동기? 비동기?
글을 시작하기에 앞서, 동기와 비동기가 무엇인지 간단하게 설명해 보자면 다음과 같다.
작업을 수행하는 두 주체
A,B가 있다고 가정하자.동기 (sync)
A가 작업을 끝내는 시간에 맞춰B가 작업을 시작한다.
다른 말로 하면,B는A가 수행한 작업의 결과(리턴 값)에 관심이 있다고도 할 수 있다.비동기 (async)
A가 작업을 끝내든 말든 상관 없이,B가 자신의 작업을 시작한다.
B는A가 수행한 작업의 결과에 관심이 없다고 표현할 수도 있다.
요는, 비동기 방식에서는 두 주체가 서로의 작업 시작 및 종료 시간에 영향을 받지 않고, 별도의 작업 시작/종료 시간을 가진다는 것이다. A가 작업을 하던 중이었으면, B가 작업을 시작하든 말든, A는 자신의 작업을 끝마친다.
그런데, 서로 다른 두 주체가 동시에 작업한다는 것은 (일단 글을 쓰는 지금 시점의 내 지식으로는) 싱글 스레드에서는 상상하기 힘들다. 그러므로, 모든 비동기 방식은 멀티 스레드에서 작동한다는 조건 하에 글을 작성하겠다.
비동기 처리?
위에서 예시로 들었던 A와 B를 가져와서 이야기하자면, 비동기 방식은 A와 B 서로가 끝났든 안 끝났든 상관 없이 자신의 일을 하므로, A의 작업 결과를 B에서 요구하는 경우에는 곤란해질 수 있다. 예를 하나 들어 보자면, (다음은 자바스크립트 코드이다)
function a(ref) {
while (ref.value < 10) {
ref.value = ref.value + 1;
}
}
function b(ref) {
return ref.value == 10;
}
function _true() {
ref = {value: 0};
a(ref);
return b(ref);
}위 코드는 동기 방식으로 작동하는 함수의 코드로, _true() 에서 a()를 호출한 뒤 b()를 호출한다. a()는 값이 10이 될 때까지 더하는 함수이고, b()는 값이 10이면 true를 반환하는 함수이므로 _true()의 리턴값은 당연히 true가 된다.
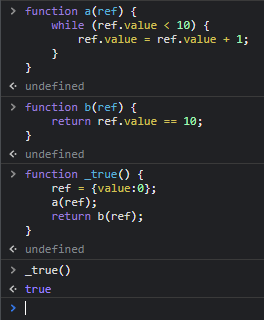
하지만 각 함수들이 비동기로 동작한다면 어떨까? a()를 부르면 값이 10이 될 때까지 더하는 스레드를 실행하고, b()를 부르면 값이 10인지 판단하는 스레드를 실행한다면? 이렇게 된다면 작업의 순서를 보장할 수 없게 된다. _true()가 반드시 true를 반환한다고 말할 수 없게 된다는 것이다. 이런 상황에서 _true()가 반드시 true를 반환하게 하려면 어떻게 할까?
바로 이럴 때 사용하는 게 비동기 처리이다. 콜백 함수를 사용하여 코드의 흐름을 제한하거나, 비동기로 작동하는 코드 사이에 동기 함수를 끼워넣어서 코드의 흐름을 조정하는 등의 기법을 이용해 비동기 처리를 구현한다.
비동기 처리 그거 자바스크립트에서 하는 거 아닌가요?
비동기 프로그래밍이라는 키워드로 구글링해 보면, 가장 많이 뜨는 것이 '자바스크립트에서 비동기 처리를 어떻게 하는가' 이다. 왜 자바스크립트와 관련된 비동기 처리만 이렇게 많이 뜨는 걸까?
자바스크립트는 특성상 웹 페이지의 코드를 작성하거나 웹 서버를 작성할 때 사용되는데, 이런 환경에서 제공되는 API는 속도를 최우선으로 하기 위해 비동기 함수로 작성되었기 때문이다. 이 함수들을 일반적인 함수를 사용하는 것처럼 그냥 사용한다면 실행 순서가 보장되지 않는다. 그래서 비동기 처리를 해서 사용해야 한다. 다음과 같이...
api에서_가져온_작업(function callback1() {
그_다음에_처리해야_하는_작업(function callback2() {
그리고_그_다음에_처리해야_할_작업(function callback3() {
...
})
})
});
그_동안_하는_또다른_작업();API에서 가져온 함수를 이용한 (오래 걸리는) 작업은 비동기로 실행된다. 덕분에 작업을 다른 주체에게 맡겨 두고, 작업이 끝날 때까지 기다리는 대신 밑에 있는 또다른 작업을 곧바로 시작해 시간을 아낄 수 있다. API 함수를 이용한 작업을 마쳤을 때 다음 작업이 있다면 callback을 이용해서 이번 작업의 다음 작업이 시작되게 만들기 위해 코드의 흐름을 조절한다.
자바스크립트에서는 위처럼 callback을 이용해서 비동기 처리를 한다고 치자. 그럼, Java에서는 어떤 식으로 비동기 처리를 할까?
Java에서의 비동기 처리
Javascript에서 callback뿐만이 아니라 Promise, async/await 등의 다양한 방법으로 비동기 처리를 구현할 수 있듯, Java에서도 비동기 처리를 할 수 있는 다양한 방법이 있다. 하지만 비동기 처리를 공부하기 전에, Java에서 비동기로 작동하는 코드를 작성하는 법을 먼저 알아보려고 한다. 다음 코드를 보자.
Thread를 이용한 비동기 코드 작성
Thread를 사용하지 않는 코드
public class ThreadExample {
public static void main(String[] args) {
// 작업 1 - 1.5초 소요
System.out.println("작업1 시작");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("작업1 종료");
// 작업 2 - 0.5초 소요
System.out.println("작업2 시작");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("작업2 종료");
}
}실행 결과
작업1 시작
작업1 종료
작업2 시작
작업2 종료작업1은 오래 걸리는 작업이고, 작업2는 오래 걸리지 않는 작업이다. 두 작업 사이에 연관성도 없는데 작업1이 끝날 때까지 오랫동안 기다리고 작업2를 시작하는 것은 비효율적이다. 이런 경우에 스레드를 나누어 오래 걸리는 작업을 다른 주체에게 맡겨 다른 작업과 동시에 실행되게 만들면 시간을 아낄 수 있다.
작업1을 스레드로 변경한 코드
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadExample {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
// 작업1 (스레드)
executorService.submit(() -> {
log("작업 1 시작");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 1 종료");
});
// 작업2
log("작업 2 시작");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 2 종료");
executorService.shutdown();
}
// 출력을 어떤 스레드에서 하고 있는지 확인
private static void log(String content) {
System.out.println(Thread.currentThread().getName() + "> " + content);
}
}실행 결과
main> 작업 2 시작
pool-1-thread-1> 작업 1 시작
main> 작업 2 종료
pool-1-thread-1> 작업 1 종료이 경우에는 실행 시간이 긴 작업1을 다른 스레드에게 맡기고, 메인 스레드는 그대로 밑으로 내려가 작업2를 시작한다. 실행 결과를 보면, main과 pool-1-thread-1의 두 주체(스레드)가 서로 다른 작업을 동시에 진행하는 것을 알 수 있다.
Java에서 비동기 코드를 작성하는 법을 살펴봤으니, 이제 비동기 처리를 어떻게 하는지 하나씩 차근차근 살펴보자. 크게 Future 객체를 사용하는 방식과 Callback을 구현하는 방식이 있다. Future 객체는 다른 주체에게 작업을 맡긴 상태에서 본 주체 쪽에서 작업이 끝났는지 직접 확인하는 방법이고, Callback은 이름에서도 알 수 있듯 다른 주체에게 맡긴 작업이 끝나면 다른 주체 쪽에서 본 주체가 전해 준 콜백 함수를 실행하는 방법이다. 먼저, 위에서 자바스크립트로 예시를 들었던 방법과 유사한, Callback을 구현하는 방식부터 알아보자.
Callback
콜백을 구현하는 방법은 여러 가지가 있다. CompletionHandler를 사용할 수도 있고, 함수형 인터페이스를 이용해서 구현할 수도 있으며, 이 밖에도 많은 방법이 있다. 먼저 CompletionHandler를 사용한 경우를 살펴보자.
CompletionHandler
import java.nio.channels.CompletionHandler;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CallbackExample1 {
private static ExecutorService executorService;
// CompletionHandler를 구현한다.
private static final CompletionHandler<String, Void> completionHandler = new CompletionHandler<>() {
// 작업 1이 성공적으로 종료된 경우 불리는 콜백 (작업 2)
@Override
public void completed(String result, Void attachment) {
log("작업 2 시작 (작업 1의 결과: " + result + ")");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 2 종료");
}
// 작업 1이 실패했을 경우 불리는 콜백
@Override
public void failed(Throwable exc, Void attachment) {
log("작업 1 실패: " + exc.toString());
}
};
public static void main(String[] args) {
executorService = Executors.newCachedThreadPool();
// 작업 1
executorService.submit(() -> {
log("작업 1 시작");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 1 종료");
String result = "Alice";
if (result.equals("Alice")) { // 작업 성공
completionHandler.completed(result, null);
} else { // 작업 실패
completionHandler.failed(new IllegalStateException(), null);
}
});
// 별개로 돌아가는 작업 3
log("작업 3 시작");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 3 종료");
}
private static void log(String content) {
System.out.println(Thread.currentThread().getName() + "> " + content);
}
}실행 결과
main> 작업 3 시작
pool-1-thread-1> 작업 1 시작
pool-1-thread-1> 작업 1 종료
pool-1-thread-1> 작업 2 시작 (작업 1의 결과: Alice)
main> 작업 3 종료
pool-1-thread-1> 작업 2 종료CompletionHandler는 비동기 I/O 작업의 결과를 처리하기 위한 목적으로 만들어졌으며, 콜백 객체를 만드는 데 사용된다. completed() 메소드를 오버라이드해서 콜백을 구현하고, failed() 메소드를 오버라이드해 작업이 실패했을 때의 처리를 구현하면 된다. try-catch나 if문을 이용해 작업이 성공했는지 판단한 뒤 작업이 성공했으면 콜백 객체의 completed()를 호출하고, 실패했거나 예외가 발생했으면 failed()를 호출하는 식으로 사용하면 된다. 또, 위 코드의 실행 결과에서 스레드 pool-1-thread-1 쪽에서 콜백을 호출해, 콜백도 계속해서 main 스레드와 별개로 비동기적으로 실행하는 것을 볼 수 있다.
다음으로 함수형 인터페이스를 이용해서 콜백을 구현한 예제를 살펴보자.
함수형 인터페이스
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.function.Consumer;
public class CallbackExample2 {
private static ExecutorService executorService;
public static void main(String[] args) {
executorService = Executors.newCachedThreadPool();
// execute 함수의 인자로 callback의 구현체를 넣는다.
execute(parameter -> {
log("작업 2 시작 (작업 1의 결과: " + parameter + ")");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 2 종료");
});
// 별개로 돌아가는 작업 3
log("작업 3 시작");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 3 종료");
}
public static void execute(Consumer<String> callback) {
executorService.submit(() -> {
log("작업 1 시작");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String result = "Alice";
log("작업 1 종료");
// 작업을 마친 후 인자로 받아온 callback의 구현체를 비동기로 실행한다.
callback.accept(result);
});
}
private static void log(String content) {
System.out.println(Thread.currentThread().getName() + "> " + content);
}
}실행 결과
main> 작업 3 시작
pool-1-thread-1> 작업 1 시작
pool-1-thread-1> 작업 1 종료
pool-1-thread-1> 작업 2 시작 (작업 1의 결과: Alice)
main> 작업 3 종료
pool-1-thread-1> 작업 2 종료작업1을 마친 뒤 callback으로 받아온 함수형 인터페이스를 실행하는 메소드를 호출하면 된다. 유의할 점은, execute()의 인자로 execute()의 작업이 모두 끝난 뒤 실행될 콜백을 작성해 넣어야 한다는 점이다. 이 경우는 execute()의 작업인 작업 1을 마친 뒤 실행될 작업 2의 내용을 작성했다. 콜백의 타입은 인자를 받아서 사용하기 위해 Consumer를 사용했다.
함수형 인터페이스
- Runnable
인자와 리턴값이 모두 없다.- Supplier<R>, Callable<R>
인자는 없고, R 타입의 객체를 리턴한다.- Consumer<T>
T 타입의 인자를 받고, 아무것도 리턴하지 않는다.- Function<T, R>
T 타입의 인자를 받고, R 타입의 객체를 리턴한다.@FunctionalInterface를 통해 커스텀 함수형 인터페이스를 만들 수도 있다.
또한, 실행 결과에서도 볼 수 있듯, CompletionHandler와 마찬가지로 함수형 인터페이스를 이용한 콜백도 호출한 쪽인 pool-1-thread-1 스레드에서 main 스레드와 별개로 비동기적으로 작동한다.
또, 예제에서는 등장하지 않았지만 콜백을 구현하는 데 있어 유의해야 할 점이 있다. 다른 스레드와 공유하는 변수 등에 접근할 경우 race condition이 발생할 수 있으므로, 반드시 synchronized 블록 등의 기법을 통해 자원을 동기화해서 사용해야 한다. 이것에 관한 내용은 추후 다른 포스팅에서 자세히 알아볼 예정이다.
Future
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class FutureExample {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
// 작업1 Callable이 리턴한 값을 future에 담는다.
Future<String> future = executorService.submit(() -> {
log("작업 1 시작");
Thread.sleep(1000);
log("작업 1 종료");
return "Alice";
});
log("작업 2 시작 (작업 1 종료 대기)");
String result = "";
try {
// 논블로킹으로 작업 1이 종료되었는지 확인한다.
log("작업 1 종료 여부: " + future.isDone());
// 블로킹 상태에서 작업 1이 끝날 때까지 대기한다.
result = future.get();
// 논블로킹으로 작업 1이 종료되었는지 확인한다.
log("작업 1 종료 여부: " + future.isDone());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
log("작업 1의 결과: " + result);
log("작업 2 종료");
}
private static void log(String content) {
System.out.println(Thread.currentThread().getName() + "> " + content);
}
}실행 결과
main> 작업 2 시작 (작업 1 종료 대기)
pool-1-thread-1> 작업 1 시작
main> 작업 1 종료 여부: false
pool-1-thread-1> 작업 1 종료
main> 작업 1 종료 여부: true
main> 작업 1의 결과: Alice
main> 작업 2 종료위에서 설명했듯 Future 객체를 사용한 비동기 처리 방식은 다른 주체에게 작업을 맡긴 상태에서 본 주체 쪽에서 작업이 끝났는지 물어보면서 직접 확인하는 방식이다. 확인하는 방법으로는 두 가지가 있다. 하나는 isDone()이나 isCanceled() 메소드로 블로킹 없이 작업을 완료했는지의 여부만 확인하는 방법이고, 다른 하나는 get()으로 작업이 완료될 때까지 블로킹된 상태로 대기하는 방법이다. 오래 걸리는 작업을 다른 주체에게 맡겨 두고 get()을 호출하기 전까지 이 쪽에서 할 일을 하다가, 작업을 마치면 get()을 호출해 작업의 결과를 받아오는 식으로 사용한다. get() 메소드를 통해 Future 객체에 담긴(담길) 작업 결과를 얻을 수 있다.
참고:
Future에 작업을 등록할 때, 등록되는 작업이Runnable인지Callable인지 잘 확인해야 한다.Runnable은 아무것도 리턴하지 않기 때문에get()을 호출했을 때 null이 나올 수 있다.
또, 다음과 같이 Future의 구현체인 FutureTask를 이용해서 구현하는 것도 가능하다.
FutureTask
// FutureTask를 생성한다. 비동기로 수행할 작업을 짜 넣는다.
FutureTask<String> futureTask = new FutureTask<>(() -> {
System.out.println(Thread.currentThread().getName() + "> 작업 1 시작");
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + "> 작업 1 종료");
return "Alice";
});
// FutureTask를 수행하는 스레드를 시작한다.
executorService.submit(futureTask);
// 작업 결과는 Future와 같은 방식으로 얻어온다.
futureTask.get();futureTask는 Runnable과 Future를 합친 RunnableFuture를 상속한 클래스의 객체인데, 둘을 모두 상속한 덕분에 Runnable과 Future의 역할을 객체 하나로 한 번에 수행할 수 있다. Future와 FutureTask 중 어느 쪽을 사용할지는 상황을 보고 정하면 되겠다.
CompletableFuture
Future는 결국 다른 주체의 작업 결과를 얻어오려면 잠시라도 블로킹 상태에 들어갈 수밖에 없기 때문에 사용하는 데 한계가 있다. 그래서 등장한 게 CompletableFuture 이다. 이번에도 먼저 예시를 보자.
import java.util.concurrent.*;
public class FutureExample {
public static void main(String[] args) {
new Thread(() -> {
try {
CompletableFuture
.supplyAsync(FutureExample::work1)
.thenAccept(FutureExample::work2)
.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}).start();
work3();
}
private static String work1() {
log("작업 1 시작");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 1 종료");
return "Alice";
}
private static void work2(String result) {
log("작업 1의 결과: " + result);
log("작업 2 시작");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 2 종료");
}
private static void work3() {
log("작업 3 시작");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
log("작업 3 종료");
}
private static void log(String content) {
System.out.println(Thread.currentThread().getName() + "> " + content);
}
}실행 결과
main> 작업 3 시작
ForkJoinPool.commonPool-worker-1> 작업 1 시작
ForkJoinPool.commonPool-worker-1> 작업 1 종료
ForkJoinPool.commonPool-worker-1> 작업 1의 결과: Alice
ForkJoinPool.commonPool-worker-1> 작업 2 시작
main> 작업 3 종료
ForkJoinPool.commonPool-worker-1> 작업 2 종료일관성이 없긴 하지만, 이번 코드에서는 각 작업들을 익명 함수로 작성하는 대신 함수로 따로 빼서 작성했다. 코드를 보면, 스레드를 생성한 뒤 그 안에서 작업 1을 supplyAsync()를 통해 호출하고, 작업 2를 작업 1이 끝난 직후에 블로킹 없이 시작할 수 있도록 thenAccept()를 통해 호출하고 있다. 그 밑에서는 main 스레드에서 작업 3을 불러 시작하는 것도 볼 수 있다. 이렇게 CompletableFuture를 사용하면 이전 작업의 결과를 get()을 통해 블로킹으로 가져올 필요 없이, then...() 함수를 통해 논블로킹을 유지하며 바로 사용할 수 있다.
사족이지만, 코드에서 작업 1, 2를 굳이 스레드로 감싸서 작성한 이유가 있다. supplyAsync()를 실행시키기 위해서 get()을 호출했는데, 이 get()은 블로킹 함수여서 작업 3과 동시에 작동시킬 수 없었기 때문이다.

좋은 글 잘봤습니다!!