1. GPT 개론
- ChatGpt란?
- 일론 머스크가 공동 창업한 OpenAI에서 서비스하는 인공지능 챗봇 서비스
- Natural Language Processing (자연어 처리) 모델 중 하나인 GPT를 채팅 형식으로 Fine Tuning (미세 조정) 한 AI
- 현재 기준으로 GPT-3.5와 GPT-4 버전을 사용한다.
- 사용자가 입력한 Prompt를 바탕으로 최적의 답변을 생성하다.
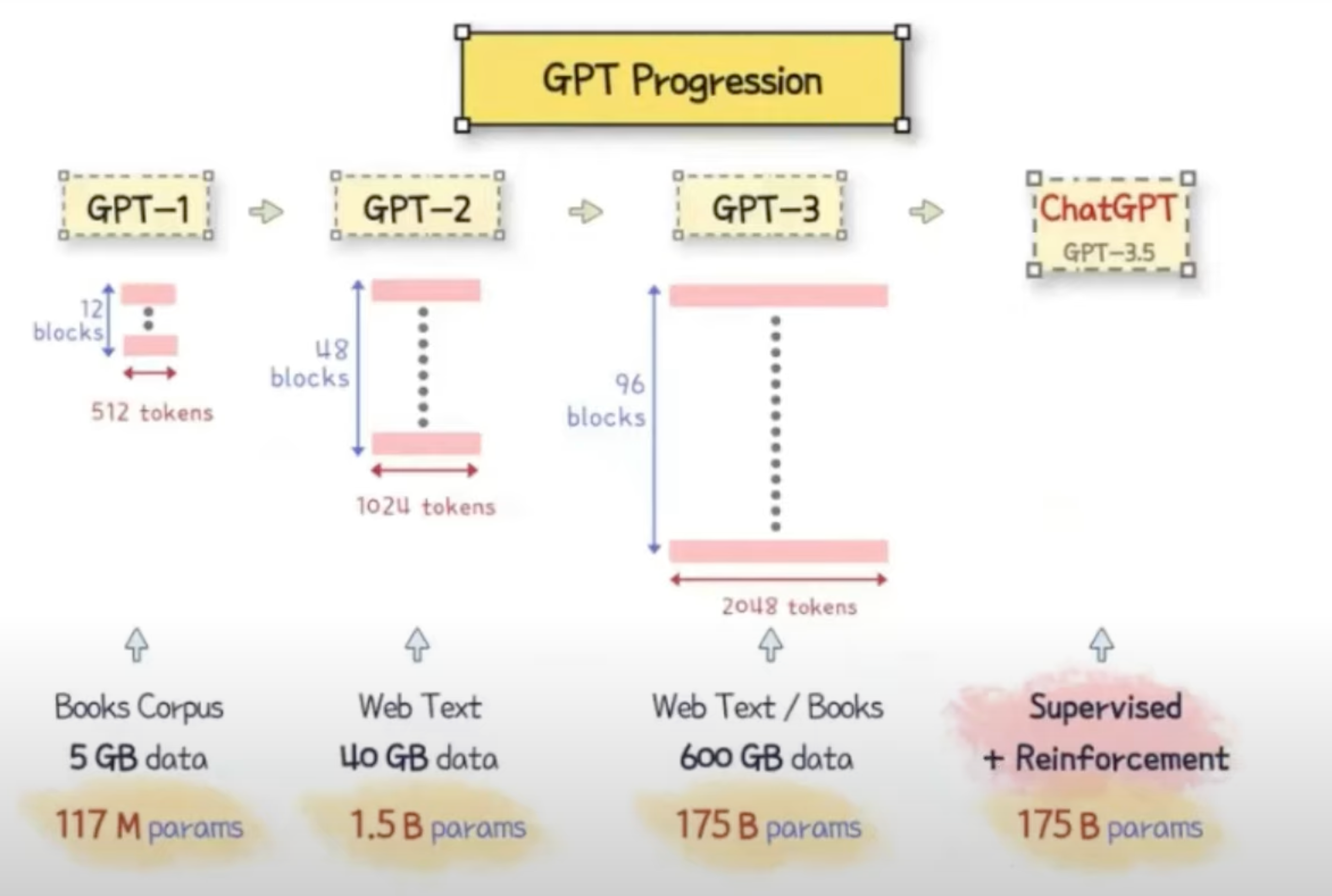
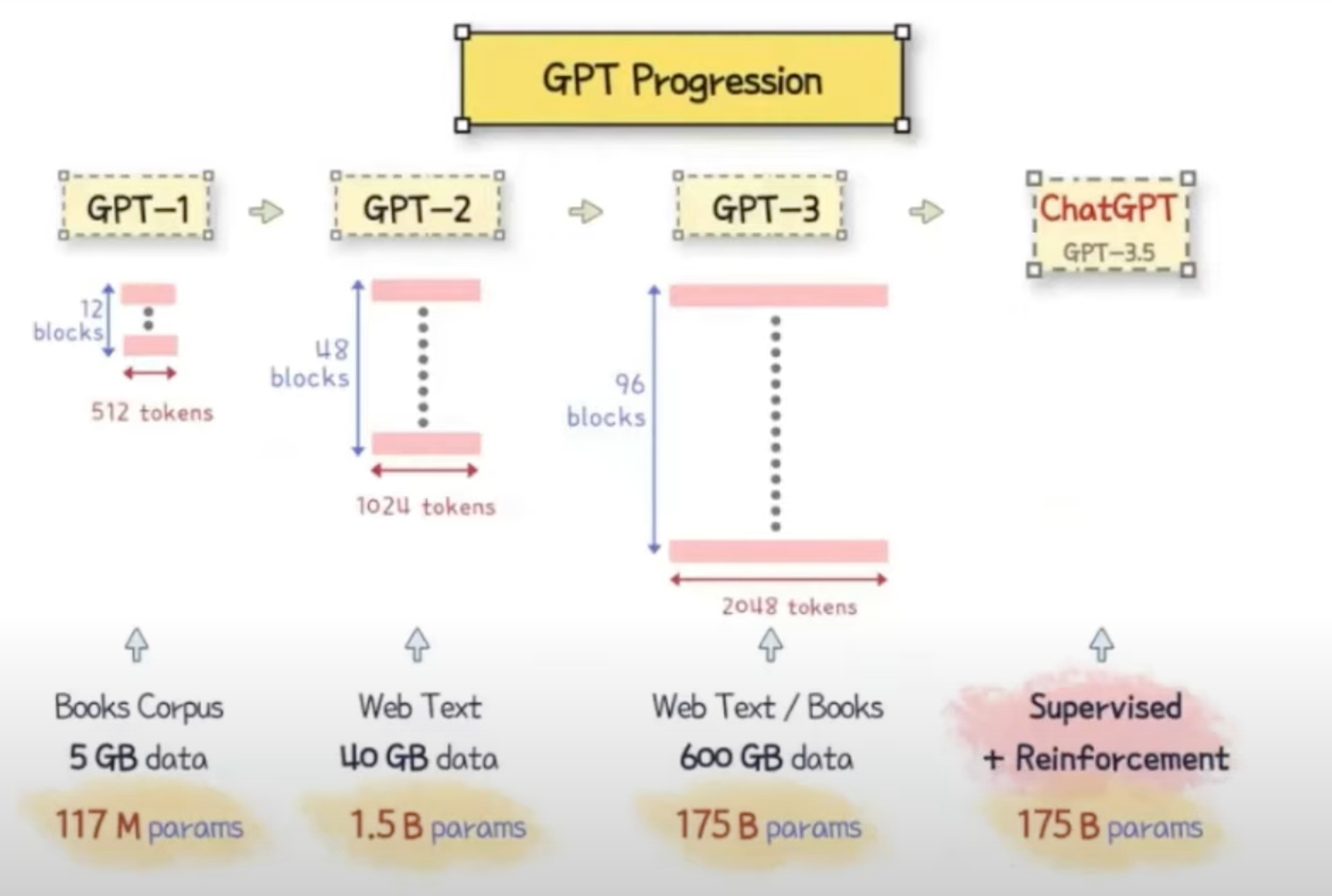
- GPT-3.5는 1,750억 개의 파라미터를 가지며 RLHF(Rainforcement Learning from Human Feedback)를 통해 GPT-3를 대화에 최적화
2. GPT 동작 원리 및 학습 메커니즘
Natural Language Processing ( 자연어 처리 )
Step_1 ( Natural Language UnderStanding ) : 사용자가 자연어를 입력합니다.
Step_2 ( Machine Learning ) : 사용자가 입력한 자연어를 분석합니다.
Step_3 ( Natural Language Generating ) : 자연어를 생성합니다.
-
자연어 생성 메커니즘
-
Auto Encoding (Ex : Bert) : 중간 빈칸 채우기 방식의 NLG

-
Auto Regressive (Ex : GPT-2 , 카카오톡 문장 자동 완성 ) : 순차 빈칸 채우기 방식의 NLG

-
-
Generative Pre-trained Transformer ( GPT ) : 사전 훈련된 생성 변환기
-
GPT-2 : 입력된 문장의 다음 문장을 예측하여 대답해주는 단순 Auto Regressive
질문 : 오늘이 무슨 날이야?
답변 : 오늘이 무슨 날이야? 라고 PLO가 질문했다. -
GPT-3 : Pre-training → Fine Tuning의 과정을 거친 Auto Regressive
1. Pre-traning ( 사전 학습 )
사전 학습 모델이란 기존에 자비어(Xavier) 등 임의의 값으로 초기화하던 모델의 가중치들을
다른 문제(task)에 학습시킨 가중치들로 초기화하는 방법이다.
예를 들어, 텍스트 유사도 예측 모델을 만들기 전 감정 분석 문제를 학습한 모델의 가중치를 활용해 텍스트 유사도 모델의 가중치로 활용하는 방법이다.
즉, 감정 분석 문제를 학습하면서 얻은 언어에 대한 이해를 학습한 후 그 정보를 유사도 문제를 학습하는 데 활용하는 방식이다.
이때 사전 학습한 가중치를 활용해 학습하고자 하는 본 문제를 하위 문제(downstream task)라 한다.
앞서 든 예시에서는 사전 학습한 모델인 감정 분석 문제가 사전 학습 문제(pre-train task)가 되고,
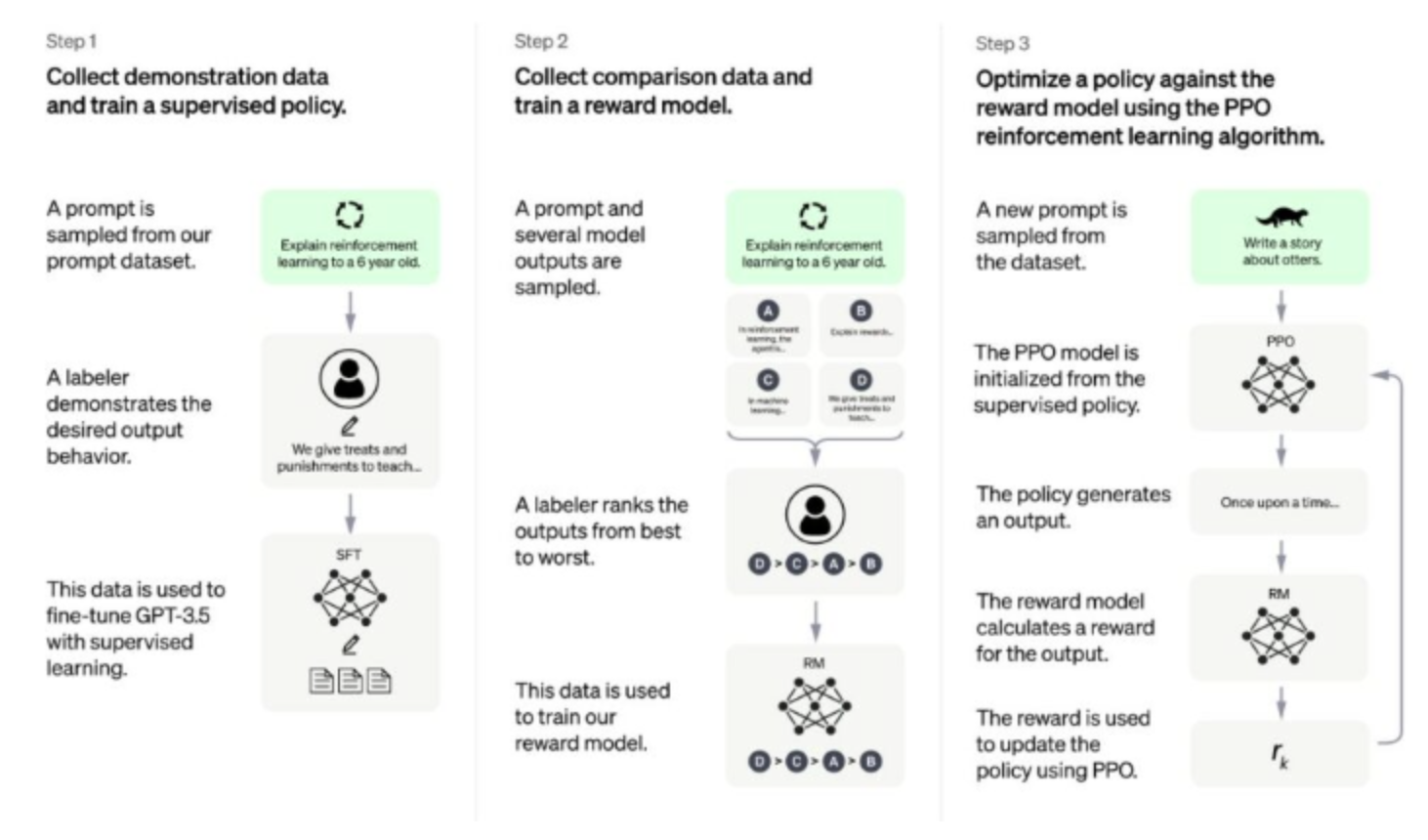
사전 학습된 가중치를 활용해 본격적으로 학습하고자 하는 문제인 텍스트 유사도 문제가 하위 문제가 된다.2. Fine Tuning ( Reinforcement Learning from Human Feedback ) | downstream task를 위한 추가 학습 단계
2-1 : Additional tranning to become better at a certain task + Supervised Fine-Tuning
2-1-1 : 수만 개의 데이터 셋을 추가 학습 )
2-1-2 : 질문 - 답변 형식의 데이터 셋을 지도 학습2-2 : Supervised learning ( Reward Model )
2-2-1 : 인간이 판단한 Revealed preference ( 현시 선호 )를 따라 판단하도록 지도 학습
ex )
질문 : [ 4,3,2,1 ] 을 숫자가 큰 순서대로 정렬해줘
답변 : [ 3,2,4,1 ] → Gpt가 질문에 대해 학습한 데이터 셋을 바탕으로 n개의 답변을 도출
학습 : [ 1,2,3,4 ] → 사람이 n개의 답변에 대해 정확도를 기준으로 순위를 측정하여 Gpt에게 재학습
답변 : [ 1,2,3,4 ] → ( Reward Model || Supervised learning )2-3 : Proximal Policy Optimization ( Reinforcement Learning )
2-3-1 : Model-Free based learning의 한 강화학습 위에서 도출된 Supervised learning을 결합하는 과정이다.
2-3-2 : RM이 가장 높은 Supervised learning을 채택할 수 있도록 반복 학습한다.
ex)
[ 1 ] 3개의 도박 기계가 있으며 가장 돈을 많이 벌 수 있도록 해 주는 모델을 알 수 없다.
[ 2 ] 번갈아가면서 동전을 넣어본다. ( Supervised learning을 하나씩 테스트 )
[ 3 ] 효과가 가장 좋아보이는 기계에 점점 더 많은 돈을 넣는다. ( Bandit )
[ 4 ] PPO도 보상, 혹은 인간의 긍정적인 반응이 더 많은 답안을 내도록 모델이 변형된다.
-
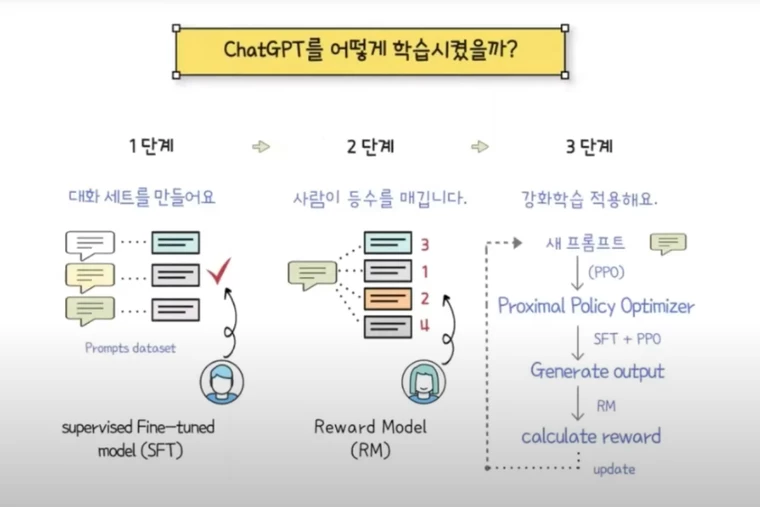
3. Fine Tuning 기법 상세
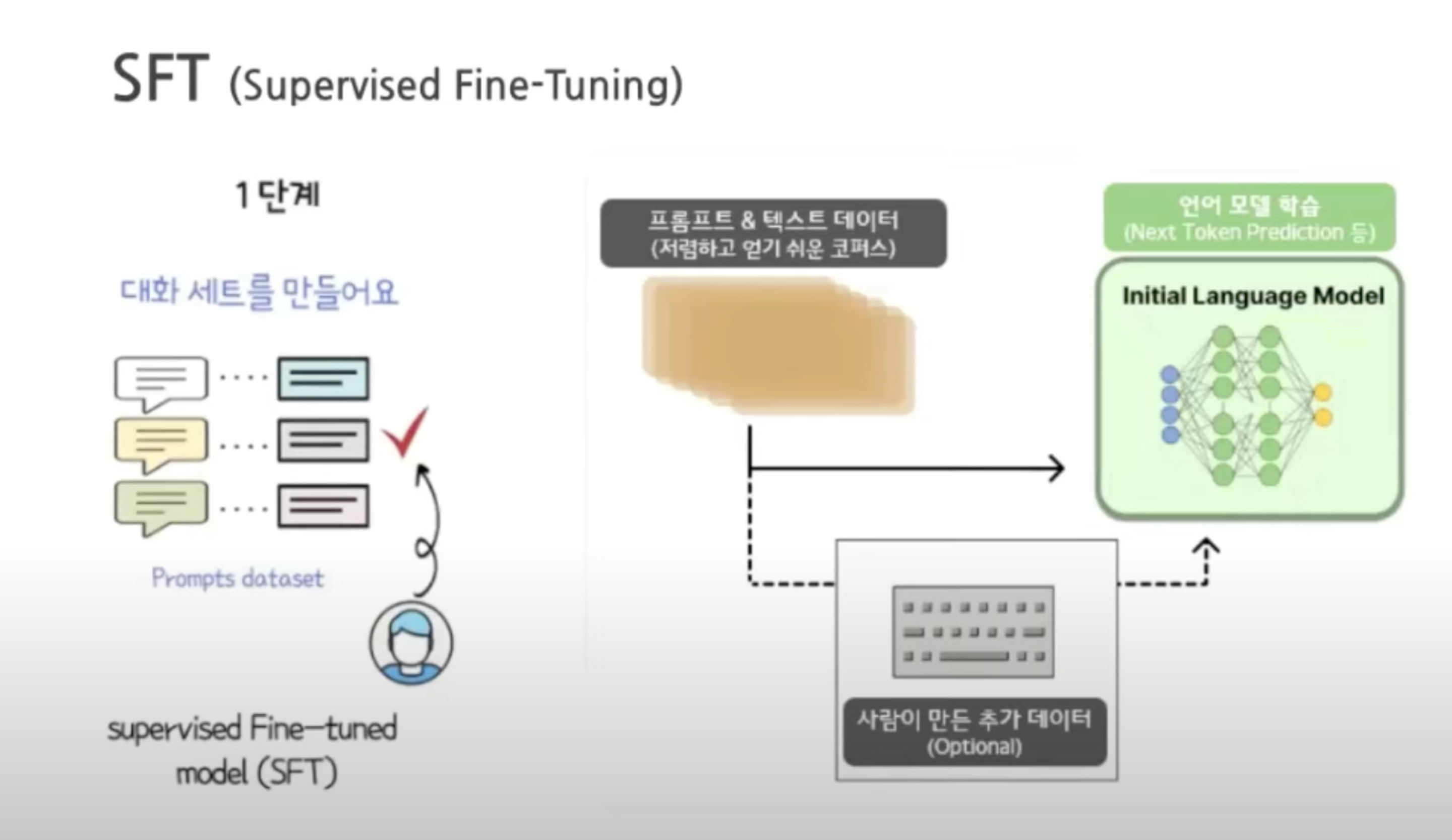
1. Supervised Fine-Tuning
-
데이터 수집 : 프롬프트 목록을 정하고 , 라벨러 그룹에게 예상 답변을 요청.
일부는 회사에서 직접 작성 후 클라우드 소싱을 통해서 샘플링 ,
사전 학습된 언어 모델을 미세조정 하는데 사용되는 비교적 적은 고품질 큐레이션 세트
( 약 12~15만 개의 데이터로 추정된다. ) -
모델 선택 : GPT-3.5 모델 선택. 사용된 기준 모델은 프로그래밍 코드로부터 파인 튜닝된
text-davinci-003인 것으로 추정
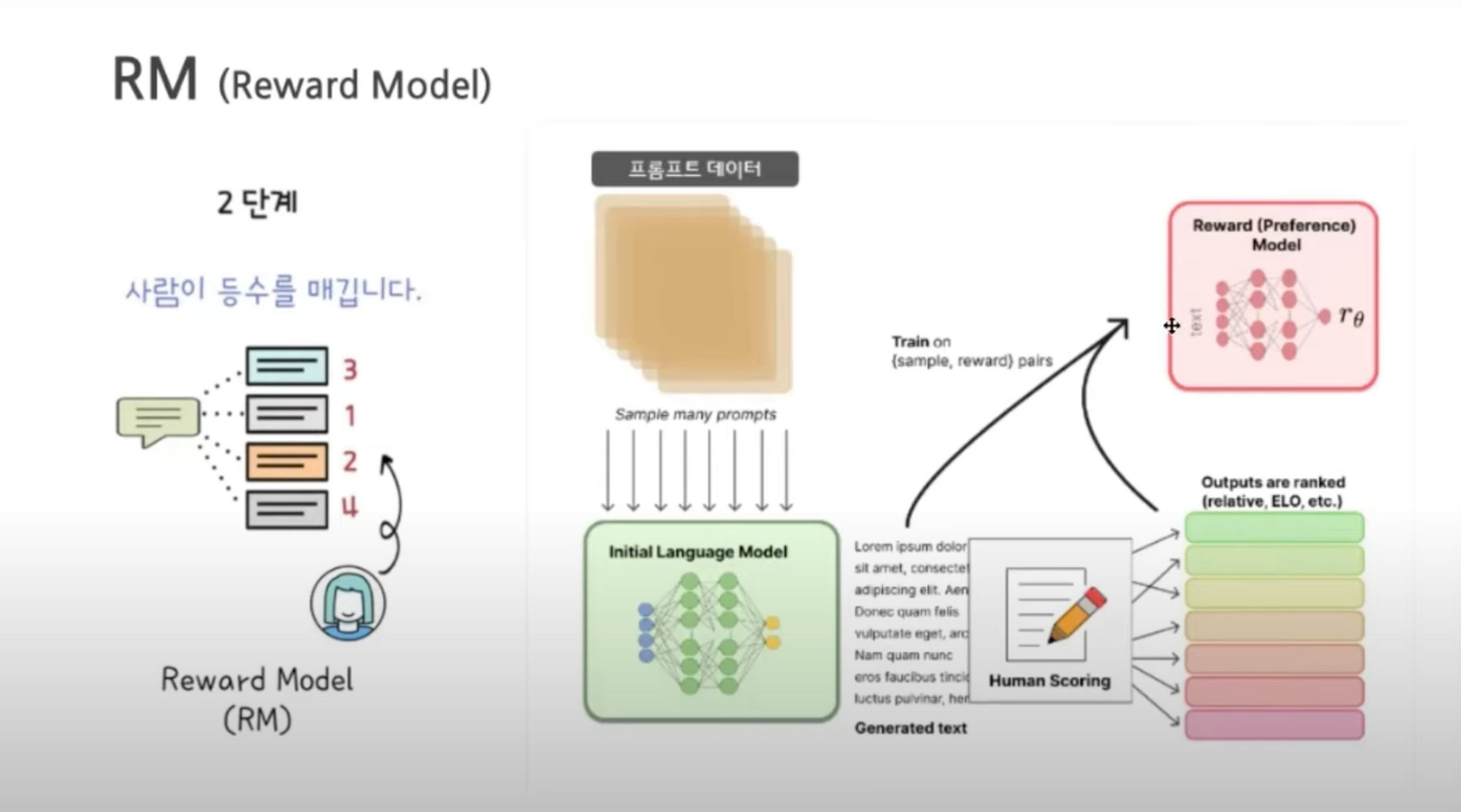
2. Reward Model
-
문장 생성 : 프롬프트 목록이 선택되고 SFT 모델이 각 프롬프트에 대해 여러개 (4~9)개 출력을 생성
-
랭킹 라벨링 : 라벨러는 출력의 순위를 레이블링함 그 결과 레이블링이 지정된 새 데이터 세트가 생성 이 데이터 세트의크기는 SFT 모델에 사용된 데이트 세트보다 약 10배 정도 큼
-
RM 학습 : 새로운 데이터는 보상 모델 ( RM )을 훈련하는데 사용됨. RM 모델은 SFT 모델 출력을 입력으로 받아 선호도 순으로 순위를 학습함.
175B 언어 모델과 6B 보상 모델을 사용
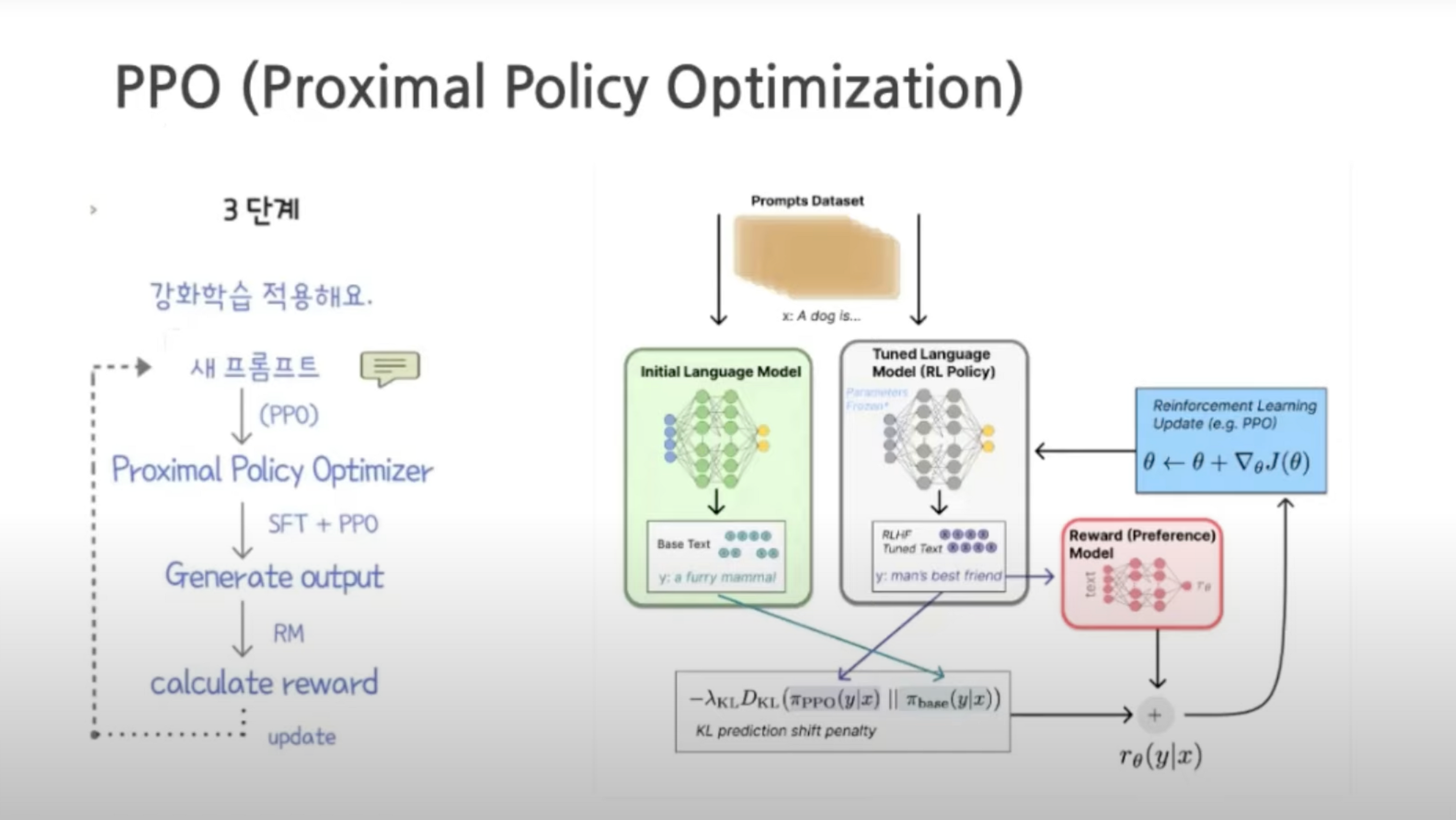
3. PPO (Proximal Policy Optimization)
-
SFT + PPO : SFT 모델에 PPO를 붙혀 파인튜닝
-
RM 모델의 평가 : 프롬프트와 응답이 주어지면 RM 모델에 따라 결정된 보상이 생성됨
-
PPO 알고리즘 : 강화 학습 정책 알고리즘 , 에이전트가 수행하는 작업과 받는 보상을 기반으로 현재 정책을 지속적으로 조정
-
초기 모델을 만들어서 지시에 따라 결과를 생성한 후 , 보상 모델을 구축하여 사람의 피드백을 모방 , 초기 모델이 사람이 선호나느 결과를 추론하도록 강화 학습 진행
4. GPT 모델의 한계점
- Lack of control study : Supervised Fine-tuned Model을 기반으로 하고 최종 PPO를 뽑는 과정에서 대조군이 없음
- Lack of ground truth for the comparison data : 모델의 데이터 선택자 의지에 영향을 받음
- Human preferences are just not homogeneous : 이용하는 사람들마다 의견이 다 다름
- Prompt-stability testing for the reward model : 인간 선택이 얼마나 큰 영향을 미치는지 정도를 알 수가 없음
- Wireheading-type issues : 특정 결과물에 쏠림 현상 나타나는 점
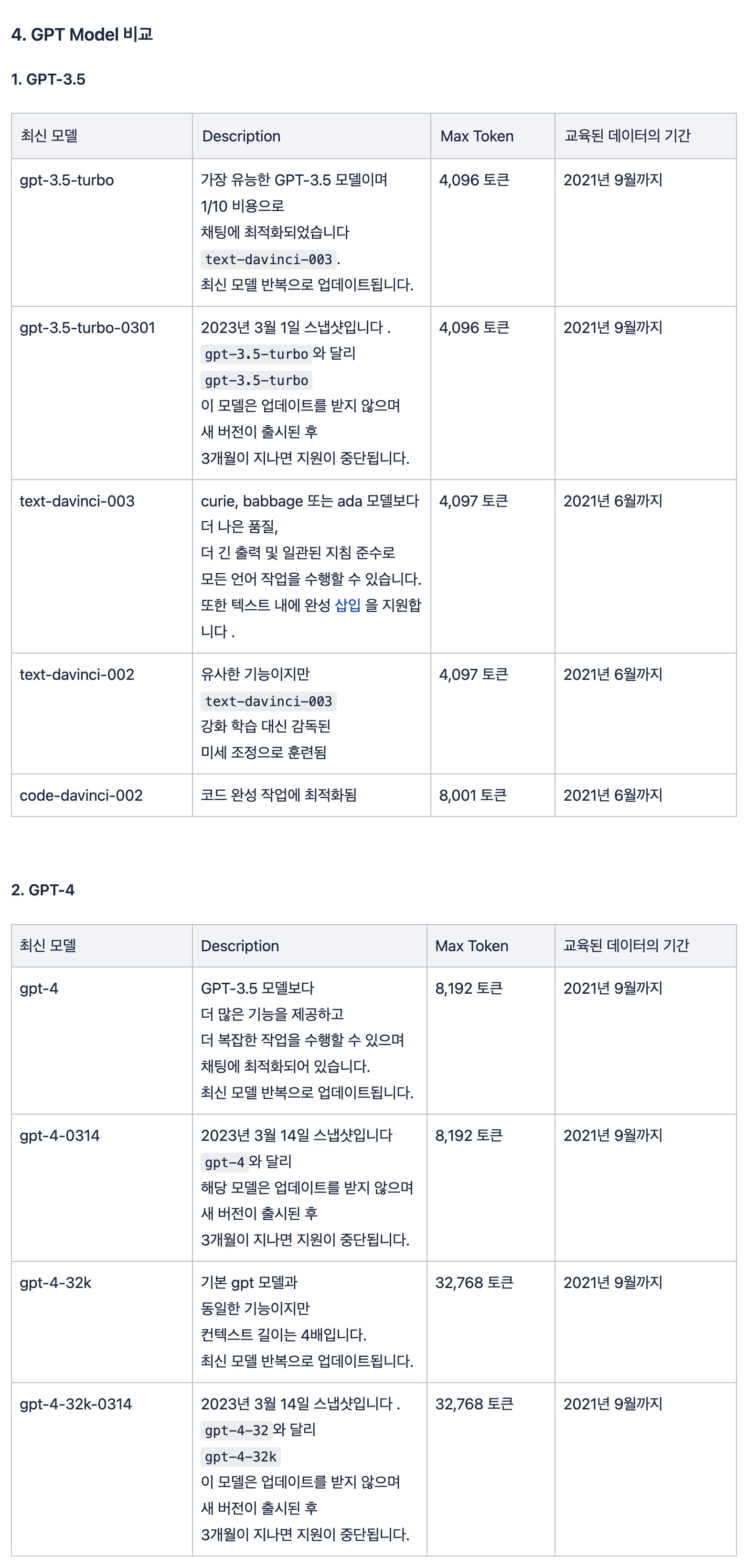
5. GPT Model 비교
Reference
1. https://www.youtube.com/watch?v=vziygFrRlZ4&list=PLhZpGghaa_0QhRZBk6ALlTDM5MlM66Hqj&index=1
2. https://docs.cohere.com/docs/prompt-engineering
3. https://platform.openai.com/docs/models/gpt-4