[출처]
https://www.youtube.com/watch?v=Ah9wAY8Hd9A&ab_channel=%EC%B5%9C%EC%9A%A9%EC%A7%84
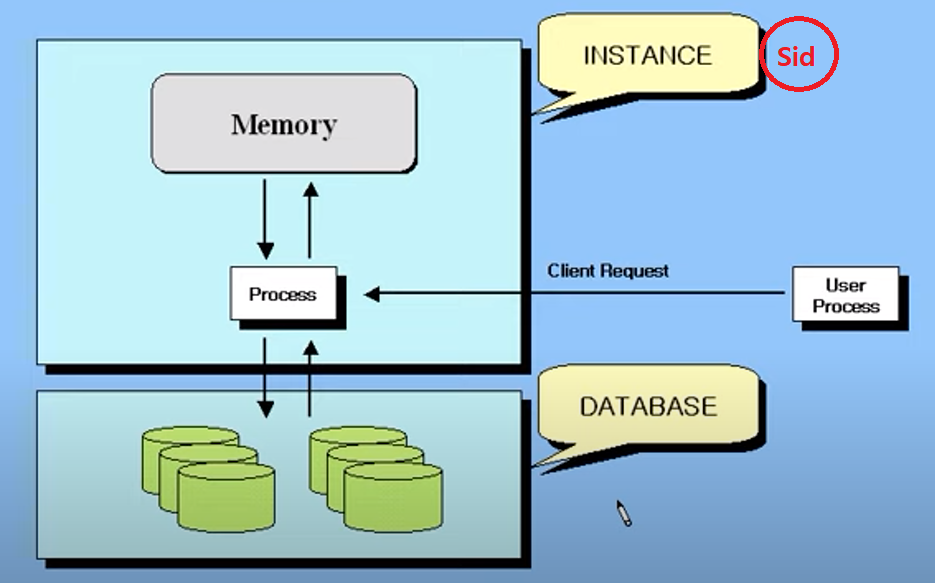
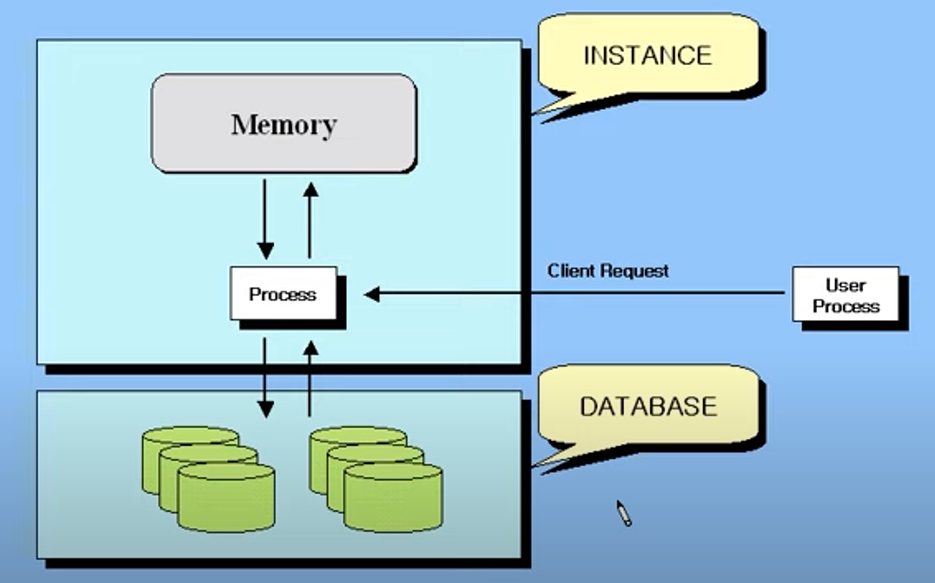
SID는 인스턴스(메모리+프로세스)의 아이디이다.
인스턴스는 SGA와 프로세스로 구성된다고 볼 수 있다.
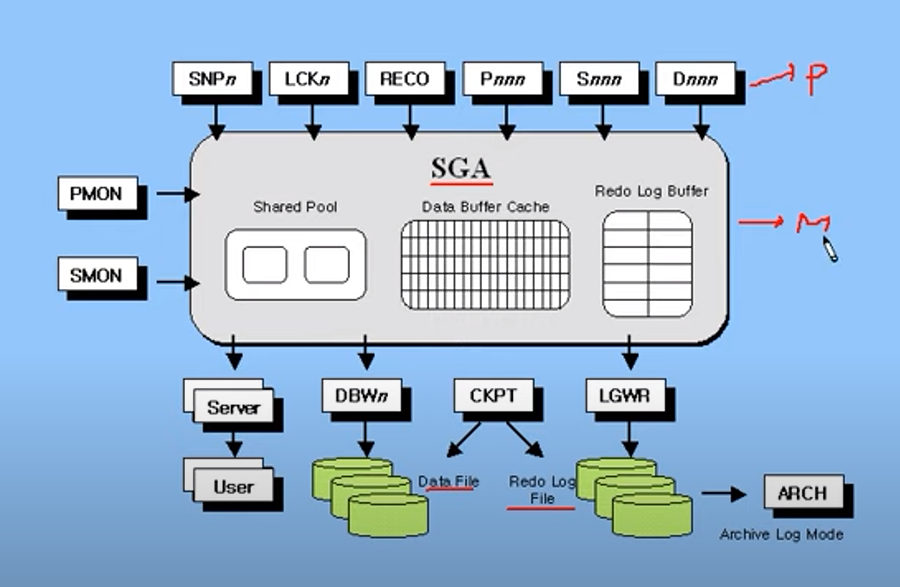
SGA
SGA(System Global Area)가 memory 영역 이고, 흰색 박스들이 process 영역 이다.
- SGA는 Shared Memory 영역이다.
- 오라클 서버가 시작되면 메모리에 SGA가 할당이 된다.
- DBMS에 대한 데이터와 제어 정보를 갖고 있다.
- 여러 사용자간에 공유가 되므로, 간혹 Shared Global Area라고 부르기도 한다.
SGA는 크게 세 부분으로, Shared Pool, Data Buffer Cache, Redo Log Buffer로 나뉘어진다.

Shared Pool
Shared Pool은 다시 Shared SQL Area, Dictionary Cache로 나뉘어진다.
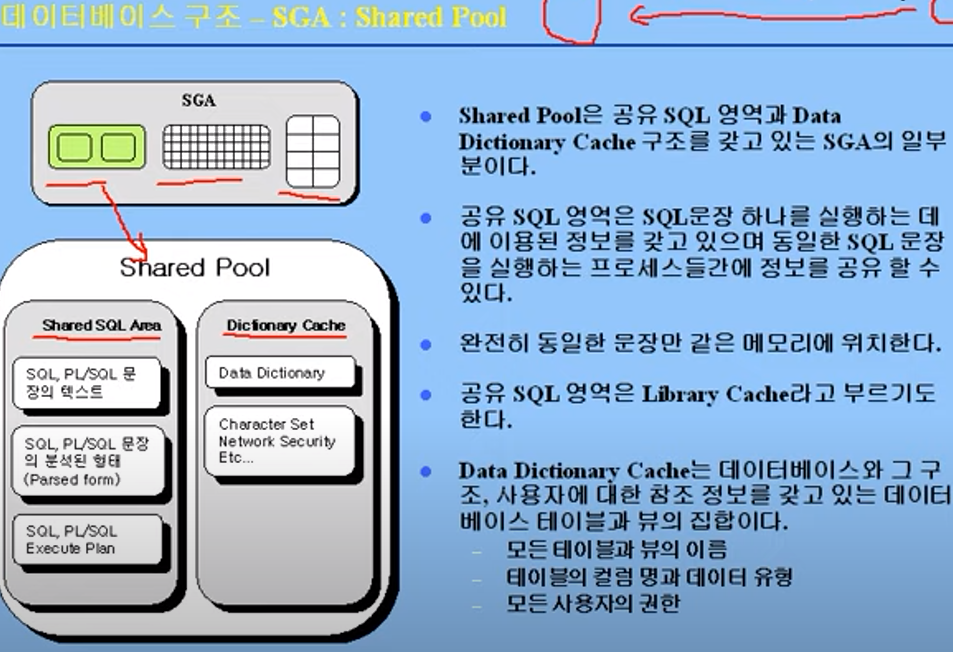
Shared SQL Area
- 사용자가 SQL 문장을 실행했을 때, 해당 문장 자체, 해당 문장의 파싱된 형태, 그리고 실행 계획에 대해 Shared SQL Area에 저장된다.
- 그 후 다시 동일한 문장이 실행될 경우 서로 다른 프로세스들끼리 이것을 공유할 수가 있다.
- 완전히 동일한 문장이면 같은 메모리 주소에 위치해있음.
- Shared SQL Area는 Library Cache라고 부르기도 한다.
Dictionary Cache
-
Dictionary Cache란, data dictionary 정보와 해당 데이터베이스의 논리적 스키마 정보를 담고 있다.
예) 모든 테이블과 뷰의 이름, 테이블의 컬럼 명과 데이터 유형, 모든 사용자의 권한 -
SQL 문장이 실행될 경우, 이 스키마에 IO가 빈번하게 발생할텐데, 이것이 디스크에 있을 경우 빈번한 IO에 의해 디스크 부하가 생길 수 있다. 그래서 SGA에 놓고 빠르게 IO를 진행한다.
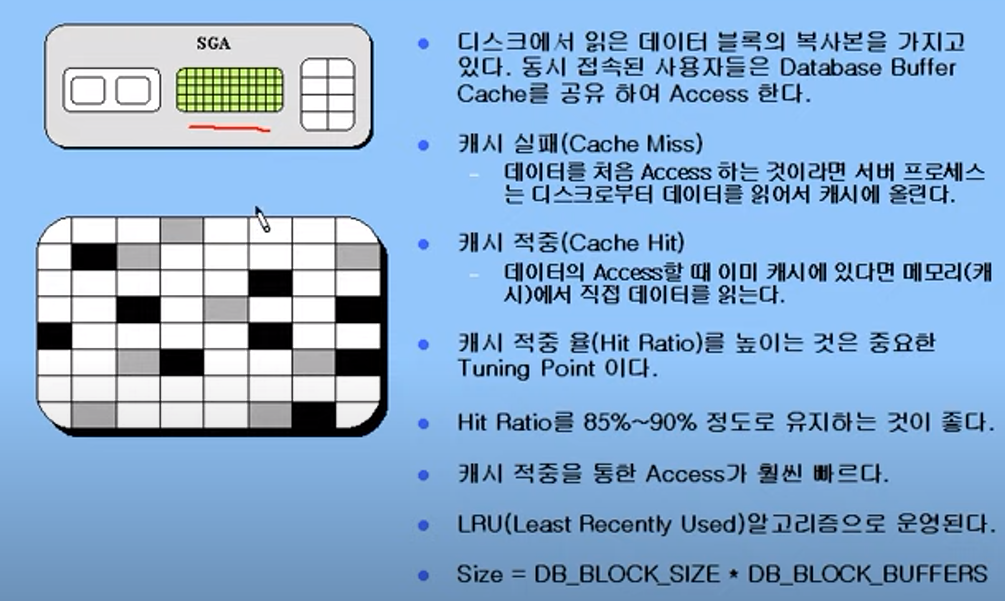
Database Buffer Cache
-
Database Buffer Cache : 디스크의 IO를 줄이기 위해..
디스크에서 읽은 데이터 블록의 복사본을 담고 있다. 동시 접속자끼리 공유함. -
캐시 적중율을 높이는 것은 중요한 Tuning Point다. Hit Ratio를 85%~90%정도로 유지하는 것이 좋다.
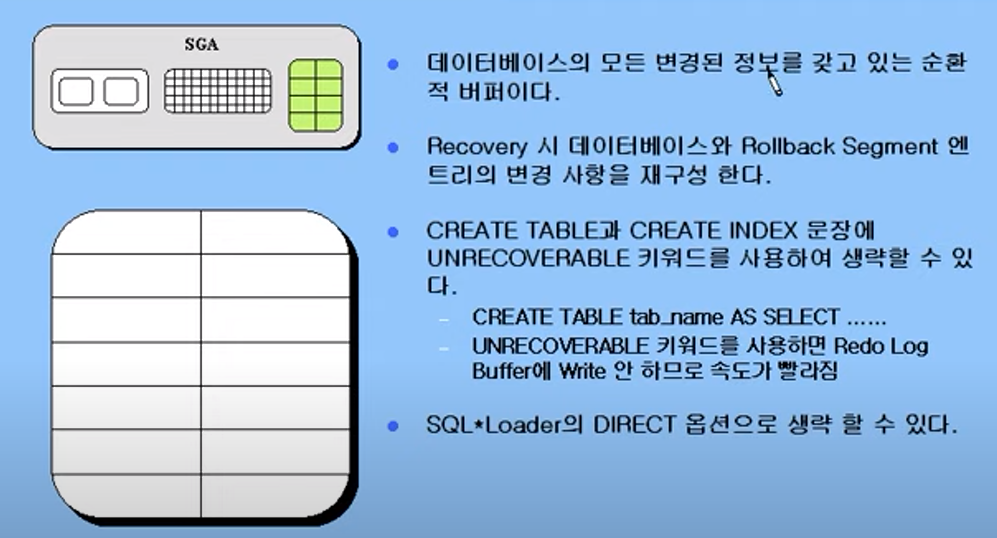
Redo Log Buffer
-
Redo Log Buffer : 데이터베이스의 모든 변경된 정보를 갖고 있다. 롤백을 위한 자료공간이다.
-
Redo Log Buffer에 입력하는 것 자체는, IO 부하를 줄 수가 있다. 그러므로, 부하를 줄이기 위해 CREATE TABLE이나 CREATE INDEX 등에 UNRECONVERABLE 키워드를 붙힐 수 있다.
Process
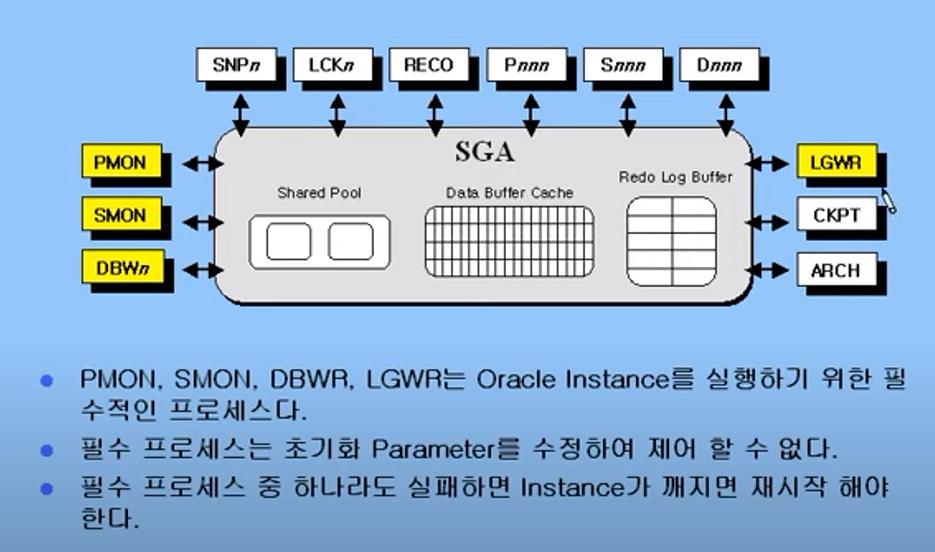
필수 프로세스
PMON, SMON DBWR, LGWR은 오라클 인스턴스를 실행하기 위한 필수적인 프로세스이다. 오라클이 직접 제어하는 것이라 사용자가 임의로 조작할 수 없다.
-
PMON :
process monitor, 비정상 종료된 프로세스등을 모니터링하다가 처리. 실패한 프로세스가 SGA에 할당되었을 경우, 메모리를 클리닝하는 작업 등도 진행한다. -
SMON :
system monitor, 인스턴스 자동 복구, 더이상 사용하지 않는 temporary segment 공간을 회수. temporary segment는 프로세스 정리 상 정렬 작업이 필요할 경우가 생기는데, 임시적으로 이에 할당해주는 공간이다. 작업이 끝나면 회수 됨. -
DBWR :
db writer, data buffer cache의 내용을 data file에 기록. 사용자 프로세스가 비어있는 버퍼를 찾을 수 있도록 관리. -
LGWR :
log writer, redo log buffer의 내용을 redo log 파일에 기록.
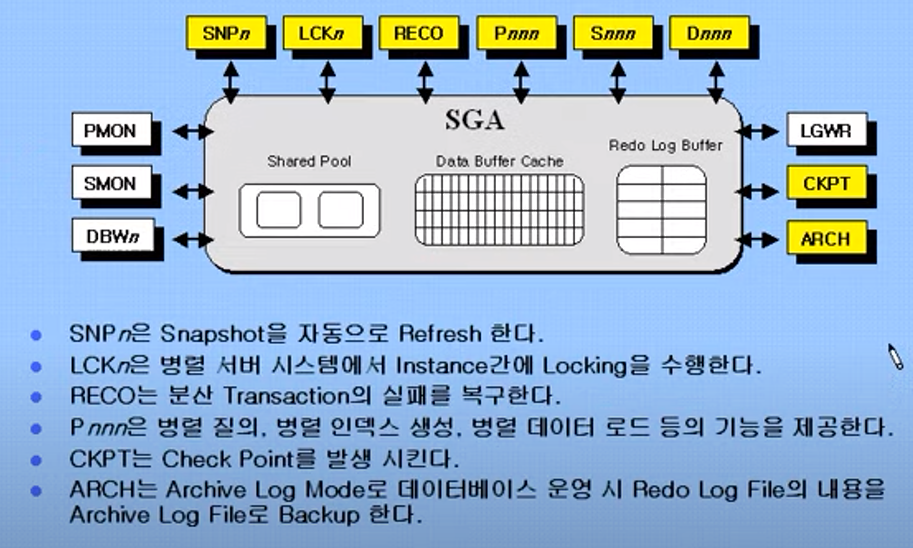
기타 프로세스
오라클 기타 프로세스, 앞선 필수 프로세스들과 달리, 사용자가 파라미터나 옵션을 조정하여 이들을 실행할 수도 안 할 수도 있는 프로세스들.
-
SNPn :
snapshot process, 분산 DB에서 스냅샷을 자동 리프레쉬해줌. -
LCKn :
lock process, Oracle Parallel Server System(OPSS)에서 인스턴스 간 locking을 수행한다. 하나의 DB를 여러 개의 인스턴스가 공유하기 때문에 인스턴스 간 lock이 필요하다.
-
RECO :
recovery process, 분산 tracsaction의 실패를 복구한다. -
Pnnn :
parallel process, 병렬 질의, 병렬 인덱스 생성, 병렬 데이터 로드 등의 병렬 작업을 관리 -
Snnn, Dnnn :
shared process, dispatcher process, 오라클 서버를 MTS(multi threaded server)방식일 때만 기동된다. -
CKPT :
checkpoint process, 오라클 내부에서 동기화를 맞추기 위해 주기적으로 checkpoint를 발생시킨다. 이것을 하는 프로세스임. -
ARCH :
archive process, 아카이브 로그 모드로 DB 운영 시 REDO LOG FILE의 내용을 archive log file로 백업한다.
서버 프로세스
Server
server process, 유저 프로세스의 요청을 받아 이를 처리하는 프로세스.
-
parsing(구문분석)
SQL 문장을 분석(오류, 보안 위배, 수행 계획이 최적화되었는지) -
execute
실제실행 -
fetch
결과를 사용자에게 전달
사용자 프로세스
User
user process, 엄밀히 말하면 오라클 아키텍처는 아니고 오라클에 접속하기 위한 client단 응용 프로그램.
Redo Log File
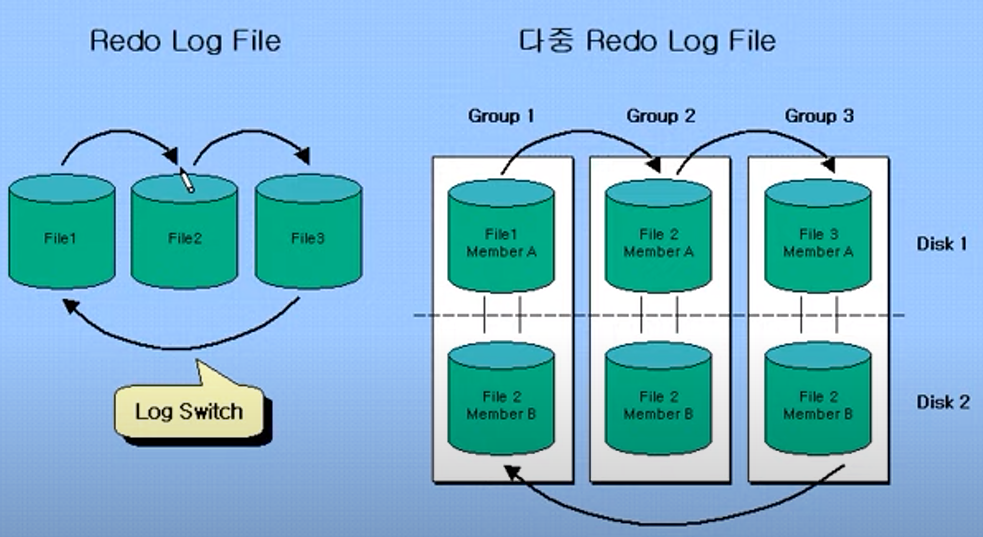
Redo Log File : DB 내에 모든 변경된 내용이 기록된다.
-
롤백 가능.
-
적어도 두 가지 이상의 그룹이 필요하다.
-
그들끼리는 순환적으로 기록되어, FILE1,2,3의 상황에 따라 순환적으로 기록된다.
-
이를 Log Switch라고 부른다.
-
사용자는 Log Switch를 임의로 조작할 수 있어서, 기록되는 위치를 바꿀 수 있다.
다중 Redo Log File : 각 그룹에 data file이 두 가지 이상일 수 있다.
-
같은 그룹 내에서는 data file이 미러링 되어있다.
-
db이중화 느낌으로, 별도의 디스크로 구성할 수 있다.
-
redo log file에 변경된 내용이 계속 순환적으로 기록이 되는데, 순환하면서 기존 데이터가 덮어씌워질 수 있다.
-
그러므로 archive process는 계속 돌고 있다가, log switch가 발생할 경우 덮어씌워질 data를 다른 곳에 다른 이름으로 복사해서 저장해놓는다.
-
그러므로, 계속 historical하게 redo log file이 적재되도록 한다.
Control File
Control file : 데이터베이스의 구조를 기술하는 작은 크기의 binary 파일이다.
-

-
데이터베이스의 이름이 저장되며, 컨트롤 파일은 DB의 mount, open, access등을 할 때 필요하다.
-
복원에 필요한 동기화된 정보(SCN system change number)가 저장된다.
-
메타파일같은 느낌? redo log file과 마찬가지로 이중화가 바람직하다.
Parameter File
parameter file :
오라클 인스턴스가 시작할 때만 참조된다. 현재 실행중이면 반영되지 않으며, 반영하려면 재부팅해야함.
요약
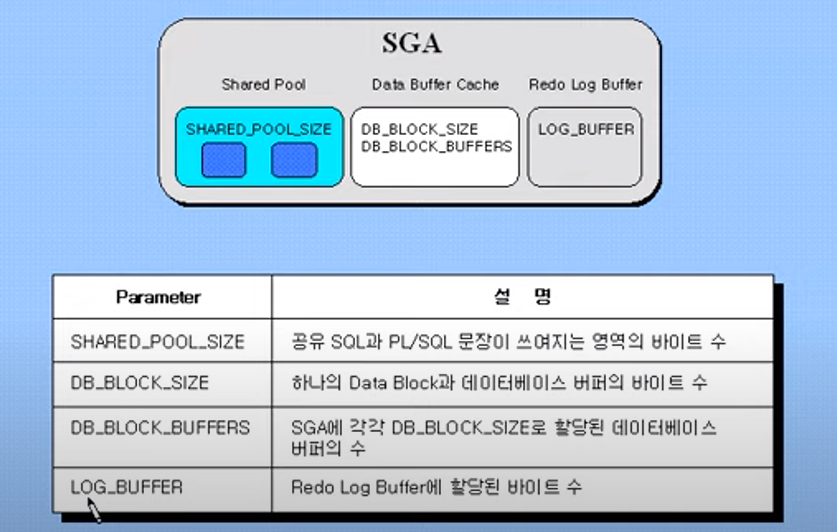
SGA(system global area)
Process
필수+기타
Files
redo log file, archive process로 별도의 공간에 계속 빽업됨. 온라인 빽업을 가능하게 함. control file, parameter file 등.
