본 논문은 Test-time domain adaptation 연구에서 Target domain이 Static한 상황만을 고려하는 기존 연구의 한계점을 극복하기 위해 Continual learning 방식을 접목한 CoTTA를 제안한 논문이다. CoTTA는 Continual한 학습을 진행하는 과정에서 오류 누적과 Catastrophic forgetting 문제를 완화하기 위해서 여러 방법을 사용한다.
Introduction
- Test-time Domain adaptation은 추론을 수행하는 동안 test data로부터 학습하여 이미 source data로 학습된 모델을 adaptation 시키는 것을 목표로 함. 이는 source data와 test data 간의 domain shift에 의해 모델의 성능이 하락하는 현상을 방지하기 위함인데, 최근 개인정보 보호 문제나 법적 제약으로 인해 일반적으로 source data를 inference 간에 사용할 수 없는 것으로 간주되기 때문에 제안된 adaptation 방법론 임
- 기존 연구에서는 pseudo label이나 Entropy regularization을 통해서 모델을 업데이트함으로써 source domain과 stationary target domain 간의 분포 shift를 해결하는 경우가 많았음. 그러나, test data가 지속적으로 변화하는 시나리오에서는 아래 두 가지 측면의 이유로 인해 불안정할 수 있음
- 지속적으로 변화하는 시나리오에서는 분포 shift로 인해 pseudo label에 영향을 주는 노이즈가 더 심해지고 잘못 보정될 수 있음
- 모델이 지속적으로 새로운 분포에 Adaptation됨에 따라 source domain의 정보를 보존하기 어려워저 Catastrophic forgetting으로 이어질 수 있음
- 본 논문에서는 이러한 한계점을 해결하기 위해 CoTTA 방법론을 제안함. 지속적으로 변화하는 test data에 의해 오류가 누적되는 것을 완화하기 위해 weight-averaged teacher model을 사용하며 이는 선행연구에서 mean teacher prediction이 standard model보다 성능이 높은 경우가 많다는 점에 착안했음. 반면, Domain 간 격차가 큰 test data의 경우, augmentation-averaged prediction을 사용함
- 또한, source data의 정보를 보존하고 forgetting을 방지하기 위해 신경망 중 일부를 확률적으로 사전에 source data로 학습된 모델로 복원하는 방법을 제안함
Related work
Domain Adaptation & TTA
-
Labeling된 Source domain과 label이 없는 target domain 간의 shift가 발생한 상황에서 adaptation을 수행하는 것이 Unsupervised Domain Adaptation(UDA)라고 함. 최근 연구에서는 UDA를 위해 target pseudo label을 반복적으로 사용하여 네트워크를 학습시키는 self-training도 유망한 결과를 보여줌
-
Test-time adaptation (TTA)는 Source-free domain adaptation으로도 불리는데, TTA는 adaptation을 위해 source domain data에 access할 필요가 없음. source가 없는 상황에서 adaptation을 수행하기 위해 생성 모델을 활용하여 feature alignment를 수행함
-
TTA를 위한 또 다른 접근법은 source model을 fine-tuning하는 것임 (e.g. TENT, SHOT).
TENT (Test entropy minimization): Pre-trained model을 사용하여 Entropy minimization을 통해 test data에 adaption함
SHOT (Source hypothesis transfer): 적응을 위해 Entropy minization 뿐만 아니라 Density regularizer를 활용함 -
또한, Pseudo protytypes를 사용하거나 Bayes 관점으로 분석하는 연구도 존재함
Continuous Domain Adaptation
- 기존의 Domain adaptation이 특정 target domain을 가정하는 것과 달리, Continuous domain adaptation은 지속적으로 변화하는 target data에 대한 adaptation 문제를 다룸. Continuous Manifold Adatation (CMA)와 Incremental Adversarial Domain Adaptation (IADA)등의 연구가 있으며 기존의 연구들은 분포 alignment를 위해 source와 target domain data에 모두 접근 가능해야 한다는 한계가 있음
Continual Test-Time Domain Adaptation
- 본 논문에서는 source domain data를 사용하지 않는 Domain adaptation 연구를 수행하며, 기존의 domain adaptation 관련 연구들과의 차이점을 아래 표로 나타냄

Methodology
- 제안하는 방법론은 Pre-trained source model을 사용하여 지속적으로 변화하는 target data에 online 방식으로 adaptation 시킴. 기존 연구에서 self-training의 Error accumulation 문제가 주요 bottleneck이라는 사실에 기반하여, Weight-and-augmentation-averaged pseudo labels를 사용하여 이를 줄이ㄹ는 방안을 제안함
- 또한, Continuous domain adaptation 과정에서 fogetting을 줄이기 위해 source model로부터 정보를 명시적으로 보존하는 방안도 제안함. CoTTA의 전체적인 구조는 아래 그림과 같음
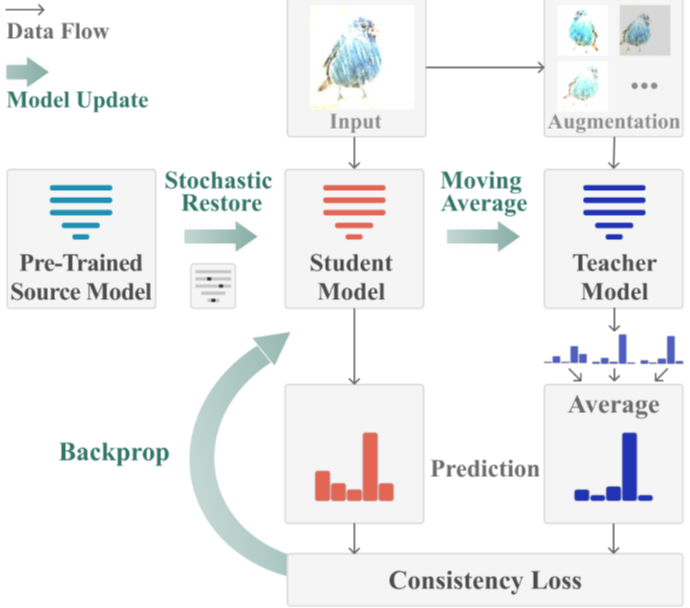
Source model
- 기존의 TTA 방법론들은 domain generalization 능력을 향상시키고 adaptation을 용이하게 하기 위해 특별한 technic을 추가하는데, 이는 source data에 대한 재훈련이 필요하며, 기존의 Pre-trained model을 재사용할 수 없게 만듦
- 반면, 본 논문에서 제안하는 TTA 방법은 이러한 한계점을 제거하며, 재훈련 없이도 기존의 source model을 활용할 수 있음
Weight-Averaged Pseudo labels
-
Self-training 접근 방식에서 일반적인 TTA의 목표는 예측값과 pseudo label 간의 Cross-entropy 일관성을 최소화하는 것임. 이러한 접근 방식은 stationary target domain에서는 효과적일 수 있지만, 분포 변화가 발생하는 target data에서는 pseudo label의 품질이 크게 저하될 수 있음
-
따라서, weight-averaged model이 훈련단계에서 최종 모델보다 종종 더 정확한 성능을 도출한다는 것에서 영감을 받아, 본 논문에서는 weight-averaged tearcher model을 활용하여 pseudo label을 생성함. Time step 에서 pseudo label은 tearch model에 의해 생성되며, 다음과 같음
-
이후, student model은 student의 예측값과 teacher의 예측값 간의 cross-entropy loss를 통해 업데이트되며 이 업데이트는 student가 teacher의 안정된 pseudo label에 기반하여 학습하도록 유도함. 이를 통해 분포 변화가 있는 환경에서도 모델의 adaptation 능력을 유지하고 Error accumulation을 줄이는 데 도움을 줌
-
Student model가 업데이트 된 이후, teacher model의 가중치는 student model의 가중치를 기반으로 지수 이동 평균을 통해 업데이트 되며 관련 수식은 아래와 같음
Augmentation-averaged Pseudo labels
- 기존 연구를 통해 Test time 동안 augmentation을 사용하는 것이 모델의 robustness를 향상시킬 수 있음이 입증되었으나, 이러한 augmentation은 특정 데이터셋에 대해 사전에 결정되고 고정되며 Inference 시간 동안의 분포 변화를 고려하지 않음. 따라서, 본 논문에서는 test time에서의 domain shift를 고려하고 Prediction confidence를 통해 domain 불일치를 근사함
- Augmentation은 Error accumulation을 줄이기 위해 domain의 불일치가 클 때에만 적용됨
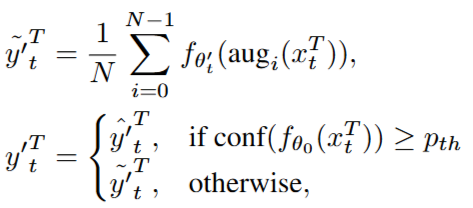
- 는 teacher model의 augmentation-averaged prediction을 나타내며, 은 direct prediction을 나타냄. Confidence가 높은 sample에 대해 augmentation을 수행하게 되면, 모델 성능이 저하될 수 있다는 것을 관찰하였기 때문에 sample의 confidence를 구분짓는 과정이 중요함
- 요약하자면, Confidence metric을 사용하여 Domain 불일치를 근사하고 augmentation을 적용할 시점을 결정함. 이후, student model은 refined pseudo label을 통해 업데이트되며 이를 통해 안정적이고 robust한 학습이 지속될 수 있음
Stochastic Restoration
-
더욱 정확한 pseudo label은 error accumulation을 완화할 수 있지만, self-training을 통한 장기적인 Continuous domain adaptation은 필연적으로 error와 forgetting을 동반함. 더 나아가, 분포 변화가 강한 sample을 처리한 후에도 continuous adaptation의 영향으로 인해 잘못된 예측을 하는 방향으로 모델이 학습될 가능성이 존재함
-
이러한 문제를 해결하기 위해 CoTTA는 Stochastic restoration 방법을 제안하며, source model로부터 지식을 명시적으로 복원함
-
이러한 stochastic restoration은 Dropout의 특별한 형태로 간주될 수 잇으며, 훈련 가능한 가중치의 일부 Tensor 요소를 초기 가중치로 확률적으로 복원함으로써, 네트워크는 초기 source model에서 지나치게 달라지는 것을 방지하고, 결과적으로 catastrophic forgetting을 완화할 수 있음
-
또한, source model의 정보를 보존함으로써 네트워크는 모든 훈련 가능한 파라미터를 학습할 수 있고, 이는 Model collapse를 방지함. 이를 통해 adaptation을 위한 더 큰 model capacity를 제공함
Experiments
- CoTTA의 성능을 검증하기 위해 5가지 Continual test-time adaptation benchmark tasks 수행함
- CIFAR10-to-CIFAR10C (standard)
- CIFAR10-to-CIFAR10C (gradual)
- CIFAR100-to-CIFAR100C
- ImageNet-to-ImageNet-C
- Cityscapses-to-ACDC
CIFAR10-toCIFAR10C
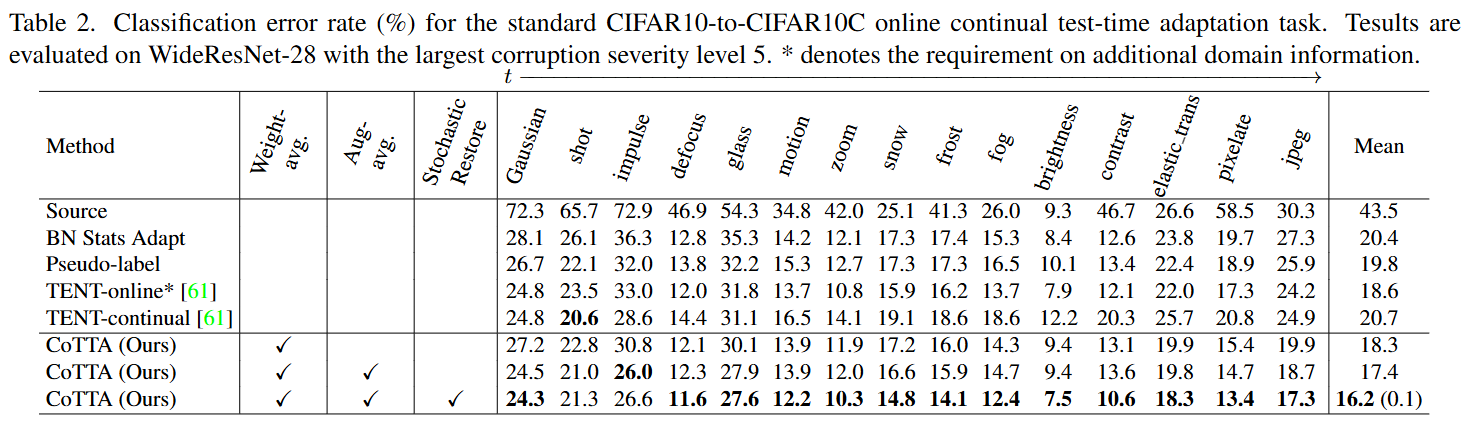
- 위 표에서 볼 수 있듯이, Adaptation 없이 source model만 사용하는 경우 평균 error rate가 43.5%로 매우 높아서 adaptation이 필요함을 알 수 있음. 제안된 CoTTA는 weight-and-augmentation-averaged consistency을 활용하여 비교 방법론들의 성능을 능가하며 평균 error rate는 16.2%로 크게 감소하였음
- 또한, Stochastic restore를 통해 장기적으로도 성능 저하를 나타내지 않음을 보임
CIFAR100-to-CIFAR100C
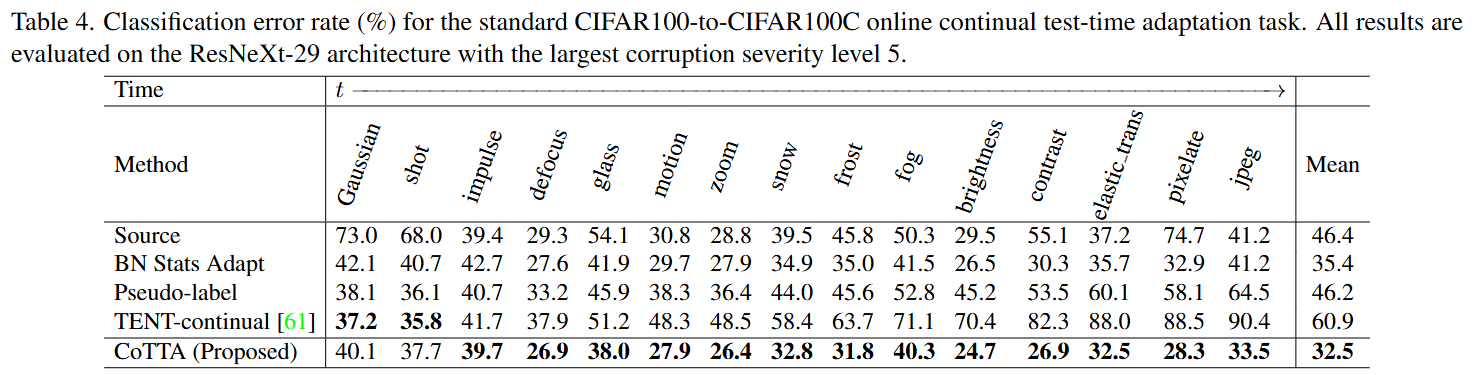
- 위 표는 해당 실험의 결과를 정리한 것이며 CoTTA가 평균 error rate 32.5%로 가장 우수한 성능을 도출함. 여기서, 시간이 지남에 따라 성능 개선 폭이 더 커졌다는 점이 중요하며 이는 제안된 방법이 과거의 unlabeled test images를 학습하여 현재 test data의 성능을 추가적으로 개선할 수 있음을 나타냄
ImageNet-to-ImageNet-C

- ImageNet dataset에 대한 실험 결과, CoTTA는 다양한 corruption type에 대해서 robust한 성능을 도출함
Cityscapes-to-ACDC
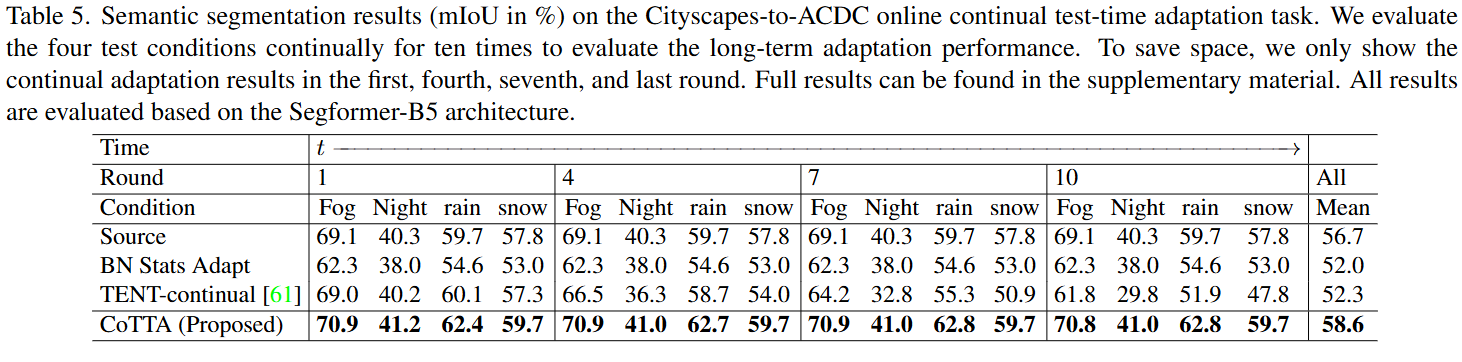
- Classification task 이외에도 Semantic segmentation task 실험 결과, CoTTA는 비교 모델 대비 최소 1.9%p의 성능 향상을 기록하였으며, 평균적으로 58.6% mIoU를 기록함. BatchNorm or LayerNorm과 같은 특정 layer 종류에 의존하지 않기 때문에 복잡한 architecture를 사용하는 경우에도 효과적인 성능을 도출함
Conclusion
- 본 논문에서는 Continuous test-time adaptation을 위해 CoTTA를 제안하였으며, weight and augmentation averaged prediction을 사용하여 self-training에 사용되는 pseudo label의 정확도를 향상시켰음. 또한, stochastic restoration을 통해 forgetting 문제를 완화함. CoTTA는 Pre-trained model에 plug-in이 가능하며, architecture에 대한 수정 없이도 적용할 수 있다는 장점이 있음. 다양한 task에 대한 실험을 통해 제안 방법의 성능을 검증하였고, 대부분의 경우에 가장 우수한 실험 결과를 나타냄
