한번에 끝내는 코딩테스트 369
1.[Fast Campus] 한 번에 끝내는 코딩테스트 369 : 자료구조와 알고리즘

용어 : 자료구조, 데이터 구조, data structure대량의 데이터를 효율적으로 관리할 수 있는 데이터의 구조를 의미코드상에서 효율적으로 데이터를 처리하기 위해 데이터의 특성에 따라 체계적으로 데이터를 구조화👉 어떤 데이터 구조를 사용하느냐에 따라 코드 효율이
2.[Fast Campus] 한 번에 끝내는 코딩테스트 369 : 배열
데이터를 나열하고, 각 데이터를 인덱스에 대응하도록 구성한 데이터 구조같은 종류의 데이터를 효율적으로 관리하기 위해 사용같은 종류의 데이터를 순차적으로 저장장점 - 빠른 접근 가능 : 첫 데이터의 위치에서 상대적인 위치로 데이터 접근( 인덱스 번호 )단점 - 데이터 추
3.[Fast Campus] 한 번에 끝내는 코딩테스트 369 : 큐
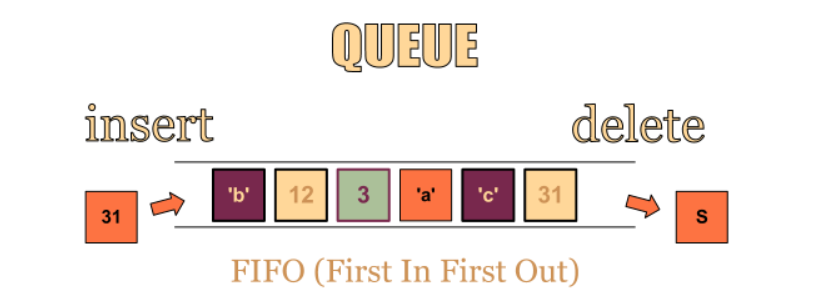
줄을 서는 행위와 유사가장 먼저 넣은 데이터를 가장 먼저 꺼낼 수 있는 구조 ( FIFO, LILO 방식 : 스택과 반대 )Enqueue : 큐에 데이터를 넣는 기능Dequeue : 큐에서 데이터를 꺼내는 기능JAVA 에서는 기본적으로 java.util 패키지에 Que
4.[Fast Campus] 한 번에 끝내는 코딩테스트 369 : 스택
데이터를 제한적으로 접근할 수 있는 구조한쪽 끝에서만 자료를 넣거나 뺄 수 있는 구조가장 나중에 쌓은 데이터를 가장 먼저 빼낼 수 있는 데이터 구조 ( LIFO )스택은 LIFO 또는 FILO 데이터 관리 방식을 따름대표적인 스택의 활용 : 컴퓨터 내부의 프로세스 구조
5.[Fast Campus] 한 번에 끝내는 코딩테스트 369 : 링크드 리스트

떨어진 곳에 존재하는 데이터를 화살표로 연결해서 관리하는 데이터 구조 (= 연결 리스트)배열은 순차적으로 연결된 공간에 데이터를 나열하는 데이터 구조노드(Node) : 데이터 저장 단위(데이터값, 포인터)로 구성포인터(Pointer) : 각 노드 안에서, 다음이나 이전
6.[Fast Campus] 한 번에 끝내는 코딩테스트 369 : 복잡도
하나의 문제를 푸는 알고리즘은 다양함👉 다양한 알고리즘 중 어느 알고리즘이 더 좋은지를 분석하기 위해, 복잡도를 정의하고 계산시간 복잡도 : 알고리즘 실행 속도👉 시간 복잡도의 주요 요소는 반복문 (입력의 크기가 커지면 커질수록 반복문이 알고리즘 수행 시간을 지배)
7.[Fast Campus] 한 번에 끝내는 코딩테스트 369 : 해쉬테이블
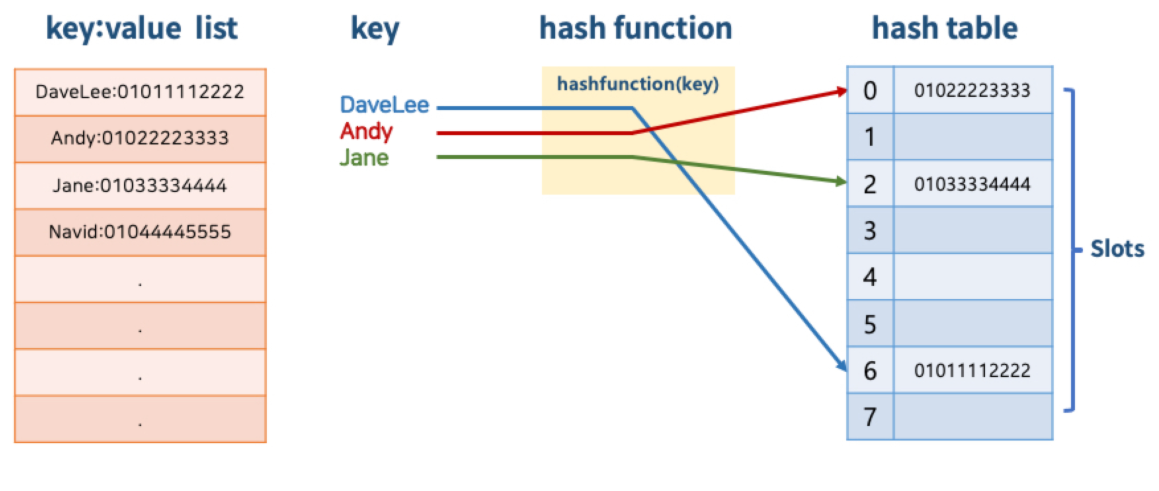
키(key)와 데이터(value)를 매핑할 수 있는 데이터 구조해쉬 함수를 통해 배열에 키에 대한 데이터를 저장할 수 있는 주소(인덱스 번호)를 계산key를 통해 바로 데이터가 저장되어 있는 주소를 알 수 있으므로 저장 및 탐색 속도가 획기적으로 빨라짐미리 해쉬 함수가