Abstract
- 최근 Time-series Anomaly Detection을 위해 제안된 연구들은 여러 Dataset에서 높은 F1 Score를 보이기때문에 Time-series Anomaly Detection 연구가 발전한 것처럼 보인다. 그러나 모델의 평가과정에서 수행되는 Point Adjustment라는 방법론에 의해 이상 탐지 모델이 과대평가될 가능성이 큼을 지적한다. 본 논문에서는 무작위로 초기화된 이상치 점수 조차도 Point Adjustment 방법론을 사용하면 State-of-the-arts 성능을 달성할 수 있음을 밝혔다. 또한, PA를 사용하지 않는 상황에서 훈련되지 않은 모델이 기존 모델들과 비슷한 성능을 얻을 수 있음을 보여줌으로써 Time-series Anomaly Detection에 대한 의문을 제기한다. 연구결과를 바탕으로 새로운 Metric과 Evaluation protocol을 제안한다.
Introduction
- 4차 산업혁명으로 시스템 장애는 사회적으로 큰 영향을 미칠 수 있기 때문에 이러한 장애를 방지하기 위해 시스템의 이상 상태를 탐지하는 것이 중요해졌다. 이는 이상 탐지라는 이름으로 연구되고 있으며 다양한 시계열 이상탐지 방법론들이 딥러닝을 채택하고 있다. 각 모델들은 기존의 방법론들보다 높은 F1 Score를 보임으로써 우수성을 입증해왔다. 그러나 현재 대부분의 Time-series-AD는 Point Adjustment라는 독특한 Evaluation protocol을 적용하여 F1 score를 산출한다. PA protocol은 Anomalies 기간 내 단 한번의 Alarm 만으로도 시스템 복구를 위한 조치를 취하기에 충분하다는 것을 기반으로 제안되었다. 그러나, PA는 모델 성능을 과대평가할 가능성이 높다.
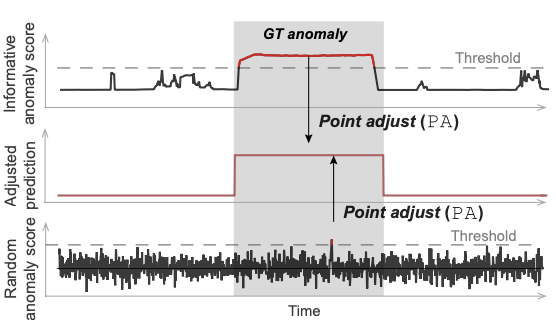
- 위 그림은 단적인 예시이지만 과대평가 가능성을 설명하기에 충분하단 예시이다. 첫번째와 세번째 그래프는 각각 잘 훈련된 모델의 이상치 점수와 무작위로 생성된 이상치 점수를 나타내고, 회색 음영부분은 Ground Truth에 의한 이상 영역을 나타낸다. PA Protocol을 사용하면 잘 훈련된 모델에서 나온 이상치 점수와 무작위로 생성한 이상치 점수가 동일한 성능을 보이게 되므로 PA protocol에 의해 평가된 F1 score가 높은 모델이 다른 모델보다 성능이 더 좋다고 단정짓기엔 무리가 따른다.
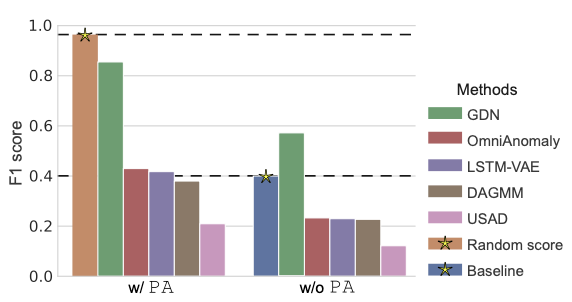
- 또한, 실험을 통해 위 그림처럼 PA protocol을 적용했을 때 무작위로 생성한 이상치 점수가 대부분의 최신 모델의 성능을 뛰어넘을 수 있음이 확인되었다.
Contribution
- Time-series Anomaly Detection에 대한 독특한 Evaluation protocol인 PA가 기존 방법의 탐지 성능을 크게 과대평가한다는 것을 보여준다.
- PA를 사용하지 않는 기존 방법은 Baseline 대비 개선 효과가 없거나 대부분 미미한 것을 보여준다.
- 연구 결과를 바탕으로 Time-series Anomaly Detection을 엄격하게 평가하기 위하 새로운 Baseline과 Evaluation protocol을 제안한다.
Pitfalls of the TAD Evaluation
Point Adjustment
- Time-series Anomaly Detection은 시간 T 동안 N개의 센서에서 관측된 시계열 신호에서 Sliding window 접근법에 의해 나누어진 window가 특정 임계값 이상의 Anomaly score를 가지는 Abnormal인지 판별하는 Task이다. 이때, 모델의 성능 평가에 Precision, Recall, F1 score가 사용된다.
- 기존의 모델들은 Test dataset의 Normal과 Abnormal을 labeling할 때 PA protocol을 사용한다. 해당 protocol은 Time-series dataset에는 여러 timestamp에 걸쳐 지속되는 여러 개의 Anomaly Segment가 포함될 수 있다는 가정 하에 적용된다. 각 Anomaly segment에서 Anomaly score가 적어도 한번 이상 Threshold보다 높으면 해당 Anomaly segment에 포함된 모든 timestamp에 대해 Abnormal로 labeling하는 방식으로 PA가 적용된다.
- 아래의 수식처럼 Point Adjustment가 적용된 label로 Evaluation metric을 계산한다.
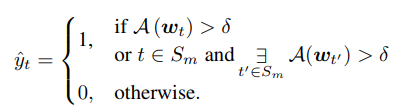
Random Anomaly Score with High F1PA
- PA protocol을 사용하여 F1 score를 산출할 때 Random sampling로 생성된 이상치 점수가 1에 가까운 높은 F1 score를 얻을 수 있음을 수학적으로 증명하는 부분입니다.

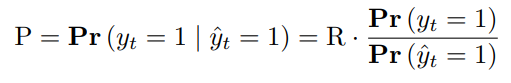

-
F1 score를 계산하는 수식이 첫번째 식과 같을 때, Precision과 Recall을 조건부 확률로 표현할 수 있다.
-
위 식을 활용하여, Anomaly segment가 하나만 존재하는 상황을 가정하면 Precision과 Recall을 아래와 같이 정리할 수 있다.
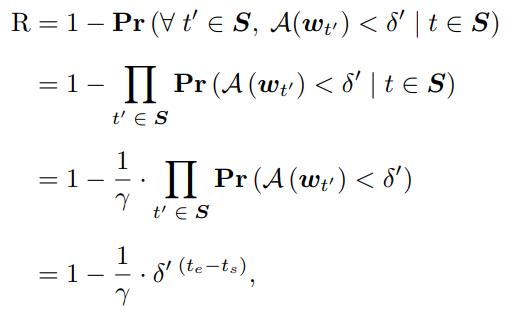

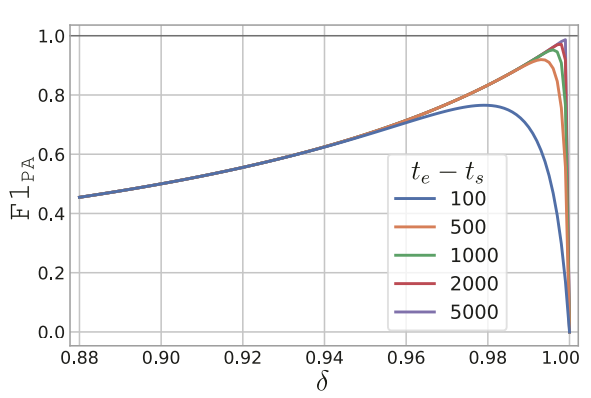
이렇게 정리된 Precision과 Recall을 사용하여 F1 score를 산출한 결과는 다음 그림과 같다. Segment의 길이를 100 ~ 5000으로 조정해가며 실험한 결과로, 를 변화시켰을 때 무작위로 산출된 Anomaly score로 계산된 F1 score가 대부분 1에 가깝게 산출되는 걸 볼 수 있다.
Untrained Model with Comparably High F1PA
- 대부분의 DL 기반 모델의 초기 Weight는 무작위로 초기화된 값을 사용한다. 이때, 초기화된 Weight가 평균이 0이고, 분산이 인 Gaussian 분포를 따른다고 했을 때 해당하는 초기화된 모델의 Output은 0에 가까운 값을 반환한다.

- 따라서, 위 식처럼 Window별 Anomaly score는 원본 데이터의 L2 Norm과 같아지므로 만약 Point anomaly가 다수인 데이터셋에는 초기화된 Weight만으로도 훌륭한 성능이 나올 것이다.
Towards a Rigorous Evaluation of TAD
New Baseline for TAD
- Time-series Anomaly Detection 성능 평가에서 기존 모델들과 비교하는 것뿐만 아니라 Baseline과의 성능 비교도 필요하다. 본 논문에서는 훈련되지 않은 AE와 같이 간단한 구조를 가진 재구성 기반 모델에서 계산된 F1 score를 새로운 Baseline으로 설정하는 것을 제안한다.
New Evaluation Protocol PA%K
-
앞서 언급한 Point Adjustment protocol의 과대평가 문제는 PA를 없애면 즉시 해결된다. 그러나, Test data 분포에 따라 F1 score는 예기치 않게 성능을 과소평가할 수 있다. 실제로 Test data의 labeling 작업은 불완전하게 진행되는 경우가 많기 때문에 일부 이상 신호는 정상 신호와 더 많은 통계를 공유하게 된다.

-
위 그림은 t-SNE를 통해 SWaT Dataset을 시각화한 것이다. 대부분의 Normal data와 Abnormal data는 Cluster를 형성하며 구분되어있지만, 일부 Abnormal로 구분된 data는 Normal data와 더 많은 패턴을 공유하는 것을 알 수 있다. 따라서 그림상의 (b)와 같은 data를 잘 구분하지 못한다는 이유만으로 모델의 성능이 부족하다고 결론 내리는 것은 모델의 성능을 과소평가하는 결과로 이어질 수 있다는 것이다.
-
이에따라 본 논문의 저자들은 기존 F1 score 산출 시 과소평가 가능성을 완화할 수 있는 Evaluation protocol을 제안한다.

-
위 수식은 새로운 protocol이 적용됨에따라 변경된 수식을 나타낸 것인데 Anomaly segment 내에서 올바르게 탐지된 이상값의 수와 길이의 비율이 특정 Threshold K를 초과하는 경우에만 해당 Segment에 PA protocol을 적용하는 방식이다.
Experimental Results
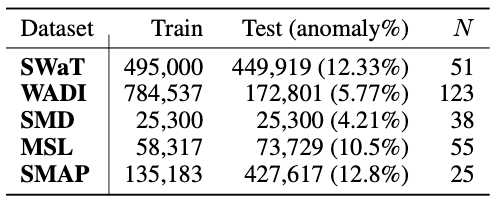
- 위는 본 논문의 실험에 사용된 Dataset의 통계치를 요약해놓은 표이다.
F1PA와 F1의 상관관계
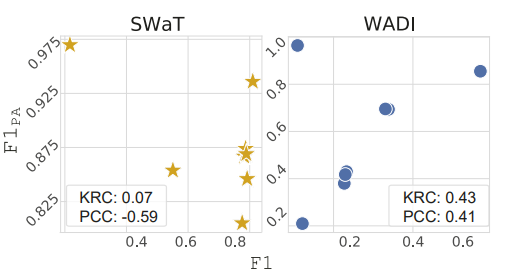
- F1 score는 이상치 탐지 성능을 나타내는 가장 보수적인 지표이기 때문에 F1PA가 탐지 성능을 신뢰성 있게 나타낸다 말할 수 있으려면 F1 score와 상관관계가 존재해야 한다. 아래 그림은 SWaT, WADI Dataset에 대해 F1PA와 F1 score의 피어슨 상관 계수와 켄달 순위 상관 계수를 나타낸 것으로 상관관계가 있다고 판단하기에 불충분함을 알 수 있기 때문에 F1PA만을 사용하여 성능 비교를 진행하는 것은 부적절하다고 말할 수 있다.
성능 비교
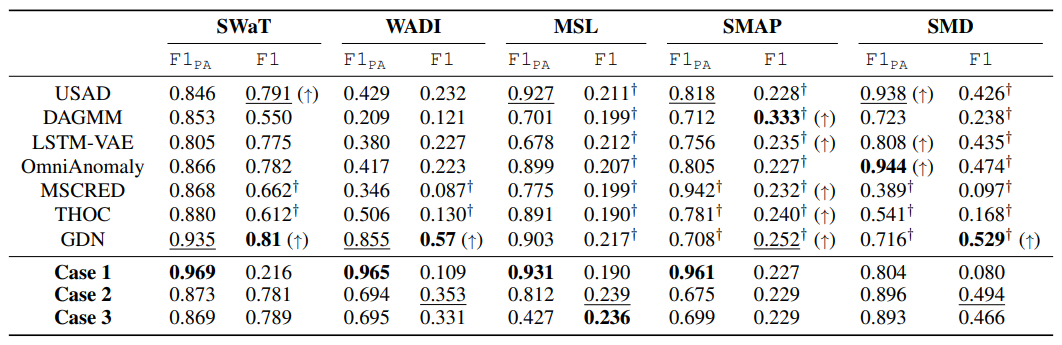
-
Case 1의 경우 Input data의 이상 징후에 대해 아무것도 반영하지 않기 때문에 이상 징후를 감지할 수 없는 것이 당연하지만, PA protocol을 적용하면 SMD를 제외하고는 기존 모델의 성능을 능가하는 것을 알 수 있다.
-
본 실험 결과는 모든 Dataset에서 F1 score가 대부분 Case2와 Case3보다 낮으며 현재 제안된 방법들이 Baseline으로 삼은 Case3에 비해 미미한 성능 상승을 불러오거나 전혀 개선되지 않았을 수 있는 가능성을 내포한다.
Effect of PA%K Protocol
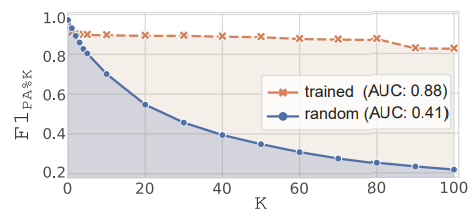
- PA%K가 PA의 과대평가 효과와 F1 score의 과소평가 경향을 완화한다는 것을 입증하기 위해 K에 따른 변화를 관찰하였다. K는 0에서 100까지 10 단위로 변경하였고, Case 1의 anomaly score와 완전히 학습된 AE를 활용하여 SWaT data에 대해 PA%K protocol을 활용한 F1 score를 측정하였다. K = 0 일때는 F1PA의 결과와 같고, K = 100 일때는 F1의 결과와 같다. Case1의 F1PA%K가 K가 증가할수록 급격히 감소하는 것으로 보아 PA protocol의 과대평가를 완화하는 것을 알 수 있고, 완전히 학습된 AE의 F1PA%K가 K에 변화함에도 급격한 성능하락이 없는 것으로 보아 F1 score의 과소평가 경향을 완화한다고 말할 수 있다.
Discussion
- 본 논문에서는 기존의 Time-series Anomaly Detection 평가방식이 두가지 측면에서 함정이 있음을 보인다.
- Point Adjustment가 성능을 과대평가하기 때문에 F1PA가 더 높은 모델이 실제로 더 나은 성능을 가지고 있다고 보장할 수 없다.
- 결과가 Baseline이 아닌 기존 모델들과만 비교되었다.
- 논문의 저자들은 향후 Time-series Anomaly Detection 평가를 위한 몇 가지 방향을 제안한다. 성능이 과대평가되는 것을 방지하기 위해서는 정확한 Labeling이 근본적인 해결책이지만 이는 막대한 비용이 소요된다. 따라서 F1PA%K는 Dataset의 수정 없이도 과대평가를 완화할 수 있는 좋은 대안이 될 수 있다.
Conclusion
- 본 논문에서는 Point Adjustment를 적용하면 Time-series Anomaly Detection 모델의 성능이 심각하게 과대평가되어 실제 모델링 성능을 반영할 수 없다는 사실을 지적하였다. 또한, Time-series Anomaly Detection Task에 대한 새로운 Baseline을 제안하였으며, 이와 관련하여 유의미한 발전을 이룬 기존 모델은 몇 가지에 불과하다는 것을 보였다. PA의 과대평가를 완화하기 위해 PA%K protocol을 제안하였다.
개인적인 생각
- 평소 시계열 이상 탐지 모델의 성능을 평가하는데 활용되는 Point Adjustment 방법론에 대해 회의적인 편이었는데 이를 지적한 논문이어서 매우 흥미롭게 읽었다. 다만, 새로운 Baseline으로 제안한 구조에 대한 근거가 제시된게 없어서 아쉬웠고, 기존모델들의 성능을 PA%K protocol로 계산하여 정리한 표가 없어서 새롭게 제안된 protocol의 효과를 비교해볼 수 없는 점에서 한계가 있는 논문인 것 같다.
