이 단원에서는 컴퓨터의 비휘발성 저장장치 시스템인 대용량 저장장치(Mass-Storage Structure)가 어떻게 구성되어 있는지 알아보자!
11.1 Overview of Mass-Storage Structure
최신 컴퓨터에 의한 대량의 보조저장장치는 HDD(하드 디스크 드라이브) 및 NVM(비휘발성 메모리) 장치에 의해 제공된다.
11.1.1 Hard Disk Drives
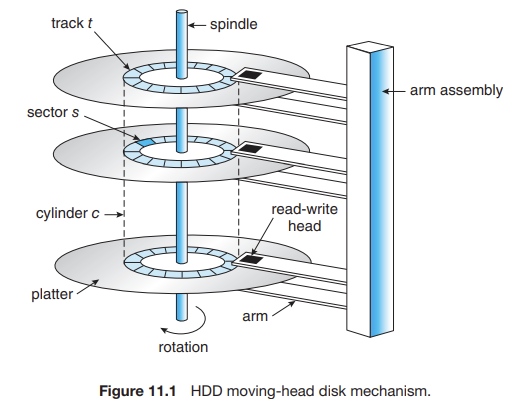
✅ HDD의 mechanism
- 플래터 (platter)
✔ 각 디스크의 플래터는 CD처럼 생긴 원형 평판모양으로, 지름은 1.8에서 3.5인치이다.
✔ 플래터의 양쪽 표면은 자기 테이프와 유사하게 자기 물질로 덮여 있다.
✔ 우리는 정보를 플래터 상에 자기적으로 기록하여 저장하고 플래터의 자기 패턴을 감지하여 정보를 읽는다. - 읽기-쓰기 헤드 (read-write head)
✔ 모든 플래터의 각 표면 바로 위에서 움직인다.
✔ 헤드는 모든 헤드를 한꺼번에 이동시키는 디스크 암(disk arm)에 부착되어 있다. - 트랙과 섹터 (track & sector)
✔ 플래터의 표면은 원형인 트랙으로 논리적으로 나누어져 있고, 이것은 다시 섹터로 나누어져있다.
✔ 각 섹터의 크기는 고정되어 있으며, 일반적으로 512byte였으나 4KB로 변경을 시작했다. - 실린더 (cylinder)
✔ 동일한 arm 위치에 있는 트랙의 집합은 하나의 실린더를 형성한다.
✔ 하나의 디스크 드라이브에는 수천 개의 동심원 실린더가 존재할 수 있고, 각 트랙은 수백 개의 섹터를 포함할 수 있다.
✅ 접근시간/속도에 대하여
- 전송속도 (transfer rate) : 드라이브와 컴퓨터 간의 데이터 흐름의 속도
- 위치지정시간 (Positioning time) : 탐색시간 + 회전지연시간
탐색시간 (seek time) : 디스크 암을 원하는 실린더로 이동하는데 필요한 시간
회전지연시간 (rotational latency) : 원하는 섹터가 디스크 헤드 위치까지 회전하는데 걸리는 시간

✅ 헤드 충돌 (head crash)
디스크 헤드는 공기 또는 헬륨과 같은 다른 가스의 매우 얇은 쿠션 위를 비행하며 헤드가 디스크 표면에 닿을 위험이 있다. 디스크 플래터는 얇은 보호 층으로 코팅되어 있지만 헤드는 때때로 자기 표면을 손상하는데, 이 사고를 헤드 충돌이라고 한다.
헤드충돌은 일반적으로 수리할 수 없고, 전체 디스크를 교체해야 한다.
디스크의 데이터가 다른 저장장치나 RAID로 보호하지 않은 경우 손실된다.
11.1.2 Nonvolatile Memory Devices
비휘발성 메모리(NVM) 장치의 중요성이 증가하고 있는데,,,
NVM 장치는 기계식이 아닌 전기식으로, 컨트롤러 및 데이터를 저장하는데 사용되는 플래시 NAND 다이 반도체 칩으로 구성되어 있다.

플래시 메모리 기반 NVM은 디스크 드라이브와 유사한 컨테이너에서 자주 사용되며 이 경우 SSD (solid-state disk)라고 한다.
(다른 경우에는 USB 드라이브 또는 DRAM 스틱의 형태를 취함)
✅ NVM 장치의 장점
✔ 움직이는 부품이 없으므로 HDD보다 안정성이 높다.
✔ 탐색 시간이나 회전 지연시간이 없으므로 더 빠를수도 있다.
✔ 전력소비량이 적다.
✅ NVM 장치의 단점
✔ 기존 하드디스크보다 메가바이트당 가격이 비싸다.
✔ 더 큰 하드디스크보다 용량이 적다.
그러나 시간이 지남에 따라 NVM 장치의 용량이 HDD 용량보다 빠르게 증가하고 가격이 빠르게 하락해서 사용량이 급증하고 있다!!
✅ NAND 반도체
NAND 반도체는 일부 특성 때문에 자체적인 저장 및 신뢰성 문제를 가진다
✔ 섹터와 유사한 '페이지' 단위로 읽고 쓸 수 있지만 데이터를 덮어쓸 수 없다.
✔ 덮어쓰기 위해서는, 먼저 NAND 셀을 지워야 하는데 삭제는 여러 페이지로 구성된 '블록' 단위로 이루어지며 읽기 또는 쓰기보다 시간이 더 걸린다.
✔ 삭제할 때마다 기능이 열화되며, 약 100000개의 프로그램(삭제주기) 후에 셀은 더이상 데이터를 유지하지 않는다.
✔ 쓰기 마모로 인해, 그리고 움직이는 부품이 없기 때문에 NAND NVM 수명은 연 단위가 아니라 DWPD (Drive Writes Per Day)로 측정된다.
11.1.3 Volatile Memory

✅ 자기 테이프 (Magnetic Tapes)
✔ 초기의 보조저장장치 매체로 사용되었다.
✔ 비록 자기 테이프가 비휘발성이고, 많은 양의 데이터를 보관할 수 있지만, 메인 메모리와 드라이브와 비교할 때 접근 시간이 느리다.
➡ 따라서 자기 테이프는 보조저장장치로 부적합하다.
➡ 자기 테이프는 주로 예비용(back-up)이나 자주 사용하지 않는 정보의 저장에 사용하거나, 한 시스템에서 다른 시스템으로 정보를 전송하기 위한 매체로 사용한다.
DRAM은 대용량 저장장치로 자주 사용되고, 특히 RAM 드라이브는 보조저장장치처럼 작동하지만 시스템 DRAM의 한 영역을 할당하여 저장장치인 것처럼 나머지 시스템에 제공하는 장치 드라이버에 의해 생성된다.
❓ 컴퓨터에는 이미 버퍼링 및 캐싱을 하는데 왜 임시 데이터 저장장치로 DRAM을 사용할까
✔ DRAM은 휘발성이며, RAM 드라이브의 데이터는 시스템 크래시, 종료 또는 전원이 꺼진 후에 지속되지 않는다.
✔ 캐시와 버퍼는 프로그래머나 OS에 의해 할당되는 반면, RAM 드라이브를 사용하면 사용자와 프로그래머가 표준 파일 연산을 사용하여 데이터를 메모리에 임시로 보관할 수 있다.
RAM 드라이브는 고속 임시 저장 공간으로 유용하다!
NVM 장치는 빠르지만 DRAM은 훨씬 빠르며, RAM 드라이브에 대한 I/O 작업은 파일과 내용을 생성, 읽기, 쓰기 및 삭제하는 가장 빠른 방법이다.
11.1.4 Secondary Storage Connection Methods
보조저장장치는 시스템 버스 또는 I/O 버스에 의해 컴퓨터에 연결된다.
버스에서의 데이터 전송은 컨트롤러(또는 호스트 버스 어댑터(HBA))라고 하는 특수 전자 프로세서에 의해 수행된다.
호스트 컨트롤러 (host controller)는 버스의 컴퓨터 쪽에 있는 컨트롤러이고,
각 저장장치에는 장치 컨트롤러 (device controller)가 내장되어 있다.
✅ 대용량 저장장치 I/O 작업 수행 과정
1. 메모리 매핑된 I/O 포트를 사용하여 명령을 호스트 컨트롤러에 놓는다.
2. 호스트 컨트롤러는 메시지를 통해 명령을 장치 컨트롤러에 전송한다.
3. 장치 컨트롤러는 드라이브 하드웨어를 작동하여 명령을 수행한다.
장치 컨트롤러에는 일반적으로 내장 캐시가 있는데, 드라이브에서의 데이터 전송은 캐시와 저장 매체 사이에서 발생하며 호스트로의 데이터 전송은 DMA를 통해 캐시와 흐스트 DRAM 사이에서 빠른 전자 속도로 발생한다.
11.1.5 Address Mapping
저장장치는 논리 블록 (logical blocks)의 커다란 1차원 배열처럼 주소가 매겨진다.
(논리 블록: 가장 작은 전송단위)
✔ 각 논리 블록은 물리 섹터 또는 반도체 페이지로 맵핑된다.
✔ 각 논리 블록의 1차원 배열은 장치의 섹터들 또는 페이지들에 맵핑된다.
✔ 섹터 0은 HDD의 가장 바깥쪽 실린더에 있는 첫 번째 트랙의 첫 번째 섹터일 수 있다.
✔ 맵핑은 해당 트랙을 순서대로 완료한 후에 해당 실린더의 나머지 트랙을 맵핑한 다음, 나머지 실린더를 바깥쪽에서 안쪽으로 맵핑한다.
✅ 고정 선형 속도 (constant linear velocity, CLV)
✔ 트랙당 비트의 밀도가 일정해서, 트랙이 디스크의 중심으로부터 멀어질수록 트랙은 길이가 더 길어져 더 많은 섹터를 가질 수 있게 된다.
✔ 드라이브는 헤드가 바깥쪽에서 안쪽 트랙으로 이동하면서 헤드 아래를 통과하는 데이터의 비율을 동일하게 유지하기 위해 회전속도를 늘인다.
✔ CD-ROM과 DVD-ROM 드라이브에 사용된다.
✅ 고정 각속도 (constant angular velocity, CAV)
✔ 디스크의 회전 속도를 일정하게 유지한다.
✔ 안쪽 트랙에서 바깥쪽 트랙으로 갈수록 비트의 밀도를 줄여 데이터의 비율을 일정하게 유지한다.
✔ 하드디스크에 사용된다.
11.2 Disk Scheduling
HDD는 접근 시간을 최소화하고 전송 대역폭을 최대화함으로써 효율적인 하드웨어 사용에 책임을 다한다.
❓ 전송 대역폭(bandwidth)
: 전송된 총 바이트 수 / 첫 번째 서비스 요청과 마지막 전송 완료 사이의 전체 시간
원하는 드라이브와 컨트롤러가 쉬고 있다면 system call 요청은 즉시 시작되지만, 바쁘면 요청은 그 드라이브의 큐에 들어가 기다려야 하는데, 이때 큐의 순서를 조정하여 성능을 향상할 수 있다.
11.2.1 FCFS Scheduling
디스크 스케줄링의 가장 간단한 형태.
본질적으로는 공평해보이지만 빠른 서비스를 제공하지는 못한다.
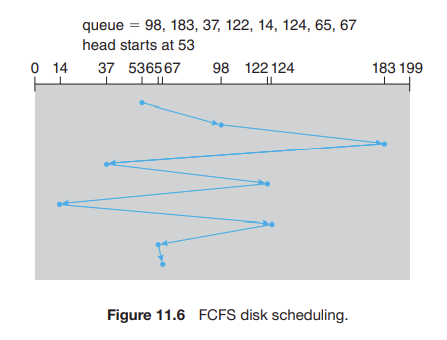
다음과 같은 입/출력 요청이 디스크 큐에 와 있다고 생각해보자!
98->183->37->...->67처럼 순서대로 이동했다고 했을 때,
122에서 14까지 이동한 후 124로 다시 이동하는 것보다는 122와 124를 함께 서비스해주고 37과 14 실린더를 그 다음에 함께 처리한다면 헤드의 총 이동 거리를 많이 줄일 수 있고 성능도 향상할 수 있다!
11.2.2 SCAN Scheduling
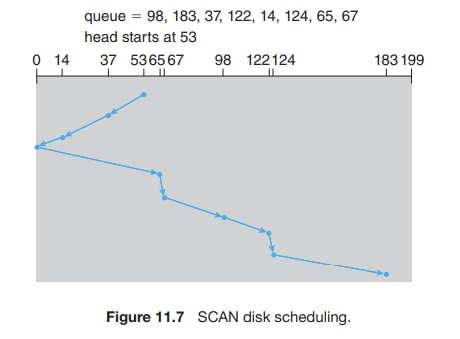
SCAN 알고리즘에서는 디스크 암이 디스크의 한 끝에서 시작하여 다른 끝으로 이동하며, 가는 길에 있는 요청을 모두 처리한다.
➡ 다른 한쪽 끝에 도달하면 역방향으로 이동하면서 오는 길에 있는 요청을 모두 처리한다.
➡ 따라서 헤드는 디스크 양쪽을 계속해서 가로지르며 왕복한다.
❓ 만약 이동 안에 새로운 요청이 헤드 가는 방향으로 도착하면 가면서 처리되지만, 반대로 헤드 뒤로 도착하면 되돌아올 때 처리된다.
✔ 모든 실린더에 요청이 균일하게 도착한다고 가정했을 때, 헤드가 한쪽 끝에 도달하면 헤드 바로 근처에는 대기 중인 요청이 거의 없고(방금 거기를 지나왔으니까), 반대쪽 끝으로 가장 많은 요청이 몰려 있을 것이다(그곳을 서비스한지 가장 오래됐으니까).
➡ 따라서 되돌아서 현재 있는 위치부터 서비스를 시작하기보다 가장 반대쪽부터 서비스를 시작하는 것이 다음에 나오는 알고리즘의 기본 개념이다.
11.2.3 C-SCAN Scheduling
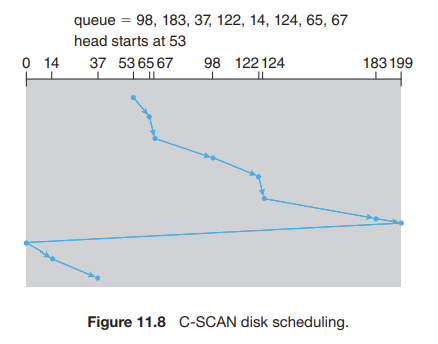
C-SCAN (circular-SCAN) 스케줄링은 각 요청에 걸리는 시간을 좀 더 균등하게 하기 위한 SCAN의 변형이다.
➡ SCAN과 같이 한쪽으로 헤드를 이동해 가면서 요청을 처리하지만, 한쪽 끝에 다다르면 반대 방향으로 헤드를 이동하며 서비스하는 것이 아니라 처음 시작했던 자리로 다시 돌아가서 서비스를 시작한다.
11.3 NVM Scheduling
위의 디스크 스케줄링 알고리즘은 HDD와 같은 기계식 플래터-기반 저장장치에 적용되며, 주로 디스크 헤드 이동량을 최소화하는데 중점을 둔다. 하지만 NVM 장치에는 이동 디스크 헤드가 없으며 일반적으로 간단한 FCFS 정책을 사용한다.
✅ NOOP 스케줄러
✔ FCFS 정책을 사용하지만 인접한 요청을 병합하도록 수정한다.
✔ NVM 장치는 읽기 서비스에 필요한 시간은 일정하지만 플래시 메모리의 속성 때문에 쓰기 서비스 시간은 일정하지 않다.
➡ 이 속성을 이용하여 인접한 쓰기 요청만 병합하고 읽기 요청은 FCFS 순서로 처리한다.
11.4 Error Detection and Correction
오류 감지는 문제가 발생했는지 여부를 결정한다.
메모리 시스템은 패리티 비트 (parity bit)를 사용하여 특정 오류를 오랫동안 감지했다.
➡ 메모리 시스템의 각 바이트에는 1로 설정된 비트 수가 짝수(패리티 = 0)인지 홀수(패리티 = 1)인지 기록하는 패리티 비트가 연관된다.
❓ 패리티는 고정 길이 워드의 값을 계산, 저장 및 비교하기 위해 나머지 연산을 수행하는 체크섬(checksum)의 한 형태이다.
11.5 Storage Device Management
드라이브의 초기화, 드라이브로부터의 부팅 및 손상된 블록의 복구에 관해 알아보자.
11.5.1 Drive Formatting, Partitions, and Volumes
새로운 저장장치는 아무런 정보도 없는 비어있는 판 또는 초기화되지 않은 반도체 저장 셀의 집합이다.
✅ 저수준 포매팅 (low-level formatting) 또는 물리적 포매팅 (physical formatting)
✔ 각 저장장치 위치마다 특별한 자료구조로 장치를 채운다.
✔ 섹터 또는 페이지를 위한 자료구조는 보통 헤더(header), 자료 구역(data area)과 트레일러(trailer)로 구성된다.
✔ 헤더와 트레일러는 섹터/페이지 번호와 오류 탐지 또는 오류 수정 코드와 같은 컨트롤러가 사용하는 정보를 가지고 있다.
✅ 드라이브를 사용하여 파일을 보유하기 위해 OS가 자체 데이터 구조를 장치에 기록하는 단계
1. 장치를 하나 이상의 블록 또는 페이지 그룹으로 파티션
➡ OS는 각 파티션을 별도의 장치인 것처럼 취급할 수 있다.
➡ OS에서 장치를 인식하면 파티션 정보를 읽은 다음, OS는 파티션에 해당하는 장치 항목을 생성한다.
➡ /etc/fstab과 같은 구성 파일은 OS에 파일 시스템을 포함하는 각 파티션을 지정된 위치에 마운트 하고 읽기 전용과 같은 마운트 옵션을 사용하도록 지시한다.
(파일 시스템을 마운트하면 시스템과 해당 사용자가 그 파일 시스템을 사용할 수 있게 됨)
2. 볼륨 생성 및 관리
➡ 파일 시스템이 파티션 내에 직접 배치될 때와 같이 이 단계는 암시적으로 적용되고, 그러면 해당 볼륨을 마운트하여 사용할 수 있다.
➡ 다른 경우, 볼륨 생성 및 관리가 명시적으로 행해진다.
(볼륨: 마운트 가능한 모든 파일 시스템을 의미)
3. 논리적 포매팅 또는 파일 시스템의 생성
➡ OS는 초기 파일 시스템 자료구조를 장치에 저장한다.
11.5.2 Boot Block
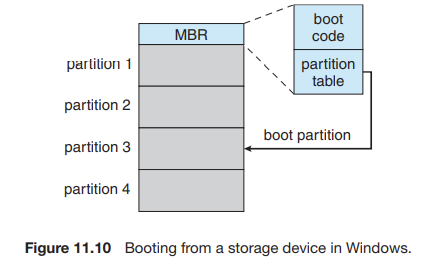
- 부트스트랩 로더 (bootstrap loader)
: 컴퓨터의 전원을 켜거나 재부팅할 때와 같이 컴퓨터가 실행을 시작하기 위해 실행되는 초기 프로그램
✔ 작은 부트스트랩 로더 프로그램은 보조저장장치에서 완전한 부트스트랩 프로그램을 가져온다.
✔ 완전한 부트스트랩 프로그램은 장치의 고정된 위치에 있는 '부트 블록'에 저장된다.
- 부트 디스크 / 시스템 디스크
: 부트 파티션이 있는 장치
✔ 부트스트랩 NVM의 코드는 저장장치 컨트롤러에게 부트스트랩 프로그램을 메모리에 올리도록 지시하고, 그 프로그램의 수행을 시작한다.
- MBR (master boot record)
: 하드 디스크의 첫 번째 논리 블록 또는 NVM 장치의 첫 번째 페이지
부트 코드와 파티션 테이블이 들어 있다.
어떤 파티션이 부트되어야 하는가에 대한 표시가 같이 되어 있다.
✔ 부팅은 시스템 펌웨어에 상주하는 코드를 실행하여 시작하고, 이 코드는 시스템이 MBR에서 부트 코드를 읽도록 지시한다.
11.5.3 Bad Block
디스크는 움직이는 부품들이 있고 매우 정밀하므로 고장나기 쉽다.
어떤 경우는 공장에서 출고될 때 이미 손상 블록을 가지고 나올 수도 있다.
손상된 블록들은 디스크와 컨트롤러에 따라 다양한 방법으로 처리될 수 있다.
✅ 섹터 예비 (sector sparing) 또는 섹터 포워딩 (sector forwarding)
✔ 컨트롤러는 손상 블록의 리스트를 유지한다.
✔ 리스트는 공장에서 저수준 포맷하는 동안 초기화되고, 디스크가 사용되는 동안 계속 유지된다.
✔ 저수준 포맷팅은 OS가 볼 수 없는 예비 섹터를 남겨 놓고, 컨트롤러는 이러한 예비 섹터 중 하나를 손상된 섹터와 교체시킬 수 있다.
❓ 손상된 섹터를 예비 섹터로 교체했을 경우, 논리적 블록이 요청될 때마다 변경된 새로운 섹터 주소로 가게 됨!
✅ 섹터 밀어내기 (sector slipping)
✔ 블록 17에 결함이 생겼고, 첫번째 예비 섹터가 202 다음에 있다고 할 때, 17부터 202까지 모든 섹터를 재매핑시킨다. (한칸씩 이동)
➡ 섹터 202는 예비 섹터로 복사되고, 201은 202로, 200은 201로,,,
✅ 연성 에러 (soft error)
손상된 블록 데이터를 복사하고 예비 블록으로 대체할 수 있는 경우
✅ 경성 에러 (hard error)
데이터를 잃게되는 경우이며, 손상된 블록 내용은 백업으로부터 가져와야 하는 등 사람의 개입이 필요하게 된다.
11.6 Swap-Space Management
스와핑 (swapping)은 사용 가능 물리 메모리가 매우 작아질 때 활성화되며, 사용 가능 메모리를 만들기 위해 (사용빈도가 적은) 프로세스들은 메모리에서 스왑 공간으로 이동하게 된다.
그러나 현대에는 전체 프로세스가 아닌 페이지들을 스왑한다.
이러한 점을 반영해 '스와핑'과 '페이징'을 같은 의미로 사용하기도 한다.
11.6.1 Swap-Space Use
스왑 공간은 사용하는 OS에 따라 다양하게 운영된다.
스와핑을 사용하는 시스템에 따라서는 프로세스의 이미지 전체를 스왑 공간에 유지하게 할 수도 있고, 페이징을 사용하는 시스템에서는 단순히 메인 메모리에서 밀려나는 페이지들을 이 공간에 저장할 수도 있다.
➡ 스왑 공간의 크기는 물리 메모리의 크기, 가상 메모리의 크기, 가상 메모리가 사용되는 방식 등에 따라 적게는 수 MB에서 많게는 수 GB이다.
11.6.2 Swap-Space Location
스왑 공간은 두 군데에 있을 수 있다.
- 일반 파일 시스템이 차지하고 있는 공간
- 별도의 raw 파티션
11.7 Storage Attachment
11.7.1 Host-Attached Storage
호스트 연결 저장장치는 로컬 I/O 포트를 통해 액세스 되는 저장장치이다.
고성능 워크스테이션과 서버는 일반적으로 더 많은 저장장치가 필요하거나 저장장치를 공유해야 하므로 광섬유 채널(fire channel, FC)과 같은 더 정교한 I/O 아키텍처를 사용한다.
➡ FC: 넓은 주소 공간과 스위치 기능이 있는 특성 때문에 다수의 호스트와 저장장치가 기본 망에 연결되어 I/O 통신에 큰 유통성을 제공한다.
다양한 저장장치가 호스트 연결 저장장치로 사용하기 적합한데, 그 중에는 HDD, NVM 장치, CD, DVD, Blu-ray 및 테이프 드라이브 및 SAN (storage-area net-work) 등이 있다.
11.7.2 Network-Attached Storage
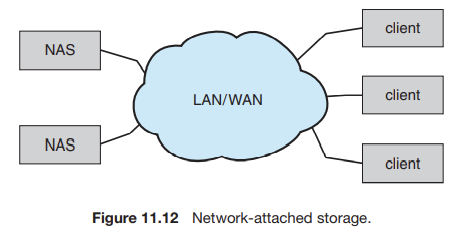
✅ NAS (nework-attached stoarge)
✔ 네트워크를 통해 저장장치에 대한 액세스를 제공한다.
✔ 클라이언트는 NFS 또는 CIFS 등의 원격 프로시저 호출을 통해 NAS에 접근한다.
✔ NAS는 디바이스가 가지고 있는 전용 프로토콜이 아닌 TCP/IP 상에서 RPC를 사용하여 호출한다.
11.7.3 Cloud Storage
네트워크 연결 저장장치와 유사하게 클라우드 저장장치는 네트워크를 통해 저장장치에 액세스 할 수 있다. 하지만 유료(또는 무료)로 저장장치를 제공하는 원격 데이터 센터에 인터넷 또는 다른 WAN을 통해 접속하여 액세스 된다.
11.7.4 SAN and Storage Arrays
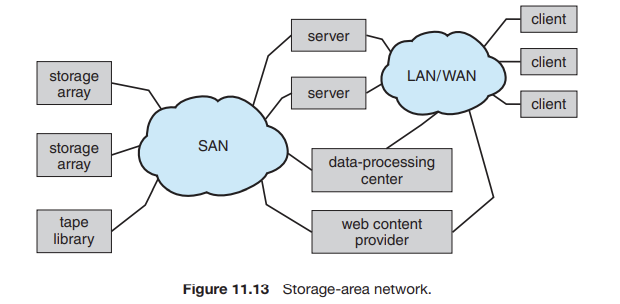
✅ SAN (storage-area network)
✔ 서버들과 저장장치 유닛들을 연결하는 사유 네트워크이다.
➡ 따라서 네트워크 프로토콜이 아닌 저장장치 프로토콜을 사용한다.
✔ 여러 호스트와 저장장치가 같은 SAN에 부착될 수 있고, 저장장치는 동적으로 호스트에 할당이 가능해 융통성 있게 사용할 수 있다.

- 저장장치 배열 (storage arrays)
SAN 포트, 네트워크 포트 또는 둘 다를 포함하는 특수 목적 장치.
또한 데이터를 저장하는 드라이브와 저장장치를 관리하고, 네트워크를 통해 저장장치에 액세스 할 수 있는 컨트롤러를 포함한다.
11.8 RAID Structure
디스크를 만드는 기술이 발전함에 따라 디스크의 가격이 저렴해지면서 여러 개의 디스크를 이용해 병렬로 운영되는데,, 더 신뢰성 높고 더 빠른 데이터 전송률을 확보하기 위해 RAID (redundant array of inexpensive disk)를 사용한다.
11.8.1 Improvement of Reliability via Redundancy
디스크를 한 개만 사용하여 데이터를 저장하는 경우, 한 번 디스크 오류가 발생하면 엄청난 양의 데이터 손실이 발생할 수 있다. 따라서 중복을 허용하여 데이터를 저장함으로써 데이터의 분실을 막는다.
✅ 미러링 (mirroring)
✔ 중복을 도입하는 가장 간단한 (그러나 가장 비용이 많이 드는) 접근 방법으로, 모든 드라이브의 복사본을 만드는 것이다.
✔ 미러링을 사용하는 경우, 하나의 논리 디스크는 두 개의 물리 드라이브로 구성되고 모든 쓰기 작업은 두 드라이브에서 실행된다. 이러한 결과를 미러드 볼륨이라고 부른다.
이 볼륨 중 하나의 드라이브에 오류가 발생하면, 다른 드라이브로부터 데이터를 읽어 들인다.
✔ 두 디스크를 사용하여 동시에 쓰기를 진행하는 경우 갑자기 전원 고장이 발생한다면, 두 블록은 불완전한 상태가 되는데 이를 방지하기 위해 NVRAM 캐시(비휘발성 캐시)를 RAID 영역에 두고 첫 번째 디스크에 쓰기 작업을 마친 후, 두 번째 디스크에 쓰기 작업을 마친다. 이는 전원 결함 시 데이터 손실을 막아 쓰기 작업이 완전하게 끝날 수 있다.
11.8.2 Improvement in Performance via Parallelism
디스크를 병렬로 접근하게 된다면 한 개의 요청으로 두 개의 디스크에 동시에 쓰기 작업 혹은 읽기 작업이 가능하다.
✅ 데이터 스트라이핑 (data striping)
✔ 여러 드라이브에 각 바이트의 비트를 나누어 저장한다.
➡ 예를 들어 8개의 드라이브를 가지고 있는 경우, 각 드라이브 i에 각 바이트의 비트 i를 쓰는 것이다. 8개의 드라이브의 배열은 보통 사이즈의 8배, 8배의 접근율을 가지는 하나의 드라이브로 취급된다.
✔ n개의 디스크에서 파일의 i번째 블록은 (i mod n) + 1의 드라이브로 간다.
✔ 스트라이핑도 비트 레벨이 아닌 바이트 레벨, 섹터 레벨로 가능하며, 블록 레벨의 스트라이핑이 가장 일반적이다.
11.8.3 RAID Levels
미러링은 높은 신뢰성을 제공하지만 비용이 많이 소요된다.
스트라이핑은 높은 전송률을 제공하지만 신뢰성을 향상할 수 없다.
적은 비용으로 중복을 허용하는 많은 기법이 있으며, RAID 레벨로 분류될 수 있다.
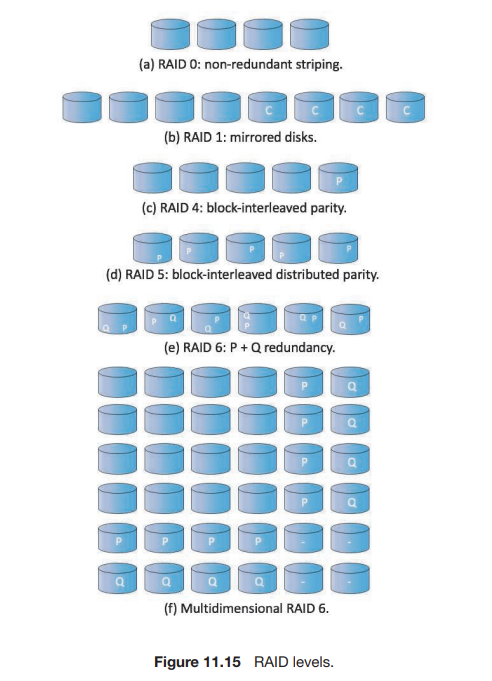
- RAID 0 : 블록 레벨 스트라이핑 디스크 구성으로 여러 개의 디스크를 사용하여 입출력 속도를 향상시키는 구성
- RAID 1 : 드라이브 미러링을 사용
- RAID 4 : 메모리-스타일 오류 수정 코드(ECC) 구성으로 패리티 비트를 이용하여 단일 비트 손상의 경우 데이터를 복구하는 방법이다. 예를 들어, 일련의 쓰기 요청의 첫 번째 데이터 블록은 드라이브 1에, 두 번째 블록은 드라이브 2에, N번째 블록은 드라이브 N에 이런 식으로 저장될 수 있고, 이러한 블록의 오류 수정 계산 결과는 드라이브 N+1(P)에 저장된다.
- RAID 5 : RAID 3,4의 경우 다른 디스크에 패리티비트 정보를 저장하는데 이럴 경우 패리티 비트가 저장된 하드가 손실된 경우가 있다. 이를 막기 위해 비트 정보와 함께 패리티 정보도 N+1개로 나누어 분산시켜 저장한다.
- RAID 6 : P + Q 중복 기법이라고 불리기도 한다. RAID 5와 유사하지만 여러 디스크 오류에 대비하기 위해 추가 중복 정보를 저장한다. 패리티 비트 대신에 에러 교정 코드를 사용한다. 4비트마다 2비트의 중복 데이터를 허용하므로 시스템 내의 2개의 디스크 오류가 생길 수 있다.
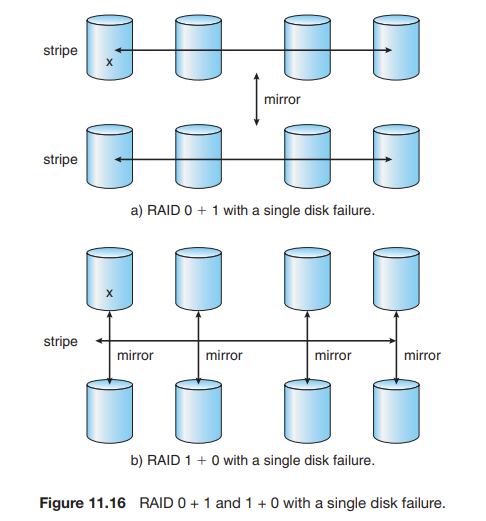
- RAID 0+1 : RAID 0과 RAID 1을 조합한 것이다. 높은 성능과 높은 신뢰성 두 가지를 모두 사용할 수 있는 대신에 하드디스크 사용량이 두 배로 늘어난다. 드라이브의 세트가 스트라이프되고, 그 스트라이프가 다른 동등한 스트라이프로 미러링된다.
- RAID 1+0 : 드라이브는 쌍으로 미러링된 후 결과 미러링 된 쌍이 스트라이프 된다.
11.8.4 Selecting a RAID Level
이러한 다양한 선택이 가능하다면,, 시스템 설계자는 어떤 RAID 레벨을 선택해야 할까?
고려사항 중 하나는 복구 능력이다.
11.8.5 Extensions
RAID의 개념은 테이프나 무선 시스템의 데이터를 브로드캐스트 하는 일을 포함하여 여러 저장장치에 적용된다. 테이프의 경우에는 데이터 복구율을 향상시킬 수 있고, 무선 시스템의 데이터 브로드캐스팅의 경우에는 데이터의 블록은 작은 유닛으로 나누어지고 패리티를 함께 브로드캐스팅 하여 전송 손실이 생기더라도 복구가 가능하다.
11.8.6 Problems with RAID
RAID는 물리적 매체의 오류는 보호하지만 다른 하드웨어나 소프트웨어 오류는 보호하지 못한다.
