- 클라우드 기반 Spark 클러스터
- AWS Spark 클러스터 론치
AWS에서 Spark을 실행하려면
- EMR (Elastic MapReduce) 위에서 실행하는 것이 일반적
- EMR이란?
- AWS의 Hadoop 서비스 (On-demand Hadoop)
- Hadoop (YARN), Spark, Hive, Notebook 등등이 설치되어 제공되는 서비스
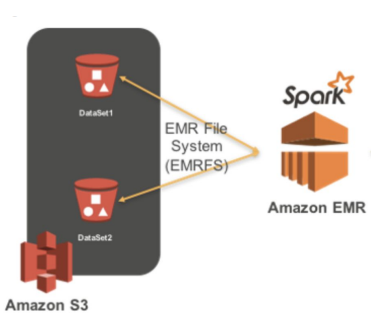
- EC2 서버들을 worker node로 사용하고 S3를 HDFS로 사용
- AWS 내의 다른 서비스들과 연동이 쉬움 (Kinesis, DynamoDB, Redshift, …)
- AWS의 Hadoop 서비스 (On-demand Hadoop)
Spark on EMR 실행 및 사용 과정
- AWS의 EMR (Elastic MapReduce - 하둡) 클러스터 생성
- EMR 생성시 Spark을 실행 (옵션으로 선택)
- S3를 기본 파일 시스템(HDFS)으로 사용
- EMR의 마스터 노드를 드라이버 노드로 사용
- 마스터 노드를 SSH로 로그인
- spark-submit를 사용
- Spark의 Cluster 모드에 해당
- 마스터 노드를 SSH로 로그인
Spark 클러스터 매니저와 실행 모델 요약

Zeppelin이란?
- https://zeppelin.apache.org/: Spark 전용 노트북 (Spark, SQL, Python, R)

- AWS Spark 클러스터 상에서 PySpark 잡 실행
PySpark 잡 실행 과정
- Spark 마스터노드에 SSH로 로그인
- 이를 위해 마스터노드의 TCP 포트번호 22번을 오픈해야함
- spark-submit을 이용해서 실행하면서 디버깅
- 두 개의 잡을 AWS EMR 상에서 실행해 볼 예정
입력 데이터를 S3로 로딩
- Stackoverflow 2022년 개발자 서베이 CSV 파일을 S3 버킷으로 업로드
- 익명화된 83,339개의 서베이 응답
- s3://spark-tutorial-dataset/survey_results_public.csv
PySpark 잡 코드 설명
- 입력 CSV 파일을 분석하여 그 결과를 S3에 다시 저장 (stackoverflow.py)
- 미국 개발자만 대상으로 코딩을 처음 어떻게 배웠는지 카운트해서 S3로 저장
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
S3_DATA_INPUT_PATH = 's3://spark-tutorial-dataset/survey_results_public.csv'
S3_DATA_OUTPUT_PATH = 's3://spark-tutorial-dataset/data-output'
spark = SparkSession.builder.appName('Tutorial').getOrCreate()
df = spark.read.csv(S3_DATA_INPUT_PATH, header=True)
print('# of records {}'.format(df.count()))
learnCodeUS = df.where((col('Country') == 'United States of America')).groupby('LearnCode').count()
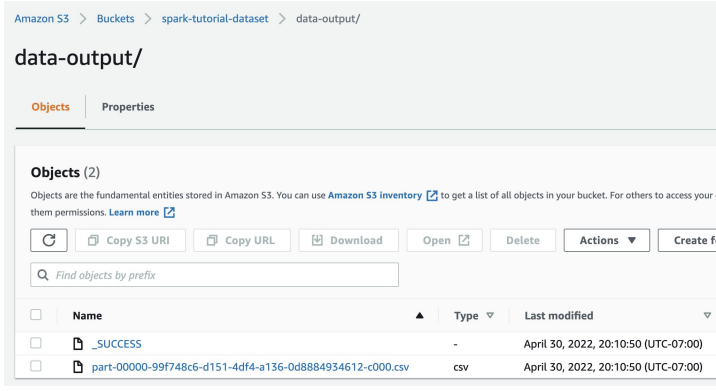
learnCodeUS.write.mode('overwrite').csv(S3_DATA_OUTPUT_PATH) # parquet
learnCodeUS.show()
print('Selected data is successfully saved to S3: {}'.format(S3_DATA_OUTPUT_PATH))PySpark 잡 실행
- Spark 마스터노드에 ssh로 로그인하여 spark-submit을 통해 실행
- 앞서 다운로드받은 .pem 파일을 사용하여 SSH 로그인
- spark-submit --master yarn stackoverflow.py
$ ssh -i 앞서다운로드받은프라이빗키.pem hadoop@마스터노드호스트이름
Last login: Sun May 1 02:04:15 2022
__| __|_ )
_| ( / Amazon Linux 2 AMI
___|\___|___|
….
[hadoop@ip-172-31-95-199]$ spark-submit --master yarn stackoverflow.py
22/05/01 02:13:52 INFO SparkContext: Running Spark version 2.4.8-amzn-1
22/05/01 02:13:52 INFO SparkContext: Submitted application: Tutorial
…
22/05/01 02:14:28 INFO ShutdownHookManager: Deleting directory /mnt/tmp/spark-8aec657d-196f-4e9b-8b6e-498f87d4bab9PySpark 잡 실행 결과를 S3에서 확인하기
Spark 클러스터 요약
- AWS에서 Spark은 EMR의 일부로 동작
- EMR상의 Spark 잡은 YARN 클러스터 모드로 실행
이번 강의 요약
- Spark는 2세대 빅데이터 처리 기술
- 자체 분산 파일 시스템을 갖고 있지 않음
- DataFrame, SQL, ML, Streaming, Graph와 같은 다양한 기능 지원
- 빅데이터 처리 종합 선물세트
- 구조화된 데이터 처리라면 DataFrame을 쓸 필요 없이 SQL을 사용
- 주로 기능적인 부분에 대해 학습
- Spark 고급 강의에서는 최적화에 관계된 부분의 심화 학습 예정
Spark의 다른 용도(ETL 다음)
- ML Feature 계산
- 이는 큰 스케일에서는 Feature 계산을 위한 용도
- DataFrame과 SQL 사용. UDF를 많이 사용하게 됨
- Model Serving
- MLflow와 연관
- 기타 분석 관련 파이프라인 작성
- 마케팅 기여도 분석
- A/B Test 분석(데이터 분석가와 협업)
다음 스텝
- SQL 심화 학습
- DBT 배우기
- Spark 최적화 관련 학습
- Executor와 Driver의 메모리 사용
- Spill이란 무엇이며 어떻게 막을 수 있나?
- Data Skew를 막거나 줄이기 위한 방법들

초짜에요...