
✔️ 결과를 만드는 함수 reduce, take
map이나 filter함수가 배열이나 이터러블한 모나딕(하나의 관계를 갖는 관계 또는 함수)한 값에 내부에 있는 원소들에게 함수들을 합성해놓는 역할을 한다.
반면, reduce나 take는 이터러블이나 배열 같이 안쪽에 있는 값들을 꺼내어 더하는 식으로
최종적으로 결과를 만들어내는 함수이다.
따라서, map이나 filter같은 함수들은 지연성을 가진다고 할 수 있고, reduce나 take는 결과를 만드는 시작점을 만들기 때문에 iterator의 값을 꺼내어 연산을 시작한다.
물론, take함수는 지연성을 가질 수도 있지만, 실제로 몇개로 떨어질지 모르는 배열에서 특정 갯수만큼 배열로 축약하고 완성하는 특성이 있기 때문에 지연성을 가지기보단 함수가 호출된 시점에 연산이 이루어지는 것이 더 확실하고 편리하므로 더 낫다.
✔️ queryStr 함수
결과를 만드는 함수 reduce를 응용해서 객체로부터 url의 queryString을 만드는 함수 queryStr을 만들어보자.
1️⃣ Object.entries 형태로 객체 확인
const queryStr = obj => go(
obj,
Object.entries
);
log(queryStr({limit: 10, offset:10, type: 'notice'}));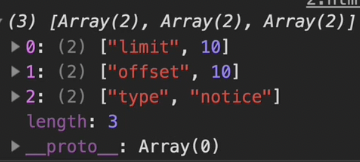
2️⃣ map안에서 구조분해를 통해 key와 value를 받아 출력
const queryStr = obj => go(
obj,
Object.entries,
map(([k,v])=>`${k}=${v}`),
);
log(queryStr({limit: 10, offset:10, type: 'notice'})); 
3️⃣ reduce을 통해서 a와 b의 사이에 seperator를 준다.
const queryStr = obj => go(
obj,
Object.entries,
map(([k,v])=>`${k}=${v}`),
reduce((a,b)=>`${a}&${b}`)
);
log(queryStr({limit: 10, offset:10, type: 'notice'})); 
4️⃣ obj를 받아서 그대로 obj를 전달하므로 pipe를 통해서 단축시킨다.
const queryStr = pipe(
Object.entries,
map(([k,v])=>`${k}=${v}`),
reduce((a,b)=>`${a}&${b}`)
);
log(queryStr({limit: 10, offset:10, type: 'notice'})); ✅ 이런 식으로 queryStr 호출을 시작으로 해서 최종적으로 결과값을 만들어 낼 때 함수적으로 어떤 과정을 통해서 완성되는지를 생각해보자~
✔️ 다형성이 높은 join함수
Array.prototype.join(기존 Array 제공 함수) 는 지연평가를 제공하지 않는다.
✏️ 기존 Array.prototype.join 사용
- 즉시평가 가능한 배열만 가능. Iterator 불가능
[1,2,3,4].join('-') //1 - 2 - 3 - 4✅ 따라서, 지연성도 제공하여 더 다형성이 높은 join 함수를 생성해보자.
✏️ 새로만든 join
배열이 아닌 값도 사용 가능. 왜냐하면 받는 값을 reduce를 통해서 축약하기 때문에 Iteratable Protocol를 따른다는 얘기이며, 그 뜻은 join() 실행 전까지는 지연이 가능하다는 소리이다.
다시말해, Iterable한 값이 아니더라도 reduce를 통해 사용되어 join()이 실행될 때 최종적인 값만 출력하기 때문에 가능한 것이다.
const join = curry((sep =",", iter) => reduce((a, b)=> `${a}${sep}${b}`, iter));✏️ 새로만든 join 사용
function *a(){
yield 10;
yield 11;
yield 12;
yield 13;
}
join(' - ', a());//10 - 11 - 12 - 13✏️느긋한 L.map을 사용할 때 join사용하기
join으로 넘어갈 당시에 인자값은 iterable하기 때문에 실제 값이 생성되어있지 않는 지연성이 있다.
const queryStr = pipe(
Object.entries,
L.map(([k, v]) => `${k}=${v}`),
function (a) {
log(a);
return a;
},
join('&')
);
//실행결과
//Generator {<suspended>}
//board.html?_ijt=5a6paisfamop82mebiurepmg4p:33 limit=10&offset=10&type=noticeL.map역시 이터레이터를 처리할 수 있어서Object.entries가 아닌 지연평가L.entries를 만들어서 내려줘도 된다.
L.entries = function* (obj) {
for (const key in obj) {
yield [key, obj[key]];
}
};
const queryStr = pipe(
L.entries,
function (a) {
log(a);
return a;
},
L.map(([k, v]) => `${k}=${v}`),
join('&')
);
log(queryStr({limit: 10, offset:10, type: 'notice'}));
//실행결과
//L.entries {<suspended>}
//board.html?_ijt=5a6paisfamop82mebiurepmg4p:33 limit=10&offset=10&type=notice✔️ take, find
앞서 만든 join 함수는 reduce 계열의 함수라 할 수 있는데, reduce함수를 이용해서 만들었기 때문이다.
또한 entries를 통해서 만드는 함수는 또 map을 통해서 만드는 함수라고 칭할 수 있는데 이렇게 함수를 사용해서 만드는 것을 함수 계열을 가지는 식으로 함수를 만들 수 있다.
이전에 만들어 본 queryStr이 reduce함수로 결론을 내는 함수였다면
✅ find함수는 take로 결론을 만들어내는 함수이다.
✏️ Example
1️⃣ user들의 age가 기록된 객체가 존재한다.
const users =[
{ age: 32},
{ age: 31},
{ age: 37},
{ age: 28},
{ age: 25},
{ age: 32},
{ age: 31},
{ age: 37},
{ age: 19},
{ age: 22},
];2️⃣ find함수는 결과적으로 take(1)에 의해 하나의 값만 출력하게 만든다.
const find = (f, iter) => go(
iter,
filter(a => console.log(a), f(a)),
take(1), // 조건에 만족하는 첫번째 값만 추출
([a])=>a
));
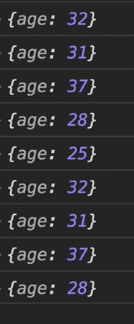
log(find(u => u.age < 30, users)); //{age: 28}✅ 하지만, filter의 a 값을 출력해보면 모든 값이 출력되는 것을 알 수 있다. 왜냐하면 filter에서 모든 값을 조건에 맞는지 비교하여 반환하기 때문이다.
3️⃣ 따라서, L.filter을 통해 지연성평가를 사용하여 위의 문제를 해결할 수 있다.
const find = curry((f, iter) =>go(
iter,
L.filter(f),
take(1), // 조건에 만족하는 첫번째 값만 추출
([a])=>a
));
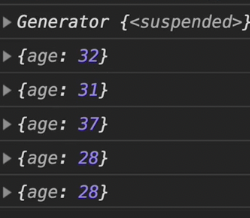
log(find(u => u.age < 30)(users));//{age: 28}✅ 즉, 아래의 출력결과처럼 조건에 맞는 값(age:28)을 찾는 순간 로직이 종료되는 것이다.
예를 들어, user의 목록이 100만개가 있었고 조건에 맞는 값을 10만번째에 찾았다면 그 뒤의 990만번의 불필요한 연산을 막은 것이다.
✔️ L.map, L.filter로 map과 filter 만들기
✅ 지연평가 L.map과 L.filter로 즉시평가 map과 filter를 만드는 방법은 결과를 만들어내는 함수 take를 이용하면 간단하게 구현이 가능
1️⃣ L.map을 사용하게 되면 지연된 값이 출력된다.
const mapV2 = curry(pipe(
L.map,
));
log(map(a => a + 10, L.range(4)));
2️⃣ take를 통해 지연성을 제공하는 이터러블객체를 실제 호출하여 값이 더이상 안나올때까지 꺼내게 된다.
const mapV2 = curry(pipe(
L.map,
take(Infinity)
));
log(map(a => a + 10, L.range(4)));
3️⃣ L.filter 역시 L.map과 같이 take를 통해서 구현이 가능하다.
const mapV2 = curry(pipe(L.map, take(Infinity)));
const filterV2 = curry(pipe(L.filter, take(Infinity)));✔️ .flatten, flatten
이터레이터 객체에는 내부에 또 다른 이터레이터를 가지고 있을 수 있다.
flatten은 이런 이터레이터 안의 이터레이터를 평탄화해서 펼쳐주는 역할을 한다.
✏️ 직접하는 평탄화
[[1,2], 3,4, [5,6]]
[...[1,2], 3, ,4, ...[5,6]] // 평탄화
[1,2,3,4,5,6] //결과✅ L.flatten 함수
const isIterable = a => a && a[Symbol.iterator];
L.flatten = function* (iter) {
for (const a of iter) {
if (isIterable(a)) {
for (const b of a) yield b;
} else {
yield a;
}
}
};1️⃣ 이터러블한 객체 받아오기
[[1,2], 3,4, [5,6]]2️⃣for of를 통해서 각각의 값 a를 순회
a = [1,2]
a = 3
a = 4
a = [5,6]3️⃣ isIterable의 조건 즉, a의 값이 이터러블인지 확인 (ex. 배열의 원소인지, 아직도 배열인지)
a = [1,2] -> 이터러블 O
a = 3 -> 이터러블 X
a = 4 -> 이터러블 X
a = [5,6] -> 이터러블 O4️⃣ 만약 isIterable의 조건을 만족하면 다시 for of를 통해서 순회
a = [1,2] // 순회
b = 1
b = 2
a = [5,6] // 순회
b = 5
b = 6✚ yield *
yield *을 활용하면 위 코드를 아래와 같이 변경할 수 있다.yield *iterable은for (const val of iterable) yield val;과 같다.
L.flatten = function *(iter) {
for (const a of iter) {
if (isIterable(a)) yield *a;
else yield a;
}
};✚ L.deepFlat
- 만일 깊은
Iterable을 모두 펼치고 싶다면 아래와 같이L.deepFlat을 구현하여 사용할 수 있다.L.deepFlat은 깊은Iterable을 펼쳐준다.
L.deepFlat = function *f(iter) {
for (const a of iter) {
if (isIterable(a)) yield *f(a);
else yield a;
}
};
log([...L.deepFlat([1, [2, [3, 4], [[5]]]])]);
// [1, 2, 3, 4, 5];
✅ 즉시평가 flattern
- 이전에 만든 지연성 함수를 결과를 도출해내는 함수(take, reduce)를 통해 즉시평가가 가능하게 한다.
const flatten = pipe(L.flatten, takeAll);✔️ L.flatMap, flatMap
flatMap은 flatten과 map을 동시에 작업해주는 함수
flatMap이 존재하는 이유는 자바스크립트가 기본적으로 지연평가가 아닌 즉시평가여서 비효율적으로 동작하기 때문이다.
✅ flatMap은 map과 flatten의 결합이다.
// flatMap
([[1,2],[3,4],[5,6,7]].flatmap(a=>a.map(a=>a*a))); //[1, 4, 9, 16, 25, 36, 49]
// flatten + map
flatten([[1,2],[3,4],[5,6,7]].map(a=>a.map(a=>a*a))); //[1, 4, 9, 16, 25, 36, 49]
하지만 즉시평가 flatMap의 경우 불필요한 연산을 해야하는 경우가 있기 때문에 지연성을 제공하는 flatMap을 만들 수 있다.
물론 둘이 시간복잡도의 차이는 없다. 연산을 안해도 되거나 그냥 넘어가도 되는 값이 있지 않는한 순회해야 하는 것들을 모두 순회하는 것들이기 때문이다.
따라서, 조금 더 효율성이 있고, flatmap의 경우 배열에 대해서만 동작하므로 이터러블한 객체도 사용가능하게 다형성을 높여보자.
✅ L.flatMap
L.flatMap = curry(pipe(L.map, L.flatten));
//즉시평가 flatMap
const flatMap = curry(pipe(L.flatMap, takeAll));💡 일반적인 JS 제공 flatMap
arr.flatMap(callback(currentValue[, index[, array]])[, thisArg])
callback: 새로운 배열의 엘리먼트를 생성하는 함수
currentValue: 배열에서 처리되는 현재 엘리먼트,index(Optional): 배열에서 처리되고 있는 현재 엘리먼트 인덱스array(Optional): map이 호출된 배열
thisArg(Optional): callback실행해서this로 사용할 값const arr1 = [1, 2, [3], [4, 5], 6, []]; const flattened = arr1.flatMap(num => num); console.log(flattened); // expected output: Array [1, 2, 3, 4, 5, 6]
✔️ Example.
✏️ 2차원 배열을 예제로 지금까지 구현한 함수들을 응용해보자.
2차원 배열 예제
const arr = [
[1, 2],
[3, 4, 5],
[6, 7, 8],
[9, 10]
];✅ arr에서 홀수만 꺼내기
go(arr,
L.flatten,
L.filter(a => a % 2),
takeAll,
log
) // [1, 3, 5, 7, 9]✅ arr에서 홀수만 꺼내 모두 더하기
go(arr,
L.flatten,
L.filter(a => a % 2),
reduce(add),
log
)//25✅ arr에서 홀수만 3개만 꺼내 제곱하기
go(arr,
L.flatten,
L.filter(a => a % 2),
take(3),
map(a=>a*a),
log
)//[1, 9, 25]✏️ 실무적인 예제
예제 데이터
let users = [
{
name: 'a', age: 21, family: [
{name: 'a1', age: 53}, {name: 'a2', age: 47},
{name: 'a3', age: 16}, {name: 'a4', age: 15}
]
},
{
name: 'b', age: 24, family: [
{name: 'b1', age: 58}, {name: 'b2', age: 51},
{name: 'b3', age: 19}, {name: 'b4', age: 22}
]
},
{
name: 'c', age: 31, family: [
{name: 'c1', age: 64}, {name: 'c2', age: 62}
]
},
{
name: 'd', age: 20, family: [
{name: 'd1', age: 42}, {name: 'd2', age: 42},
{name: 'd3', age: 11}, {name: 'd4', age: 7}
]
}
];✅ 모든 유저의 가족들 중 미성년자를 3명만 찾아서 반환하라
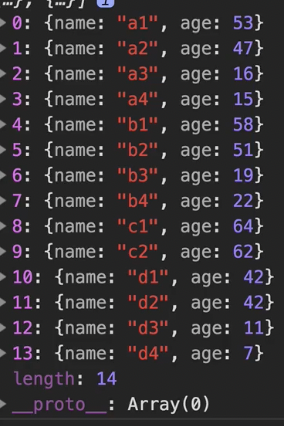
1️⃣ users의 family 의 value를 평탕화하여 펼친다
go(users,
L.map(u=>u.family),
L.flatten,
...
log
);
2️⃣ 20세 미만 유저만 필터
go(users,
L.map(u=>u.family),
L.flatten,
L.filter(a => a.age < 20),
...
log
);3️⃣ 3명까지만 결과 도출
go(users,
L.map(u=>u.family),
L.flatten,
L.filter(a => a.age < 20),
take(3),
log
);전체코드
go(users,
L.map(u=>u.family),
L.flatten,
L.filter(a => a.age < 20), // 20세 미만 유저만 필터
take(3), // 3명까지만 결과 도출
log
);
//실행결과
0: {name: "a3", age: 16}
1: {name: "a4", age: 15}
2: {name: "b3", age: 19}💡 잠깐) 지연평가 함수(L.func)의 성능 향상
최신 javascript에서도
flatMap,map,forEach,reduce등 대부분의 기능을 기본적으로 제공하고 있다. 그런데 어째서 이렇게 사용자정의로 구현한 함수들을 사용할까?위의 코드들이 기본으로 제공되는 API 로직과 가장 큰 차이점은 지연평가로인한 불필요한 연산및 결과도출의 생략이다.
즉시평가로 할 경우 filter등에서 arr의 모든 값 1~10까지 다 꺼내어 condition function과 비교후 맞는 값들을 꺼냅니다.
하지만, 지연평가의 경우 필요한 수치까지 다 가져오면(ex:3개만 가져오는 take(3) 함수) 더이상의 결과도출을 하지 않고 로직이 종료.
출처: https://catsbi.oopy.io/10ba3b65-9705-4e00-8f28-e1a2d256c992
참조 및 참고하기 좋은 사이트
