💡 인덱스(index)란?
인덱스는 데이터베이스의 테이블에 대한 검색 속도를 향상시켜주는 자료구조입니다.
테이블의 특정 컬럼(Column)에 인덱스를 생성하면, 해당 컬럼의 데이터를 정렬한 후 별도의 메모리 공간에 물리적 주소와 함께 저장됩니다. 컬럼의 값과 물리적 주소(key, value)를 한 쌍으로 저장합니다.
비유적으로 설명하자면 목차같은 것입니다. 두꺼운 책에서 우리가 원하는 내용이 있을 경우 목차에서 찾아본 페이지로 이동하는 것처럼 데이터베이스도 수많은 데이터 위치를 포함하는 자료구조를 통해 빠르게 찾아갈 수 있도록 도와줍니다.
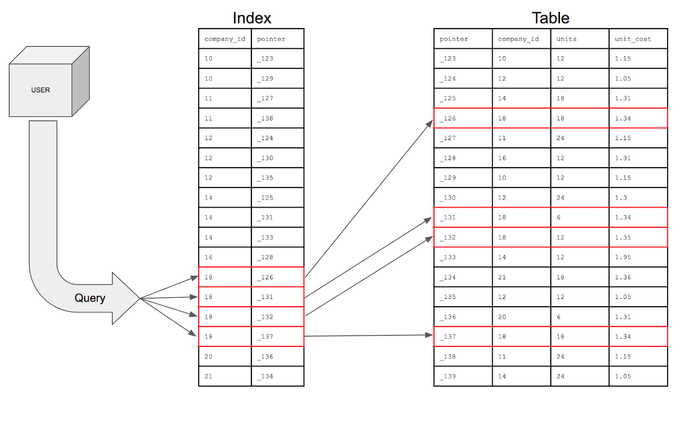
출처 : https://mangkyu.tistory.com/96
💡 인덱스(index)의 장단점
📁 장점
테이블을 검색하는 속도와 성능이 향상 됨으로써 데이터베이스의 부하를 줄일 수 있습니다.
핵심은 인덱스에 의 데이터들이 정렬된 형태를 가진다는 것입니다. 기존에 Where 문으로 특정 조건의 데이터를 찾기 위해서 테이블의 전체를 조건과 비교해야 하는 풀 테이블 스캔(Full table Scan) 작업이 필요했는데, 인덱스를 이용하면 데이터들이 정렬되어 있기 때문에 조건에 맞는 데이터를 빠르게 찾을 수 있습니다.
또한 ORDER BY 문이나 MIN/MAX 같은 경우도 이미 정렬이 되어 있기 때문에 빠르게 수행할 수 있습니다.
📁 단점
인덱스가 항상 정렬된 상태로 유지되어 오는 장점도 있지만, 그에 따른 단점도 존재합니다.
- 인덱스를 관리하기 위한 추가 작업이 필요
- 추가 저장 공간이 필요
- 잘못 사용하면 오히려 검색 성능 저하
인덱스를 항상 정렬된 상태로 유지해야 하기 때문에 인덱스가 적용된 컬럼에 INSERT, DELETE, UPDATE 작업을 수행하면 다음과 같은 추가 작업이 필요합니다.
- INSERT : 새로운 데이터에 대한 인덱스 추가
- DELETE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업 수행
- UPDATE : 기존의 인덱스를 사용하지 않음 처리, 갱신된 데이터의 대한 인덱스 추가
이처럼 인덱스의 수정도 추가적으로 필요하기 때문에 데이터의 수정이 잦은 경우 성능이 낮아집니다. 또 데이터의 인덱스를 제거하는 것이 아니라 '사용하지 않음' 으로 처리하고 남겨두기 때문에 수정 작업이 많은 경우 실제 데이터에 비해 인덱스가 과도하게 커지는 문제점이 발생할 수 있습니다. 별도의 메모리 공간에 저장되기 때문에 추가 저장 공간이 많이 필요하게 됩니다.
또한 인덱스는 전체 데이터의 10% ~ 15% 이상의 데이터를 처리하거나, 데이터 형식에 따라 오히려 성능이 낮아질 수 있습니다. 예를 들어 나이나 성별 같이 값의 RANGE 가 적은 컬럼인 경우, 인덱스를 읽고 나서 다시 많은 데이터를 조회하기 때문에 비효율적입니다.
💡 인덱스를 사용하면 좋은 경우
인덱스를 효율적으로 사용하기 위해선 데이터의 RANGE 가 넓고 중복이 적을수록, 조회가 많거나 정렬된 상태가 유용한 컬럼에 사용하는 것이 좋습니다.
- 규모가 큰 테이블
- INSERT, UPDATE, DELETE 작업이 자주 발생하지 않는 컬럼
- WHERE나 ORDER BY, JOIN 등의 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
💡 인덱스의 자료구조
인덱스는 여러 자료구조를 이용해서 구현할 수 있는데, 대표적으로 해시 테이블과 B+Tree가 있습니다.
📁 해시 테이블(Hash table)
해시테이블은 KEY 와 VALUE 를 한쌍으로 데이터를 저장하는 자료구조입니다. key 를 이용해 value를 구하는 방식이며 해시 충돌이라는 변수가 존재하지만 평균적으로 O(1) 의 매우 빠른 시간만에 원하는 데이터를 탐색할 수 있는 구조입니다.
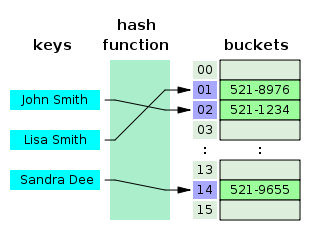
출처 : https://en.wikipedia.org/wiki/Hash_table
해시 테이블을 이용한다면 key는 컬럼의 값, value는 데이터의 위치로 구현하는데, 해시 테이블은 실제로 인덱스에서 잘 사용되지 않습니다. 그 이유는 해시테이블은 등호(=) 연산에 최적화 되어 있기 때문입니다. 데이터베이스에선 부등호(>, <) 연산이 자주 사용되는데, 해시 테이블 내의 데이터들은 정렬되어 있지 않으므로 특정 기준보다 크거나 작은 값을 빠른 시간 내에 찾을 수 없습니다.
📁 B+Tree
기존의 B-Tree는 어느 한 데이터의 검색은 효율적이지만, 모든 데이터를 한번 순회하는 데에는 트리의 모든 노드를 방문해야함으로 비효율 적입니다. 이러한 B-Tree 단점을 개선 시킨 자료구조가 B+Tree 입니다.
B+Tree 는 오직 leaf node(말단 노드) 에만 데이터를 저장하고 leaf node가 아닌 node 에서는 자식 포인터만 저장합니다.그리고 leaf node 끼리는 LinkedList로 연결되어 있습니다.
또, B+Tree 에서는 반드시 leaf node에만 데이터가 저장되기 때문에 중간 node 에서 key를 올바르게 찾아가기 위해서 key가 중복될 수 있습니다.
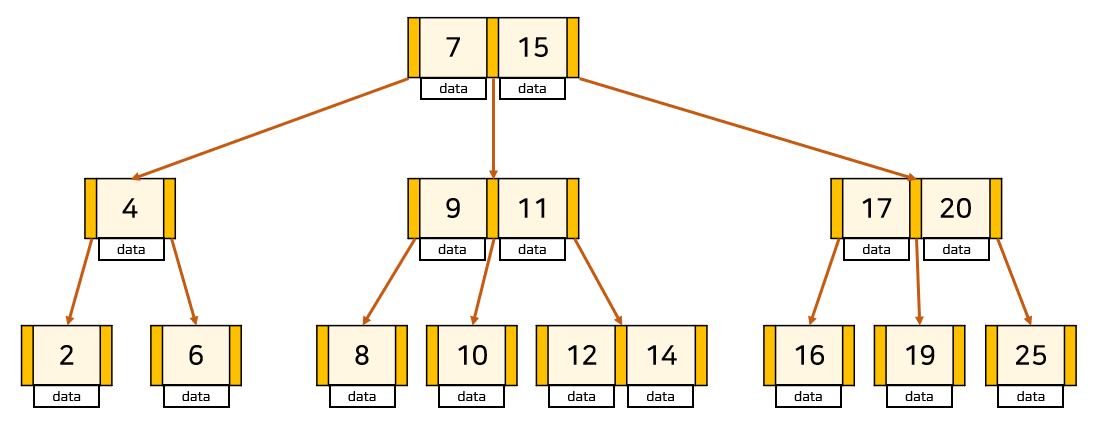
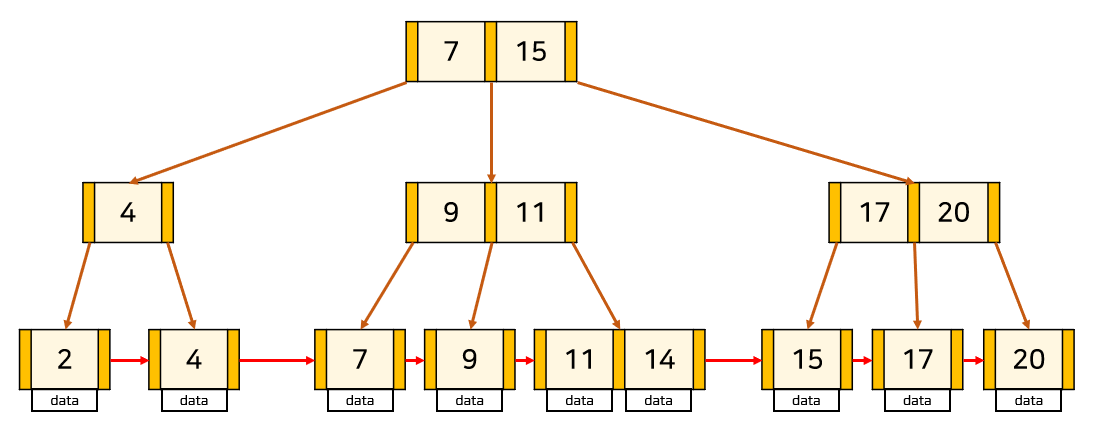
📁 B+Tree 장점
📌 leaf node를 제외하고 데이터를 저장하지 않기 때문에 메모리를 더 확보할 수 있습니다. 따라서 하나의 node 에 더 많은 포인터를 가질 수 있기 때문에 트리의 높이가 더 낮아지므로 검색 속도를 높일 수 있다.
📌 full scan 을 하는 경우 B+Tree는 leaf node 에만 데이터가 저장되어 있고, leaf node 끼리 LinkedList로 연결되어 있기때문에 선형 시간이 소모된다. 반면 B-Tree는 모든 node를 확인해야 한다.
📁 B+Tree 단점
📌 B-Tree는 가장 빠를 경우 root node에서 찾을 수 있지만, B+Tree 같은 경우 반드시 특정 key에 접근하기 위해서 leaf node 까지 가야합니다.
📁 B+Tree를 사용하는 이유
해시테이블에서 언급했듯이 인덱스 컬럼은 부등호를 이용한 순차 검색 연산이 자주 발생할 수 있습니다. 따라서 B+Tree의 LinkedList 를 이용하면 순차 검색의 효율적으로 할 수 있게 됩니다.
📁 삽입
📌 key 수가 최대보다 적은 leaf node에 삽입하는 경우
해당 node의 가장 앞이 아닌 곳에 삽입되는 경우 단순히 삽입을 해주면 됩니다. 하지만, leaf node 의 가장 앞에 삽입되는 경우, 해당 node를 가리키는 부모 node의 포인터의 오른쪽에 위치한 key를 K로 바꿔줍니다. 그리고 leaf node 끼리 LinkedList로 이어줘야 함으로 삽입된 key에 LinkedList로 연결합니다.
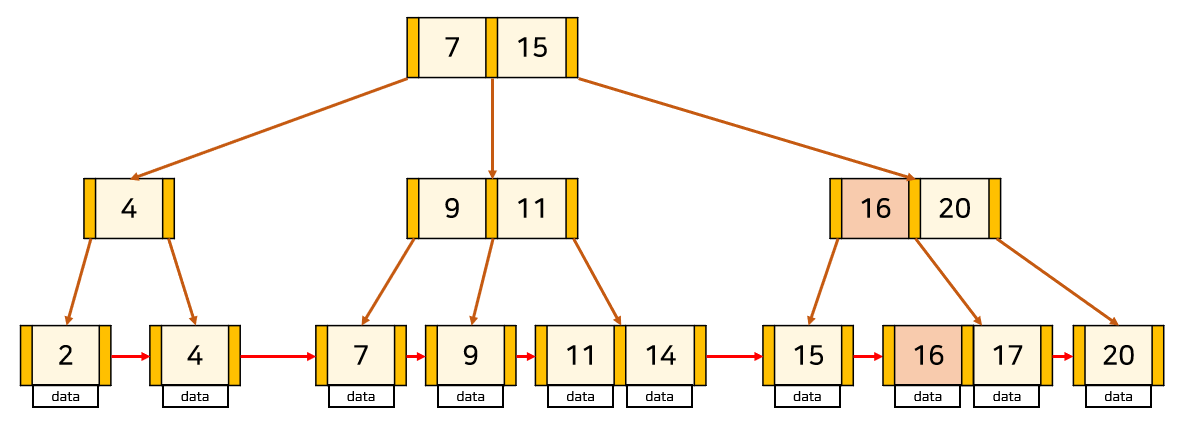
출처 : https://rebro.kr/169
📌 key의 수가 최대인 leaf node에 삽입하는 경우
key의 수가 최대이므로 삽입하는 경우 분할을 해주어야 합니다. 만약 중간 node에서 분할이 일어나는 경우 B-Tree와 동일하게 해주면 된다. leaf node에서 분할이 일어나는 경우 중간 key를 부모 node로 올려주는데, 오른쪽 node에 중간 key를 붙여 분할합니다. 그리고 분할된 두 node를 LinkedList로 연결해줍니다.
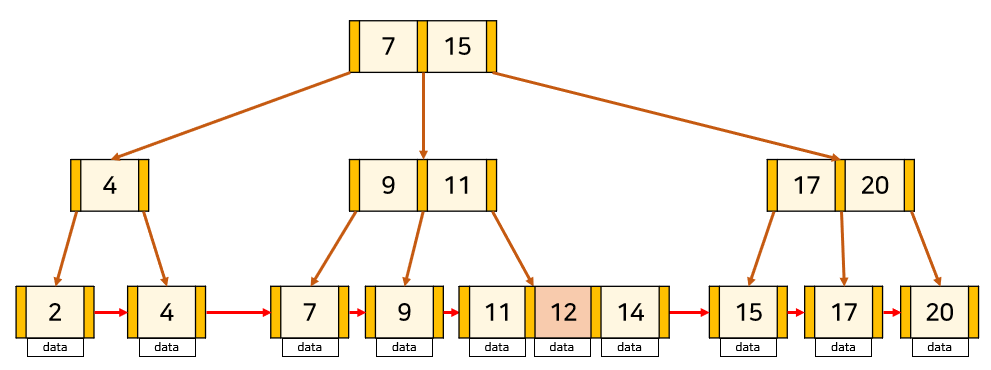
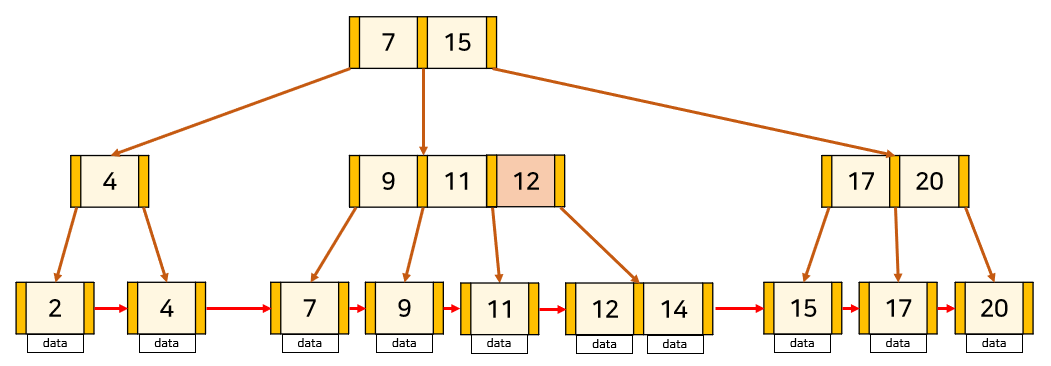
출처 : https://rebro.kr/169
📁 삭제
📌 삭제할 key가 leaf node의 가장 앞에 있지 않은 경우
B-Tree와 동일한 방법으로 삭제됩니다.
📌 삭제할 key가 leaf node의 가장 앞에 위치한 경우
이경우는 leaf node가 아닌 node에 key가 중복해서 존재합니다. 따라서 해당 key를 노드보다 오른쪽에 있으면서 가장 작은 값으로 바꿔주어야 합니다.
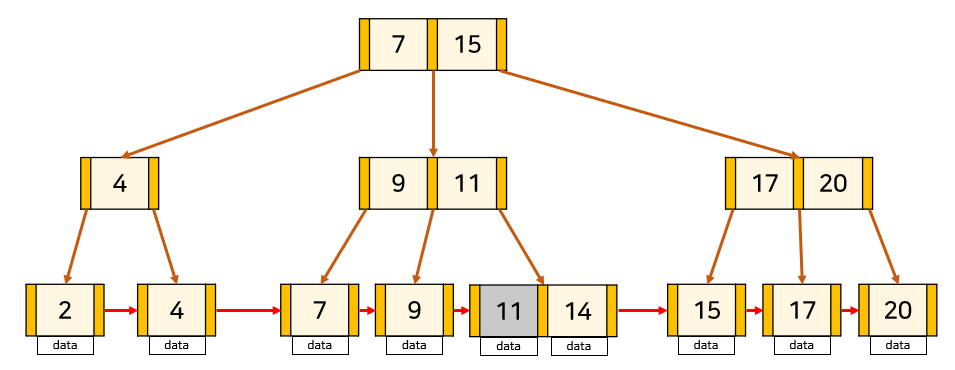
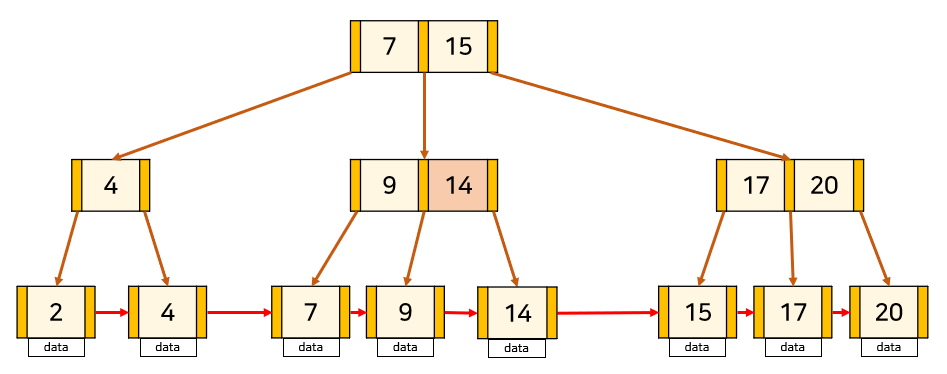
출처 : https://rebro.kr/169
💡 Reference
https://rebro.kr/167
https://junhyunny.github.io/information/database-index-and-considerations/
https://mangkyu.tistory.com/96
