
사진 업로드 API: UX 설계 판단에서 성능 최적화까지
사용자에게 즉각적인 피드백을 주기 위해 AI 분석을 동기로 설계했지만, 부하 테스트에서 동시 접속 시 19초 지연이라는 한계를 발견하고, UX와 성능 사이의 trade-off를 판단하여 0.2초로 개선한 과정을 정리합니다.
문제 상황
냉비서(냉장고 비서)는 사용자가 식품 사진을 촬영하면 AI가 자동으로 제품명, 카테고리, 소비기한을 분석해주는 앱입니다.
그런데 한명일때는 상관없지만 다수일 경우 사진 업로드가 느렸습니다.
사용자가 사진을 찍고 업로드 버튼을 누르면, 응답이 돌아올 때까지 수십 초를 기다려야 했습니다. 한 명이 사용할 때는 1~2초 , 여러 명이 동시에 사용하면 30초를 넘기는 상황이었습니다.
왜 처음에 이렇게 만들었는가
이 동기 호출(Precheck)을 넣은 이유가 있었습니다. 사용자가 사진을 흔들리게 찍거나, 식품이 아닌 이미지를 올리거나, 인식이 불가능한 사진을 업로드하는 경우가 있습니다. 이런 상황에서 사용자에게 즉각적인 피드백("이 사진은 인식할 수 없습니다")을 주고 싶었습니다.
비동기로 처리하면 사용자는 업로드가 성공한 줄 알고 앱을 닫는데, 나중에 Push 알림으로 "분석 실패"를 받게 됩니다. 이보다는 업로드 시점에 바로 알려주는 것이 더 나은 UX라고 판단했고, 실제로 한 명이 사용할 때는 Gemini 응답이 약 1~2초면 돌아왔기 때문에 체감상 전혀 문제가 없었습니다.
하지만 부하 테스트에서 이 설계의 한계가 드러났습니다. 처음에는 1명이 연속으로 API를 호출하는 시나리오에서 요청이 밀리는 현상을 발견했습니다. 그걸 보고 동시 사용자 수를 점진적으로 올려보니, 사용자 수에 비례해서 응답이 선형적으로 느려지는 패턴이 확인되었습니다.
1. 부하 테스트로 병목 식별
테스트 환경
| 항목 | 값 |
|---|---|
| 서버 | Spring Boot 3.5 / Java 17 / 2 vCPU |
| DB | PostgreSQL + HikariCP (max 10) |
| AI | Google Gemini 2.5 Flash |
| 스토리지 | NCP Object Storage |
| 테스트 도구 | k6 (20 동시 사용자, 10회 API 호출) |
| 모니터링 | Grafana + Prometheus + Spring Boot Actuator |
왜 20 VU인가
VU를 높이지 않은 이유는 두 가지입니다.
첫째, 비용 문제입니다. 이 API는 요청마다 Gemini AI를 호출합니다. 높은 VU로 장시간 동시 호출하면 AI API 비용이 급격히 늘어나고, 개인 프로젝트에서 감당하기 어려운 수준이 됩니다.
둘째, 20 VU로 충분히 문제가 드러났습니다. VU 1에서도 Gemini 응답이 약 1초 걸리는 상황에서, 동시 사용자가 늘어나면 선형적으로 느려지는 패턴이 명확하게 관측되었습니다. 병목의 원인을 식별하는 데 VU 100이 필요하지 않았습니다. 20명이면 "동시 접속 시 선형 지연 증가"라는 핵심 문제를 정량적으로 확인하기에 충분했습니다.
1회차 결과: 평균 19.5초
k6로 20명의 동시 사용자가 사진을 업로드하는 시나리오를 실행했습니다.
| 구분 | 값 |
|---|---|
| 평균 | 19,477ms (19.5초) |
| P95 | 31,391ms (31.4초) |
| 최대 | 32,209ms (32.2초) |
| 성공률 | 100% |
성공률은 100%였지만, 응답 시간이 문제였습니다. 특히 동시 사용자가 늘어날수록 응답이 선형으로 느려지는 패턴이 관측되었습니다.
요청 1~2 (1명 사용): 2~5초
요청 3~6 (3~8명 동시): 10~21초 ← 동시 사용자 수에 비례하여 증가
요청 7~10 (8명+ 동시): 25~32초Grafana 모니터링: 서버는 한가했다
Grafana를 확인하니, 서버 리소스는 여유로웠습니다.
| 리소스 | 사용률 |
|---|---|
| CPU | 0.1% |
| Heap 메모리 | 21% |
| GC Pressure | 0% |
| 스레드 | 31 → 37 (peak) |
CPU가 0.1%인데 응답이 19초? 서버 성능이 부족한 게 아니었습니다. 서버는 대부분의 시간을 아무것도 하지 않고 외부 API 응답을 기다리는 데 쓰고 있었습니다.
2. 원인 분석: 코드를 따라가 보니
API 엔드포인트의 코드를 따라가 보았습니다.
개선 전 플로우
@Transactional
public Result execute(Long userSeq, MultipartFile productImage) {
// 1. AI 쿼터 체크 ~50ms
aiRequestGuardService.acquireForBasic(userSeq, key);
// 2. Gemini AI에 사진 전송 (동기 블로킹) 5~32초 ← 여기가 문제
AnalysisResult precheck = geminiService.analyze(imageBytes); // WebClient.block()
// 3. NCP 스토리지에 이미지 업로드 ~100ms
storageUploadService.upload(image);
// 4. DB에 아이템 저장 ~20ms
fridgeItemRepository.save(item);
// 5. 비동기 상세 분석 요청 ~0ms
photoAnalysisWorker.analyzeAsync(itemId);
return result;
}문제가 보였습니다. 2번 단계에서 Gemini AI에 사진을 보내고 응답이 올 때까지 동기적으로 기다리고 있었습니다. 이 "Precheck" 호출이 전체 응답 시간의 95% 이상을 차지했습니다.
더 큰 문제는, 이 동기 호출이 @Transactional 안에 있었다는 점입니다.
@Transactional 시작 → DB 커넥션 획득
│
├── 쿼터 체크 (DB 사용) ~50ms
├── ★ Gemini 대기 (DB 미사용) 5~32초 ← DB 커넥션이 잡혀만 있음
├── 스토리지 업로드 (DB 미사용) ~100ms ← DB 커넥션이 잡혀만 있음
├── DB 저장 (DB 사용) ~20ms
│
@Transactional 종료 → DB 커넥션 반환실제 DB를 쓰는 시간은 ~70ms인데, 커넥션은 30초 넘게 점유되고 있었습니다. HikariCP 풀이 10개이므로, 동시 11번째 요청부터는 커넥션을 확보하지 못해 추가 지연이 발생합니다.
비동기 워커도 같은 문제가 있었습니다.
@Async
@Transactional // ← Gemini 호출 동안 DB 커넥션 점유
public void analyzeAsync(Long itemId, byte[] imageBytes) {
entity = fridgeItemRepository.findById(itemId); // ~20ms DB 사용
result = geminiService.analyze(imageBytes); // 5~96초 DB 미사용, 커넥션 점유만
fridgeItemRepository.save(entity); // ~20ms DB 사용
}최악의 경우 워커 하나가 96초 동안 DB 커넥션을 점유했습니다 (Gemini 재시도 3회 × 32초).
정리: 3가지 문제
| 문제 | 영향 |
|---|---|
| Gemini Precheck가 API 동기 경로에 있음 | 응답 시간 5~32초 |
| @Transactional이 Gemini 호출을 포함하여 메서드 전체를 감싸고 있음 | DB 커넥션 30~96초 점유 |
| Gemini 장애 시 보호 장치 없음 | 60초 타임아웃까지 무한 대기 |
3. 개선: 3가지 변경
과제 1. Gemini Precheck 제거 (핵심)
API 동기 경로에서 Gemini 호출을 완전히 제거하고, 기존 비동기 워커에서 처리하도록 변경했습니다.
API 동기 경로에서 Precheck를 제거하되, 기존 Precheck가 담당하던 비식품 판별(NOT_FOOD) 역할을 비동기 워커에 추가했습니다. Precheck 로직이 사라진 게 아니라, 비동기 워커가 Precheck 역할까지 함께 수행하도록 변경한 것입니다.
[개선 전]
API → 쿼터 체크 → ★ Gemini(5~32초) → Storage → DB → 응답
└→ 비동기 워커에서 Gemini 호출
[개선 후]
API → 쿼터 체크 → Storage → DB → 응답
└→ 비동기 워커에서 Precheck + Gemini 분석비식품 이미지 판별 결과는 Push 알림으로 사용자에게 전달하도록 변경했습니다.
과제 2. 트랜잭션 범위 3분할
비동기 워커의 @Transactional을 제거하고, TransactionTemplate으로 DB 작업 구간만 짧게 감쌌습니다.
@Async // @Transactional 제거
public void analyzeAsync(Long itemId, byte[] imageBytes) {
// Phase 1: 짧은 트랜잭션 — 상태 마킹 (~30ms)
PrepareResult prepare = transactionTemplate.execute(status -> {
FridgeItemEntity entity = fridgeItemRepository.findById(itemId).orElse(null);
entity.setBasicAnalysisStatus(AnalysisStatus.PROCESSING);
return new PrepareResult(entity.getName(), ...);
});
// Phase 2: 트랜잭션 없음 — Gemini 호출 (5~32초, DB 커넥션 없음!)
AnalysisResult result = geminiService.analyze(imageBytes);
// Phase 3: 짧은 트랜잭션 — 결과 저장 (~30ms)
transactionTemplate.executeWithoutResult(status -> {
FridgeItemEntity entity = fridgeItemRepository.findById(itemId).orElse(null);
entity.setProductName(result.productNameGuess());
// ... 결과 반영
});
}| 항목 | 개선 전 | 개선 후 |
|---|---|---|
| 워커 1건당 DB 커넥션 점유 | 5~96초 | ~60ms |
| 점유 시간 단축 | - | 99.9% |
과제 3. Circuit Breaker 추가
Gemini API 장애 시 전체 서비스가 마비되는 것을 방지하기 위해 Resilience4j Circuit Breaker를 적용했습니다.
@CircuitBreaker(name = "gemini", fallbackMethod = "fallback")
public AnalysisResult analyze(byte[] imageBytes) {
// Gemini API 호출
}
private AnalysisResult fallback(byte[] imageBytes, Throwable t) {
return fallbackRejected(AiRejectReason.OTHER,
"AI 분석 서비스가 일시적으로 불안정해요. 잠시 후 다시 시도해 주세요.");
}최근 10건 중 50% 이상 실패하면 회로를 열어 즉시 fallback을 반환합니다.
4. 결과: 동일 조건 2회차 부하 테스트
3가지 개선을 적용하고, 1회차와 동일한 조건(20 VU, 10회 호출)으로 다시 테스트했습니다.
응답 시간 비교
| 구분 | 1회차 (개선 전) | 2회차 (개선 후) | 개선율 |
|---|---|---|---|
| 평균 | 19,477ms | 188ms | 99.0% (104배) |
| P95 | 31,391ms | 473ms | 98.5% (66배) |
| 최대 | 32,209ms | 688ms | 97.9% (47배) |
| 최소 | 5,271ms | 80ms | 98.5% (66배) |
| 성공률 | 100% | 100% | 유지 |
지연 패턴 비교
1회차: 동시 사용자 증가 → 선형 지연 증가
─────────────────────────────────────────
요청 1~2 (1명): 2~5초
요청 3~6 (3~8명): 10~21초 ← Gemini 큐잉으로 선형 증가
요청 7~10 (8명+): 25~32초
2회차: 동시 사용자 증가해도 평탄 유지
─────────────────────────────────────────
요청 1 (첫 연결): 688ms ← TLS 핸드셰이크
요청 2~5 (1명): 80~210ms ← 이미지 크기에 비례
요청 6~10 (4명): 82~186ms ← 동시 접속해도 지연 증가 없음1회차에서 보였던 "동시 사용자 → 선형 지연 증가" 패턴이 완전히 사라졌습니다.
Grafana 모니터링 비교
두 테스트를 같은 Grafana 타임라인에서 비교하면, 차이가 극명합니다.
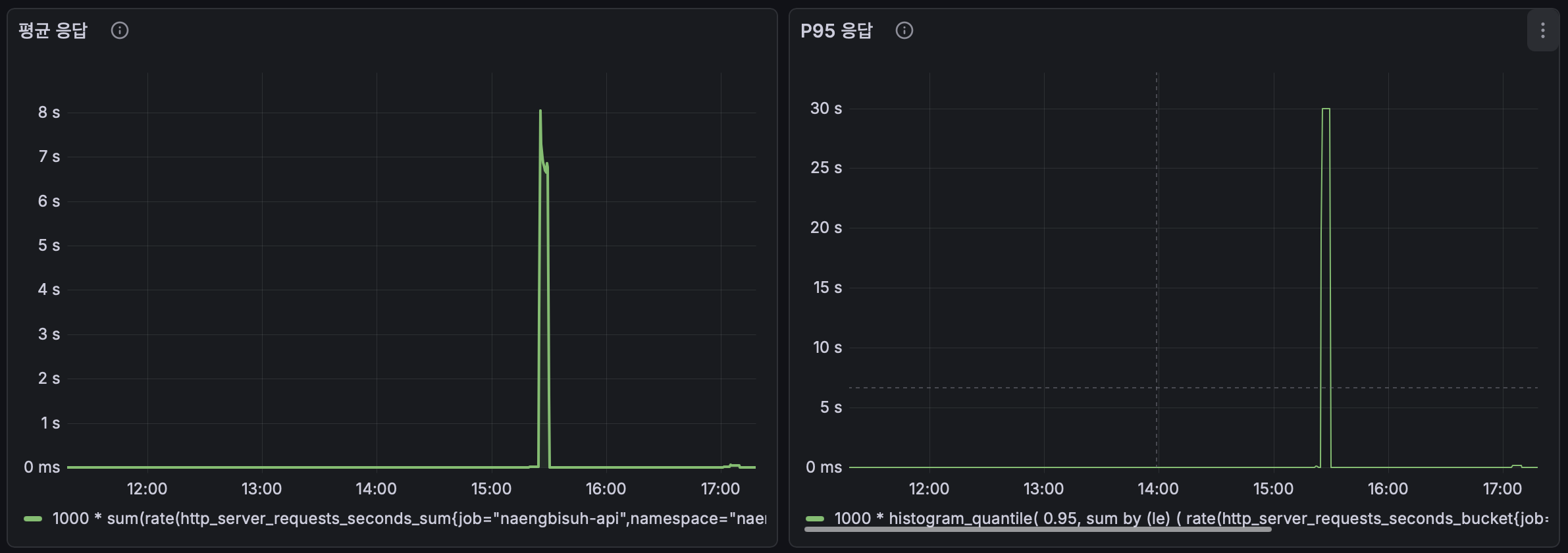
15:00 부근의 큰 스파이크가 1회차(개선 전), 17:00 부근의 거의 보이지 않는 변화가 2회차(개선 후)
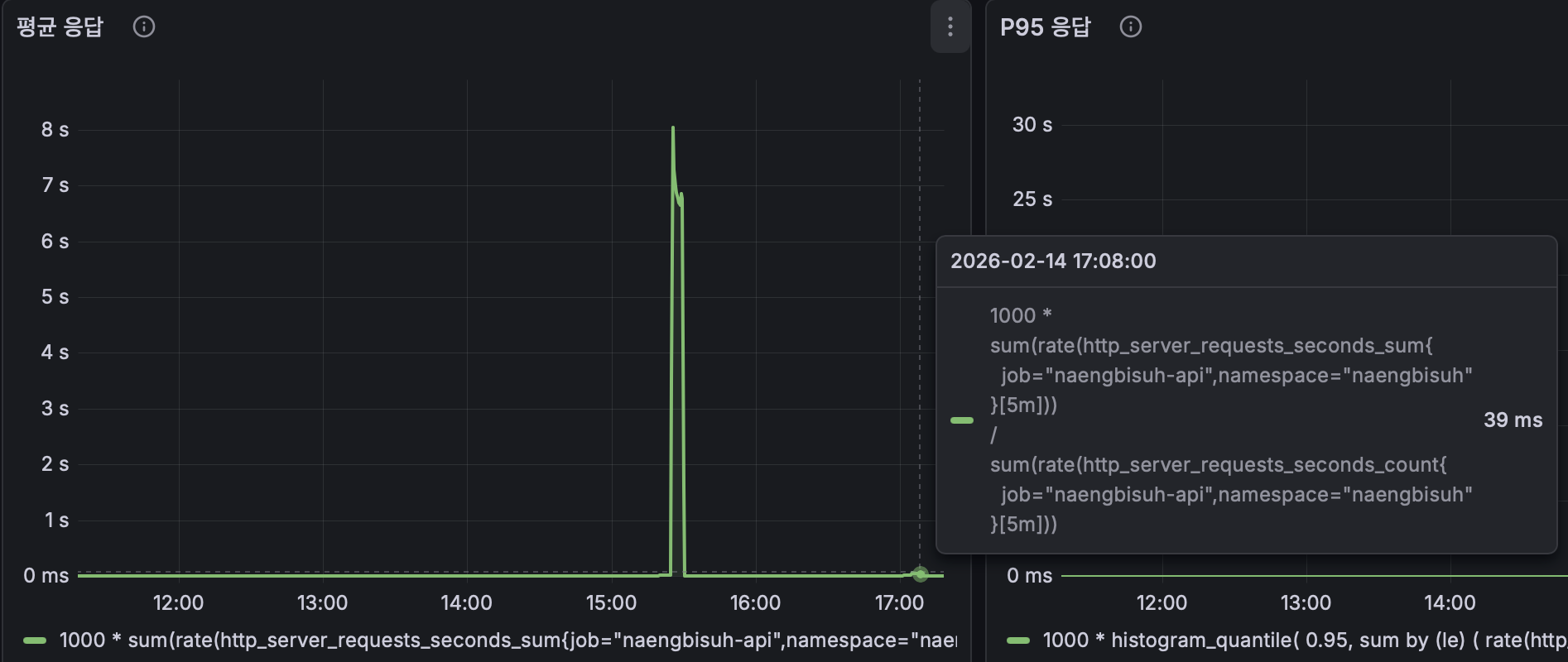
개선 후 Grafana 평균 응답시간: 39ms (1회차: ~8초)
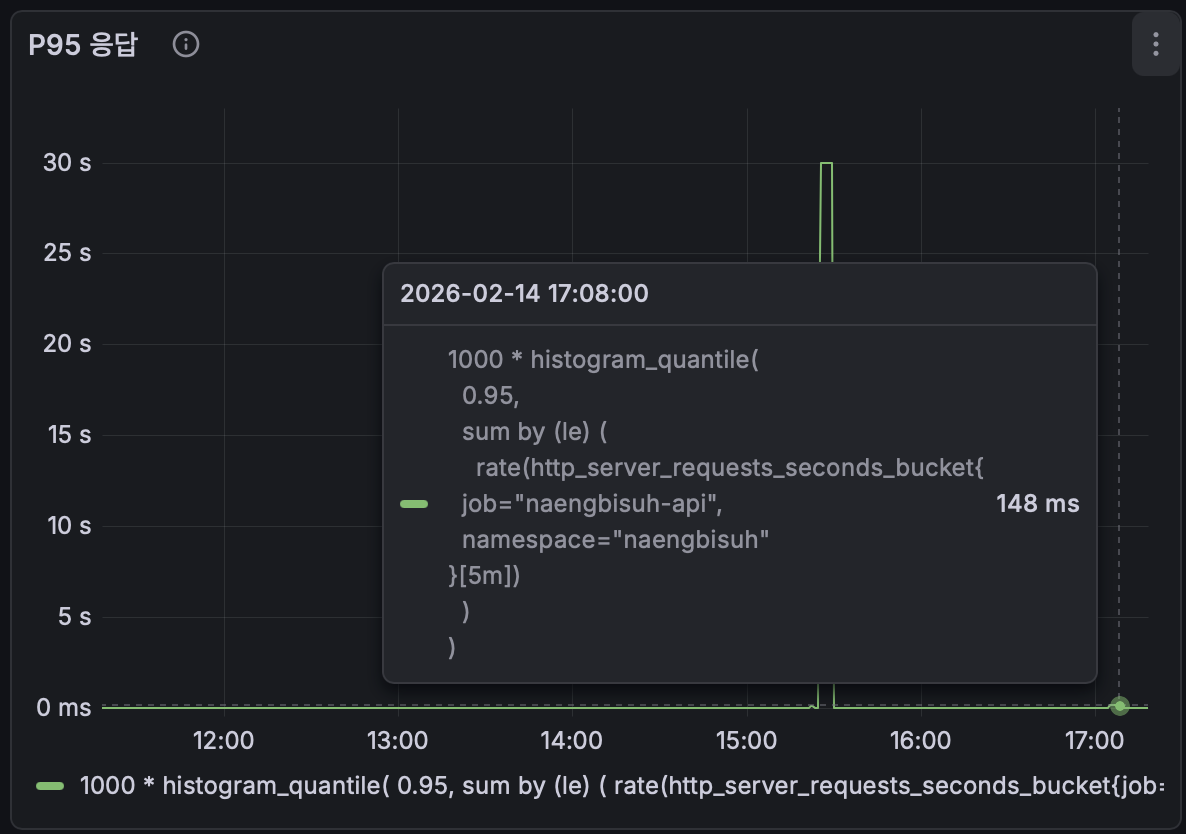
개선 후 Grafana P95 응답시간: 148ms (1회차: ~30초)
Grafana 수치 비교
| 메트릭 | 1회차 | 2회차 | 개선율 |
|---|---|---|---|
| 평균 응답 (피크) | ~8초 | 39ms | 99.5% |
| P95 (피크) | ~30초 | 148ms | 99.5% |
| 5xx 에러 | 발생 | 0% | 해소 |
5. 이 수준의 개선이 가능했던 이유
일반적인 성능 최적화(캐싱, 인덱싱, 스레드풀 조정)와 달리, 이번 개선 폭이 컸던 이유는 병목의 성격이 근본적으로 달랐기 때문입니다. 하드웨어 리소스 부족이 아니라, 아키텍처 설계에서 병목이 발생하고 있었습니다.
전체 응답 시간의 대부분을 차지하는 단일 병목(동기 Gemini 호출)을 제거했으니, 큰 폭의 개선은 자연스러운 결과입니다.
중요한 점은, 이 문제가 서버를 스케일업(CPU, 메모리 증설)해도 해결할 수 없었다는 것입니다. Gemini API의 응답 시간(5~32초)은 서버 성능과 무관합니다. CPU 0.1%인데 응답이 19초라는 사실은, 부하 테스트와 Grafana 모니터링 없이는 직관적으로 파악하기 어렵습니다. "느리니까 서버를 늘리자"가 아니라, "왜 느린지 먼저 측정하자" 가 유일한 해결 경로였습니다.
6. 과제별 효과 정리
| 과제 | 변경 내용 | 효과 | 관측 방법 |
|---|---|---|---|
| Precheck 제거 | API 동기 경로에서 Gemini 호출 제거 | 응답 시간 99% 단축, Gemini 비용 50% 절감 | k6 응답 시간에서 직접 관측 |
| 트랜잭션 3분할 | TransactionTemplate으로 DB 작업만 짧게 감싸기 | DB 커넥션 점유 99.9% 단축 (96초→60ms) | Grafana HikariCP 메트릭 |
| Circuit Breaker | Gemini 장애 시 빠른 실패 반환 | 장애 전파 방지 | 정상 상태에서는 미작동 (방어적 설계) |
7. 배운 것
초기 설계 판단과 운영에서의 학습
Precheck를 동기 경로에 넣은 건, 사용자가 흔들린 사진이나 비식품 이미지를 올렸을 때 즉시 피드백을 주기 위한 의도적인 설계였습니다. 비동기로 처리하면 사용자는 업로드 성공으로 인식하고, 나중에 "분석 실패" 알림을 받게 됩니다. 동기적으로 바로 알려주는 게 UX 관점에서 확실히 나았고, 한 명이 쓸 때는 Gemini 응답이 약 1초면 돌아왔기 때문에 실제로 문제가 없었습니다.
하지만 동시 사용자가 생기면서 "UX를 위한 설계 판단"과 "시스템 확장성"이 충돌하는 지점을 경험했습니다. 이건 전형적인 사용자 경험 vs 성능의 trade-off였습니다. 결론적으로 성능을 선택했습니다.
감수한 리스크가 있습니다. 비동기로 전환하면 AI 분석이 제대로 진행되지 않았을 때(흔들린 사진, 비식품 이미지 등), 사용자는 업로드 시점에 즉각적인 피드백을 받지 못합니다. 이전에는 "이 사진은 인식할 수 없습니다"를 바로 알려줬지만, 이제는 나중에 Push 알림으로 분석 실패를 받게 됩니다. 사용자 입장에서는 사진을 다시 올려야 하는 번거로움이 생기는 것이고, UX적으로 분명 손해입니다.
그래도 이 결정을 한 이유는, 동시 사용자가 늘어날수록 동기 호출의 대가가 기하급수적으로 커지기 때문입니다. 한 명일 때 1초의 편의를 위해 10명이 사용할 때 19초의 지연을 감수할 수는 없었습니다. "한 사람의 편의"보다 "전체 사용자의 안정성"을 선택한 것입니다.
그리고 돌이켜 보면, 19초 대기 자체가 이미 나쁜 UX였습니다. "즉각 피드백"이라는 목적으로 동기 호출을 넣었지만, 동시 사용자가 생기면 그 "즉각"이 19초가 됩니다. 사용자가 "분석 중입니다..." 화면을 19초 동안 바라보고 있는 것과, 0.2초 만에 등록이 완료되고 문제가 있으면 나중에 알림을 받는 것 중 — 실제 사용자 경험은 후자가 낫습니다. 결국 비동기 전환은 성능 개선이면서 동시에 체감 UX도 개선한 결정이었습니다.
이후로는 기능 개발 단계에서부터 "이 외부 호출이 동기 경로에 있어야 하는가?"를 먼저 판단하게 되었습니다.
외부 API를 동기 경로에 넣지 말 것
외부 API(특히 AI 모델)는 응답 시간이 수초~수십 초로 가변적입니다. 이를 API 응답 경로에 동기적으로 넣으면:
- 사용자 체감 응답 시간이 외부 API에 종속됨
- 동시 사용자 증가 시 선형 지연 증가
- @Transactional 안에 있으면 DB 커넥션까지 장시간 점유
동기 경로에는 내가 제어할 수 있는 것만 넣고, 외부 의존성은 비동기로 처리해야 합니다.
모니터링 체계가 곧 문제 해결 능력이다
이번 개선에서 가장 시간을 많이 쓴 건 코드 수정이 아니라 부하 테스트 환경 구축이었습니다. k6 시나리오 설계, Grafana + Prometheus 대시보드 구성, Spring Boot Actuator 메트릭 연동 — 이 인프라가 있었기에 "CPU 0.1%인데 응답 19초"라는 비직관적인 현상을 데이터로 설명할 수 있었습니다.
코드를 고치는 것보다, 무엇을 고쳐야 하는지 찾는 체계를 만드는 게 더 중요합니다.
@Transactional의 범위를 의식할 것
Spring의 @Transactional은 편리하지만, 메서드 전체를 감싸면 외부 API 호출이나 I/O 대기 중에도 DB 커넥션이 점유됩니다. 이번 사례에서 워커 1건당 DB 커넥션 점유가 최대 96초에서 60ms로 줄었는데, 코드 변경은 @Transactional 제거와 TransactionTemplate 적용뿐이었습니다. 특히 비동기 워커에서 이 패턴을 사용하면, 워커가 많아질수록 커넥션 풀이 빠르게 고갈됩니다.
작은 변경이지만 DB 커넥션이라는 유한 자원에 대한 인식이 바뀌는 계기였습니다.
요약
| 개선 전 | 개선 후 | |
|---|---|---|
| API 평균 응답 | 19.5초 | 0.19초 |
| 사용자 체감 | 수십 초 대기 | 즉시 응답 |
| Gemini 동기 호출 | 매 요청마다 | 없음 (비동기 처리) |
| DB 커넥션 점유 | 최대 96초/요청 | ~60ms/요청 |
| Gemini 비용 | 요청당 2회 호출 | 1회 호출 (50% 절감) |
| 장애 보호 | 없음 (60초 타임아웃) | Circuit Breaker |
사용자가 느끼는 변화: "사진 올리면 한참 기다려야 해요" → "바로 올라가요"
테스트 환경: Spring Boot 3.5 / Java 17 / PostgreSQL / Gemini 2.5 Flash / NCP Object Storage / k6 v1.1.0
모니터링: Grafana + Prometheus + Spring Boot Actuator
