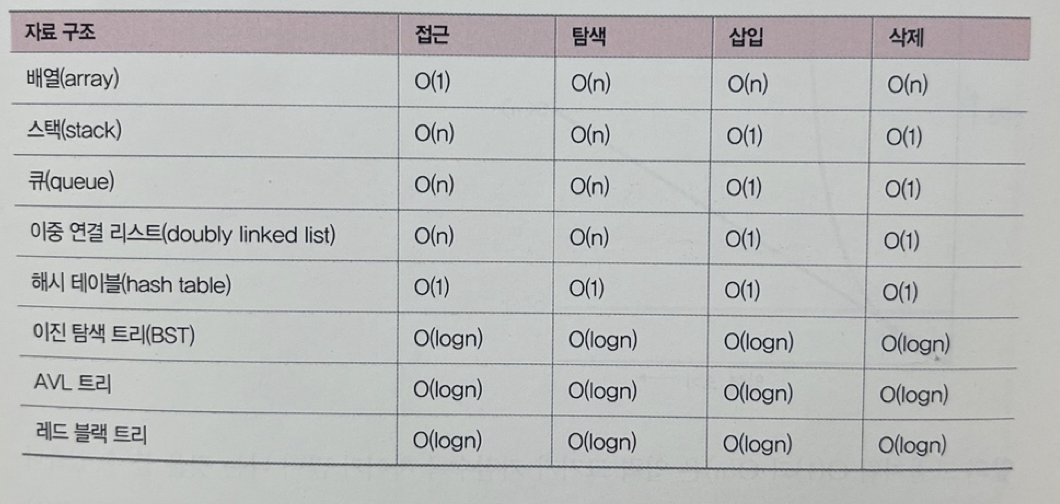
✏️ 자료 구조의 평균 시간 복잡도
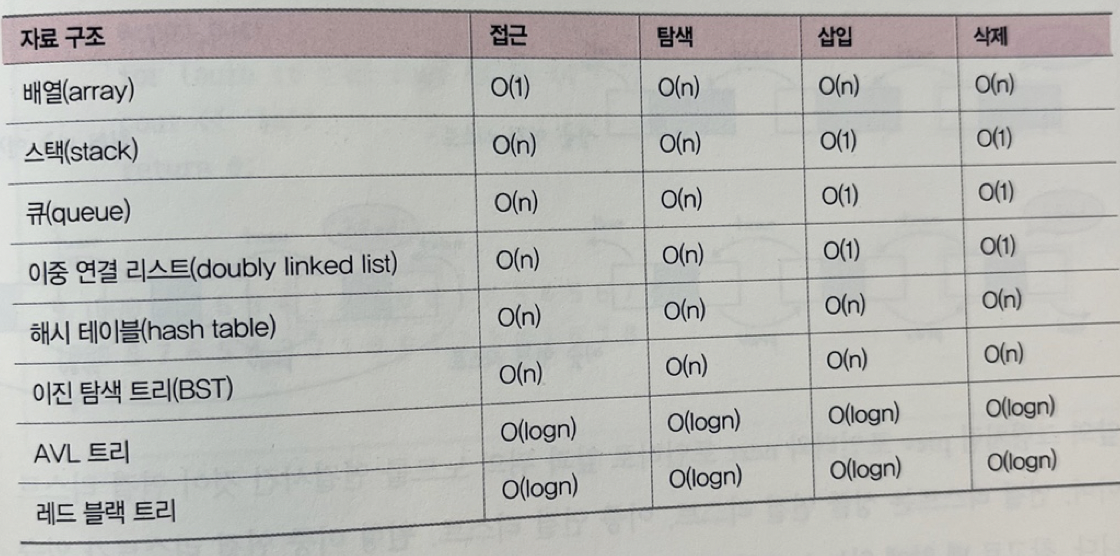
✏️ 자료 구조 최악의 시간 복잡도
⭐️ 공간 복잡도
- 프로그램을 실행시켰을 때 필요로 하는 자원 공간의 양
- 정적 변수로 선언된 것 말고도 동적으로 재귀적인 함수로 인해 공간을 계속해서 필요로 할 경우도 포함
ex) a 배열에 1004 x 4바이트의 크기가 할당
int a[1004];⭐️ 선형 자료구조
- 요소가 일렬로 나열되어 있는 자료 구조
1️⃣ 연결 리스트
- 데이터를 감싼 노드를 포인터로 연결해서 공간적인 효율성을 극대화시킨 자료 구조
- 삽입과 삭제가 O(1)이 걸리며 탐색에는 O(n)이 걸린다
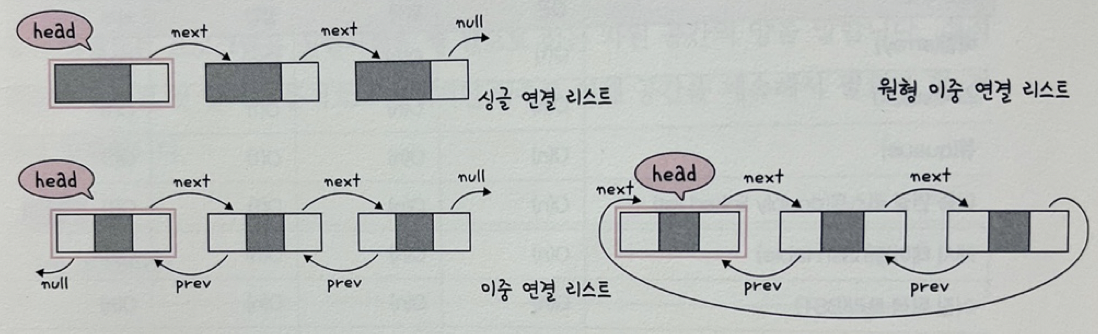
prev포인터와 next포인터로 앞과 뒤의 노드를 연결시킨 것이 연결 리스트이며, 연결리스트는 싱글 연결 리스트, 이중 연결 리스트, 원형 이중 연결 리스트가 존재
- 싱글 연결리스트: next포인터만 가진다
- 이중 연결리스트: next포인터와 prev포인터를 가진다
- 원형 이중 연결 리스트: 이중 연결 리스트와 같지만 마지막 노드의 next 포인터가 헤드 노드를 가리키는 것
2️⃣ 배열
- 같은 타입의 변수들로 이루어져 있고, 크기가 정해져 있으며, 인접한 메모리 위치에 있는 데이터를 모아놓은 집합
- 중복을 허용하는 순서가 존재
- 탐색에 O(1)이 되어 랜덤 접근이 가능(정적배열 기반)
- 삽입과 삭제에는 O(n)이 소요(정적배열 기반)
- 인덱스에 해당하는 원소를 빠르게 접근해야 하거나 간단하게 데이터를 쌓고 싶을 때 사용
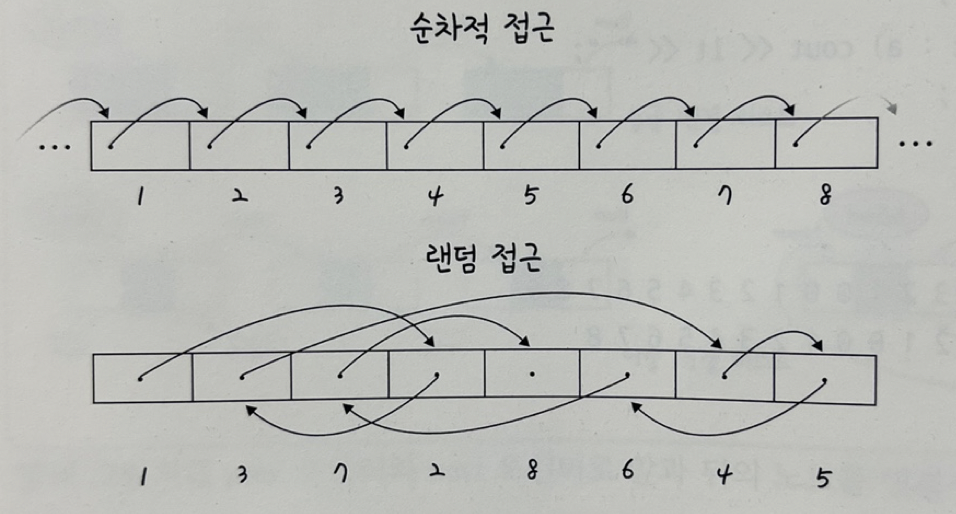
랜덤 접근 & 순차적 접근
- 랜덤 접근
직접 접근이라고 하는 랜덤 접근은 동일한 시간에 배열과 같은 순차적인 데이터가 있을 때 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능 - 순처적 접근
데이터를 저장된 순서대로 검색해야한다(랜덤접근과 반대)
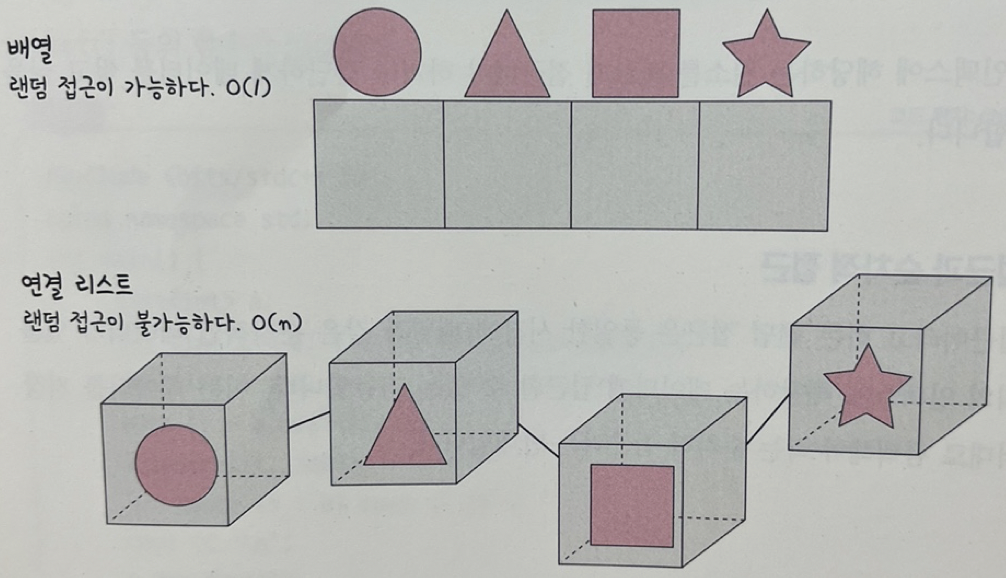
💡 배열과 연결리스트 비교
- 배열은 상자를 순서대로 나열한 데이터 구조이며 몇번째 상자인지 알면 해당 상자의 요소를 끄집어내기가 가능
- 연결 리스트는 상자를 선으로 연결한 형태의 데이터 구조이며 상자 안의 요소를 알기 위해서는 하나씩 상자 내부를 확인해야 한다.
추가와 삭제를 많이 하는 것은 연결리스트, 탐색을 많이 하는 것은 배열로 하는 것이 좋다
3️⃣벡터
-
동적으로 요소를 할당할 수 있는 동적 배열
-
컴파일 시점에 개수를 모른다면 벡터를 사용
-
중복을 허용하고 순서가 있고 랜덤 접근이 가능
-
탐색과 맨 뒤의 요소를 삭제하거나 삽입하는데 O(1)이 소요
-
맨 뒤나 맨 앞이 아닌 요소를 삭제하고 삽입하는데 O(n)의 시간이 걸린다
-
뒤에서부터 삽입하는 push_back()의 경우 O(1)이 소요되는데, 벡터의 크기가 증가되는 시간 복잡도가 amortized 복잡도, 즉 상수 시간 복잡도 O(1)과 유사한 시간 복잡도를 가지기 때문.
push_back()을 한다고 해서 매번 크기가 증가하는 것이 아니라 2의 제곱승 +1마다 크기를 2배를 늘리는 것을 확인 가능
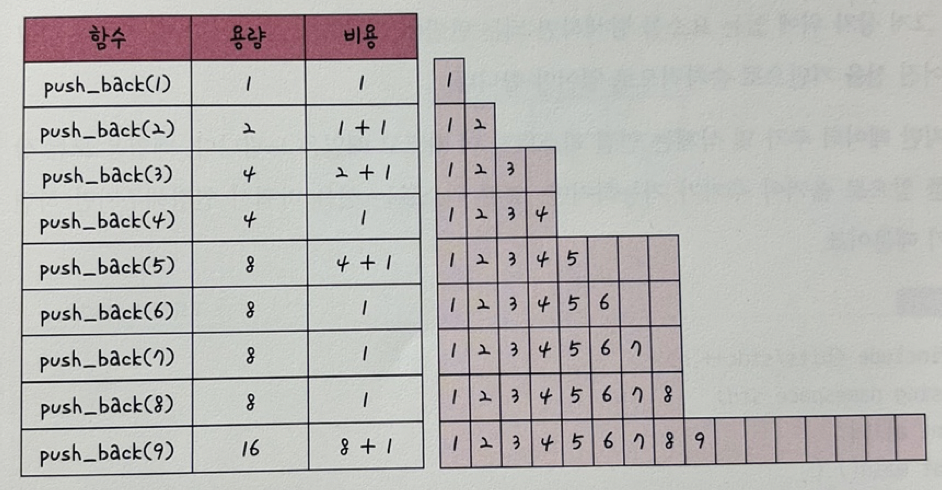
-
C를 i번째 push_back()을 할 때 드는 비용이라고 한다면, C(i)는 1 또는 1 + 2^k
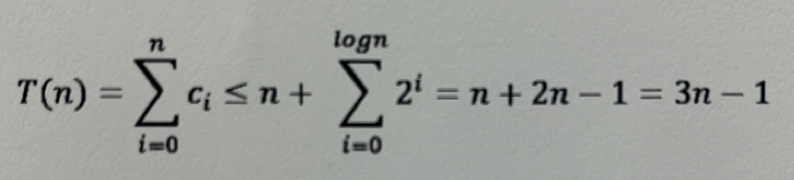
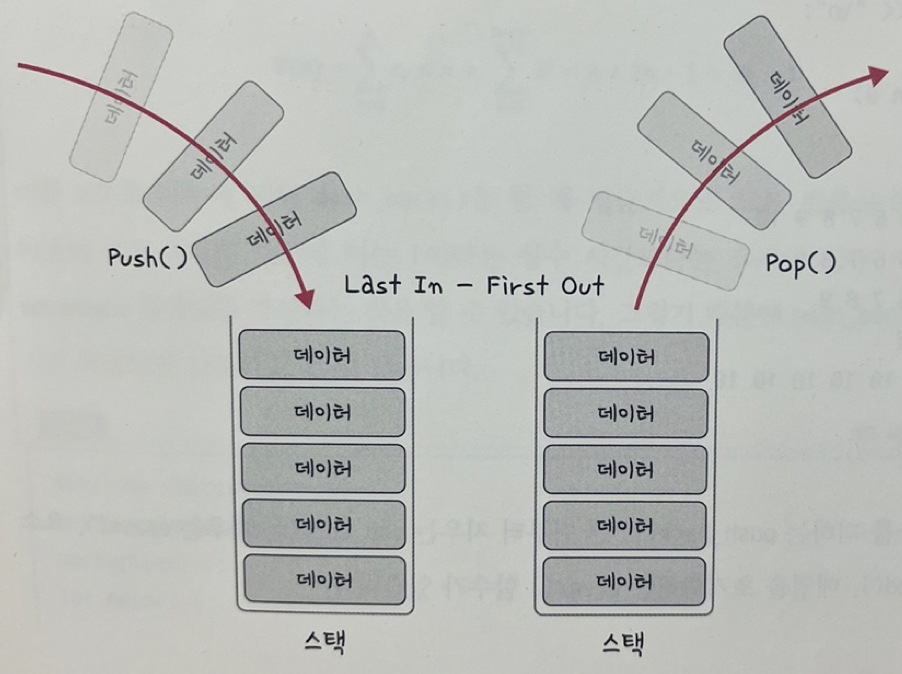
4️⃣ 스택
- 가장 마지막으로 들어간 데이터가 가장 첫번 째로 나오는 성질(LIFO)
- 재귀적인 함수, 알고리즘에 사용
- 웹 브라우저 방문 기록 등에 사용
- 삽입 및 삭제에 O(1), 탐색에 O(n)이 소요
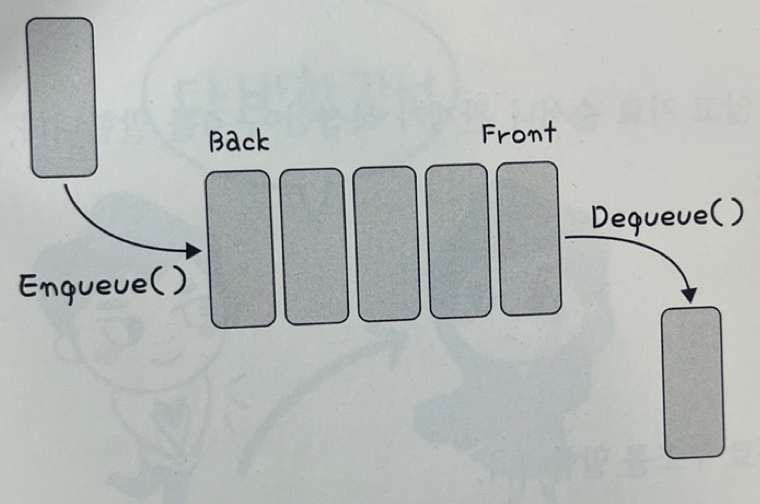
5️⃣ 큐
- 먼저 집어넣은 데이터가 먼저 나오는 성질(FIFO)
- 삽입 및 삭제에 O(1), 탐색에 O(n)이 소요
- CPU 작업을 기다리는 프로세스, 스레드 행렬 또는 네트워크 접속을 기다리는 행령, 너비 우선 탐색, 캐시 등에 사용

기록하여 기억하고, 계획하여 실천하자. will be a FE developer (HOME버튼을 클릭하여 Notion으로 놀러오세요!)