
Week 2
Day 01
강의 복습 내용
[Deep Learning Basic]
1. Historical Review
- Artificial Inteligence : 사람의 지능을 모방
- Machine Learning : 데이터를 통해 사람의 지능을 모방
- Deep Learning : 뉴럴 네트워크 모델을 사용하여 데이터를 통해 사람의 지능을 모방
Deep learning의 4가지 Key point
- Data : 풀고자하는 문제의 데이터
- Model : 데이터가 주어졌을 때 내가 알고 싶어하는 것을 구할 수 있도록 도와주는 것
- AlexNet, GoogLeNet, ResNet ...
- Loss Function : 모델을 어떻게 학습할지,,, 이루고자 하는 근사치에 불과하다
- MSE, CE, MLE
- Algorithm : Data, Model, Loss function이 주어졌을 때 네트워크를 어떻게 줄일지
Deep Learning 방법론
2012년 AlexNet : 컨볼루션 신경망(CNN)으로써 CNN의 부흥에 아주 큰 역할을 한 구조이다.
2013년 DQN : 강화 학습 가능한 심층 신경망을 이용한 인공지능
2014년 Encoder / Decoder : NMT(Neural Machine Translation)에 필요한 모델
2014년 Adam Optimizer
2015년 Gan
2015년 Residual Networks (ResNet) : 네트워크를 깊게 쌓을 수 있게 만들어준 학습 모델
2017년 Transformer
2018년 Bert
2019년 Big Language Models(GPT-X)
2020년 Self-Supervised Learning : 한정된 학습 데이터 외에 라벨을 모르는 데이터를 사용하여 학습
2. Neural Networks & Multi-Layer Perceptron
Neural Network는 인간의 뇌를 모방한 모델이다 / 함수를 근사하는 모델이다.
예시로 Linear Regression은 가장 간단한 뉴럴 네트워크라 할 수 있다. 입력과 출력이 1차원일때 입력과 출력을 연결하는 모델 즉 2개의 파라미터(weight, bias)를 찾는것이 목표이다. 즉 N개의 데이터를 잘 표현할 수 있는 모델을 찾는 것.

그렇다면 W와 B는 어떻게 구할까? Back Propagation을 통해 구한다. 즉 Loss function을 각각의 파라미터로 미분(편미분)하여 음수 방향으로 업데이트 하면 loss가 최소화하는 어떤 지점으로 수렴하게 될 것이다.



이런 식으로 W와 B를 업데이트하는 방법을 Gradient Descent라고 한다. 줄이고자하는 loss function에 대해서 파라미터에 대한 편미분을 구하고, 구한 편미분을 빼주는 것이다. 다시 말해, 마지막 최종 loss function 값을 전체 파라미터로 미분하는 것이 Back Propagation이고, 각 Back Propagation에서 나온 편미분 값을 업데이트 시키는 것이 Gradient Descent이다.
딥러닝은 뉴럴 네트워크를 깊게 쌓는 것이다. 한번 선형 결합이 반복되면 Nonlinear Transform을 거쳐 더 많은 표현력을 갖도록 한다.

Loss Function이 어떤 성질을 갖고 있고, 왜 내가 원하는 결과를 얻어 낼 수 있는지 알아야된다!
Regression Model들은 MSE를 loss function으로 사용한다. MSE로 학습을 할 수록 오류가 감소하는 것을 볼 수 있다.
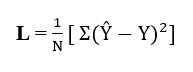
Classification Model은 Cross Entropy를 사용한다. Vanishing Gradient와 느린 학습 속도를 방지할 수 있기 때문이다. 크로스 엔트로피 참고 사이트
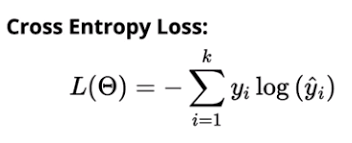
마지막으로 Probabilistic에서는 MLE을 사용한다. 최대우도법 참고 사이트
과제 정리
파이토치를 사용하여 Multilayer Perceptron을 구현하여 MNIST 데이터를 학습시켰다. MLP 클래스를 만들어 초기화 함수와 foward 함수를 구현하였다. Loss function으로 Cross Entropy를 사용했고, optimize 알고리즘으로는 Adam을 사용했다.
1. Reset Gradient
2. Back Propagate
3. Optimizer Update
학습 과정을 거쳤다. 파이토치를 처음 사용하면서 함수가 다 구현이 되어있어 편리했다. 히든 레이어를 더 만들어 정확도가 올라가는지 실험해보자!!
피어세션 정리 및 학습 회고
부스트코스의 2주차이다. 1주차때 다 하지 못한 선택 과제를 이해하려고 노력했으나 역시 수학은 어렵다... 파이토치를 사용한 실습을 했고 코드 내용을 서로 상의했다. 강의를 듣고 그날 바로 학습 정리를 하니까 공부하는데 도움이 많이 된다.
피어세션
Day 02
강의 복습 내용
[Deep Learning Basic]
3. Optimization
- Generalization : training error와 test error의 차이. Generation이 좋다 == 네트워크의 성능이 학습 데이터와 비슷한 성능이 나온다.
- Underfitting / Overfitting
- Cross Validation : 학습데이터(training / validation data)를 나눠서 번갈아 가면서 학습 시킨다. cross validation으로 hyper parameter를 찾아 보정 후 모든 데이터를 학습시킨다.
- Bias / Variance : Bias는 평균적으로 봤을때 true target에 접근하면 low, 많이 벗어나면 high bias이다. Variance는 입력을 넣었을때 출력이 얼마나 일관적인지를 표현한다. 학습 데이터에 노이즈가 있을시 bias와 variance 둘다 줄이는건 힘들다.
- Bootstrapping : 학습 데이터를 여러개로 나눠 여러 모델을 만든다.
- Bagging and boosting
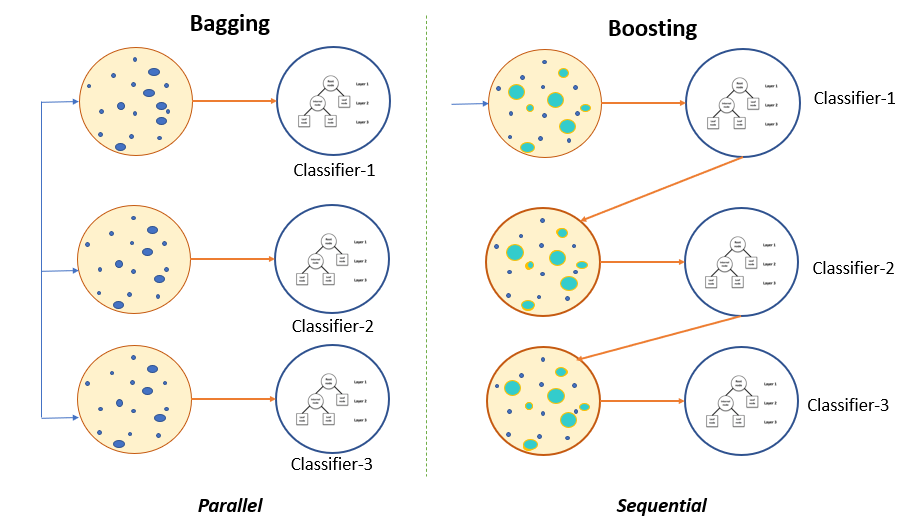
Batch Size가 클 수록 sharp minimizers이고, 작을 수록 flat mnimizer이다. 다시 말해 Batch의 사이즈가 작을 수록 Generation이 좋다.
Gradient Descent Methods
-
Stochastic Gradient Descent
'Gradient Descent'란 네트워크에서의 결과값과 실제 결과값 사이의 차이를 나타내는 loss function의 최소화하기 위해 기울기(gradient)의 반대 방향으로 일정 크기만큼 이동하는 것을 반복하여 최소값을 찾아낸다. Stochastic Gradient Descent는 데이터의 모음(mini-batch)에 대해 loss function을 계산하여 계산의 속도를 높이는 장점이 있다. -
Momentum
Momentum 방식은 Gradient Descent를 통해 이동하는 과정에 '관성'을 주는 것이다. 현재 Gradient Descent를 통해 이동하는 방향과 별개로, 과거에 이동했던 방식을 기억해 그 방향으로 일정 정도를 추가적으로 이동하는 방식이다. -
Nesterov accelerated gradient
Momentum 방식을 기초로 하지만 Gradient를 계산하는 방식이 살짝 다르다.

-
Adagrad
파라미터가 얼만큼 변했는지 확인하여, 많이 변한 파라미터는 적게 변화시키고 적게 변한 파라미터는 많이 변화시킨다. 학습이 진행될 수록 학습이 멈춰지는 단점이 생긴다. -
Adadelta
-
RMSprop
-
Adam
Momentum을 사용하고, adaptive하게 learning rate를 계산한다.
과제 정리
SGD, Momentum, Adam optimizer를 사용하여 학습된 모델을 plot하여 비교해봤다. Adam 알고리즘이 가장 좋은 성능을 보여주었다. Momentum과 learning rate을 사용하여 더 좋은 성능을 보여준거 같다. Momentum 알고리즘이 SGD보다 좋은 성능을 보여주었는데 이는 이전에 얻은 정보를 꾸준히 반영하는 효과가 있기 때문이다.

위 그림을 보면 피크가 큰 곳의 정확도가 매우 높게 나온다. 그 이유는 loss function을 MSE로 설정하였기 때문이다. 오차값이 더 클 수록 더 많이 계산해서 정확히 맞춘다.
피어세션 정리 및 학습 회고
Gradient Descent의 알고리즘의 변형 알고리즘을 학습해보았다. 다양한 알고리즘이 있으며 어떤 문제를 풀고 있는지에 따라 어떤 알고리즘을 사용하는지, 어떤 네트워크에 적용해야하는지 차이가 날 것이므로 실제로 실험해볼 필요가 있을 거 같다.
피어세션
Day 03
강의 복습 내용
[Deep Learning Basics]
4. Convolution Neural Networks
CNN은 인간의 시신경을 모방하여 만든 딥러닝 구조 중 하나이다. Convolution을 통해 공간적인 특성을 유지하는 특징이있다. Convolution layer, pooling layer, fully connected layer로 이루어져 있다.
- Convolution layer : 3X3 필터를 사용하여 Convolution feature의 값을 얻어내는 레이어이다. 이미지에서의 유용한 정보를 찾는 feature extraction을 한다.
- Pooling layer : 데이터의 공간적인 특성을 유지하면서 크기를 줄여주는 층으로 Convolution layer 사이에 주기적으로 넣어준다.
- Fully connected layer : 최종적으로 원하는 결과값을 만들어주는 layer. Decision making을 한다. fully connected layer를 줄이는 추세 -> 파라미터의 개수를 줄일려고
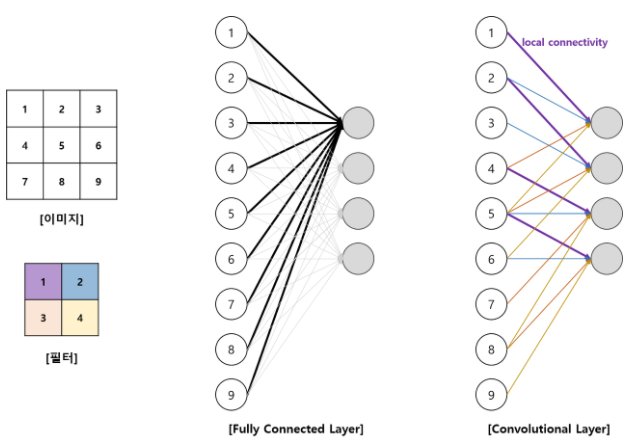
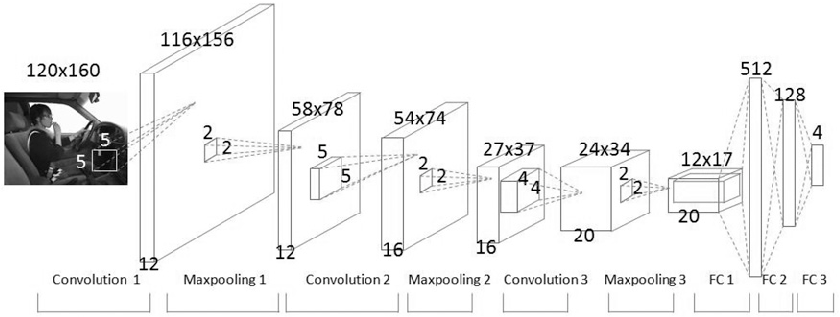
CNN 주요 용어
- Convolution
합성곱 연산은 두 함수 f, g 가운데 하나의 함수를 반전(reverse), 전이(shift)시킨 다음, 다른 하나의 함수와 곱한 결과를 적분하는 것을 의미한다. 출처: https://ko.wikipedia.org/wiki/%ED%95%A9%EC%84%B1%EA%B3%B1
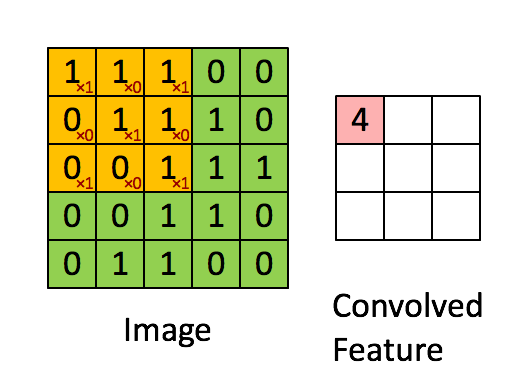
-
Channel
컬러 사진은 색을 표현하기 위해 RGB 3개의 실수로 3차원의 데이터로 표현한다. 즉 3개의 채널로 구성된다. 반면 흑백 사진은 2차원 데이터로 1개의 채널로 구성된다. 높이가 39, 폭이 31인 컬러 사진은 (39,31,3)으로 표현되고, 흑백사진은 (39,31,1)로 표현된다. -
Filter (Kernel)
이미지의 특징을 찾아내기 위한 파라미터이다. 일반적으로 (3,3) 또는 (5,5)와 같은 행렬로 정의한다. -
Stride
움직인 간격을 의미한다.
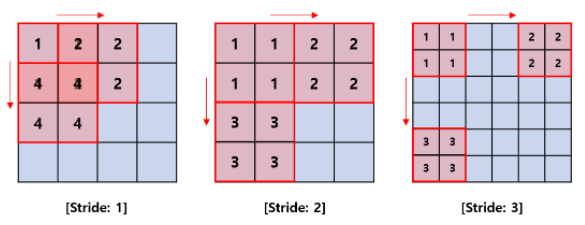
-
Padding
행렬의 크기가 작아짐을 방지하는 것과, 이미지의 모서리 부분의 정보 손실을 줄이고자 이미지 주변에 0으로 채워 넣는 방법이다.
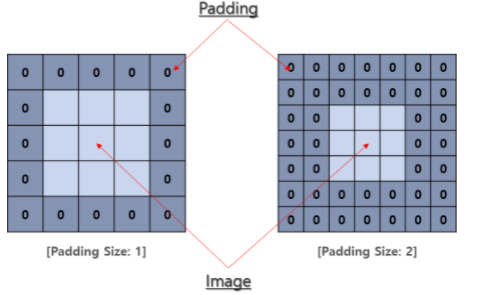
CNN 파라미터 계산
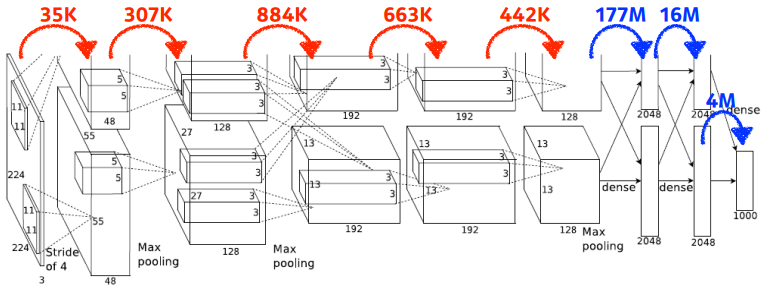
Convolution
35K = (11 x 11 x 3) x 48 x 2
307K = (5 x 5 x 48) x 128 x 2
884K = (3 x 3 x 128) x 2 x 192 x 2
663K = (3 x 3 x 192) x 192 x 2
442K = (3 x 3 x 192) x 128 x 2
Fully Connected Layer (Dense Layer)
177M = (13 x 13 x 128) x 2 x 2048 x 2
16M = 2048 x 2 x 2048 x 2
4M = 2048 x 2 x 1000
Fully Connected Layer(Dense Layer, Multi-Layer Perceptron)는 파라미터의 개수가 기하급수적으로 커진다. input의 파라미터 개수와 output의 파라미터의 개수를 곱한 것이므로 매우 커진다.
1 X 1 Convolution
이미지에서 1개의 픽셀만 보고, 채널의 수를 줄여 파라미터의 개수를 줄인다.
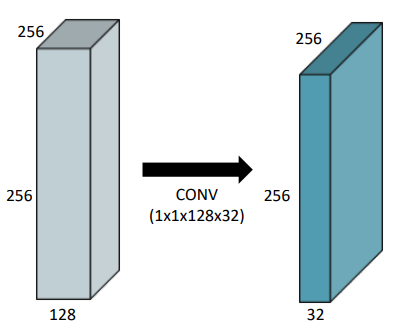
참고
5. Modern Convolution Neural Networks
-
AlexNet
ReLu activation (overcome vanishing gradient problem), GPU, Data augmentation, Dropout, Local response normalization
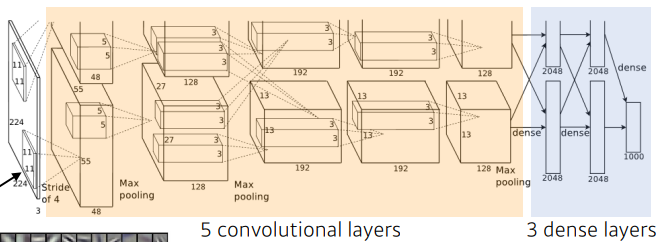
-
VGGNET
3 x 3 convolution filter만을 사용했다.
왜? (3,3)을 2번 했을때와 (5,5)를 1번 했을때의 파라미터의 개수 차이가 있기 때문에 (3,3)을 2번 사용하는 것이 더 효율적이다.
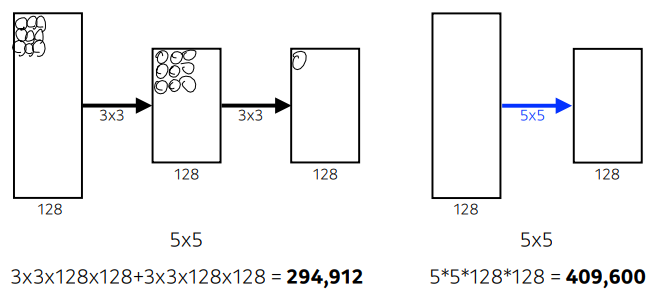
-
GoogLeNet
1 x 1 convolution을 활용해서 파라미터의 개수를 줄인다.
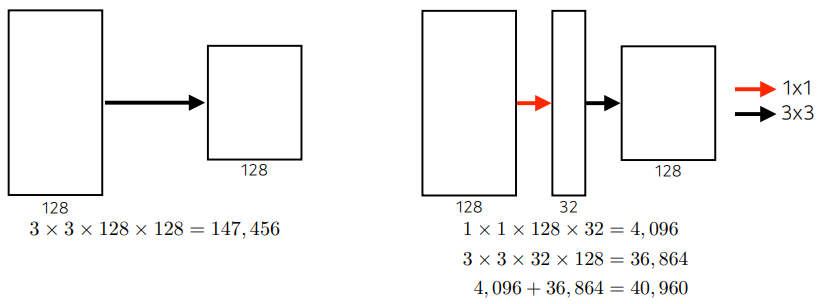
-
ResNet
Identity map을 추가해서 더 많은 네트워크이 있어도 학습이 더 잘되게끔 하였다. -
DenseNet
ResNet과 달리 더하지 않고 Concatenation을 한다. Dense Block과 Transition Block을 반복한다.
6. Computer Vision Applications
Semantic Segmentation(Dense prediction)은 사진에 있는 모든 픽셀을 해당하는 class로 분류하는 것이다.
Fully Convolutional Network
Fully Connected Layer를 없앤 이유로 마지막 Dense Layer를 거치고 나면 위치 정보가 사라지기 때문이다. Segementation은 위치 정보가 핵심이기 때문에 이는 심각한 문제이다. Transposed convolution을 통해서 낮은 해상도의 heat map을 업샘플링 해서 인풋과 같은 크기의 맵을 만든다. (단순히 분류만 했던 network가 fully connected layer를 제거 함으로서 semantic segmentation을 할 수 있고, heat map을 제작할 수 있는 가능성이 나온다)
Detection
- R-CNN
1. Image를 입력 받는다.- Selective search 알고리즘으로 regional proposal output 약 2000개를 추출한다. 모두 동일한 사이즈로 만들어 주기 위해 warp해준다.
- CNN 모델 -> 2000개의 이미지를 모두 CNN을 사용하기 때문에 시간이 오래걸린다.
- classification을 진행하여 결과를 얻는다.
- SPPNet
CNN을 한번만 사용하여 R-CNN보다 더 빠르게 작동한다.
- Fast R-CNN
- Faster R-CNN
- YOLO
과제 정리
Convolutional Neural Network (CNN) 알고리즘을 사용해서 MNIST 데이터를 학습시켰다. CNN은 MLP와 달리 레이어의 channel 수를 직접 정할 수 있다. 또한 마지막에 Dense Layer를 작성하므로 분류를 진행한다. 다시 말해 Convolution Layer를 거치고, 한 줄로 핀 다음에 Fully Connected layer를 거치는 과정이다.
피어세션 정리 및 학습 회고
CNN을 학습하는데 상당히 많은 부분이 헷갈렸다. 강의를 반복해서 듣고, 구글링 후 정리를 했더니 이해가 된다. AI를 공부하면서 처음 듣는 단어들이 상당히 많아 헷갈리는데 단어를 정확히 정의 하는 것이 매우 중요하다 생각이 된다.
마스터 클래스에서 '생활코딩'의 이고잉님의 깃을 배울 수 있었다. 깃을 알고 있긴 했지만 이고잉님의 강의를 듣고 더 정확히 알 수 있어 깃이 한결 편해졌다.
피어세션
Day 04
강의 복습 내용
[Deep Learning Basics]
7. Recurrent Neural Networks
Sequential Model
연속적인 데이터는 이미지보다 처리하는 과정이 매우 어렵다. 얻고 싶은 정보는 하나인데 데이터의 길이(차원)를 모르기 때문이다. 따라서 CNN 모델을 사용할 수 없다. Sequential Model은 입력이 들어오면 다으메 들어올 걸 예측하는 모델이다.
- Autoregressive model : 과거의 몇개의 데이터만 보겠다.
- Markov model : 바로 직전의 데이터만 보겠다.
- Latent autoregressive model : 히든 단계가 과거의 정보를 요약하고 있다. 다음 단계는 히든 스테이트 하나에 의존하게 된다.
RNN
RNN은 시퀀스 모델이다. 입력과 출력을 시퀀스 단위로 처리하는 모델이다.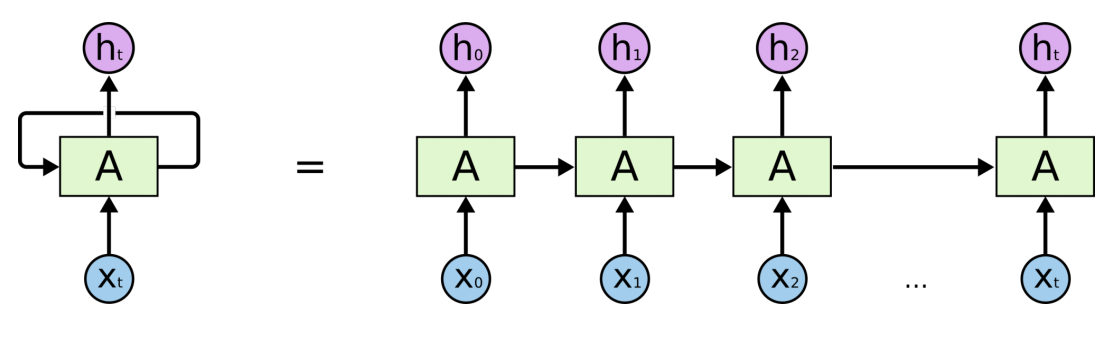 RNN은 관련 정보와 그 정보를 사용하는 지점 사이 거리가 멀 경우 역전파시 그래디언트가 점차 줄어 학습능력이 크게 저하된다. 이를 vanishing gradient problem라고 한다. 이를 극복한 것이 LSTM이다.
RNN은 관련 정보와 그 정보를 사용하는 지점 사이 거리가 멀 경우 역전파시 그래디언트가 점차 줄어 학습능력이 크게 저하된다. 이를 vanishing gradient problem라고 한다. 이를 극복한 것이 LSTM이다.
LSTM
LSTM은 RNN의 히든 state에 cell-state를 추가한 구조이다. 덕분에 state가 꽤 오래 경과하더라도 그래디언트가 잘 전파된다. 이전까지의 정보를 현재 입력 바탕으로 지울지, 새롭게 쓸지를 결정하고, 두 정보를 취합(update cell)을 한다. Update Cell를 한번 더 조작을 해서 그 값을 밖으로 내보낼지 output gate를 통해 결정한다.
- Forget Gate : 과거 정보를 잊는 단계이다. 0이 나오면 이전 상태의 정보를 잊고, 1이면 이전 정보를 기억한다.
- Input Gate : 현재 정보를 기억하기를 위한 단계이다.
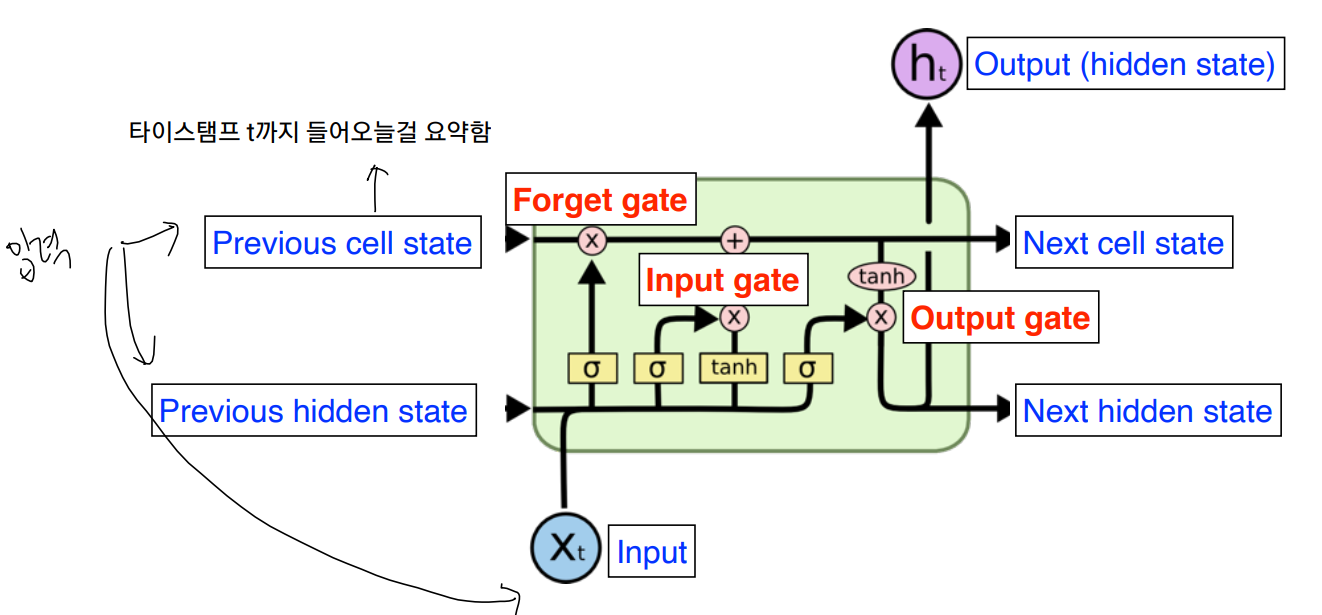
Gated Recurrent Unit
LSTM에 비해 파라미터의 수가 더 적어 성능이 좋다.
8. Transformer
Transformer는 self-attention을 이용해 병렬 처리가 가능하게 만드는 모델이다. 모델은 어떤 한 언어로 된 문장을 받아 다른 언어로 번역을 내놓을 수 있다. Transformer의 구조는 크게 Encoder와 Decoder로 나눌 수 있고 encoder 안에는 여러개의 encoder를 쌓아 올리고, decoder 또한 여러개의 decoder를 쌓아 올린 것이다.
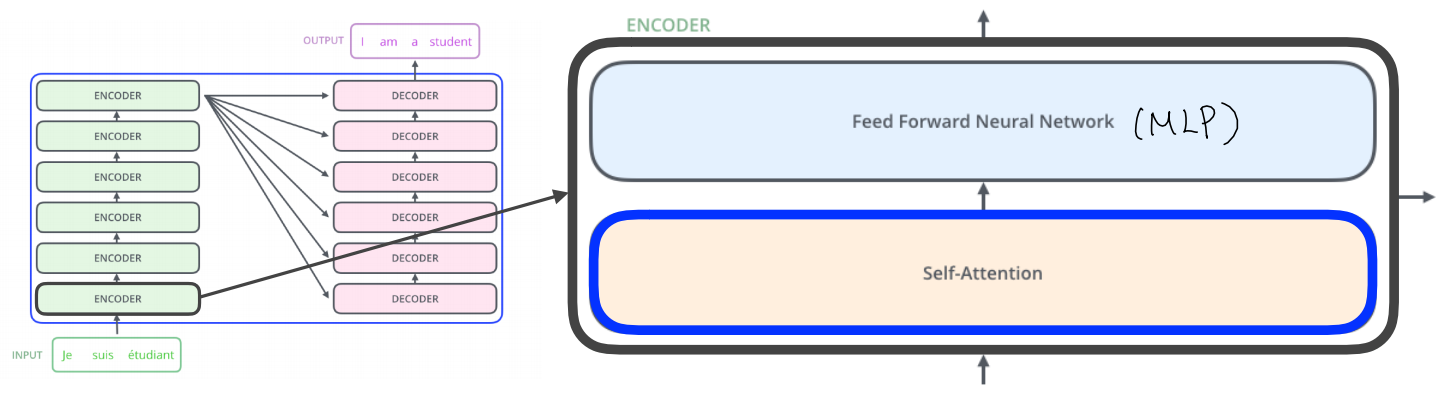
Encoder는 self-attention과 feed fowarde Neural Network로 구성되어 있다. 여기서 Self-Attention이 각 단어 사이의 관계성을 학습하는 과정을 거친다. 다시 말해 단어 사이의 dependency가 존재하는 반면 Feed Foward는 dependency가 없다. Self-Attention은 Query, Key, Value 3가지 벡터를 만들어낸다. Query 벡터 1개를 자신을 포함한 다른 모든 Key 벡터를 내적하여 score를 뽑아낸다. 계산한 score를 normalize와 softmax를 거쳐 value벡터와 곱하여 값들을 모두 더하면 최종 값이 된다.
Self-Attention은 Query, Key, Value 3가지 벡터를 만들어낸다. Query 벡터 1개를 자신을 포함한 다른 모든 Key 벡터를 내적하여 score를 뽑아낸다. 계산한 score를 normalize와 softmax를 거쳐 value벡터와 곱하여 값들을 모두 더하면 최종 값이 된다.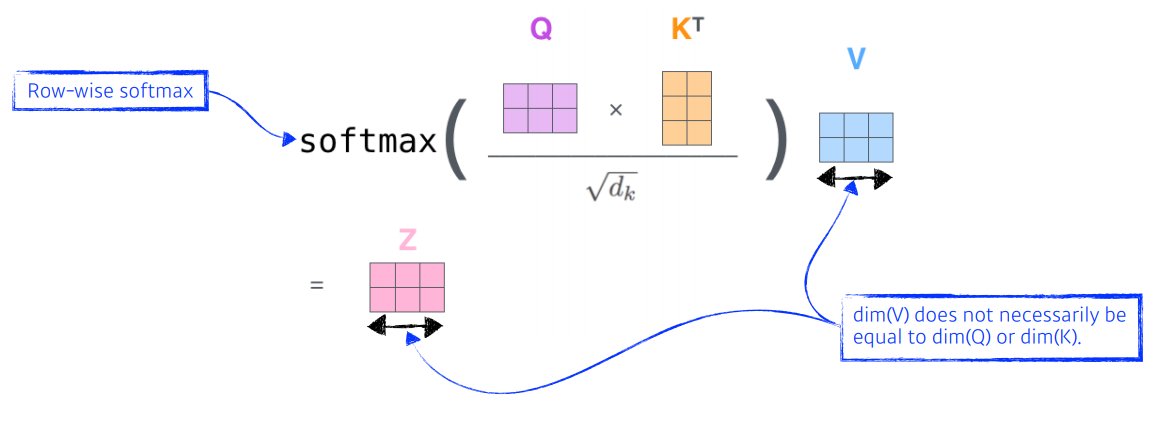
Position encoding이라는 벡터를 추가하여 입력 값에 더하여 각 단어의 위치와 시퀀스 내의 다른 단어 간의 위치 정보를 줄 수 있다. Encoder의 최상위 층의 Key, Value 벡터를 그대로 Decoder에서 사용한다.
과제 정리
과제 복습하기!!
피어세션 정리 및 학습 회고
학습이 갑자기 어려운 느낌이 들었다. 학습을 하고 바로 바로 정리해야되는데 일이 있어 못했다... 처음 듣는 단어가 엄청 많다 보니까 힘든 하루였다.
피어세션
Day 05
강의 복습 내용
[Deep Learning Basics]
9, 10. Generative Models
Generative Model은 단순히 이미지나 문장을 만드는 것에 그치지 않고 해당 데이터를 구분할 수 있다.
GAN(Genreative Adversarial Network)
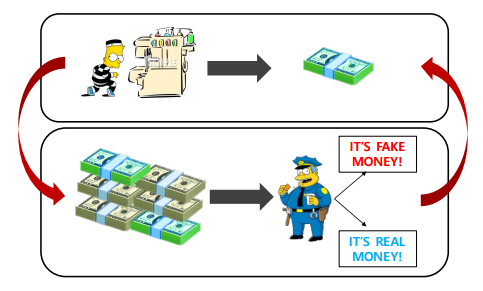
위 사진을 보면, 위조 지폐를 경찰이 분별하고 이를 바탕으로 도둑은 경찰을 속이기 위해 더 치밀하게 위조지폐를 만든다. 이 과정이 Gan과 매우 비슷하다고 볼 수 있다. Discriminator가 이미지가 들어오면 진짜와 가짜를 구별해주는 경찰의 역할을 해주고, Generator가 랜덤코드를 받아 가짜의 이미지를 만드는 도둑 역할을 한다. GAN의 장점은 Discriminator와 Generator가 동시에 같이 학습을 하며 성능이 상승해 굉장히 좋은 이미지를 만들 수 있다.
피어세션 정리 및 학습 회고
9강과 10강에 있는 내용을 제대로 이해하지 못했다. GAN은 유투브를 통해 이해를 했지만 9강에 있던 수학 수식이 왜 나왔는지 어떤 연관이 있는지 잘 이해가 안간다.....
오늘의 피어세션은 다른 팀과 1시간 하면서 어떻게 하는지 알아봤다. 다른 조들은 따로 알고리즘 공부를 한다길래 좋은 거 같아 우리 조도하기로 했다. 다음 주 부터 부지런히 공부해야될거 같다! 화이팅하자!!!!!! 다음 주는 당일에 학습 정리를 하고 부지런히 살자!!
피어세션
