로그 생성
→ 기존에 조회와 같은 경우 Spring Data JPA로 구현을 해놓았기 때문에, 일반적인 JPA(Hibernate)는 블로킹 방식이라 WebFlux와 함께 사용하기 어렵다고 판단. webflux는 사용하지 않음.
→ 따라서, 동기 방식을 사용하되 효율적으로 처리할 수 있는 대안을 생각
시스템이 실제로 얼마나 많은 데이터를 처리할 수 있는지 테스트하기 위한 환경을 구축
단순히 처리량을 측정하는 것뿐만 아니라, 부하 상태에서 시스템이 어떤 한계에 도달하는지가 주요 포인트 관점이었음
🛠 사용된 기술 및 설계
1️⃣ 큐 기반 비동기 로그 저장
private final LinkedList<UserLog> logQueue = new LinkedList<>();LinkedList를 내부 큐로 사용하여 빠른 삽입/삭제 연산 지원.- 크기 제한이 없으며,
poll()로 빠르게 요소 제거 가능.
2️⃣ ReentrantLock + Condition을 활용한 동기화
private final ReentrantLock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
logQueue는 다중 스레드 환경에서 접근되므로ReentrantLock으로 동기화.- *조건 변수(Condition)를 사용하여 큐가 비어있으면 대기**하고, 데이터가 쌓이면 알림.
3️⃣ 배치 저장 (BULK_SIZE 및 FLUSH_TIMEOUT 설정)
private static final int BULK_SIZE = 100; // 배치 크기
private static final long FLUSH_TIMEOUT = 500L; // 최대 대기 시간 (ms)
- 로그가 100개 이상 쌓이거나, 500ms가 지나면 배치 저장.
- 불필요한 DB 호출을 줄이고, TPS를 증가시킴.
4️⃣ ExecutorService를 사용한 비동기 실행
private final ExecutorService consumerExecutor = Executors.newSingleThreadExecutor();
- 싱글 스레드 풀을 사용하여 로그를 소비 (
newSingleThreadExecutor()). startConsumer()에서 실행되며, 백그라운드에서 지속적으로 큐를 확인.
5️⃣ 비동기 로그 저장 처리 흐름
① 로그 적재 (enqueueLog)
public void enqueueLog(UserLog userLog) {
lock.lock();
try {
logQueue.add(userLog);
if (logQueue.size() >= BULK_SIZE) {
condition.signal(); // 로그가 충분히 쌓이면 즉시 저장
}
} finally {
lock.unlock();
}
}
- 로그가 들어오면 LinkedList에 저장.
- BULK_SIZE가 넘으면
condition.signal()을 호출하여 즉시 저장 트리거.
② 비동기 로그 처리 (startConsumer)
private void startConsumer() {
consumerExecutor.submit(() -> {
while (running || !logQueue.isEmpty()) {
List<UserLog> batch = new ArrayList<>();
lock.lock();
try {
while (logQueue.isEmpty() && running) {
condition.await(FLUSH_TIMEOUT, TimeUnit.MILLISECONDS);
break;
}
int count = 0;
while (count < BULK_SIZE && !logQueue.isEmpty()) {
batch.add(logQueue.poll());
count++;
}
} finally {
lock.unlock();
}
if (!batch.isEmpty()) {
try {
saveLogPort.saveAllLogs(batch);
log.info("배치 로그 저장 완료: {} 개", batch.size());
} catch (Exception e) {
log.error("로그 저장 중 오류 발생", e);
}
}
}
});
}
- 배치 저장 로직
- 큐가 비어있다면 최대
FLUSH_TIMEOUT동안 대기. BULK_SIZE만큼 로그를 가져와 배치 저장.
- 큐가 비어있다면 최대
- 비동기 실행
ExecutorService의 싱글 스레드에서 실행되어 백그라운드에서 지속적으로 큐를 모니터링.
③ 서비스 종료 시, 남은 로그 저장 (shutdown)
public void shutdown() {
running = false;
lock.lock();
try {
condition.signalAll();
} finally {
lock.unlock();
}
consumerExecutor.shutdown();
try {
if (!consumerExecutor.awaitTermination(5, TimeUnit.SECONDS)) {
consumerExecutor.shutdownNow();
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
- 서버 종료 시, 큐에 남아있는 로그를 저장하고 안전하게 종료.
- 최대 5초 대기 후 강제 종료 (
shutdownNow()호출).
🗂 전체 처리 흐름 (Mermaid 시퀀스 다이어그램)
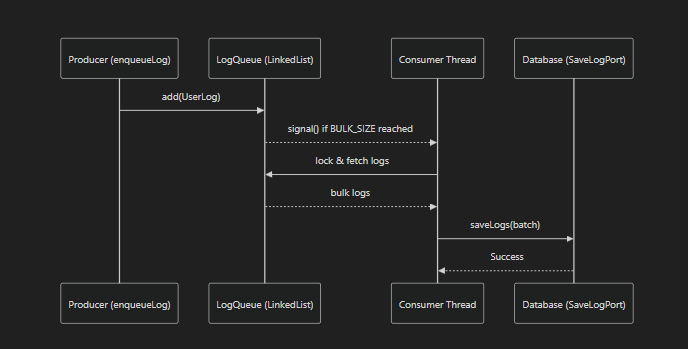
📌 설명:
enqueueLog()가 호출되면 로그를LinkedList에 저장- 로그가
BULK_SIZE를 초과하면condition.signal()을 호출해 즉시 처리 Consumer Thread가lock을 잡고poll()을 통해 배치 로그 가져오기- 로그를 DB에 저장 후 성공 응답
🚀 개선 효과 테스팅
기존 MVC 방식과 큐 + Thread를 도입한 개선 방식에 대해 Jmeter 부하 테스팅을 통한 성능 분석
1. TPS 비교
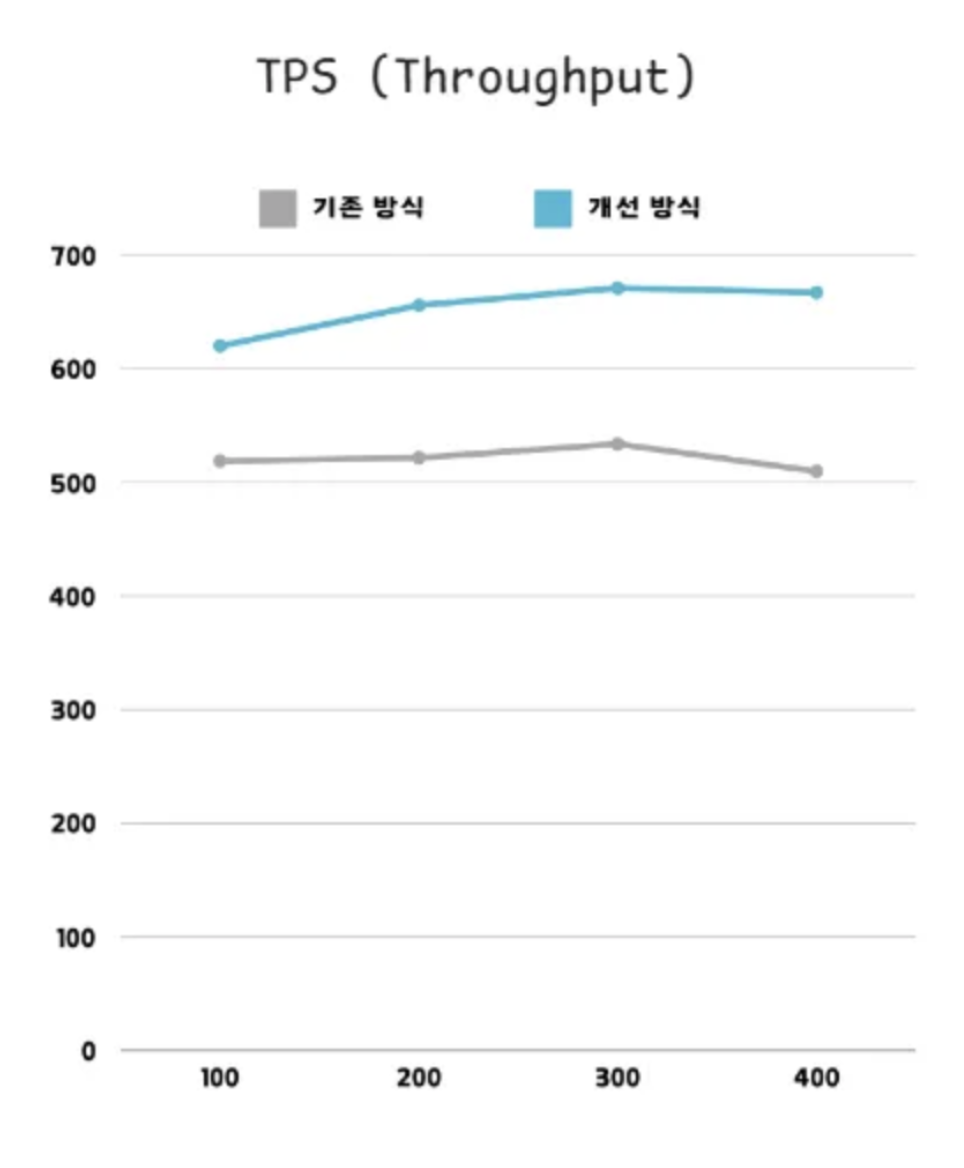
📊 TPS 분석 결과
| 사용자 수 | 기존 방식 (Sync TPS) | 개선 방식 (Async TPS) | 향상 배율 (배) |
|---|---|---|---|
| 100명 | 518.8 | 620.0 | 1.20배 (20% 증가) |
| 200명 | 521.7 | 655.9 | 1.26배 (26% 증가) |
| 300명 | 533.8 | 671.0 | 1.26배 (26% 증가) |
| 400명 | 509.8 | 667.2 | 1.31배 (31% 증가) |
⇒ async 방식을 적용하여 기존 방식 대비 최대 31%까지 TPS 향상 시켜 백엔드 성능 개선
2. AVG_RES (평균 응답 시간) 비교
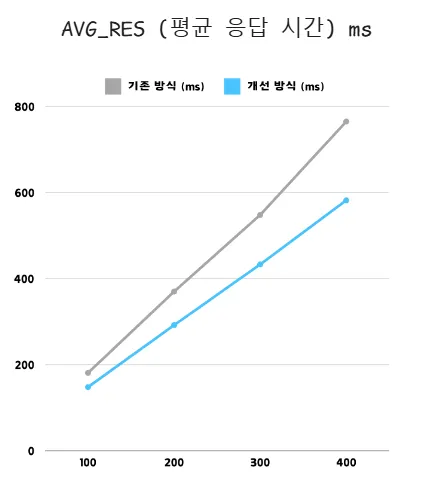
📊 평균 응답 시간(Average Response Time) 분석 결과
| 사용자 수 | 기존 방식 (Sync, ms) | 개선 방식 (Async, ms) | 향상 배율 (배) |
|---|---|---|---|
| 100명 | 181 | 148 | 1.22배 (22% 감소) |
| 200명 | 370 | 292 | 1.27배 (27% 감소) |
| 300명 | 548 | 433 | 1.27배 (27% 감소) |
| 400명 | 765 | 582 | 1.31배 (31% 감소) |
⇒ 평균 응답 시간 개선을 기존 방식에 비해 평균 1.27배 단축 (약 27% 성능 향상)
- 기존 방식의
사용자 증가 시 응답 시간이 급격히 증가문제점 개선
3. Execution Time (총 실행 시간) 비교
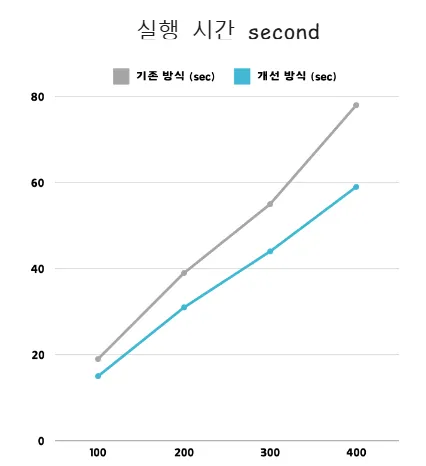
📊 실행 시간(Execution Time) 분석 결과
| 사용자 수 | 기존 방식 (Sync, 초) | 개선 방식 (Async, 초) | 향상 배율 (배) |
|---|---|---|---|
| 100명 | 19 | 15 | 1.27배 (27% 감소) |
| 200명 | 38 | 31 | 1.23배 (23% 감소) |
| 300명 | 55 | 44 | 1.25배 (25% 감소) |
| 400명 | 78 | 59 | 1.32배 (32% 감소) |
⇒ 실행 시간 개선율: 기존 방식 대비 평균 1.27배 단축 (약 27% 성능 향상)
💡 최종 정리
✅ ReentrantLock + Condition을 사용하여 동기화된 큐 관리
✅ ExecutorService를 활용한 비동기 배치 처리
✅ TPS 증가, 응답 시간 단축, DB 부하 감소 효과
✅ 서버 종료 시 안전하게 로그 저장 (shutdown 처리)
📌 결론: 기존 동기 방식보다 최대 31% 성능 향상, TPS 증가 및 실행 시간 단축! 🚀

열시미 해야쥐