
병렬과 동시성의 차이점을 말해주세요.
-
동시성은 여러 작업이 겹치는 기간에 실행될 수 있음을 의미하며 동시에 실행되는 것이 아니라 CPU가 작업마다 시간을 분할해 동시에 실행되는 것처럼 보이게 하는 것이다.
동시성의 핵심 목표는 유휴 시간을 최소화하는 것이다.
둘 이상의 작업이 진행중일 경우에 데이터 무결성을 유지시켜줘야 한다.- 동시성 작동과정
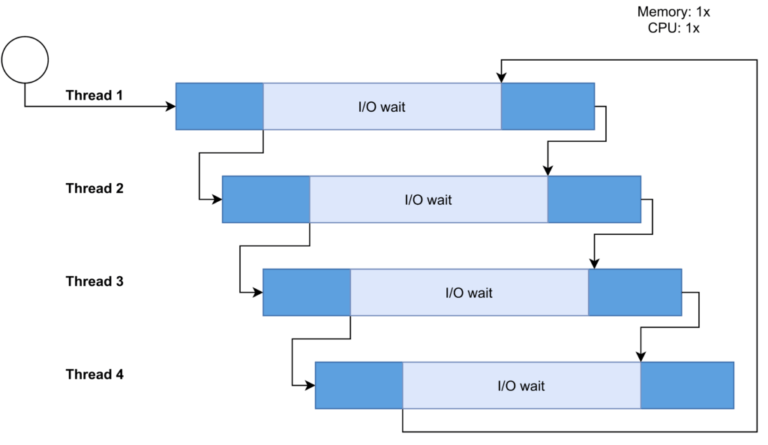
사진 출처: https://www.baeldung.com/cs/concurrency-vs-parallelism
- 동시성 작동과정
-
병렬성은 동일한 시간에 독립적인 작업을 실행할 수 있음을 의미한다. 동시성과 달리
여러 작업을 다른코어, 다른 프로세스, 별도의 컴퓨터 등에서 동시에 실행할 수 있다.- 병렬처리의 예시: 분산 컴퓨팅 시스템
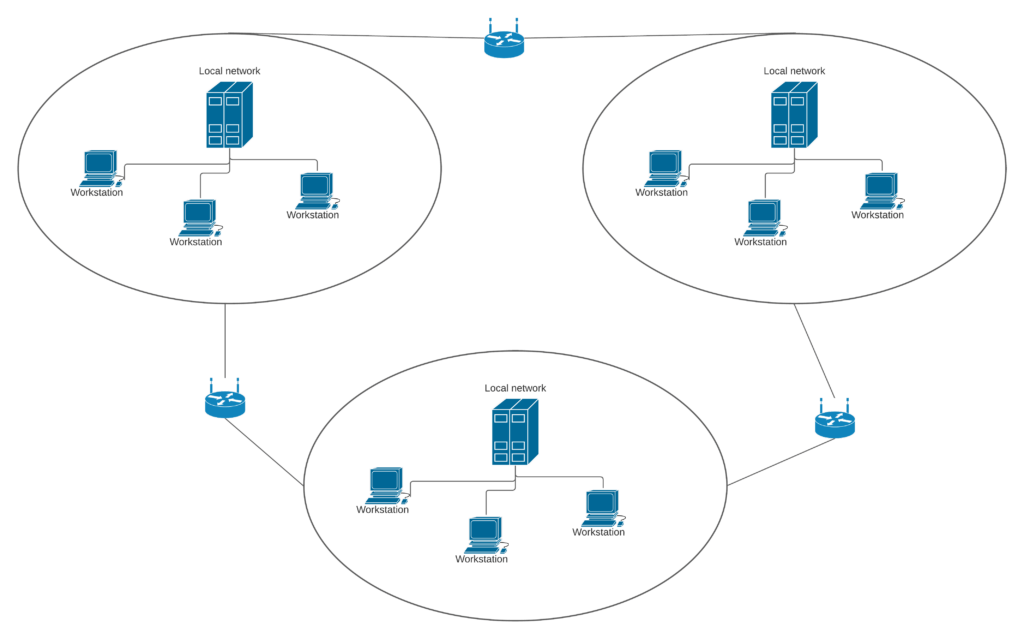
- 병렬처리의 예시: 분산 컴퓨팅 시스템
-
동시성과 병렬성의 작업 과정
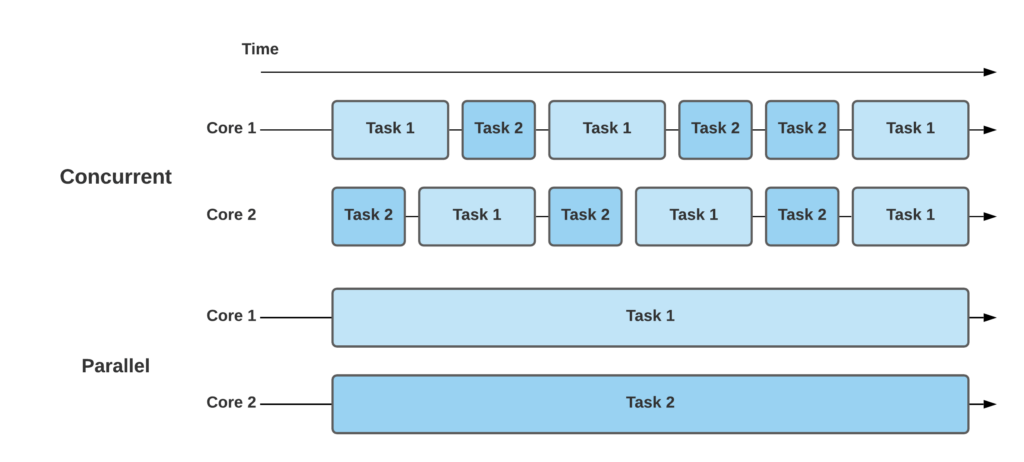
- 정리

스레드와 프로세스의 차이를 말해주세요.
-
프로세스란 단순히 실행중인 프로그램이라고 한다. 즉 사용자가 작성한 프로그램이 운영체제에 의해 메모리 공간을 할당받아 실행 중인 것을 말한다. 프로세스는 프로그램에 사용되는 데이터와 메모리 등의 자원 그리고 스레드로 구성된다.
-
스레드란 프로세스 내에서 실제로 작업을 수행하는 주체를 의미한다. 모든 프로세스에는 한 개 이상의 스레드가 존재하여 작업을 수행한다. 둘 이상의 스레드를 가지는 프로세스를 멀티스레드 프로세스라고 한다.
-
프로세스와 스레드의 차이점은 프로세스는 자신만의 주소공간(code,data, heap, stack)을 할당받아 프로세스는 다른 프로세스의 변수나 자료에 접근할 수 없다. 스레드는 stack만 따로 할당받고 나머지 영역은 다른 스레드끼리 서로 공유한다.
따라서 프로세스는 오류가 발생해서 프로세스가 강제 종료 되어도 다른 프로세스에 영향을 주지 않지만 스레드는 오류가 발생해서 종료된다면 같은 프로세스 내의 다른 모든 스레드도 강제로 종료된다. 이렇게 프로세스와 스레드는 개념의 범위부터 구조까지 모두 다르다.
📌 프로세스와 스레드, 멀티프로세스 멀티 스레드에 대해서
데몬 스레드는 무엇인가요?
- 데몬 스레드는 우선순위가 낮은 스레드로 부터 백그라운드에서 사용자의 애플리케이션을 보좌하는 역할을 수행하는 스레드이다. 대표적인 데몬 스레드로는 JVM에 생성된 객체들의 메모리 공간을 회수하는 GarbageCollection이 있다.
데몬 스레드와 일반스레드의 차이점은 사용자의 애플리케이션이 종료될 때 일반 스레드는 작업이 모두 종료되고 나서 프로세스가 종료되지만 데몬 스레드는 프로세스가 종료되면서 강제 종료가 된다.
스레드를 만드는 방법을 나열해주세요.
- Thread 클래스를 상속받아서 생성
java.lang.Thread 클래스를 상속 받아서 run()메소드 오버라이딩
satrt()호출하여 실행- 특징
실행 스레드로 자신의 콜 스택을 갖춘 독립적인 프로세스
- 특징
- Runnable 인터페이스 구현하여 생성
java.lang.Runnable 인터페이스로부터 run()메서드 오버라이드 하여 구현
별도의 thread를 생성하고 구현한 Runnable 인터페스를 인자로 넘겨준다- 특징
오버라이딩하여 만들었기 때문에 다른 클래스를 상속 받아서 쓸수 있고 재사용 가능
Runnable 인터페이스를 구현
- 특징
- 정리
Thread 클래스가 다른 클래스를 확장할 필요가 있을 경우나 한 곳에서만 스레드를 사용하는 경우 Runnable 인터페스를 구현하고 아닐 경우에는 Thread클래스를 사용하는게 낫다
runnable과 callable의 차이는 무엇인가요?
- runnable과 Callable은 다른 스레드에서 사용될 수 있는 클래스의 객체를 위한 인터페이스이다.
- runnable은 어떤 객체도 리턴하지 않으며 Exception을 발생시키지 않는다.
- Callable은 특정 타입의 객체를 리턴하며 Exception을 발생시킨다.
- Runnabnle의 확장개념이 Callable이다.
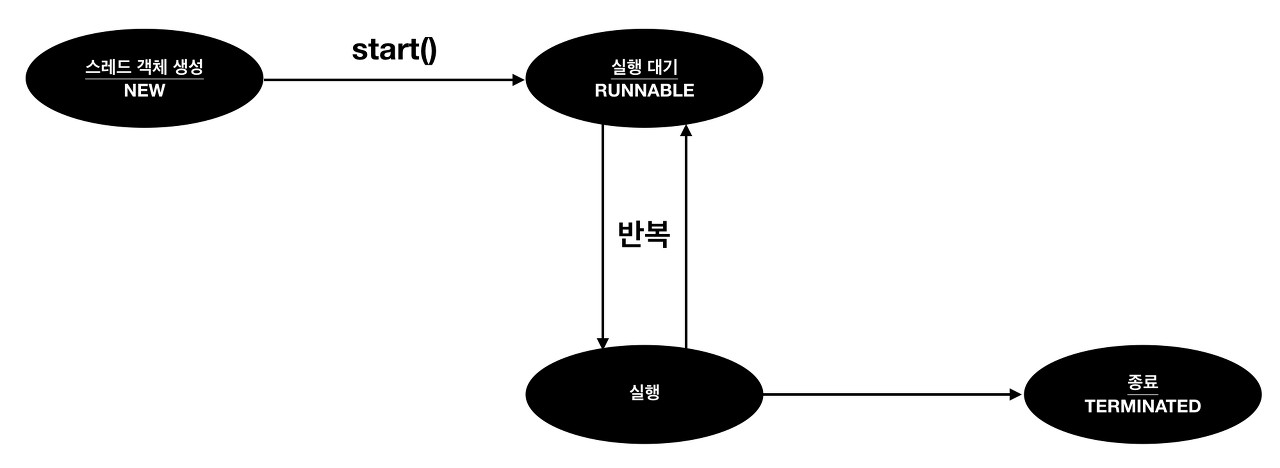
스레드의 여러가지 상태에 대해 말해주세요.
| 상태 | 열거 상수 | 설명 |
|---|---|---|
| 객체 생성 | NEW | 쓰레드 객체가 생성, 아직 start() 메소드가 호출되지 않은 상태 |
| 실행 대기 | RUNNABLE | 실행 상태로 언제든지 갈 수 있는 상태 |
| WAITING | 다른 쓰레드가 통지할 때까지 기다리는 상태 | |
| 일시 정지 | TIME_WAITING | 주어진 시간 동안 기다리는 상태 |
| BLOCKED | 사용하고자 하는 객체의 락이 풀릴 때까지 기다리는 상태 | |
| 종료 | TERMINATED | 실행을 마친 상태 |
sleep()과 wait()의 차이는 무엇인가요?
-
sleep()
- java.lang.Thread 클래스의 정적 메서드로 현재 실행중인 스레드를 일시적으로 지연시키는데 사용된다.
- 인터럽트가 발생하거나 지정된 시간이 경과하면 스레드가 실행을 재개한다.
- 객체가 중단될 때 까지 객체에 대한 lock을 해제하지 않는다.
-
wait()
- Object.wait()메서드는 모든 객체의 인스턴스 메서드로, 동기화된 다중 스레드가 같은 오브젝트에 접근하고자 할때 중지시킨다.
- 객체에 대한 lock을 해제하여 notify 또는 notifyAll 메서드가 호출 될 때 까지 다른 객체가 실행 되도록 한다.
- wait() 은 반드시 synchronized 블록 내에서 호출되어야함. 그렇지 않으면 'IllegalMonitorStateException' 이 발생
- wait() 은 다른 스레드에게 lock을 양보하고, 해당 객체의 lock을 잃게됨
-
sleep()은 현재 스레드를 잠시 멈추게 할 뿐 lock을 해제하지는 않지만
wait()은 락을 소유하고 있던 스레드가 락을 해제하며 WAITING 또는 TIME_WATING으로 상태가 바뀌게 된다.
notify()와 notifyAll()의 차이는 무엇인가요?
- notify()는 잠들어 있던 스레드 중 임의로 하나를 골라 깨운다.
- nofityAll()은 호출로 잠들어 있던 스레드 모두를 깨운다.
thread run()과 tnread start()의 차이는 무엇인가요?
- 둘다 스레드를 실행하기 위한 함수지만 run()을 사용하면 호출한 스레드에서 작업이 처리되고 start()를 사용하면 스레드를 새로 만들어서 처리된다.
병렬 처리를 하고 싶다면 start()를 사용해야 한다.
스레드 풀을 생성할 수 있는 여러가지 방법을 말해주세요.
-
스레드 풀이란 동시에 여러 작업을 효율적으로 실행 및 관리하기 위해 서버에서 만드는 스레드 모음이다. 스레드 풀을 이용하면 각 작업에 대한 새 스레드를 생성하는 대신 이미 생성된 스레드 풀에 있는 스레드를 재사용한다. 이는 성능과 리소스 관리에 도움이 된다.
-
스레드 풀 생성 방법
-
newCachedThreadPool()
스레드 수의 제한을 두지 않는 스레드 풀 방식으로, 새로운 스레드 시작 요청이 들어올 때마다 스레드를 하나씩 생성한다.
업무가 종료된 스레드들은 바로 사라지지 않고 1분동안 살아있다가 다른 작업 요청이 없다면 제거 된다. 반복되는 스타일의 작업요청이 들어올 경우 유용하다. -
newFixedThreadPool(int nThreads)
최대 스레드를 10개까지 만드는 방식으로, 동시에 일어나는 업무의 양이 비교적 일정할때 사용한다. -
ThreadPoolExecutor 객체 생성
단 하나의 스레드를 생성하는 방식으로 주로 스레드 작업 중에 예외상황이 발생할
경우 예외처리를 위한 스레드 생성용으로 많이 사용한다. -
newScheduledThreadPool()
일정 시간마다 주기적으로 반복해야하는 스타일의 동시작업을 위한 스레드풀이다. Timer 클래스를 대체할 수 있는 스레드 풀 방식이다. -
ForkJoinPool()
최초의 ForkJoinPool을 생성한 스레드에서 부모 스레드로 업무를 할당하고 큰 업무를 작은 업무 단위로 쪼개서 부모 스레드로부터 부모 스레드로 부터 처리로직을 복사하여 새로운 스레드에서 쪼개진 작은 업무를 수행시킨다. 업무가 완료되면 다시 부모 스레드에서 Join하여 값을 취합한다. 이후 최초의 스레드로 값을 리턴한다.
-
스레드 풀의 상태에 대해 말해주세요.
- Executors 객체 내에 int 형으로 상태 값 존재
/ runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS; // 11100000 00000000 00000000 00000000
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
-
RUNNING : 새로운 테스크를 받고 큐에 집어 넣는 일을 실행
SHOUTDOWN : 새로운 테스크를 받지 않음, 이미 큐에 있는 테스크는 처리
STOP : 새로운 테스크를 받지 않음, 큐에 있는 테스크도 처리하지 않음, 현재 진행중인 테스크에 인터럽트를 건다
TIDYING : 모든 테스크를 소멸, TIDYING 상태로 전이되는 스레드는 terminated() 메소드를 실행 시킴
TERMINATED : terminated() 메서드가 완료 됨 -
외부에서 직접적인 접근은 불가능하고 isShutdown(), isTerminated() 등 이런 메서드를 통해 스레드 풀의 상태를 알 수 있다.
스레드 풀에서 submit()과 execute()의 차이는 무엇인가요?
-
excute()
리턴 값이 없는 Runnable 객체를 작업 큐에 저장한다. 따라서 작업처리 결과를 받지 못한다. 작업 처리 도중에 예외가 발생화면 스레드가 종료되고 해당 스레드를 스레드 풀에서 제거한 뒤, 다른 작업처리를 위해 새로운 스레드를 생성한다. -
submit()
Runnable 또는 Callable을 작업큐에 저장하고 Future 객체를 리턴한다.작업처리 결과를 받을 수 있다. 작업 처리 도중에 예외가 발생하면 스레드는 종료되지 않고 다음 작업을 위해 재사용 된다. -
정리
excute()는 리턴 값이 없고 submit()은 리턴 값이 있으며 exctue()는 예외 발생 시 스레드를 새로 생성하고 submit()은 스레드가 재사용 된다는 차이점이 있다.
따라서 스레드 생성 오버헤더를 줄이기 위해 submit()을 사용하는 것이 좋다.
자바 프로그램에서 멀티 스레드 작업의 안전성을 어떻게 보장할 수 있을까요?
- synchronized 키워드를 사용하여 동시성을 보장한다.
- Thread-safe한 Collection을 사용한다. 이방법이 synchronized를 사용 하는 것 보다 성능이 좋다.
- stack에 한정되도록 프로그래밍 하여 동시성을 보장한다. 스레드는 다른 자원은 공유하지만 스택과 지역변수는 별도로 가지고 있기 대문에 독립적으로 사용할 수 있다.
스택을 벗어나는 순간 사용할 수 없다는 단점이 있다. - Thread Local을 이용하여 특정 스레드가 실행하는 모든 코드에서 스레드에 설정된 변수 값을 사용할 수 있기에 stack에서 프로그래밍 하는 방법의 상위호환이라 볼 수 있다.
- 불변 객체를 사용하여 동시성을 보장한다. (예시: String 클래스, final 키워드)
