[논문 리뷰] Big data driven jobs remaining time prediction in discrete manufacturing system: a deep learning-based approach
0
Paper Seminar
목록 보기
7/16
Abstract
- Jobshop에 스마트 센서와 IoT가 널리 보급됨에 따라 예측 제조를 위한 제조 BigData 처리에 대한 필요성이 증가하고 있다. 본 연구에서는 DL 기반으로 Job remaining Time을 예측하는 제조 BigData를 구상한다. 데이터 수집, 데이터셋 설계, 예측 모델링의 세 부분으로 구성된 JPT 예측 절차를 개발하였다. 이를 위해 Stacked sparse Autoencoder라는 모델을 구축한다. 이 연구는 생산 중에 JRT를 예측하는 최초의 Deep learning 기반 연구이며, 실험 결과 S-SAE 모델이 기존의 Linear regression, Backpropagation network, Multi-layer network 및 Deep belief network보다 높은 정확도를 보였다.
Introduction
- RFID기술이 생산라인에서 WIP, 공작 기계, 자재, 작업자 및 기타 물리적 자산 간의 연결성을 획기적으로 높이면서 제조 BigData는 빠른 속도로 생성되고 있다. 한편, BigData의 출현과 함께 현재 가장 주목받는 머신러닝 알고리즘 중 하나인 Deep learning은 생산 관리 및 제어를 위한 고급 예측 모델 구축을 포함하여 BigData 솔루션 부분에서 점점 더 중요한 역할을 하고 있다.
- 제조 기업은 제품의 복잡성 증가와 함께 맞춤화 수준이 증가함에 따라 MTS(make-to-stock)방식에서 MTO(make-to-order)방식으로 전환하게 되었다. 이러한 배경 속에 원래의 생산 일정과 실제 제조 공정의 차이에 대한 균형을 맞추기 위해 발주된 주문의 실시간 진행 정보를 획득하는 것이 필수적이다. Job remaining time은 주문의 나머지 작업을 완료하는 데 필요한 잔여 시간을 나타내며, 실시간 조건에서 즉각적으로 예측할 수 있다. 이를 통해 관리자는 실시간 온라인 제조 스케쥴링에 대한 의사 결정을 할 수 있게 된다. 그러나 실제 제조 현장에서는 예상치 못한 생산 장애로 인해 실제 완료 시간이 계획된 시간과 일치하지 않아 불가피한 일정 변경으로 이어지는 사례가 다수 발생한다. 이러한 복잡한 상황을 모두 고려하여 정확하고 효율적인 JRT 예측을 수행하는 것은 어렵다. 본 연구에서는 Jobshop에서의 RFID 기반 BigData 수집을 기반으로 BigData + Deep learning 방법을 사용하여 관리자가 고급 예측 모델을 활용하여 작업 현장 데이터를 심층 분석하고 다양한 입력과 출력간의 복잡한 관계와 영향을 파악한 다음 JRT 예측의 정확성과 효율성을 개선하여 개별 제조 시스템의 정밀 제어를 더욱 촉진할 수 있도록 모델을 설계하였습니다.
The BD driven JRT prediction
Raw data collection
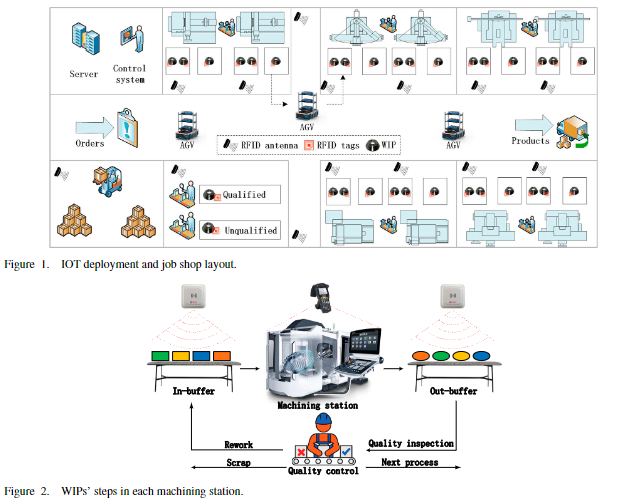
제조 시스템의 주요 목표는 주문된 부품을 제작하고 완성된 제품을 납품하는 것이다. Jobshop은 일종의 제조 시스템으로 다음과 같이 정의된다.
Definition 1
- Jobshop은 다양한 맞춤형 제품의 소규모 묶음을 만드는 제조 공정의 한 종류이다. Jobshop에서는 유사한 장비 또는 기능이 함께 그룹화되어 주문이 도착하면 작업 중인 부품이 작업 시퀀스에 따라 다양한 영역으로 이동한다. 제조 Jobshop에서 IoT 관련 기술을 적용하여 제조 대상을 식별 및 모니터링할 수 있으며, 실시간으로 생산 데이터를 수집할 수 있다.
Definition 2
- 생산 프로세스의 각 WIP 상태는 part ID, operation_NUM, in_Time, start_time, finish_Time, out_Time으로 정의된다.
Definition 3
- Jobshop의 각 작업 Station은 machine_ID, operation_Type, team_ID, operation_ID, machine_Status로 정의된다.
Definition 4
- 작업장에 발주된 각 주문은 order_ID, part_Type, part_Quantity, release_Data, lead_Date, priority, process_Route로 정의된다.
일반적으로 Raw dataset는 실시간 수집 데이터와 이력 데이터를 모두 포함하며, 주문 구성, Jobshop 실시간 상태 및 공작기계 상태에 대한 정보를 포함하는 분산 데이터베이스에 수집 및 저장된다.
Candidate dataset design
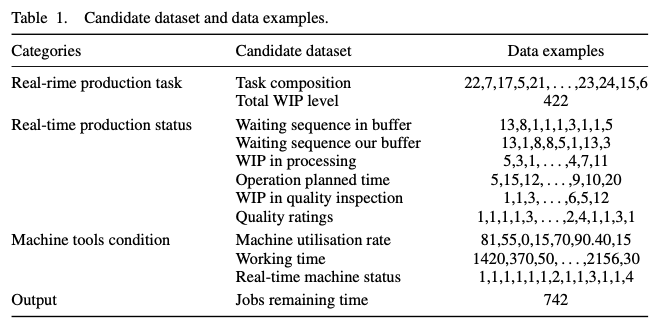
- 본 논문에서의 Candidate dataset은 Raw dataset에서 추출한 것으로, JRT에 영향을 미치는 세 가지 일반적인 측면을 다루고 있다. 기계 고장 및 부적합 공작물과 같은 명시적인 생산 장애가 포함되며 암시적 장애 또는 생산 불확실성은 수집된 데이터에 내포되어 있다.
The S-SAE model for JRT prediction
- 본 연구에서 Stacked sparse autoencoder 모델은 새로운 DL 모델 중 하나로, Candidate dataset에서 높은 수준의 대표 특징을 추출하고, 회귀 Neural network를 연결하여 정확하고 강력한 JRT 예측을 수행하도록 설계되었다.
- Sparse AE는 기본적인 AutoEncoder 구조를 확장한 것으로, Sparse penalty를 도입하여 Sparse representation을 추출하는 점에서 효과적인 Representation을 얻을 수 있다. 학습에 사용되는 Cost function은 아래와 같다.
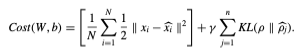
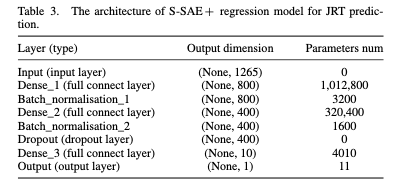
S-SAE + regression predictor

- 위 그림에서 볼 수 있듯이, S-SAE 모델은 여러개의 AE를 쌓아서 구성된다. 구체적으로 설계된 S-SAE의 Hidden layer로 두개의 Stack layer가 있다고 가정하면, 첫 번째 layer는 원본 데이터를 Input으로 사용하고, Output은 두 번째 layer의 Input으로 사용한다. 이러한 방식으로 여러 SAE를 계측적으로 쌓아서 S-SAE를 생성한다.
- S-SAE에서 추출된 Feature는 Linear activation function을 가진 하나의 regression predictor로 JRT를 산출한다.
Experiment
- BigData 기반 JRT 예측의 적용 가능성을 검증하기 위해 실험을 수행하였다. Jobshop 내에는 머시닝 센터, 밀링 머신, 선반 머신 등 44개의 work station이 있으며 각 work station에는 다양한 크기의 In-buffer 및 Out-buffer 영역이 배치되어 있다. 각 작업 후 처리 품질을 검사한다. 해당 생산 라인은 주로 13가지 부품을 가공하며, 공정 경로는 work station ID로 표시된다. 수집된 데이터는 데이터 수집 기간 동안 완료된 주문 및 현장 상태의 기록된 정보에서 비롯되며, 과거 시점 t에서 하나의 데이터 sample을 추출한다고 가정하면 주문의 마지막 작업의 실제 완료일과 시점 t사이의 시간 차이로 JRT가 계산된다.
- 실험에 사용된 모델의 Hyperparameter는 아래 표와 같다.
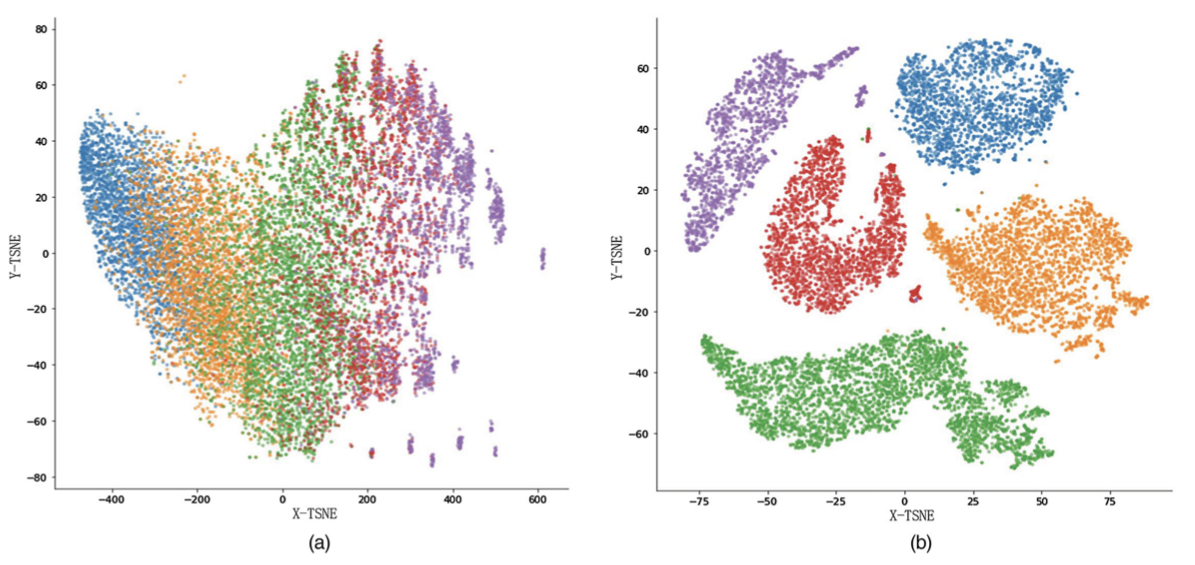
- 위 그림은 학습 전과 후를 t-SNE를 사용하여 시각화한 것이다. S-SAE를 통해 추출한 Representation이 확실하기 각 군집끼리 구분되는 것으로 보아 표현 학습이 잘 이루어졌다고 말할 수 있다.
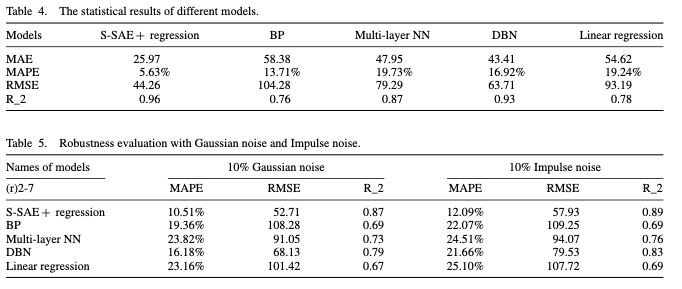
- 또한, 여러 비교 모델들과 성능 비교를 수행한 결과, MAE, MAPE, RMSE, R^2 4가지 평가지표에서 모두 제안 모델이 가장 성능이 우수한 것을 알 수 있다. 추가적으로 모델의 Robustness를 검증하기 위한 노이즈 추가 실험에서도 제안 모델이 가장 노이즈에 대한 Robustness가 높음을 알 수 있다.
The effect of proposed model in the real settings

- 실제 상황에서 제안 모델의 성능을 평가하기 위해 Testset에 대한 실험도 수행하였다. 위 그림에서 빨간색 실선이 Test data sample에 대한 JRT 예측값의 변화를 나타낸 것이고, 파란색이 실제 계산을 통한 값을 나타낸 것이다. 그림에서도 알 수 있듯이 예측된 JRT의 Trend가 실제 변화와 매우 유사한 패턴을 보인다는 것을 알 수 있다.
Conclusion
- 본 논문에서는 S-SAE를 대규모 제조 시스템 예측 작업에 적용한다. 수주된 주문의 실시간 진행 상황을 측정하기 위해 Jobs Remaining Time을 정의하고, 변화가 끊임없이 일어나느 생산 상태에 대응하여 실시간 생산 계획을 결정하기 위해 JRT 예측을 수행한다. 제안 모델은 Candidate dataset의 특징을 학습하여 4가지 성능 지표에서 비교 모델들을 큰 격차로 이겼다. 또한, 이상 생산 데이터에서도 비교적 Robustness를 유지하였다.
개인적인 생각
-
Raw data를 그대로 사용하지 않고 Data sellection을 통해 Candidate dataset을 설계한 점에서 이미 Prior knowledge가 들어갔기 때문에 해당 부분에 있어서 한계점이 있다고 생각된다.
-
그러나 비교적 간단한 모델인 S-SAE를 사용하여 효과적으로 JRT를 예측한 점에서 Contribution이 있는 논문인 것 같다.

Researcher