예전에 간단하게 JVM에 대해서 정리 해봤었는데, 이번에 팀원들과 스터디를 통해 다시 한번 공부를 하면서 복습도 하고 여러가지 새로운 것들을 알게되어 정리하고자 한다.
자바의 실행 과정
- .java파일을 자바 컴파일러가 바이트 코드인 .class 파일로 변환 시킨다.
- 실행 시, 클래스 로더는 바이트 코드로 변환된 클래스들을 로드, 링크하여 JVM에 탑재 시킨다.
- 실행 엔진은 클래스 로더로 메모리 영역에 탑재된 바이트 코드를 실행한다.
- 실행 엔진은 내부에서 바이트 코드를 기계어로 변환 시켜 실행을 한다.
인터프리터 & JIT 컴파일러
자바 실행 엔진은 런타임 시점에 인터프리터 방식으로 한 줄씩 바이트 코드를 읽어 실행 시킨다.
한 줄씩 읽는 인터프리터의 특징 때문에 속도가 느리다. 그럼에도 기본 변환 방식을 컴파일 방식을 사용하지 않는 이유는, 컴파일러는 메모리와 CPU 스레드 사용에 대한 비용 때문인데, 실행 시점에서 모든 바이트 코드를 컴파일 하면 오히려 인터프리팅 방식보다 더 느릴 수 있기 때문이다.
이러한 단점을 커버하기 위해 JIT 컴파일러 방식이 도입되었는데, JIT 컴파일러는 런타임 시점에 적절한 때에 바이트 코드를 컴파일 방식으로 기계어로 변환 시킨다. 이러한 방식 덕분에 인터프리터의 느린 속도라는 단점을 커버할 수 있게 되었다.
JIT 컴파일러
JVM은 다음 두가지 카운트를 관리한다.
- method entry counter (JVM 내에 있는 메서드가 호출된 횟수)
- back-edge loop counter (메서드가 루프를 빠져나오기까지 돈 횟수)
이 카운트가 임계값을 넘었을 경우, JIT 컴파일러가 컴파일해 기계어로 변경된다. 이렇게 기계어로 변경된 후에도 지속적인 카운트를 체크해 일정 임계값을 다시 넘었을 경우 더 높은 수준의 최적화를 실행한다. 이 최적화는 가장 높은 수준의 최적화 단계까지 반복 된다.
실제로 최적화가 이루어지는지 테스트를 해볼 수 있었다.
public class JitTest {
public static void main(String[] args) {
final int CHUNK_SIZE = 1000;
for (int i = 0; i < 500; ++i) {
long s = System.nanoTime();
for (int j = 0; j < CHUNK_SIZE; ++j) {
new Object();
}
long e = System.nanoTime();
System.out.printf("%d\t%d\n", i, e - s);
}
}
}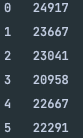
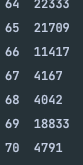
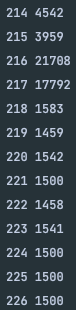
처음엔 실행시간이 20000 나노초대에 머물렀지만, 66~67회 실행 시점 부터 눈에 띄게 실행시간이 줄었다.
그 후 218회 부터 한 번 더 크게 줄었다.
이 외에도 여러가지 최적화에 대한 자료를 찾을 수 있었다.
ref - https://www.slideshare.net/dougqh/jvm-mechanics-understanding-the-jits-tricks-93206227
자바 메모리 영역(JAVA Runtime Data Areas)
PC register
스레드가 시작될 때 생성되며 현재 수행중인 JVM 명령의 주소를 가진다.
Method area
모든 스레드가 공유하는 영역으로, 클래스, 인터페이스, 메소드, 필드, Static 변수 등의 바이트 코드를 저장한다.
Stack area
스레드마다 하나의 Stack area를 가지며, 메서드 호출 시 메서드 단위로 스택 프레임이 생성된다. 호출된 메서드의 매개변수, 지역변수, 리턴 값, 연산 시 임시값 등을 저장하고
메서드 종료 시 스택 프레임 단위로 제거된다.
Heap area
모든 스레드가 공유하는 영역으로 객체(instance)들을 위한 영역, new를 통해 생성된 객체, 배열, immutal 객체 등의 정보를 저장하고, Garbage Collector에 의해 관리되는 주요 메모리 영역이다.
Native method area
자바 언어가아닌 다른 언어로 작성된 네이티브 코드를 수행하기 위한 메모리 영역이다.
Heap영역
Heap 영역은 위에서 설명했듯이 GC에 의해 관리되는 영역이다.
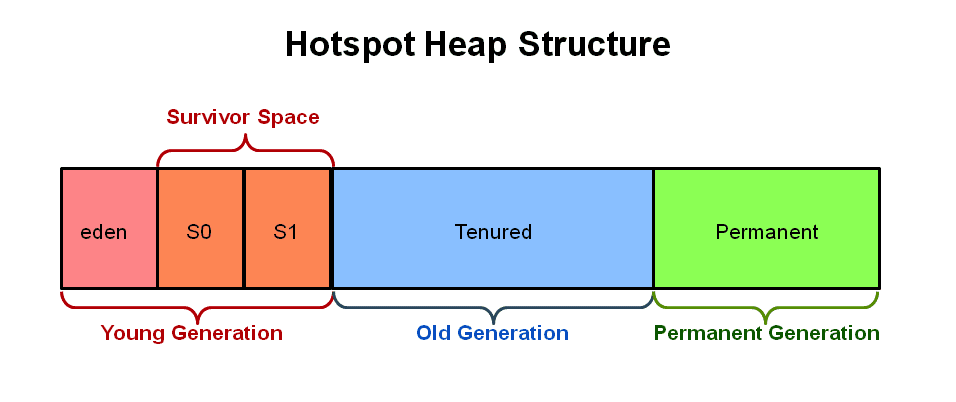
최신 글에서도 여전히 과거의 힙 영역 구조를 가지고 설명하는 글이 많이 보이지만 자바 8에서는 힙 영역 구조가 아래와 같이 변경되었다.
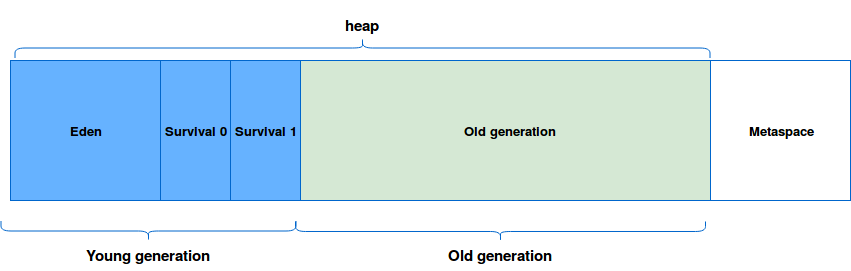
이에 대한 자세한 글은 다음 글에서 확인할 수 있다.
JAVA 8에서 perm 영역이 사라지고 metaspace 영역으로 대체된 이유?
스터디 항목 중 GC에 관해서도 있으니 빠른 시일내에 정리해서 포스팅할 수 있을 것 같다.
.jpg)