Abstract
- Deep networks는 Latent representation space에 데이터를 삽입하고 다음 작업을 완료하는 데 강력한 역량을 가지고 있다. 그러나 이러한 능력은 대부분 고품질 label에 비롯된다. Noisy label은 수집 비용이 낮지만 일반화 성능이 떨어지는 단점을 가진다. 본 논문에서는 Robust representation을 학습하고 noisy label을 처리하기 위해 Selective supervised contrastive learning을 제안한다.
- Sel-CL은 noise가 많은 label을 사용할 때 성능이 저하되는 문제를 가진 Supervised Contrastive learning을 확장한 것이다. Sel-CL은 label에 존재하는 noise로 인해 representation learning의 성능이 저하되는 Sup-CL의 문제를 보완하기 위해 Noise pair 중에서 신뢰할 수 있는 pair를 선택한다. 해당 선택 과정에서 학습된 표현과 주어진 label의 일치도를 측정하여 Confident example을 선택한다. 그런 다음, 이를 바탕으로 구축된 confident pair의 representation similarity distribution을 활용하여 Noise pair 중에서 Confident pair를 추출한다. 이렇게 얻은 최종적인 Confident pair를 Sup-CL에 사용하여 성능을 향상시킨다. 여러 Noise 형태가 있는 데이터에 대한 실험을 통해 이 방법으로 학습한 표현의 Robustness를 SOTA 성능으로 입증하였다.
Introduction
- 대규모의 고품질 label을 가진 Dataset은 높은 성능을 보장하지만 많은 비용이 든다. 이 비용을 줄이기 위해서는 Noisy label을 활용해야하는데 이는 손상된 Representation을 추출하고 다음 작업에 대한 잘못된 의사결정을 유발하며 일반화 성능을 저해한다. 따라서 Noisy label을 사용한 학습을 위해서는 Instance의 Robust latent representation을 유도하는 것이 중요하다.
- 기존의 Contrastive learning 기법을 활용한 연구에서는 Unsupervised contrastive learning에 비해 Supervised contrastive learning이 더 나은 성능을 보이기 때문에 Noisy label을 활용하기 위해 정규화, Pseudo labels 생성 과 같은 범용 기법을 활용한다. 이러한 방법들은 경우에 따라 잘 작동할 수 있지만, Sup-CL의 뛰어난 pair-wise 특성을 고려하지 못한다.
- 본 논문에서는 위의 문제를 해결하기 위해 Selective-supervised contrastive learning을 제안한다. 이 방법의 핵심 아이디어는 noisy pair 중에서 신뢰도 높은 pair를 선택하고, 신뢰도 높은 pair를 사용하여 Robust latent representation을 학습하는 것이다. Confident pair의 정확한 식별을 위한 noise rate를 추정하는 것은 어렵기 때문에 먼저 식별하기 쉬운 Confident examples를 사용하여 각 epoch에서 신뢰할 수 있는 Pair set을 구축한 다음 이를 바탕으로 모든 noisy pair 중에서 신뢰도 높은 confident pair를 선택한다.
- 이러한 pair-wise 선택을 통해 Class label이 올바른 쌍 뿐만 아니라 잘못 분류된 label도 잘 활용할 수 있다. 선택된 모든 Confident pair는 Supervised contrastive learning을 통해 Representation을 진행한다.
Contribution
- Noisy label을 사용한 Selective-supervised contrastive learning을 제안하며, 이는 Supervised contrastive learning을 수행하기 위한 confident pair를 효과적으로 선택함으로써 Robust pre-trained representation을 얻을 수 있다.
- Pair의 noise 비율을 알지 못해도 식별된 신뢰성 있는 example로 구축된 pair와 유사도가 높은 example로 구축된 Pair를 선택할 수 있다. 이는 더 나은 confident pair가 더 나은 representation을 추출하고, 더 나은 representation이 더 나은 confident pair를 식별하는 선순환 구조를 완성한다.
- Synthetic에 대한 실험을 수행한다.
Selective-Supervised Contrastive Learning
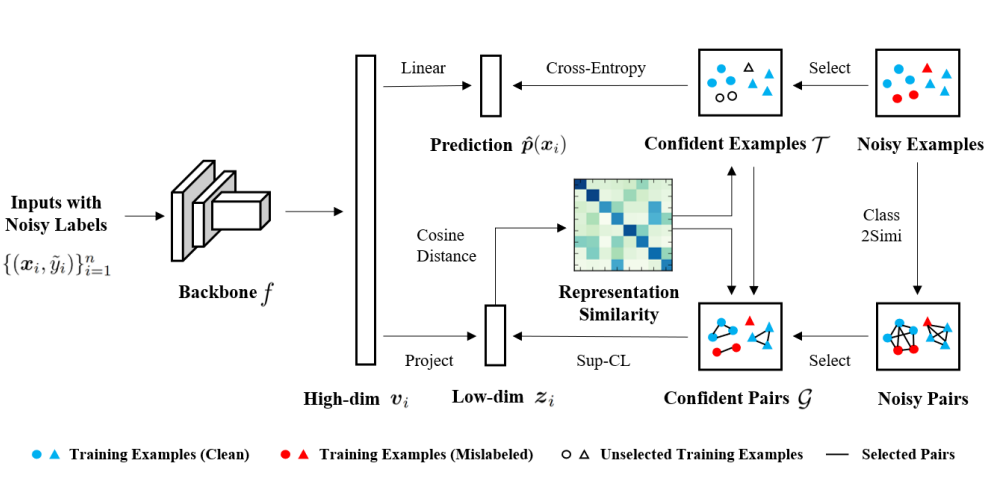
- 본 논문의 모델은 2단계로 학습된다. Robust representation을 추출할 수 있는 Backbone encoder를 학습하고, 추가로 새로운 Classifier를 적용하여 Fine-tuning한다.
Selecting Confident Examples
- Confident pair를 식별하기 위해 먼저 Representation similarity를 기반으로 Confident example을 선택한다. 위 그림에서 얻어진 Zi로 구분된 class와 주어진 label 사이의 일치도를 측정하여 식별한다. 이때 Zi를 활용하여 Class를 구분하기 위해 해당 표현과 유사한 k개의 표현의 label을 참고하여 class 분류를 수행한다. 이러한 방식으로 Representation similarity을 사용하여 label이 잘못 지정된 example의 선택을 예방할 수 있다.
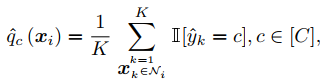
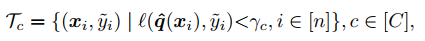
- 위 식에서 Tc는 선택된 임의의 클래스 C에서 Confident example의 집합을 의미한다.
Selecting Confident Pairs
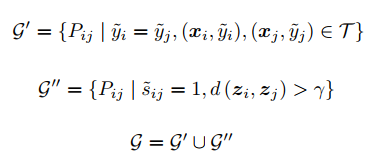
Representation Learning with Selected Pairs
- Confident pair를 선택한 후에는 각 Epoch에서 Supervised contrastive learning을 통해 이를 활용하여 Representation을 학습할 수 있다. 선택된 confident pair는 Noise가 적을 가능성이 높으므로 이 Selective supervised 패러다임은 Noise가 많은 label을 가지고 있는 데이터를 처리하는 과정에서 Representation을 잘 학습할 수 있다.
- 각 Epoch마다 Confident pair를 교대로 식별하고 Robust representation을 학습함으로써 더 나은 Confident pair가 더 나은 Representation을 낳고 더 나은 Representation이 더 나은 Confident pair를 식별하는 긍정적인 순환을 완성하며 학습이 진행된다.
Classification Fine-Tuning
- 학습된 Robust representation을 사용하기 위해 Deep encoder f만 유지하고 그 위에 새로운 Classifier head를 하나 더 적용하여 Classifier network를 형성하고 Prediction을 출력한다. Noisy label을 처리하는 기존 방법을 적용하여 Classifier를 Fine-tuning할 수 있다. 이 방법은 복잡성을 피하기 위해 간단한 Robust loss function을 사용하여 식별된 confident example에 대해 network를 Fine-tuning한다.
Experiments
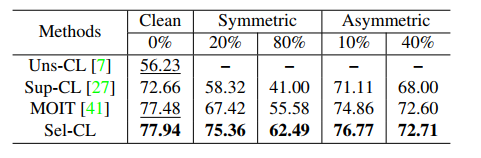
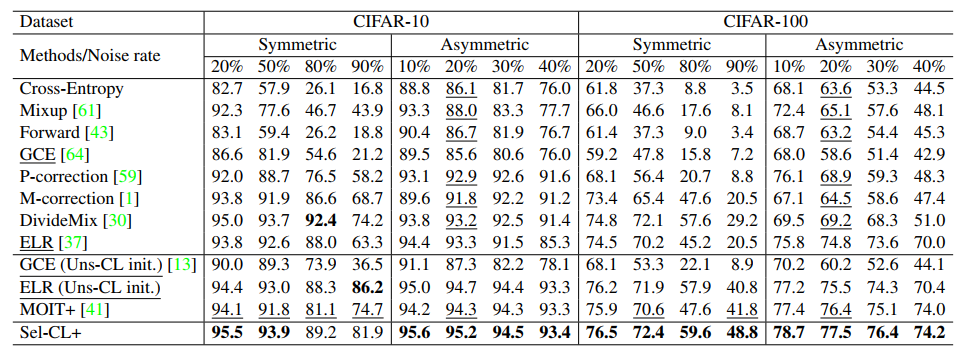
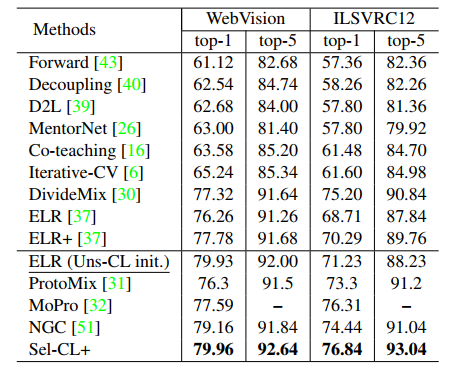
Ablation study
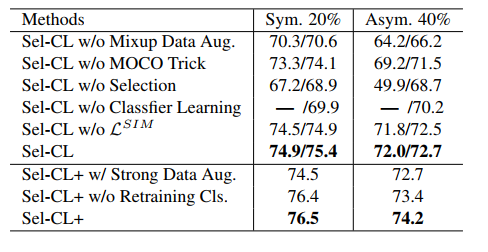
Limitations
- 대조학습을 활용하기 때문에 적절한 Data Augmentation과 대량의 Negative sample에 따라 성능이 좌우된다. 더 큰 배치 크기 또는 Memory bank가 필요하므로 하드웨어에 대한 요구사항이 높은 한계점이 존재한다.
- 실험에 활용한 KNN 알고리즘을 사용하면 더 많은 연산이 수행되어야 한다는 단점이 존재한다. 이를 완화하기 위해 더 빠른 KNN 알고리즘을 사용하였으며, 이를 통해 대규모 Dataset에 쉽게 적용할 수 있다.
Conclusion
- 본 논문에서는 Robust selective-supervised contrastive learning을 사용하여 noisy label을 가진 Dataset을 분류하는 방법론을 제안한다. Contrastive learning의 Pair-wise 특성을 활용하여 Network robustness를 더욱 향상시킨다. 사전에 noise rate를 알고있지 않더라도 Supuervised contrastive learning을 위해 noise pair 중에서 신뢰도 높은 pair를 선택한다. 여러 noise label이 존재하는 Dataset에 대한 실험을 통해 제안 모델이 State-of-the-art 성능을 달성하였으며, 논문의 저자들은 Object detection, Text matching 등 다양한 Task에 해당 방법론을 적용해보는 것에 관심있다고 말한다.

Researcher