NLP-Tokenizer
Tokenization(토큰화) 란?
Text를 여러 개의 Token으로 나누는 것
Tokenizaion 의 종류
character level
character 단위로 토큰화를 하는 방법은 한국어에서 가,나,다...와 같이 한 글자단위로 토큰화를 하거나, ㄱ,ㄴ... / ㅏ,ㅑ.. 와 같이 자음,모음으로 토큰화 방법을 말한다.
중국어(한자)의 경우는 characeter level로 토큰화를 해도 한 글자가 고유한 의미를 가지지만
한국어의 경우, 한 글자가 어떤 것을 의미하는 경우는 극히 드물고 고유한 의미를 표현하는 것은 아니기 때문에 한국어에 적용하는것은 적절하지 않은 방식이다.
space(word) level
한 문장내에서 띄어쓰기를 기준으로 토큰화를 하는 방식이다.
영어의 경우 공백을 기준으로 토큰화를 해도 단어별로 토큰화가 되지만( 몇몇 예외는 존재 ), 한국어의 경우 조사나 어미와 같은 다양한 문장구조가 존재하기 때문에 문제가 발생한다. 예를 들어, ( 컴퓨터를, 컴퓨터가, 컴퓨터는 ) 모두 컴퓨터를 의미하지만 뒤에 붙는 조사때문에 각각 다른 단어로 저장되기 때문에 학습이 잘 되지 않는 상황이 발생하기도 한다. "컴퓨터에는"이라는 단어가 등장하면 기계가 모르는 단어이기 때문에 OOV ( Out - Of - Vocabulary ) 문제가 발생한다. 또한 큰 말뭉치를 word 단위로 분절하면 매우 큰 vocab을 사용해야 하기 때문에 메모리 문제를 야기할 수 있다.
subword level
subword단위로 토큰화를 하는 것은 하나의 단어를 더 작은 단위의 의미있는 여러 서브워드로 나누는 작업이다. 이 과정으로 OOV 문제와 희귀 단어, 신조어와 같은 문제를 완화 할 수 있다. " 자주 등장하는 단어는 그대로 두고, 자주 등장하지 않는 단어는 의미 있는 서브 워드 토큰들로 분절한다. "
( 컴퓨터를, 컴퓨터가, 컴퓨터는, 노트북에는 ) 이라는 단어는
[ 컴퓨터 + 를 , 컴퓨터 + 가 , 컴퓨터 + 는, 노트북 + 에는 ] 과 같이 subword로 분리한다.
( 컴퓨터, 를, 가, 는, 노트북, 에는 )과 같이 사전이 만들어졌을 경우,
space level에서 생긴 문제인 "컴퓨터에는"이 등장할 때, 학습한 vocabulary안에 컴퓨터와 에는이 존재하기 때문에 문제를 해결할 수 있다.
An Empirical Study of Tokenization Strategies for Various Korean NLP Tasks 라는 tokenizer에 대한 흥미로운 논문이 있는데요.
본 연구는 한국어 언어모델에서의 tokenizing 방식에 따른 성능 평가를 진행하였고, 그 단위는
(1) 자소
(2) 음절
(3) 형태소
(4) subword
(5) 형태소분석 + subword로 생성한 vocab을 이용해 Subword 기반 토크나이징
(6) 띄어쓰기 기반
으로 실험을 진행하였습니다.
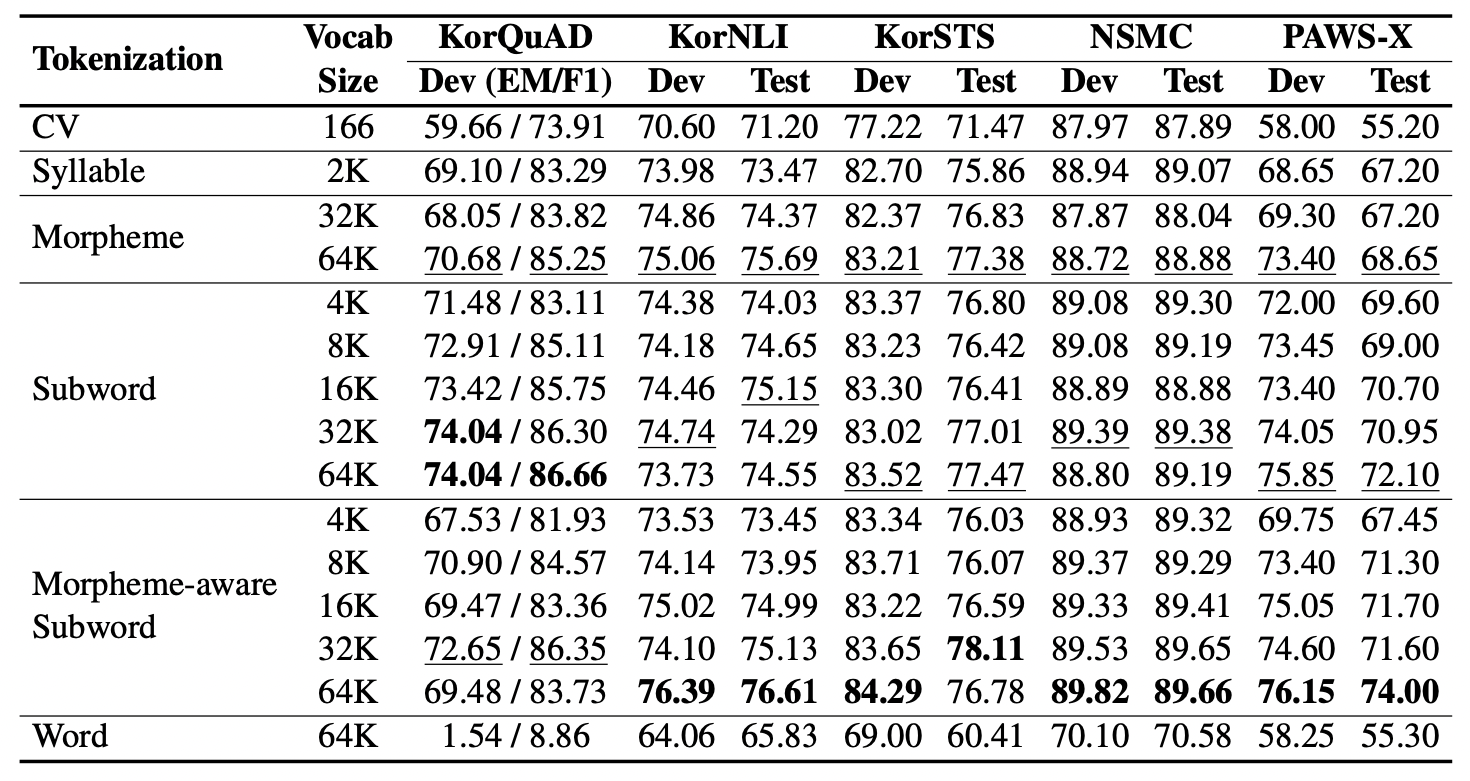
결과적으로는 morpheme-aware subword 방식이 한국어 자연어처리에서 가장 좋은 성능을 나타내주었습니다
