4.1 Introduction
CPU Overview
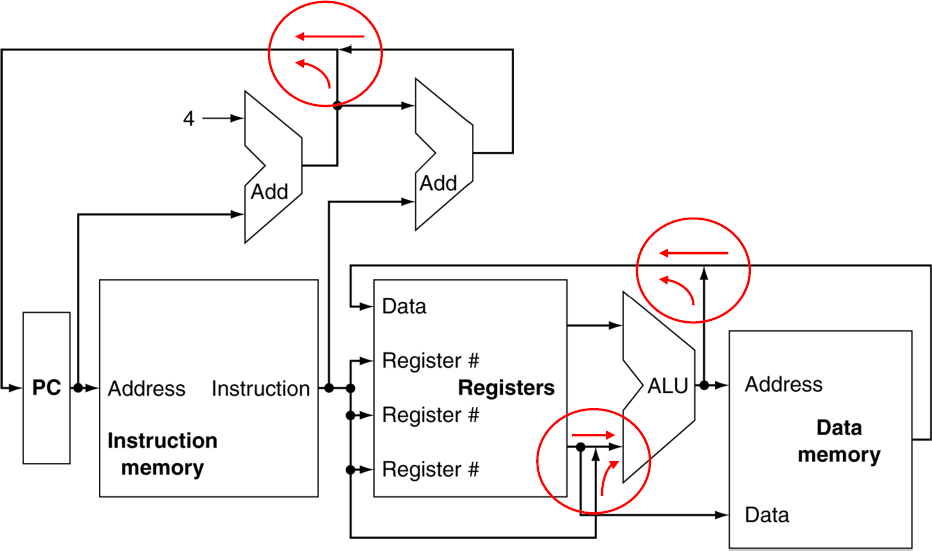
- output이 두개가 만날 수 없다.
원래는 Multiplexer(MUX)를 써서 그 중 하나의 신호를 선택해야 한다.
Control
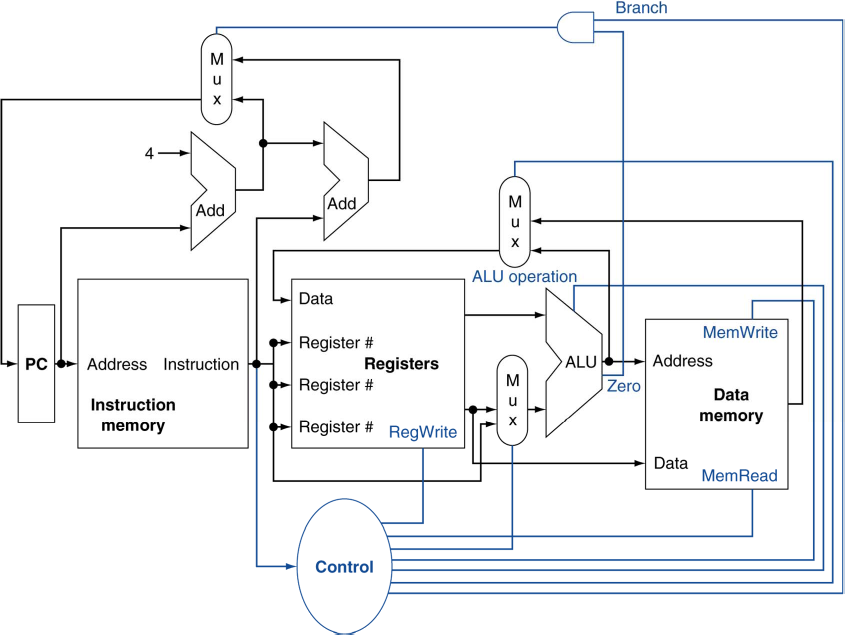
- 각각의 하드웨어가 어떻게 동작하는지를 제어해주는 컨트롤을 만들어주는 회로이다.
- 명령어를 읽어서 해당하는 제어 신호를 만들어냄.
4.2 Logic Design Basics
정보는 binary(0, 1)로 인코딩된다.
combinational element(조합 요소)
- 데이터에 동작함.
- output은 input의 조합.
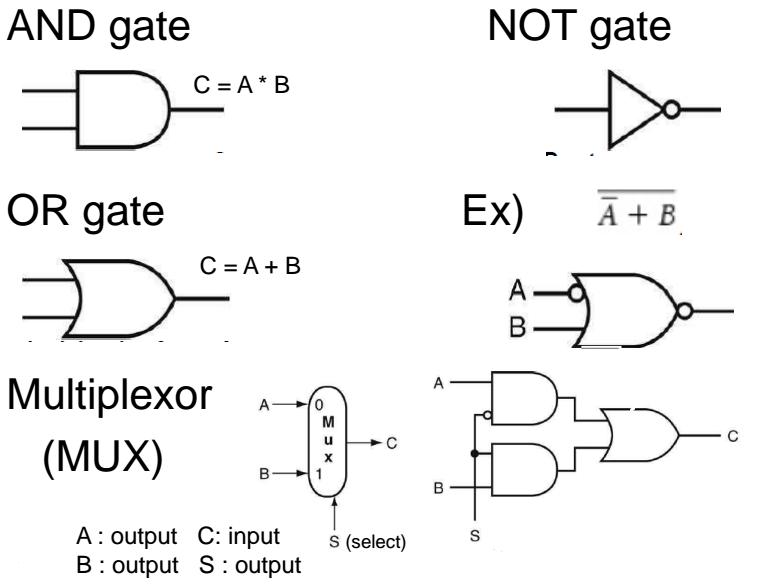
state(sequential) element(상태/순서적 요소)
- 정보를 저장(store)
- Combinational + flip flop
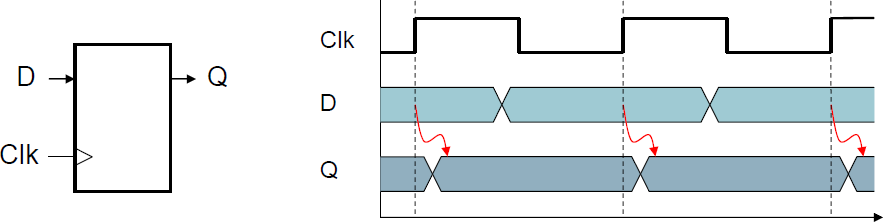
Clocking Methodology

- Combinational logic은 clock cycle동안 데이터를 변형한다.
4.3 Building a Datapath
Datapath
- 데이터가 흐르는 경로
- 연산을 위한 데이터든, 그 결과든 흘러서 어디론가 전달되거나 저장되거나 해야함.
- CPU에서, 프로세스 데이터와 주소들의 요소가 전달되는 길.
R-Format Instructions

- 레지스터
- 산술적/논리적 작업을 수행한다.
- 2개의 read 레지스터를 이용한다.
- 결과를 write 레지스터에 쓴다. - ALU
- 레지스터에서 나온 2개의 Read data input들이 들어간다.
- 결과는 다시 레지스터로 write data에 들어간다.
Load/Store Instructions
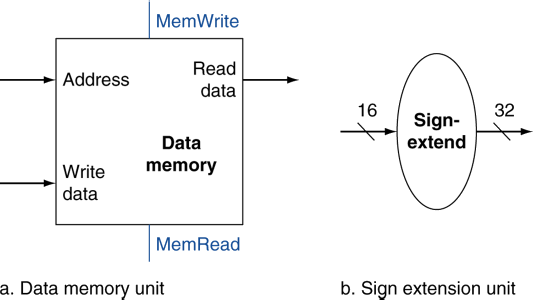
- 대상 레지스터에서 읽는다.
- 16-bit의 offset을 이용하여 주소를 계산한다.
- 주소 계산에 ALU를 사용한다.
- ALU는 32-bit이기 때문에, 32-bit로 확장해서 사용한다.
- Load: 메모리를 읽고, 레지스터를 업데이트한다.
- Store: 레지스터의 값을 메모리에 기록한다.
Branch Instructions
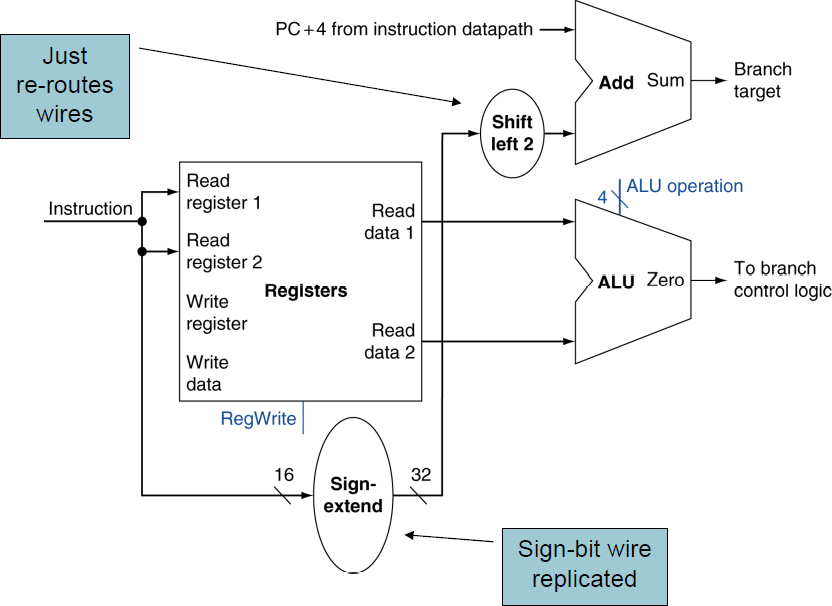
- 대상 레지스터에서 읽는다.
- 피연산자(operand, 위의 두 값)를 비교한다.
- 점프한다면 대상 주소(target address)도 계산해야 한다.
Composing the Elements
- 각 요소들을 통합하여 한 clock cycle에 동작할 수 있도록 한다.
- 한 clock cycle에 하나의 instruction만 실행한다.
- data source가 교차하는 곳에서는 multiplexer를 사용하여 다른 instruction에 다른 경로로 대응할 수 있도록 한다.
R-Type/Load/Store Datapath

4.6 Pipelining Analogy
병렬처리(Parallelism)은 성능을 향상시켜준다.
ex) pipeline화된 빨래: 겹치는 실행.
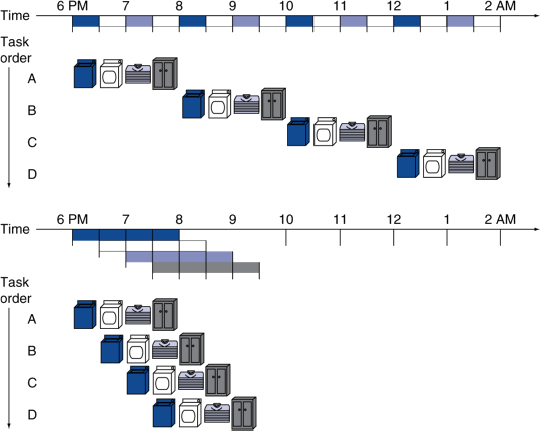
4번의 연속된 작업
- 속도향상
8 / 3.5 = 2.3배의 성능향상
계속(continuous)
- 속도향상
2n / 0.5n +1.5(pipeline이 꽉 찰 때까지 걸리는 시간) ≒ 4
= stage(pipe)의 수. "stage의 수"배 만큼 성능향상
RISC-V Pipeline
stage마다 다음 중 하나의 단계를 수행한다.
- IF: 메모리로부터 Instruction Fetch (메모리로부터 명령어 불러옴)
- ID: Instruction Decode & register read (명령어 해석, 레지스터 read)
- EX: EXcute operation(작업 실행) 혹은 calculate address(주소 계산)
- MEM: access MEMory operand (메모리에 접근)
- WB: Write result Back to register (레지스터에 결과를 다시 기록)
Pipeline 성능
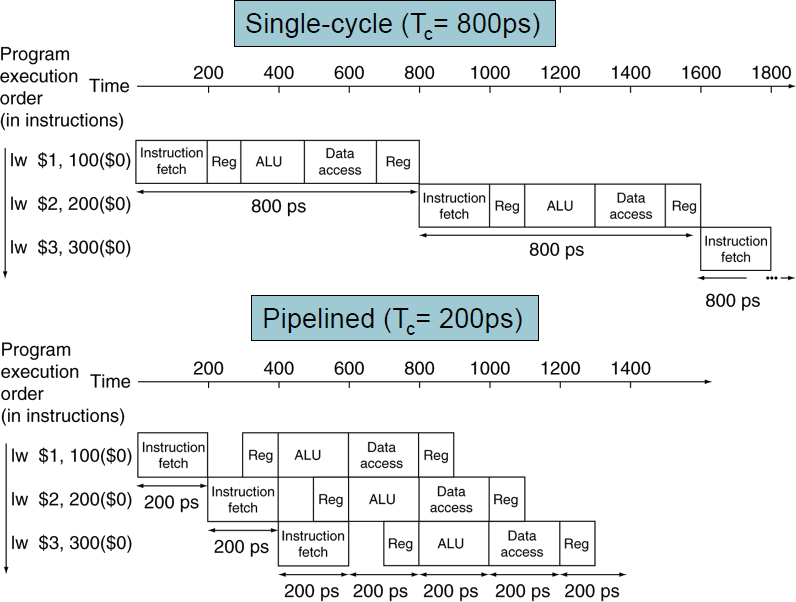
모두 같은 시간이라면 "stage의 수"배의 성능향상 효과.

모든 stage가 균등하지 않다면, 속도향상의 효과는 더 적을 것이다.
- 가장 느린 stage에 맞춰지므로.
- 총 시간이 800ps이지만, 한 stage가 700ps라면, 다른 stage는 대기해야하고 결국 700ps..
속도향상은 throughput을 늘려서 얻은 결과이다.
- 병렬식으로 동시에 여러 instruction을 실행시킴으로써.
- 지연시간(latency, 각 instruction 하나 실행에 걸리는 시간) 자체는 줄어들지 않음.
Pipelining and ISA Design
RISC-V ISA는 pipelining에 적합한 구조이다.
-
모든 instruction은 32-bit이다.
- 한 cycle 안에 fetch하고 decode하기 쉬움.
- c.f. x86: 1~17-byte(8~136-bit)의 다양한 길이
-
적은 종류의, 규격화된(regular) instruction format.
- 한 번에 decode하고 레지스터를 read 가능
-
Load/Store addressing
- 주소 계산은 3번째 stage에서, 메모리 접근은 4번째 stage에서 이루어짐.
- 즉, stage별로 다른 작업을 수행할 수 있음.
-
memory operand의 정렬(alignment. 주소가 4byte씩 되어있다.)
- memory access는 한 싸이클 안에 이뤄진다.
Hazards
다음 싸이클에서, 다음 instruction이 실행되는 것을 막아버리는 상황이 발생할 수 있다.
즉, 매 cycle마다 instruction을 실행해야 할텐데, 그렇지 못하는 상황이 발생할 수 있다.
-
Structure Hazard(구조적 위험)
instruction을 수행하기 위해 필요한 하드웨어 자원이 사용중(busy)일 수 있다. -
Data Hazard(데이터 위험)
instruction을 수행하기 위해 필요한 데이터가 있는데,
다른 instruction이 데이터를 read/write 하고 있다면(그 데이터가 busy 상태라면),
완료하기까지 기다려야 한다. -
Control Hazard(제어 위험)
어떤 instruction을 수행하기 위해 다른 instruction의 결과에 의존하는 경우.
제어 행동을 결정하는 것이 이전의 instruction에 의존하는 경우.
Structure Hazards
하드웨어 자원을 이용하는 것에서의 충돌
단일(single) 메모리를 사용하는 RISC-V pipeline에서
- Load/Store 명령은 data 접근을 위해 memory에 접근한다.
- instruction fetch도 instruction을 가져오기 위해 memory에 접근한다.
- 서로 동시에 진행될 순 없으므로, 한 쪽은 대기를 해야하고, 해당 cycle을 지연( stall)시킬 수 있다.
- pipeline에 "bubble"을 야기할 수 있다.
그러므로, pipeline화된 datapath는 instruction memory와 data memory가 분리되어야 한다.
대부분의 Structure Hazard는 resource의 부족으로 인해 발생하며,resource를 추가하면 해결되는 경우가 많다.
Data Hazards
instruction은 다른 instruction이 데이터에 접근하는 것이 완전히 끝나는 것에 의존적이다.
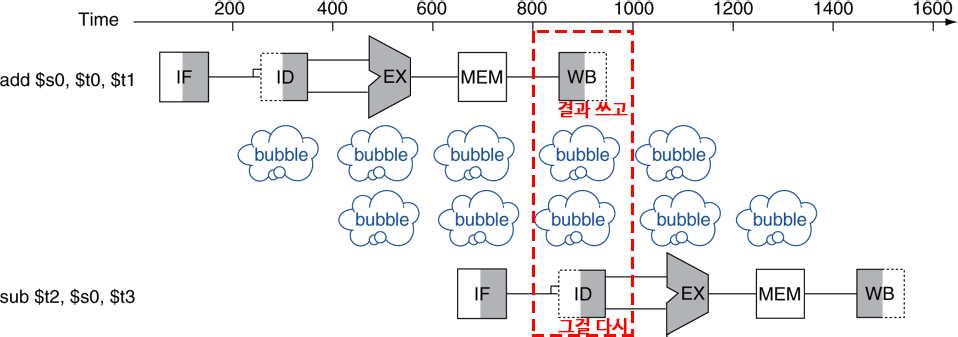
Forwarding
계산된 직후의 결과를 바로 사용
레지스터에 write back되는 것을 기다리지 않음(store까지 기다리지 않음).
datapath에 추가적인 연결이 필요하다.
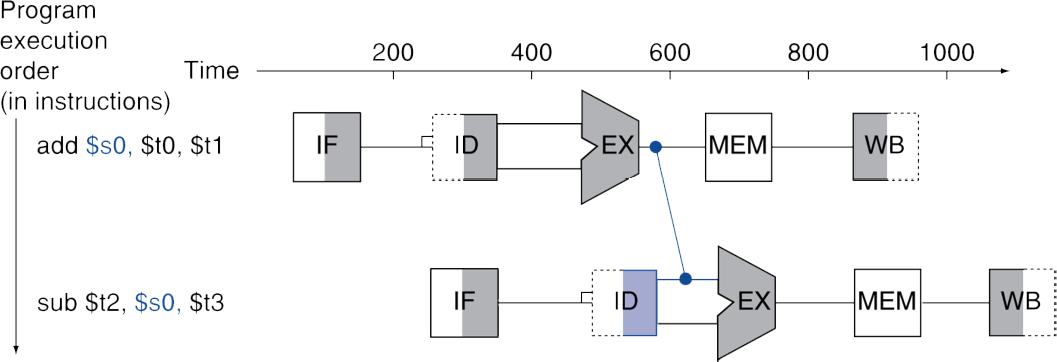
Load-Use Data Hazard
항상 forwarding(aka bypassing)으로 모든 stall을 피할 수는 없을 수도 있다.
결과가 필요한 순간에 아직 계산이 완료되지 않았다면, 제 때에 값을 끌어올 수도 없이 "존재하지도 않는다면" 활용도 불가능하다.
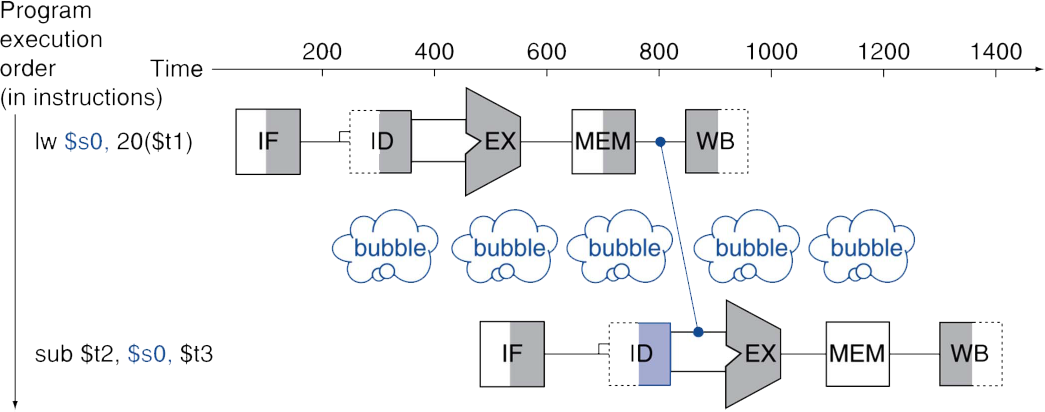
최대한 줄여도 1cycle의 stall이 발생.
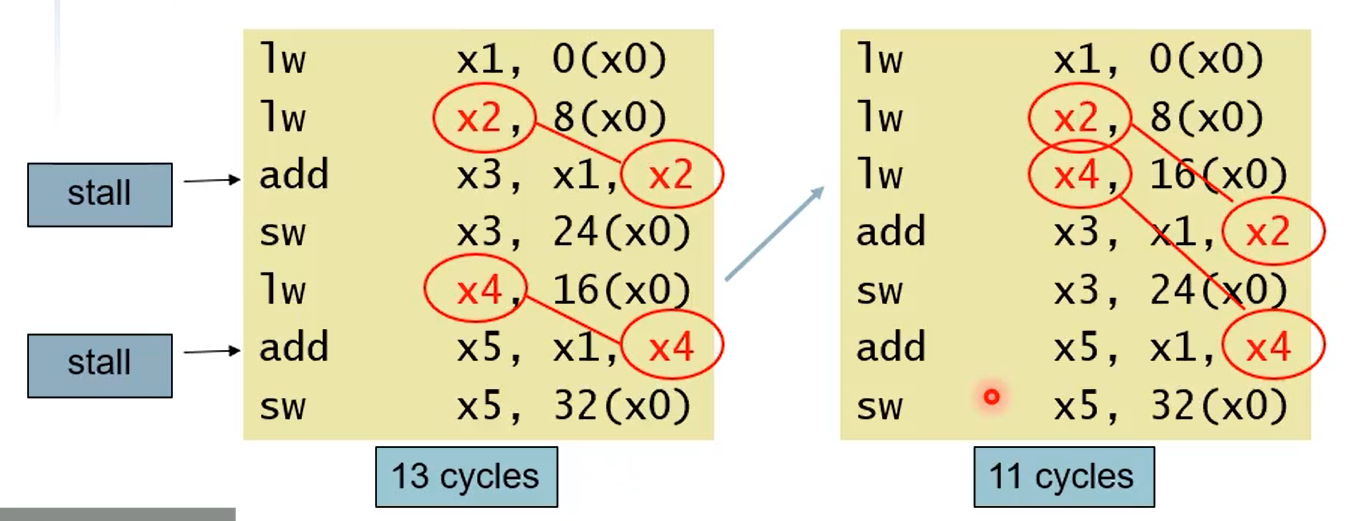
Code Scheduling to Avoid Stalls
코드의 순서를 바꿈으로써, 다음 instruction에 필요한 결과값 load 과정에서 발생할 stall을 회피한다.
Control Hazards
제어 신호로 인해 프로그램의 flow가 바뀔 수 있는 상황이다.
- 그래서 flow가 바뀔지도 모르기 때문에 직후 명령어들이 바로 실행되지 못하는 hazard.
Stall on Branch
branch에서의 stall
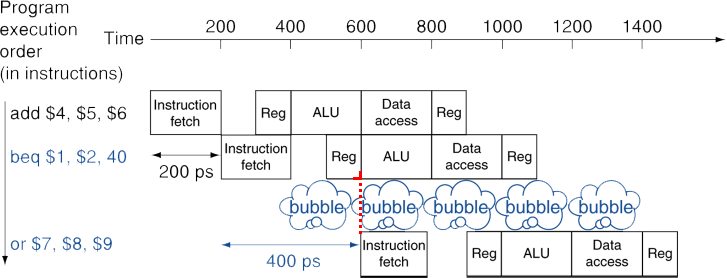
ID stage에 하드웨어를 추가하여 미리 비교를 하고 주소를 계산했더라도, ID stage가 끝나야 알 수 있으므로, 1 cycle stall.
Branch Prediction
branch 결과를 예측
Static branch prediction
- 전형적인(typical) branch 동작(behavior)에 기인한다(based on).
- 예시: loop와 if문 branch
- 되돌아가는(backward, 위로 -~) branch는 일어날 것으로 예상(가정)한다. 해당 주소의 IF.
- 진행하는(forward, 아래로 +~) branch는 일어나지 않을 것으로 예상(가정)한다. PC+4의 IF.
*정확도는 떨어질 수 있음.
Dynamic branch prediction
- 하드웨어가 실제의(actual) branch 동작(behavior)을 측정한다(measure).
- e.g. 각 branch의 최근 history를 기록한다(record).
- 미래의(future) 동작은 그동안의 경향(trend)을 따를 것으로 가정한다.
- 그게 틀린다면, 당연히 그 때는 stall이 발생하고 re-fetcing이 일어날 것임.
- istory는 잘되는 못되든 항상 기록될 것이고, stall이 발생하면 점차 수정되어 trend도 변할 것임.
*정확도는 높아지지만, history 기록과 trend 측정에 자원과 시간 소요.
4.7 Pipelined Datapath and Control
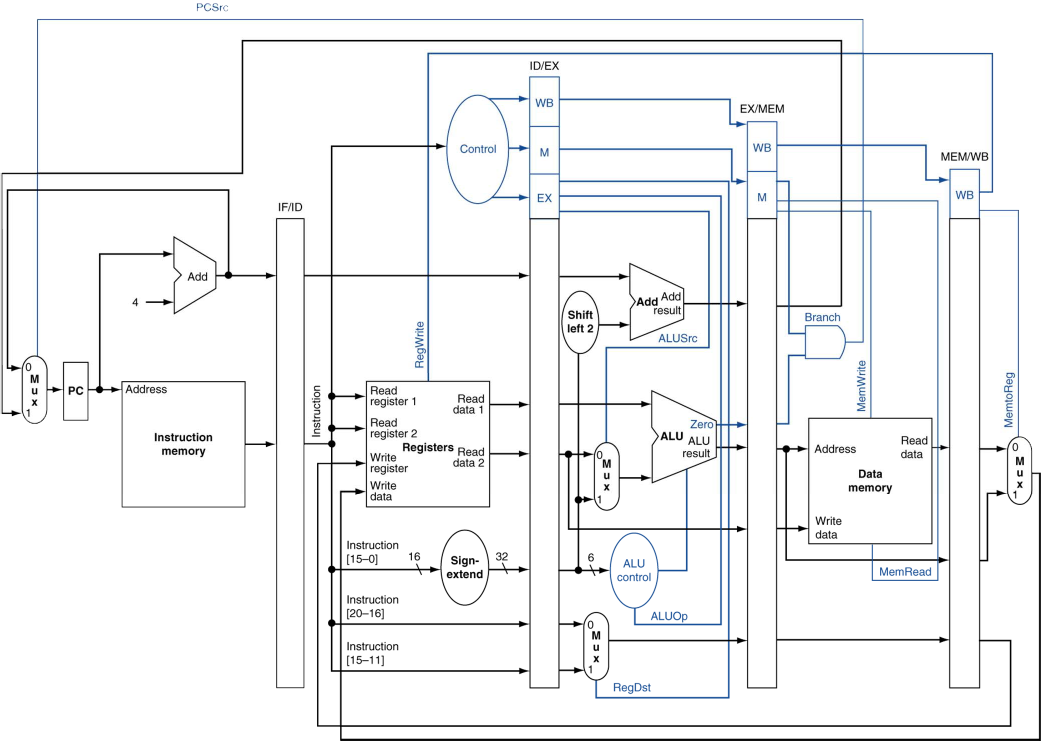
RISC-V Pipelined Datapath
예전에 본 개략도는 single-cycle이고, 이제는 muilti(pipelined).
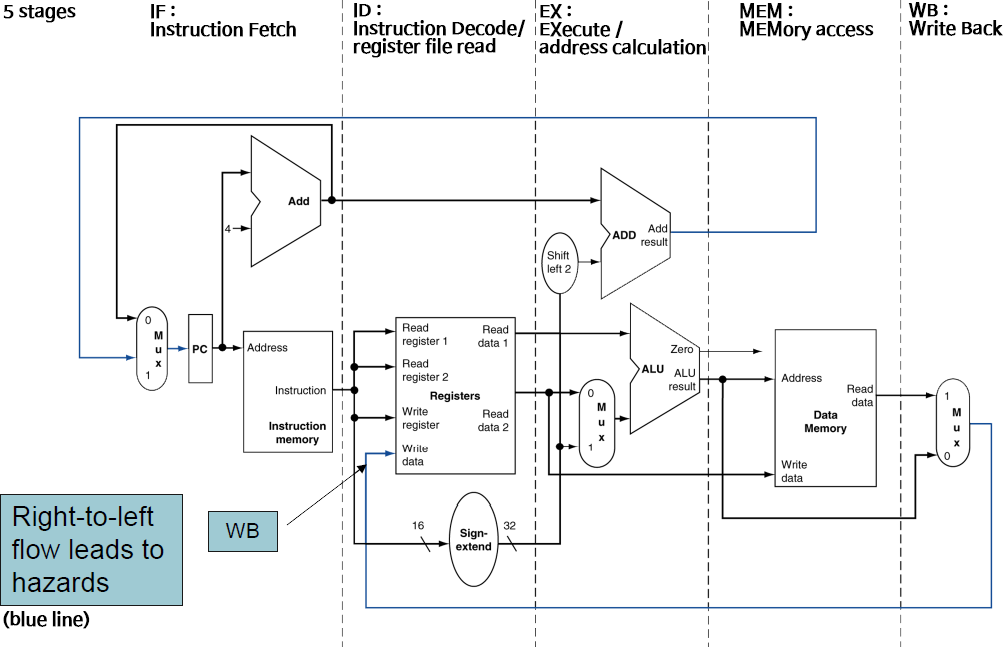
Pipeline registers
이전 cycle에서 만들어진 정보를 가지고 있어야 하기 때문에 각 stage 사이에 레지스터들이 필요하다.
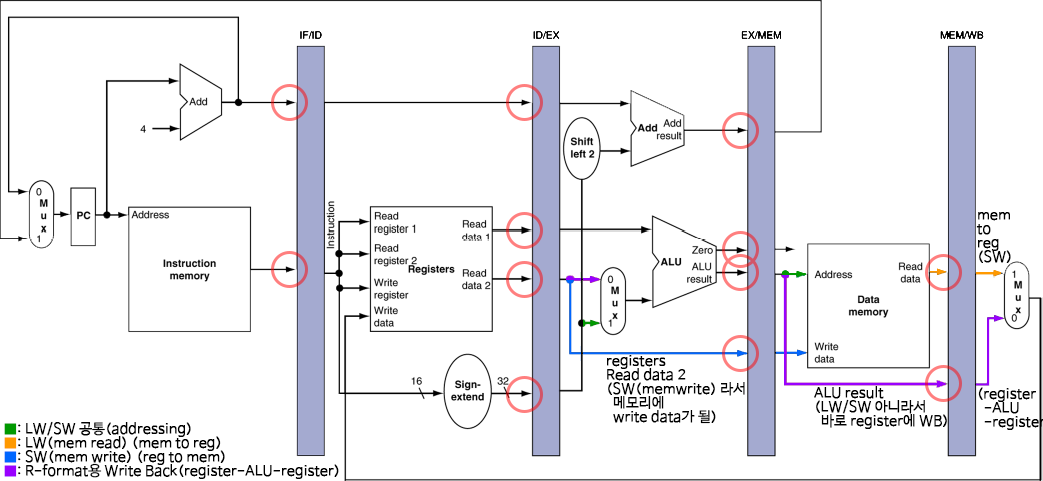
Multi-Cycle Pipeline Diagram
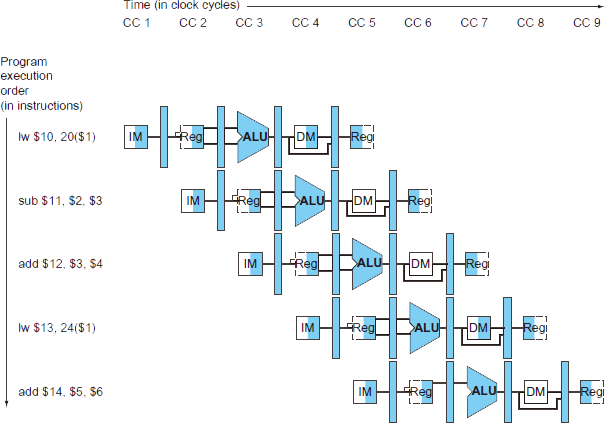
Pipelined Control
Control signal(제어신호)는 instruction으로부터 파생된다.
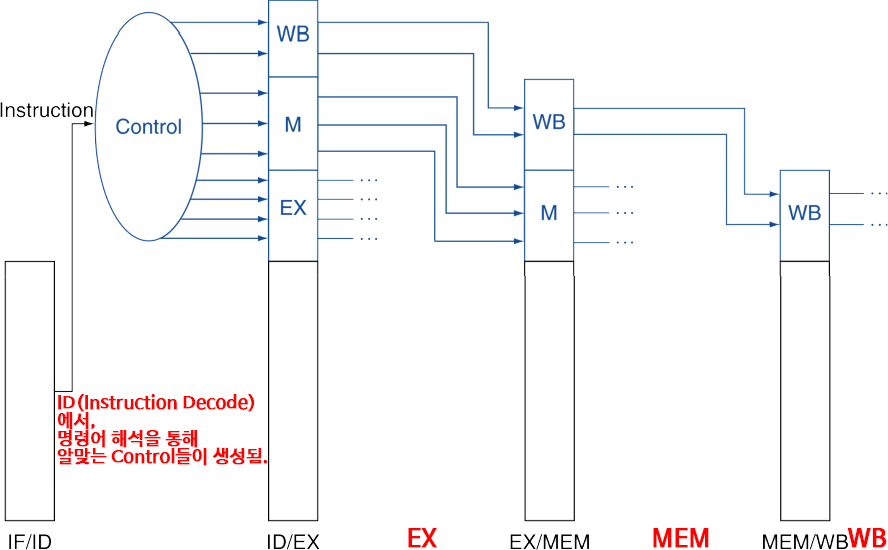
각 stage에 control들이 전달되기 위해, pipeline register(각 stage간 레지스터)에 함께 전달되어 보존되어야 한다.
4.8 Data Hazards: Forwarding versus Stalling
Dependencies & Forwarding
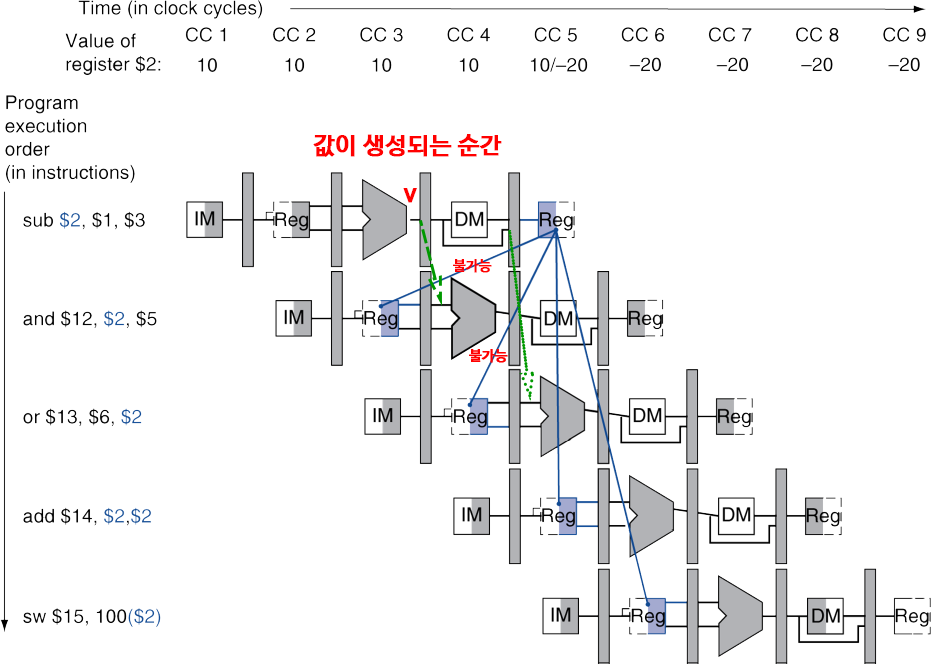
다음 cycle 기준으로는 EX/MEM 레지스터가 생성된 값을 가지고 있고,
다다음 cycle 기준으로는 EX/MEM 레지스터에는 이미 다른 값으로 덮혔지만,
MEM/WB 레지스터에 해당 값을 가지고 있다.
Detecting the Need to Forward
Forwarding이 필요한 순간을 감지해내기
pipeline을 통해 레지스터 번호를 넘겨준다
EX stage에서의 ALU 피연산자 레지스터 번호는 다음과 같다.
- ID/EX.RegisterRs1, ID/EX.RegisterRs2
Data hazard가 발생하는 경우는 아래의 4가지 경우.

-
1a/b
(다음 cycle의 instruction)EX의 Rs/Rt(피연산자들)가
(이전 cycle의 instruction)MEM의 Rd가 같을 때.
즉, WB을 위한 대상 레지스터에 값이 쓰이고, 다른 명령어가 그걸 읽어야 하는데,
아직 값이 쓰이지 않아서.
1cycle 전의 instruction에서, EX직후에서 "계산된 Rd에 쓰일 값"을 끌어와서 사용. -
2a/b
(다음 cycle의 instruction)EX의 Rs/Rt(피연산자들)가
(이전 cycle의 instruction)WB의 Rd가 같을 때.
마찬가지로, WB을 위한 대상 레지스터에 값이 쓰이고, 다른 명령어가 그걸 읽어야 하는데,
아직 값이 쓰이지 않아서.
2cycle 전의 instruction에서, "Rd에 쓰일 값이 흐르던 것"을 MEM이후에서 끌어와서 사용.
Forwarding Paths

Forwarding Conditions
-
EX hazard
(EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRs1)
→ ForwardA = 10
(EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRs2)
→ ForwardB = 10 -
MEM hazard
(MEM/WB.RegWrite & MEM/WB.RegisterRd≠0) & (MEM/WB.RegisterRd == ID/EX.RegisterRs1)
→ ForwardA = 01
(MEM/WB.RegWrite & MEM/WB.RegisterRd≠0) & (MEM/WB.RegisterRd == ID/EX.RegisterRs2)
→ ForwardB = 01
Double Data Hazard
다음의 순서를 생각해보자.
add x1, x1, x2
add x1, x1, x3
add x1, x1, x4 → 위의 어느걸 가져오지??
양 쪽 hazard가 모두 일어난다면,
- 좀 더 최근(현재에 가까운) 것을 사용
double일 경우에는 MEM hazard의 조건이 변경된다
- EX hazard가 아닐 경우에만 MEM hazard forwarding.
즉, double이라면, 항상 EX hazard로 보고 EX 직후의 값(1cycle 이전의, 최근의)을 가져오면 된다.
Revised Forwarding Conditions
-
EX hazard (그대로)
(EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRs)
→ ForwardA = 10
(EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRt)
→ ForwardB = 10 -
MEM hazard
(MEM/WB.RegWrite & MEM/WB.RegisterRd≠0)
& not ((EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRs))
& (MEM/WB.RegisterRd == ID/EX.RegisterRs)
→ ForwardA = 01
(MEM/WB.RegWrite & MEM/WB.RegisterRd≠0)
& not ((EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRt))
& (MEM/WB.RegisterRd == ID/EX.RegisterRt)
→ ForwardB = 01
Load-Use Hazard Detection
현재 cycle의 ID stage에서, 향후 instruction에 필요한 부분이 아직 준비되지 않았는지 검사한다.
Load-use hazard는 다음일 때 발생한다.
- ID/EX.MemRead & ( (ID/EX.RegisterRd == IF/ID.RegisterRs1) | (ID/EX.RegisterRd == IF/ID.RegisterRs2) )
- 이전 cycle의 명령어가 MemRead 종류라서, MemRead 신호가 있었고,
현재 cycle의 명령어의 피연산자(Rs1나 Rs2)의 번호가
이전 cycle의 Rd의 번호(메모리에서 읽은 값을 넣을 레지스터 번호)와 같을 경우.
How to Stall the Pipeline
강제로 ID/EX 레지스터의 제어 신호 값들을 모두 0으로 한다.
PC와 IF/ID 레지스터의 갱신을 방지한다.
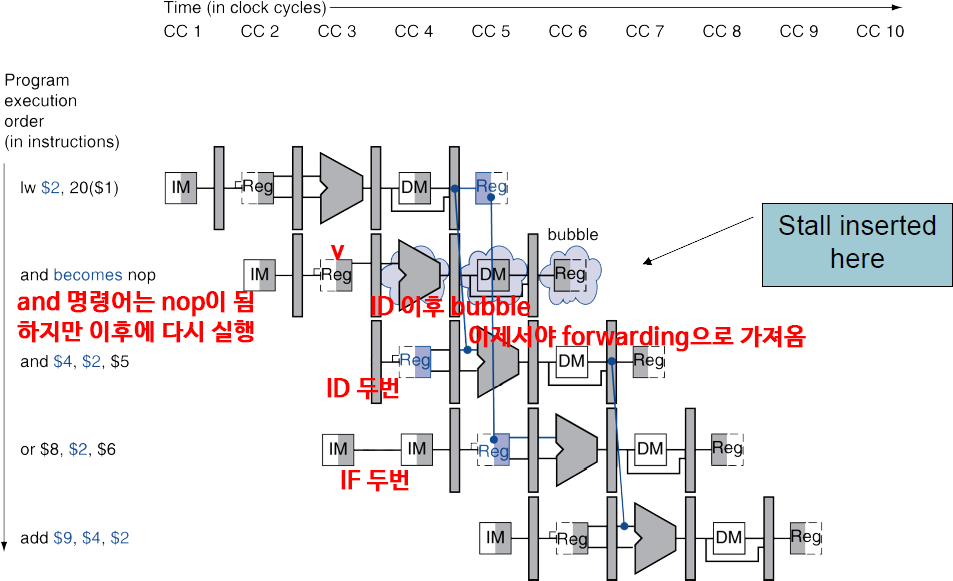
Datapath with Hazard Detection
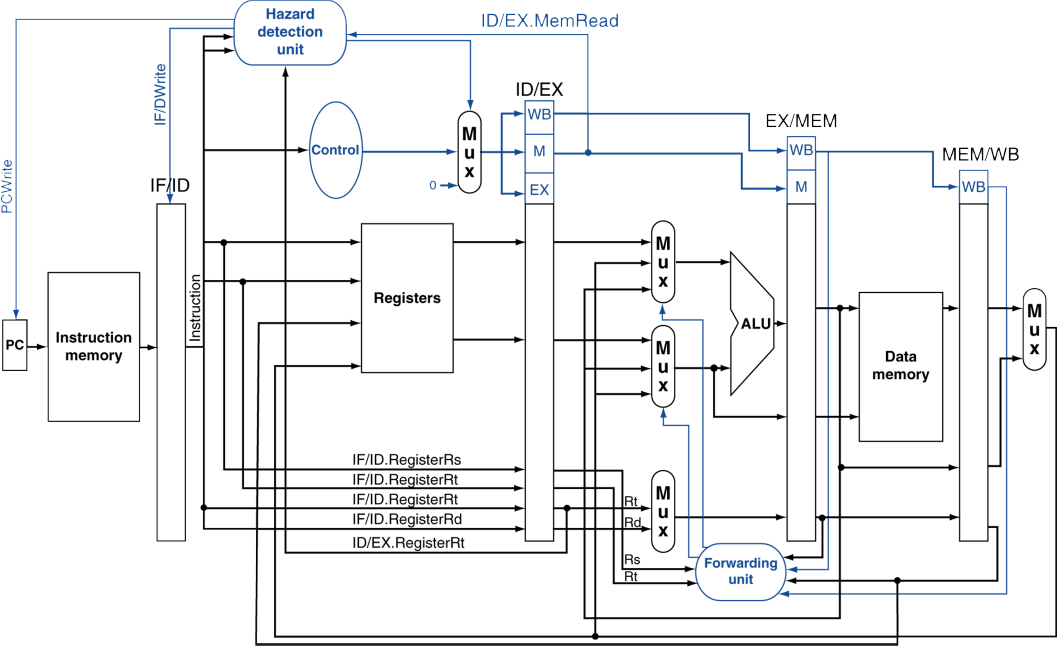
Stalls and Performance
stall은 성능을 저하시킨다. 하지만, 정확한 결과를 얻기 위해서는 꼭 필요하다.
컴파일러는 코드를 재배치해서 hazard를 피하고 stall을 방지할 수 있다.
4.9 Control Hazards
Branch Hazards
branch 결과를 알기 위해 기다리는 것 대신 "아닌 것으로 가정"하여 연속된 명령어를 수행하다가 아니면 그대로, 맞으면 제대로 명령어 가져와서 수행하기로 했었다.
- 만약 결과가 맞으면 그동안 미리 예측하여 수행해둔 명령어는 버려야 함.
- 제어 신호를 0으로 하여 비워야(flush) 함.
Reducing Branch Delay
예측에 실패하더라도 버려지는 단계를 줄여보자
branch 결과를 구하는 걸 ID stage에서 할 수 있도록 하드웨어를 옮긴다.
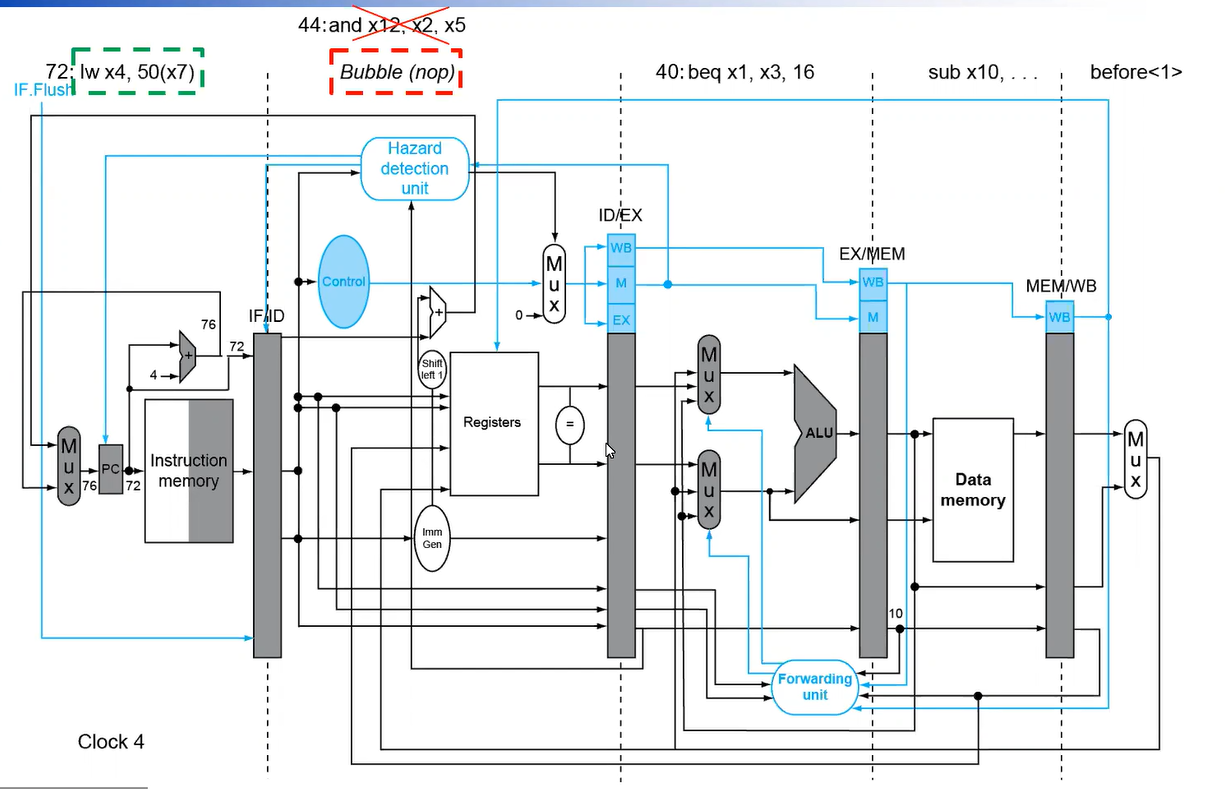
ID stage에서 분기 결과값을 구함으로써, 단 1번(IF 단계였던 직후 명령어)의 bubble만으로 줄일 수 있다.
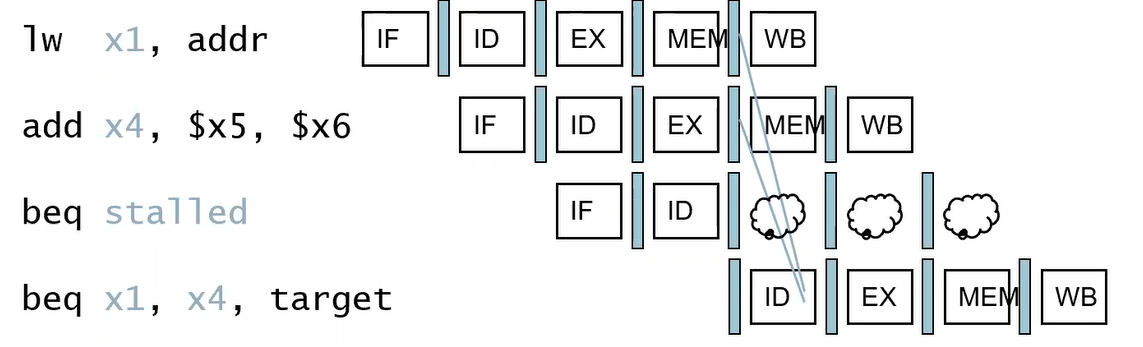
Data Hazards for Branches
만약 branch에서 비교하려는 레지스터가 2-cycle 전이나 3-cycle 전의 ALU instruction 결과(Rd)라면 forwarding을 사용하여 해결할 수 있다.
만약 비교하려는 레지스터가
- 1 cycle 전(바로 직전)의 ALU instruction의 결과(ID/EX.RegisterRd)이거나,
- 2 cycle 전의 load로 불러온 값을 쓸 레지스터(EX/MEM.RegisterRs)라면,
- 1개의 stall이 발생한다.
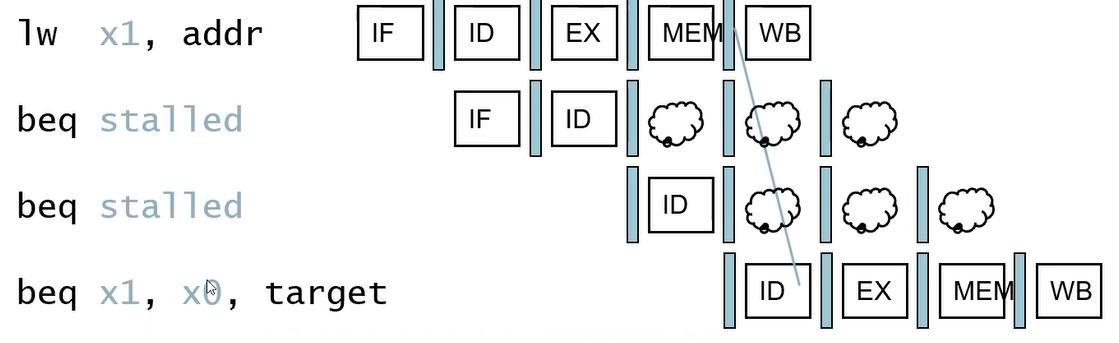
만약 비교하려는 레지스터가 직전의 load로 불러온 값을 쓸 때
- 2개의 stall이 발생한다.
Dynamic Branch Prediction
branch prediction buffer를 둔다.
거쳐온 branch instruction의 주소들을 색인화(index)한다.
분기 결과(outcome)를 저장해둔다(store). taken/not taken
branch를 수행하려면
- 테이블을 살펴보고 추론한 예상을 바탕으로, 이러하길 바라면서 진행하기로 한다.
- 분기 대상이든, 아니라서 연속으로 진행하든, 예상한 대로의 명령어를 가져와서 진행한다.
- 만약 틀렸다면, 예상대로 했던 명령어를 비우고(flush pipeline) 예측을 뒤엎는다(반대의 명령어를 가져온다).
1-Bit Predictor
1-Bit. 바로 전의 결과만 사용하는 경우.
다중 loop에서, 안쪽 loop branch는 예측실패(mispredict)를 두 번 한다.(처음, 마지막)

2-Bit Predictor
두번의 연속된 예측실패(misprediction)이 일어나야만 예측기준의 결과(predictor가 판단할)를 역전한다.
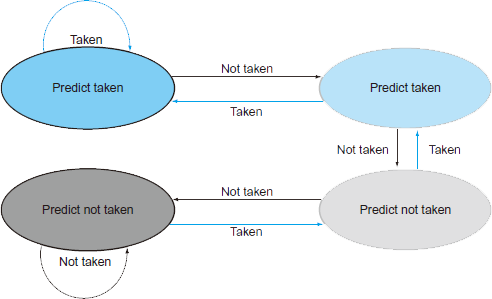
11↔10↔01↔00
Calculation the Branch Target(address)
- branch target buffer
반복될 branch라면 아예 대상 주소(바뀌지 않고 고정된 메모리주소)를 기억해두고 재활용하자.
4.10 Exceptions and Interrupts
Exception(예외)
- CPU 내부에서 발생한다.
e.g, undefined opcode, overflow, syscall, ...
Interrupt(중단)
- 외부 I/O controller(CPU가 아닌 외부장치. OS 등..)로부터 발생한다.
Handling Exceptions
문제가 생긴(offending, interrupted) instruction의 PC(지금 exception이니 지금 PC. 즉, instruction 주소)를 저장한다.
- RISC-V에서는: Supervisor Exception Program Counter(SEPC)에 저장.
문제의 종류(indication. 표시,원인)를 저장한다.
- RISC-V서는: Supervisor Exception Cause Register(SCAUSE)에 저장.
handler로 jump
Handler Actions
원인을 읽고, 관련된 handler로 넘겨준다.
필요한 동작을 결정한다.
만약 해당 명령어를 재시작 가능하다면,
- 적절한 동작으로 시정하여 동작시킨다.
- SEPC를 이용하여 원래의 PC로 돌아갈 수 있도록 한다.
그렇지 않다면,
- 프로그램을 중단한다(terminate).
- SEPC, SCAUSE, ... 등을 이용하여 error를 보고한다(Report error).
Exceptions in a Pipeline
control hazard의 또 다른 형태로 볼 수 있다.
add명령어의 EX stage에서 overflow가 발생했다고 생각해보자.
add x1, x2, x1
- x1에 잘못된 값이 쓰여지는 것을 막는다.
- 이전 명령들은 제대로 완수될 수 있도록 한다.
- add 명령어와 이후 명령어들을 비운다(flush).
- EPC와 Cause Register의 값을 세팅한다.
- handler로 제어권을 넘긴다(handler가 처리할 수 있도록 jump).
Pipeline with Exceptions

Exception Properties
재실행 가능한 명령어에 대한 exception
- pipeline은 명령어를 비운다(flush).
- handler가 처리 후, 원래의 instruction으로 돌아감.
Multiple Exceptions
pipeline은 여러 명령어를 동시에 수행한다. 그러므로 동시에 여러 exception이 발생할 수도 있다.
더 일찍인 instruction(가장 실행 진척도가 높은. 가장 후의 stage인)의 예외부터 처리한다.
복잡한(complex) pipeline에서는,
- cycle마다 여러 명령어를 실행할 수 있다.
- 명령어의 결과 순서가 실행 순서와 같지는 않다(out-of-order).
- 규칙(명령어 순서대로, precise exceptions)을 지키기가 어렵다.
Parallelism via Instructions
Instruction-Level Parallelism (ILP)
ILP를 향상시키기 위한 두 가지 방법.
- Deeper pipeline
- Multiple issue
Multiple Issue
Static multiple issue
- 어떤 명령어가 어느 cycle에서 실행할지 이미 결정이 되어 있는 것(컴파일러가 runtime 전에 결정.).
- 컴파일러가 instruction들이 함께 issue될 수 있도록 묶어줌(group).
- "issue slots"으로 패키지화함(packages them into "issue slots").
- 컴파일러가 hazards를 감지하고 회피시켜 줌.
Dynamic multiple issue
- CPU가 insturction stream을 시험해보고, 각 cycle에 issue할 instruction들을 고름.
- 컴파일러가 instruction의 순서를 재배치함으로써 도와줄 수는 있음.
- runtime 동안에 CPU는 고급 기술(advanced techniques)로 hazard를 해결함.
Speculation
어떤 instruction을 할 것인지 "예상"하는 것
예상이 맞았는지 확인한다.
- 맞았다면, operation을 그대로 진행하여 완수한다.
- 틀렸다면, roll-back하고 올바른 작업을 한다.
ex)
branch의 결과를 추측하는 것
- 만약 틀렸다면 Roll back하고 제대로.
load 명령어에서
- 특정한 메모리 주소에서 값을 읽어오는 것인데,
값이 변하지 않을 경우가 많아서 미리 읽어둔 값을 그대로 사용하려고 함.
그런데 해당 주소의 값이 변했다면 Roll back하고 제대로.
Compiler/Hardware Speculation
컴파일러는 instruction들의 순서를 재배치할 수 있다.
하드웨어는 실행할 instruction들을 내다볼 수 있다
instruction들이 실제로 수행되어야 하는 게 맞았는지 알기 전까지 buffer가 instruction들을 수행하여 결과를 갖고있다가,
- 추측이 맞았으면 그대로 가져다가 쓰고,
- 추측이 실패하면 buffer를 비운다(flush).
