- Spark 프로그래밍: SQL
- Spark SQL 소개
SQL은 빅데이터 세상에서도 중요!
- 데이터 분야에서 일하고자 하면 반드시 익혀야할 기본 기술
- 개발자가 아니어도 SQL을 많이 사용한다.
- 구조화된 데이터를 다루는한 SQL은 데이터 규모와 상관없이 쓰임
- 모든 대용량 데이터 웨어하우스는 SQL 기반
- Redshift, Snowflake, BigQuery
- Hive/Presto
- Spark도 예외는 아님
- Spark SQL이 지원됨
Spark SQL이란?
- Spark SQL은 구조화된 데이터 처리를 위한 Spark 모듈
- 데이터 프레임 작업을 SQL로 처리 가능
- 데이터프레임에 테이블 이름 지정 후 sql함수 사용가능
- 판다스에도 pandasql 모듈의 sqldf 함수를 이용하는 동일한 패턴 존재
- HQL(Hive Query Language)과 호환 제공
- Hive 테이블들을 읽고 쓸 수 있음 (Hive Metastore)
- 데이터프레임에 테이블 이름 지정 후 sql함수 사용가능
Spark SQL vs. DataFrame
- 하지만 SQL로 가능한 작업이라면 DataFrame을 사용할 이유가 없음
- 두 개를 동시에 사용할 수 있다는 점 분명히 기억
- Familiarity/Readability
- SQL이 가독성이 더 좋고 더 많은 사람들이 사용가능
- Optimization
- Spark SQL 엔진이 최적화하기 더 좋음 (SQL은 Declarative)
- Catalyst Optimizer와 Project Tungsten
- Interoperability/Data Management
- SQL이 포팅도 쉽고 접근권한 체크도 쉬움
Spark SQL 사용법 - SQL 사용 방법
- 데이터 프레임을 기반으로 테이블 뷰 생성: 임시 테이블이 만들어짐
- createOrReplaceTempView: spark Session이 살아있는 동안 존재
- createOrReplaceGlobalTempView: Spark 드라이버가 살아있는 동안 존재
- Spark Session의 sql 함수로 SQL 결과를 데이터 프레임으로 받음
namegender_df.createOrReplaceTempView("namegender")
namegender_group_df = spark.sql("""
SELECT gender, count(1) FROM namegender GROUP BY 1
""")
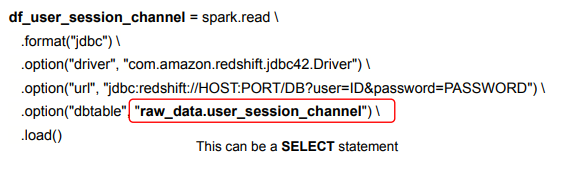
print(namegender_group_df.collect()SparkSession 사용 외부 데이터베이스 연결
- Spark Session의 read 함수를 호출(로그인 관련 정보와 읽어오고자 하는 테이블 혹은 SQL을 지정). 결과가 데이터 프레임으로 리턴됨
- Aggregation, JOIN, UDF
Aggregation 함수
- DataFrame이 아닌 SQL로 작성하는 것을 추천
- 뒤에서 실습시 예를 몇 가지 SQL로 살펴볼 예정
- Group By (SUM, MIN, MAX, AVG, COUNT)
- Window (ROW_NUMBER, FIRST_VALUE, LAST_VALUE)
- Rank
JOIN
- SQL 조인은 두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 머지
- 스타 스키마로 구성된 테이블들로 분산되어 있던 정보를 통합하는데 사용
- 왼쪽 테이블을 LEFT라고 하고 오른쪽 테이블을 RIGHT이라고 하면
- JOIN의 결과는 방식에 따라 양쪽의 필드를 모두 가진 새로운 테이블을 생성
- 조인의 방식에 따라 다음 두 가지가 달라짐
- 어떤 레코드들이 선택되는지?
- 어떤 필드들이 채워지는지?
6가지 종류의 조인
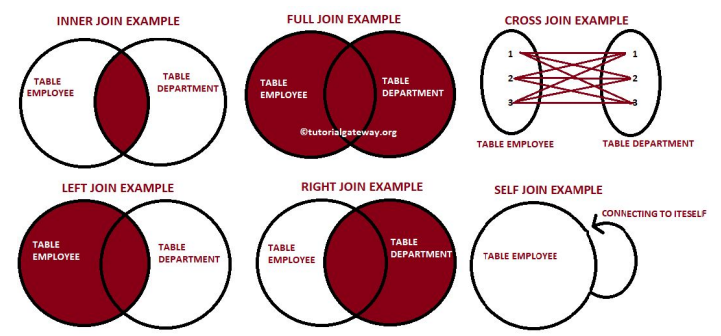
INNER JOIN - DEFAULT
- 양쪽 테이블에서 매치가 되는 레코드들만 리턴함
- 양쪽 테이블의 필드가 모두 채워진 상태로 리턴됨
SELECT * FROM Vital v
JOIN Alert a ON v.vitalID = a.vitalID;
LEFT JOIN
- 왼쪽 테이블(Base)의 모든 레코드들을 리턴함
- 오른쪽 테이블의 필드는 왼쪽 레코드와 매칭되는 경우에만 채워진 상태로 리턴됨
SELECT * FROM raw_data.Vital v
LEFT JOIN raw_data.Alert a ON v.vitalID = a.vitalID;
FULL JOIN
- 왼쪽 테이블과 오른쪽 테이블의 모든 레코드들을 리턴함
- 매칭되는 경우에만 양쪽 테이블들의 모든 필드들이 채워진 상태로 리턴됨
SELECT * FROM raw_data.Vital v
FULL JOIN raw_data.Alert a ON v.vitalID = a.vitalID;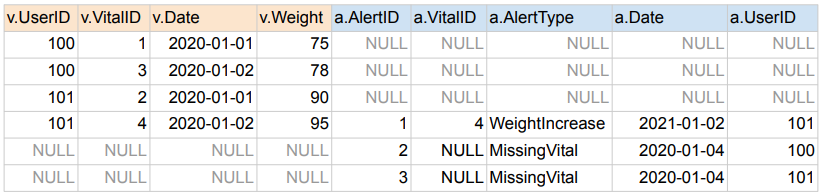
CROSS JOIN
- 왼쪽 테이블과 오른쪽 테이블의 모든 레코드들의 조합을 리턴함
SELECT * FROM raw_data.Vital v CROSS JOIN raw_data.Alert a;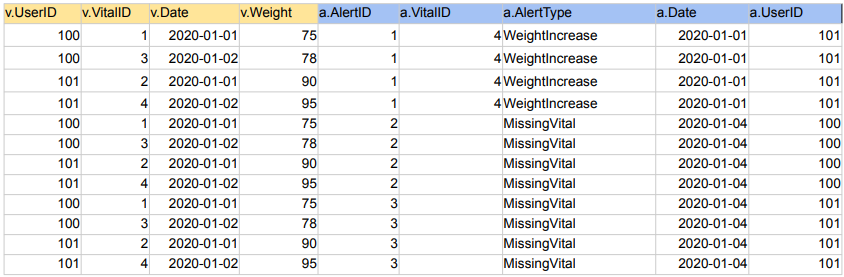
SELF JOIN
- 동일한 테이블을 alias를 달리해서 자기 자신과 조인함
SELECT * FROM raw_data.Vital v1
JOIN raw_data.Vital v2 ON v1.vitalID = v2.vitalID;
최적화 관점에서 본 조인의 종류들
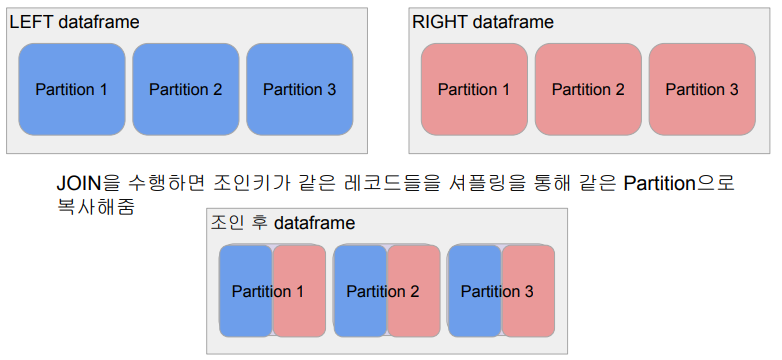
- Shuffle JOIN
- 일반 조인 방식
- Bucket JOIN: 조인 키를 바탕으로 새로 파티션을 새로 만들고 조인을 하는 방식
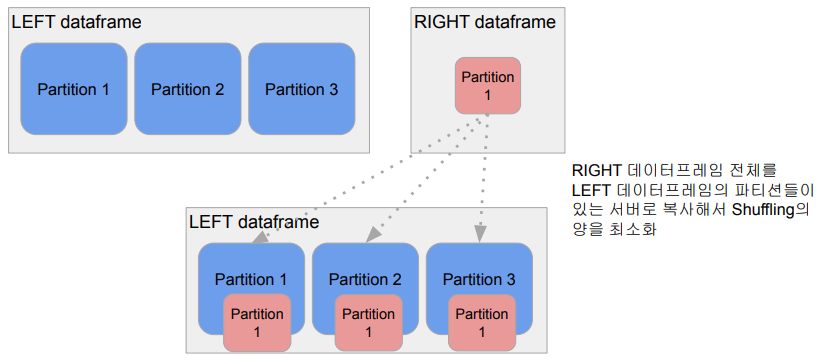
- Broadcast JOIN
- 큰 데이터와 작은 데이터 간의 조인
- 데이터 프레임 하나가 충분히 작으면 작은 데이터 프레임을 다른 데이터 프레임이 있는 서버들로 뿌리는 것 (broadcasting)
- spark.sql.autoBroadcastJoinThreshold 파라미터로 충분히 작은지 여부 결정
UDF
- User Defined Function
- DataFrame이나 SQL에서 적용할 수 있는 사용자 정의 함수
- SQL에서는 UDF 선언 방식이 조금 다름
- Scalar 함수 vs. Aggregation 함수
- Scalar 함수 예: UPPER, LOWER, …
- Aggregation 함수 (UDAF) 예: SUM, MIN, MAX
UDF 사용해보기
- 데이터프레임의 경우 .withColumn 함수와 같이 사용하는 것이 일반적
- Spark SQL에서도 사용 가능
- Aggregation용 UDAF(User Defined Aggregation Function)도 존재
- GROUP BY에서 사용되는 SUM, AVG와 같은 함수를 만드는 것
- PySpark에서 지원되지 않음. Scalar/Java를 사용해야함
UDF 사용 방법
- 함수 구현
- 파이썬 람다 함수
- 파이썬 (보통) 함수
- 파이썬 판다스 함수:
- pyspark.sql.functions.pandas_udf로 annotation
- Apache Arrow를 사용해서 파이썬 객체를 자바 객체로 변환이 훨씬 더 효율적
- 함수 등록
- pyspark.sql.functions.udf
- DataFrame에서만 사용 가능
- spark.udf.register
- SQL 모두에서 사용 가능
- pyspark.sql.functions.udf
- 함수 사용
- .withColumn, .agg
- SQL
- 성능이 중요하다면 Scala나 Java로 구현하는 것이 제일 좋음 파이썬을 사용해야 한다면 Pandas UDF로 구현
UDF - DataFrame에 사용
import pyspark.sql.functions as F
from pyspark.sql.types import *
upperUDF = F.udf(lambda z:z.upper())
df.withColumn("Curated Name", upperUDF("Name"))data = [
{"a": 1, "b": 2},
{"a": 5, "b": 5}
]
df = spark.createDataFrame(data)
df.withColumn("c", F.udf(lambda x, y: x + y)("a", "b"))- SQL에 사용
def upper(s):
return s.upper()
# 먼저 테스트
upperUDF = spark.udf.register("upper", upper)
spark.sql("SELECT upper('aBcD')").show() # return ABCD
# DataFrame 기반 SQL에 적용
df.createOrReplaceTempView("test")
spark.sql("""SELECT name, upper(name) "Curated Name" FROM test""").show()def plus(x, y):
return x + y
plusUDF = spark.udf.register("plus", plus)
spark.sql("SELECT plus(1, 2)").show()
df.createOrReplaceTempView("test")
spark.sql("SELECT a, b, plus(a, b) c FROM test").show()UDF - Pandas UDF Scalar 함수 사용
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf(StringType())
def upper_udf2(s: pd.Series) -> pd.Series:
return s.str.upper()
upperUDF = spark.udf.register("upper_udf", upper_udf2)
df.select("Name", upperUDF("Name")).show()
spark.sql("""SELECT name, upper_udf(name) `Curated Name` FROM test""").show()UDF - DataFrame/SQL에 Aggregation 사용
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf(FloatType())
def average(v: pd.Series) -> float:
return v.mean()
averageUDF = spark.udf.register('average', average)
spark.sql('SELECT average(b) FROM test').show()
df.agg(averageUDF("b").alias("count")).show()- SQL로 만드는 것이 더 깔끔하고 효율적임
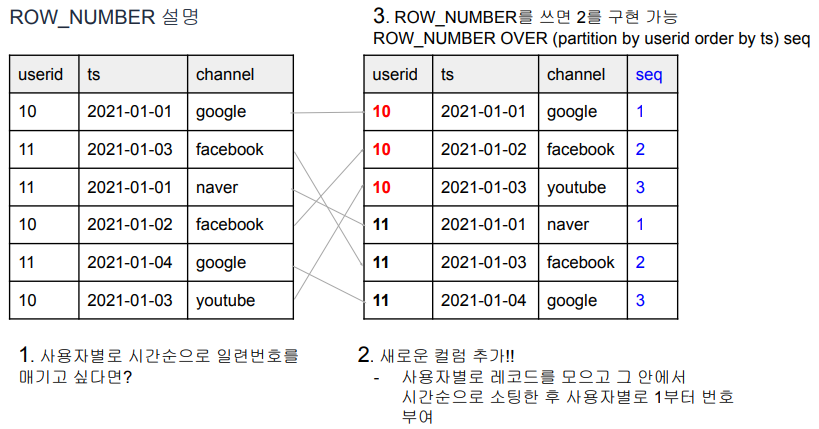
Window 함수: ROWS BETWEEN AND 이해
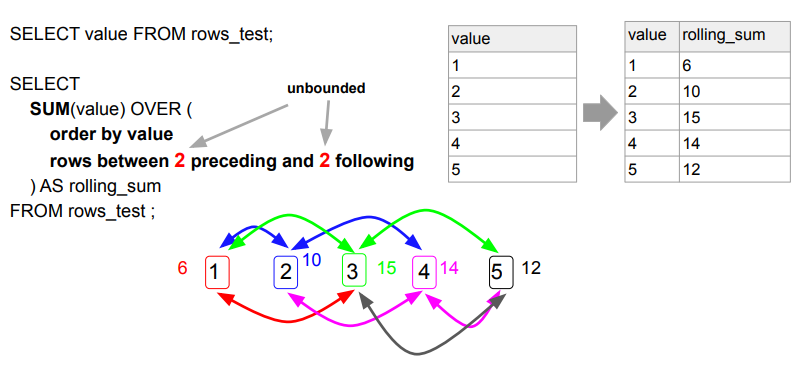
- 기존 레코드에 새로운 컬럼을 붙이는 형태임.
- unbounded는 이전 혹은 이후에 있는 모든 값들에 다 해당되는 값들.
Hive 메타 스토어 사용
Spark 데이터베이스와 테이블
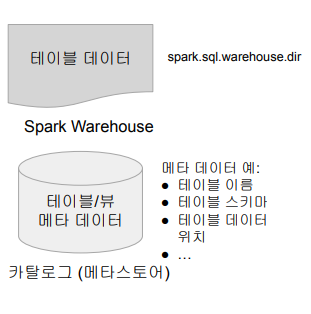
- 카탈로그: 테이블과 뷰에 관한 메타 데이터 관리
- 기본으로 메모리 기반 카탈로그 제공 - 세션이 끝나면 사라짐
- Hive와 호환되는 카탈로그 제공 - Persistent
- 테이블 관리 방식
- 테이블들은 데이터베이스라 부르는 폴더와 같은 구조로 관리 (2단계)
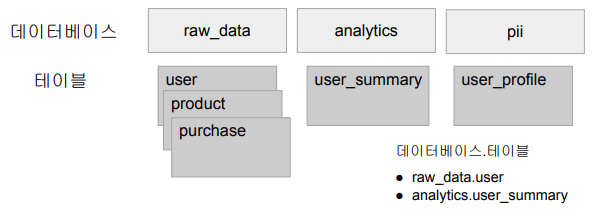
- 메모리 기반 테이블/뷰:
- 임시 테이블로 앞서 사용해봤음
- 스토리지 기반 테이블
- 기본적으로 HDFS와 Parquet 포맷을 사용
- Hive와 호환되는 메타스토어 사용
- 두 종류의 테이블이 존재 (Hive와 동일한 개념)
- Managed Table
- Spark이 실제 데이터와 메타 데이터 모두 관리
- Unmanaged (External) Table
- Spark이 메타 데이터만 관리
- Managed Table
Spark SQL - 스토리지 기반 카탈로그 사용 방법
- Hive와 호환되는 메타스토어 사용
- SparkSession 생성시 enableHiveSupport() 호출
- 기본으로 “default”라는 이름의 데이터베이스 생성
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark Hive") \
.enableHiveSupport() \
.getOrCreate()Spark SQL - Managed Table 사용 방법
- 두 가지 테이블 생성방법
- dataframe.saveAsTable("테이블이름")
- SQL 문법 사용 (CREATE TABLE, CTAS)
- spark.sql.warehouse.dir가 가리키는 위치에 데이터가 저장됨
- PARQUET이 기본 데이터 포맷
- External Table보다 선호하는 테이블 타입
- Spark 테이블로 처리하는 것의 장점 (파일로 저장하는 것과 비교시)
- JDBC/ODBC등으로 Spark을 연결해서 접근 가능 (태블로, 파워BI)
Spark SQL - External(Unmanaged) Table 사용 방법
- 이미 HDFS에 존재하는 데이터에 스키마를 정의해서 사용
- LOCATION이란 프로퍼티 사용
- 메타데이터만 카탈로그에 기록됨
- 데이터는 이미 존재.
- External Table은 삭제되어도 데이터는 그대로임
CREATE TABLE table_name (
column1 type1,
column2 type2,
column3 type3,
…
)
USING PARQUET
LOCATION 'hdfs_path';유닛 테스트
유닛 테스트
- 코드 상의 특정 기능 (보통 메소드의 형태)을 테스트하기 위해 작성된 코드
- 보통 정해진 입력을 주고 예상된 출력이 나오는지 형태로 테스트
- CI/CD를 사용하려면 전체 코드의 테스트 커버러지가 굉장히 중요해짐
- 각 언어별로 정해진 테스트 프레임웍을 사용하는 것이 일반적
- JUnit for Java
- NUnit for .NET
- unittest for Python
- unittest를 사용해볼 예정

초짜에요...