
Introduce: 비동기 로직을 적용은 해보았다만…
현재 맡고 있는 프로젝트는 음성 데이터를 실시간으로 처리하는 파이프라인을 가지고 있습니다.
처음에는 별 생각 없이 기존 서버들에 구성되어 있는 환경인 “Spring Boot 3.4.4 & Java 17” 환경에서 개발을 진행하고 있었습니다. 기능적으로 필요해서 만든 서버였기에 처음에는 버전과 환경, 최적화 등에 대한 생각을 크게 하고 있지 않았습니다.
그러다 추가적인 진행방향 기획 등을 듣고 나니 걱정들이 생겨납니다.
- 트래픽이 몰려도 성능적으로 괜찮나?
- 구조상 외부 네트워크 API를 많이 호출하게 된다. 지연시간이 너무 발생하지 않을까?
- 오류 상황이 최소화되어야 하는데 스레드 풀 관리를 제대로 할 수 있을까?
이러한 고민을 해결하기 위해 Virtual Thread를 어떻게 도입했는지 주니어 개발자의 “기술적 의사결정 과정”을 공유해볼까 합니다.
1. 프로젝트 배경 및 문제 정의

1.1. 서비스 로직: I/O Bound의 연속
제가 담당한 서비스는 다국어 컨퍼런스, 회의 등을 위한 파이프라인으로 다음과 같은 서비스 Flow를 가집니다.
STT(음성 인식) → Translation API → TTS(음성 합성) API → 결과 Redis Publish
각 단계는 Redis Publish를 제외하고는 전부 외부 API에 의존하게 되는, 전형적인 I/O Bound 작업입니다.
1.2. 기존 환경의 잠재적 한계(Java 17 & Platform Thread)
기존 Java 17환경에서는 OS 스레드와 1:1로 매핑되는 Platform Thread를 사용했었습니다.
- 외부 API 응답을 기다리는 동안 해당 스레드는 Blocking 상태가 됩니다.
- 동시 요청이 그 정도로 늘어날 상황은 많지 않다고 판단했지만, 만약 동시 요청이 급증하게 된다면 “Thread Pool이 고갈”되거나 스레드를 늘리면 메모리 사용량과 컨텍스트 스위칭 비용이 급증할 수 있습니다.
1.3. 채널별 스레드 할당 방식의 한계
제가 개발한 서비스는 회의(Conference)마다 여러 언어(Lang) 채널이 존재합니다.
데이터의 순차적 처리와 채널 간 격리를 위해, 기존에는 다음과 같이 Key(회의ID+언어코드)별로 단일 스레드(Single Thread Executor)를 생성하여 캐싱하는 전략을 사용했습니다.
// AS-IS: Java 17 (Platform Thread)
// 채널마다 무거운 OS 스레드가 하나씩 생성되어 대기함
public ExecutorService getExecutorForLangGroup(String conferenceId, String langCode) {
String key = conferenceId + ":" + langCode;
return langExecutors.computeIfAbsent(key, k ->
Executors.newSingleThreadExecutor(r -> {
Thread thread = new Thread(r);
thread.setDaemon(true); // 채널마다 OS 스레드 점유
return thread;
})
);
}이 방식은 로직은 단순하고 명확해 보일 수 있지만 단점이 명확했습니다.
- 확장성 한계: 동시 진행되는 회의가 100개이고 각 10개 언어를 지원한다면, 순식간에 1,000개의 OS 스레드가 생성됩니다.
- 리소스 낭비: 대화가 없는 조용한 방에서도 스레드가 점유된 상태로 대기(Idle)하여 메모리를 낭비합니다.
(물론 이부분은 임시로 방에 활성화된 언어 채널을 계속해서 감시하며 해결했지만, 이 또한 비용에 해당하긴 합니다.) - Context Switching: 활성 스레드가 많아지면 CPU가 스레드를 교체하는 비용이 작업 처리 비용보다 커집니다.
2. 해결책 모색: Java 21과 Virtual Thread

우선 첫 번째로 고민했던 것은 리액티브 프로그래밍(Webflux)이었습니다.
하지만 “기존 코드를 갈아엎어야 한다”라는 것과 “다른 API들은 어떻게 처리해야 하지?”의 두 가지 고민으로 인해 무산되었습니다.
그러다 떠오른 “Java 21에 Virtual Thread라는 것이 있다고 했었는데…”
이게 진짜 가볍고? 빠르고? 아무튼 좋다? 라고 했던 것 같아 냅다 알아봤습니다.
3. Virtual Thread란 무엇인가
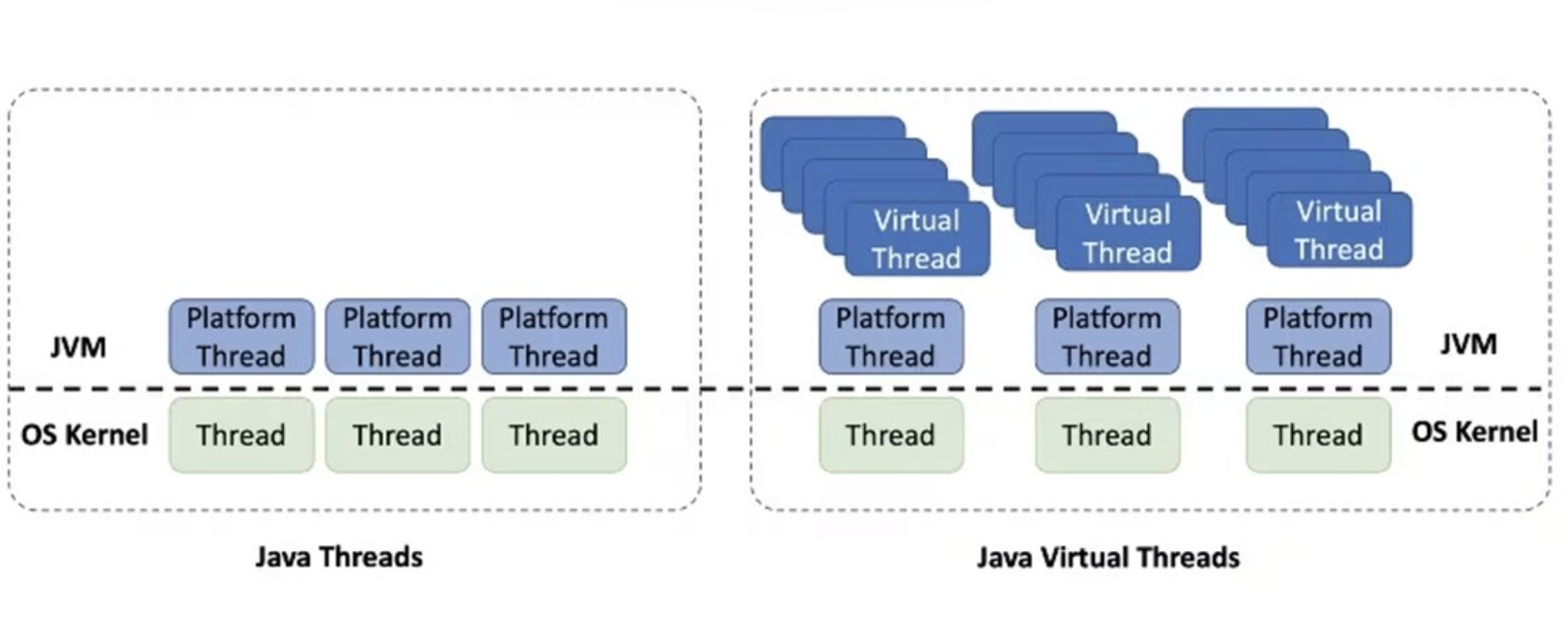
3.1. 간단 개념
기존의 Platform Thread가 OS 스레드 하나를 점유하는 무거운 객체라면, Virtual Thread는 JVM 내부에서 관리되는 경량 스레드입니다.
- Platfrom Thread: OS 스레드 = 1:1 매핑(비쌈, 개수 제한)
- Virtual Thread: OS 스레드(Carrier) = N:M 매핑(매우 저렴, 수백만 개 생성 가능)
Virtual Thread는 I/O Blocking이 발생하면, 실제 OS 스레드(Carrier Thread)를 점유하지 않고 다른 Virtual Thread에게 자리를 양보(Yield)합니다. 덕분에 적은 수의 OS 스레드로도 수많은 동시 요청을 처리할 수 있습니다.
가장 Virtual Thread의 장점이 극대화되는 케이스에 해당했기 때문에 도입하지 않을 이유가 없었습니다.
- Blocking I/O 를 그대로 사용해도 OS 스레드 점유 시간이 거의 없음
- API 응답 대기 중 OS 스레드를 반납하기 때문에 적은 리소스에서 많은 요청 병렬 처리 가능
Virtual Thread 참고자료: Oracle 공식 문서 - Virtual Threads
4. 도입 과정
4.1. Java 버전 업그레이드
먼저 Java 17 → Java 21로 변경할때 Springboot 3.4.4가 지원하는데, 다행이도 완벽하게 지원했습니다.
JDK 설치 및 build.gradle설정 변경만으로도 충분했습니다.
물론 이 과정 이후에 Springboot 버전도 검토하여 3.5.6 버전으로 버전업 하였습니다.(가장 큰 사유 LTS 버전이라)
4.2. Springboot 설정 적용
많은 기술블로그들에서 Spring Boot 3.2부터는 옵션 하나로 톰캣(Tomcat)과 TaskExecutor가 Virtual Thread를 사용하도록 설정할 수 있습니다.
# application.yml
spring:
threads:
virtual:
enabled: trueChat GPT한테 물어보니 설정 적용 안해도 가능하다고는 합니다.
4.3. 로직 변경
기존에 사용하던 getExecutorForLangGroup()을 수정해주었습니다. (1.3. 참고)
// TO-BE: Java 21 (Virtual Thread)
public ExecutorService getExecutorForLangGroup(String conferenceId, String langCode) {
String key = conferenceId + ":" + langCode;
return langExecutors.computeIfAbsent(key, k ->
// 더 이상 물리 스레드를 미리 만들지 않음.
// 작업이 들어올 때마다 가볍게 생성되는 Virtual Thread Executor 사용
Executors.newVirtualThreadPerTaskExecutor()
);
}5. 성능 측정 및 수치적 이점
5.1. 변경의 이론적 이점
| 항목 | 기존 (newSingleThreadExecutor) | 변경 후 (newVirtualThreadPerTaskExecutor) |
|---|---|---|
| I/O 작업 처리 | 단일 스레드에서 순차적 블로킹 | 병렬 처리 가능, I/O 대기 시 플랫폼 스레드 해제 (언마운트) |
| 처리량 (Throughput) | 매우 낮음 (하나의 느린 작업에 종속) | 매우 높음 (대부분의 시간을 I/O 대기 없이 활용) |
| 시스템 Latency | 높음 (큐 대기 시간 발생) | 낮음 |
| 리소스 효율 | 비효율적 (플랫폼 스레드 점유) | 매우 효율적 (가벼운 가상 스레드 사용) |
5.2. 변경의 수치적 이점
저는 간이로만 테스트를 진행하겠습니다.
회의 하나에서 언어 2개 채널을 오픈하고 각각 같은 길이의 문장을 처리 완료하는데 걸린 시간을 체크했습니다.
- As-Is(Platform Thread): 2.5s
- To-Be(Virtual Thread): 1.3s
약 48%의 속도 개선을 할 수 있었습니다.
부끄럽지만 부하 테스트를 제대로 해 본 적이 없어, 추후 공부하여 제대로 테스트 할 수 있도록 해보겠습니다.
6. 수치 이외의 잠재적 이점
수치적인 성능 향상도 향상이지만 잠재적으로 얻을 수 있던 이점은 개발 생산성이었습니다.
- 코드의 단순함:
WebFlux같은 복잡한 비동기 코드나 콜백 지옥 없이, 익숙한 동기 스타일(Imperative style)로 코드를 짜도 비동기처럼 동작합니다. - 디버깅 용이성: 스택 트레이스(Stack Trace)가 끊기지 않고 연결되어 있어, 에러 추적이 훨씬 수월합니다.
- 자원 효율성: 스레드 풀 사이즈를 고민하거나 튜닝하는 시간이 사라졌습니다.
7. 주니어 개발자로서의 의견
많은 분들이 저와 같을 것이라고 생각합니다.
- 기획대로 기능을 완성하기 위해 우선 설계부터 하는데, 어떻게 설계해야 확장성이 좋지?
- DB 테이블은 어떻게 설계하지? 컬럼만 추가할까? 매핑 테이블을 만들까?
- 병렬 처리를 위해 뭘 해야되는거지?
이런 고민들을 거쳐 “기능 완성”이라는 멋진 성과를 내놓습니다.
하지만 이번에 저는 “기능 완성”에서 그치지 않았습니다.
기능개발 이후 집중했던 내용은 “리소스 절약”과 “성능 향상” 이었습니다.
- 현재 방식이 어떤 한계점을 맞을 수 있는지 잠재적인 위협을 고려하고(단순
Platform Thread만을 사용하게 되는 상황 경계) - 어떤 기술을 “왜” 선택해야 하는지(Java 21의 명확한 도입 이유)
무엇이든 “다들 이렇게 하니까”라는 것은 경계하기로 했습니다. 어떤 기술 스택을 적용할 지에는 “근거”가 필요합니다. “왜”라는 것은 성장의 원동력이 되니까요.
저는 요즘 이틀에 최소 30분씩은 기존 로직을 검토합니다.
성능상 어떤 것을 개선할 수 있을지, 이 부분이 중복되는데 디자인패턴을 적용할 수 있을지, 아니면 진짜 사소하게 Util 클래스에서 DB데이터를 조회해야 하는데 Service로직을 거쳐서 가져올지, 아니면 바로 Mapper로 접근할지 등을 말이죠.
작은 습관이 미래에 더 나은 나를, 멋진 시니어로 성장하는 나를 만들 수 있을 것이라고 믿습니다.
Reference
