XAI(Explainable Artificial Intelligence)
🔍 XAI가 뭔가요?
설명 가능한 인공 지능(xai)은 사용자가 머신 러닝 알고리즘으로 생성된 결과와 출력을 이해하고, 신뢰할 수 있게 하는 일련의 프로세스와 방법입니다.
🌟 설명 가능한 AI(XAI)라는 개념은 왜 나왔나요?
⬛ DEEP NEURAL NETWORK의 BLACK BOX
여러 머신 러닝 기법 중에서 현재 우리 주변에서 가장 많이 사용되고 좋은 결과를 내놓는 건 딥러닝 네트워크입니다. 딥러닝 네트워크는 우리에게 엄청난 결과를 내놓지만 우리가 알 수 있는 건 결과 뿐입니다. 특히 요즘은 거대한 모델들이 우후죽순으로 등장하면서 모델들이 더 복잡해지고 있지요! 우리는 기본적으로 왜 이런 결과가 나왔는지 궁금해 하기도 하지만 결과만 잘 나온다면 궁금해 하지 않아도 될지도 모르겠다는 생각을 하기도 합니다.
우리는 Chat GPT가 처음 나왔을 때부터 엄청나게 많이 사용했죠. 결과가 잘 나오는 거 같으니까요. 이해하기에는 모델이 너무 크고 기술에 익숙하지도 않아서 어떻게 그리고 왜 이런 결과가 나오는지 알 수 없지만 지금도 궁금한 게 생기면 잘 사용하고 있지요. 이는 여기서 잘못된 결과를 얻더라도 크게 책임질 일이 없기 때문에 가능합니다. 물론 수업 시간에 사용하다가 과제 결과가 나쁘면 영향이 클지도?😋
하지만 자율 주행 차량에 들어가는 모델이나, 어떤 병을 진단하는 모델이라면 어떨까요? 아무 이유도 모른 체 모델이 잘못된 결론을 냈고, 차량 사고가 난다 거나 병을 진단하지 못해 사람이 죽기라도 한다면 우리는 그 책임을 누구에게 물어야 할까요? 모델을 만든 회사일까요? 데이터를 모은 사람일까요? 아니면 오류가 일어날 수도 있음을 알고도 사용한 고객의 잘못일까요?
이런 위험을 타파하고자 나온 것이 XAI입니다. 또한 결과가 도출된 과정을 설명하여 더 많은 사람들이 인공지능을 신뢰할 수 있는 우리 주변의 것이라고 생각할 수 있도록 신뢰성을 높여주는 기능을 할 수도 있습니다.
⚠️ AI의 오류
인공지능이 언제나 완벽한 결과만 내놓는다면 우리는 굳이 XAI같은 개념을 내놓지 않아도 될지 모릅니다. 하지만 인공지능도 많은 오류를 범하지요. 우리가 잘 알고 있는 할루시네이션이 그 대표적인 예시가 될 거에요. Chat GPT는 없는 사실을 마치 있는 것처럼 그럴듯하게 대답합니다. 우리는 GPT가 왜 이런 말을 하는지 알지 못해요. 그래서 고치기도 힘들죠.
다른 예시를 들어볼까요?

왼쪽의 판다 이미지는 분류 모델이 57%로 판다라고 분류했어요. 하지만 특정 노이즈를 더해주자 오른쪽에 우리 눈에는 판다로 보이는 이미지가 모델이 분류했을 때는 긴팔원숭이로 분류했습니다.
ONE-PIXEL ATTACK

어떤 한 이미지에 한 픽셀 값만 바꿔서 모델에 집어 넣었더니 분류 모델은 완전히 다른 결과를 내놓습니다.
이런 인공지능의 오류는 때로 사회적 문제를 안겨줄 수도 있고, 특정 목적을 품은 이들에 의해 오용 될 수 있습니다. 모델이 왜 이런 결과를 냈는지 알 수 없다면 우리는 이 결과를 맹목적으로 신뢰하거나 신뢰하지 않거나 둘 뿐입니다. 만약 이유를 설명할 수 있다면 우리는 모델을 고칠 수도 있고 공격자로부터 대응할 수 있습니다.
☀️ 그럼 XAI를 이용하면 어떤 점이 좋을까요?
위에서 말한 거처럼 인공지능의 내부는 블랙박스입니다. 알 수 있는 게 결과 뿐이죠. 우리가 나중에 어떤 모델을 만들었다고 생각해보죠. 처음에는 이 모델이 잘 작동한다고 생각하고 배포까지 마쳤다고 생각해봅시다. 그런데 이런! 어떤 한 가지 오류로 인해서 모델을 고쳐야만 하게 됐습니다. 우리는 이런 상황에서 어떤 대처를 할 수 있을까요? 아마도 우리는 모델 자체를 다시 만들거나 배포를 포기해야만 하게 될 겁니다.
XAI는 이런 부분에서 해결책을 제시해줍니다. 모델의 오류를 진단하고 원인을 제시할 수 있게 되는 겁니다. 이런 장점은 우리 같은 인공지능을 공부하는 사람들에겐 아주 중요한 내용입니다. 인공지능의 유지 보수가 가능해지는 거죠.
좀 더 자세한 예시를 들어볼까요? 2~3년 전부터 꾸준히 올라오는 사례가 있죠. 인공지능이 인종차별을 했다는 내용의 기사의 내용을 접해본 적 있을 겁니다. (인종차별 기사) 이런 경우 보통 데이터가 편향됐거나, 모델 자체가 편향된 경우도 있습니다. 하지만 어느 부분이 편향되어 이런 문제가 발생하는 지 정확한 원인은 찾기 힘든 게 현실입니다. 이런 부분에서 XAI의 필요성이 강조됩니다. XAI를 통해 편향을 이해하고 고칠 수 있다고 학자들이 강조하곤 합니다.
또한 위에서 이야기 했던 중요한 결정을 내리는 상황에서 인공지능이 내놓은 결과의 이유를 설명할 수 있게 됩니다. 사람들이 결과의 원인을 세밀하게 알 수 있게 되어 모델의 신뢰도가 상승하죠. 책임 소재도 명확해질 겁니다.
🔍 XAI는 어떻게 작동하는 걸까요?
XAI는 설명 가능한 인공지능을 포괄하는 개념입니다. 여러가지 기법들이 XAI의 분류 기준에 들어갑니다. 이 중에서 제가 가장 이해하기 쉬웠던 기법에 대해 간략하게 설명할까 합니다.
Saliency Map

Computer Vision 분야에서 논문을 읽다 보면 가끔 위와 같은 이미지들이 있습니다. 이는 모델이 어떤 부분에 집중하면서 정보를 처리하는지 알아보기 쉽게 표현해 줍니다. Saliency map은 모델이 집중하는 곳을 알 수 있는 기법입니다.
Saliency map은 다른 영역에 비해서 픽셀 값의 변화가 급격한 부분을 모아서 맵핑한 후에 관심 있는 배경과 분리하는 방법입니다. 이 기법은 Gradient Descent를 사용하여 변화가 큰 부분을 찼습니다. 즉, 모델이 결과를 내는데 있어서 중요하게 생각하는 부분의 픽셀을 강조하여 보여줄 수 있습니다.
🆕 XAI의 최신 근황

현지 시간 2024.1.13 MIT CSAIL연구진이 사전 훈련된 언어 모델로 구축한 AIA(자동 해석 에이전트)를 활용하여 신경망 동작을 자율적으로 실험하고 설명하는 새로운 AI 방법을 제안했다고 합니다. 언어모델이 개입하여 AI가 작동하는 과정을 사람이 이해할 수 있도록 자연어나 코드로 생성한다는 내용입니다.
MIT 연구진은 일종의 ‘통역사’로 언어모델을 도입했다고 합니다. AIA는 인간 과학자가 하는 것처럼 신경망 해석을 위한 가설 형성과 실험 테스트, 반복 학습에 참여합니다. 이 과정에서 개별 뉴런부터 전체 모델이 동작하는 과정을 자연어와 실행 코드 등 사람이 이해할 수 있는 형식으로 생성해 내는 것입니다. 'GPT-4'와 같은 복잡한 모델이 수행한 엄청난 양의 계산을 일괄적으로 처리할 수 있게 만들었다고 합니다. 특히 AIA는 독립적으로 가설을 생성하고 테스트하는 과정에서 인간 과학자가 놓치기 쉬웠던 미묘한 패턴을 찾아내는 등 놀라운 능력을 보여줬다고 합니다.
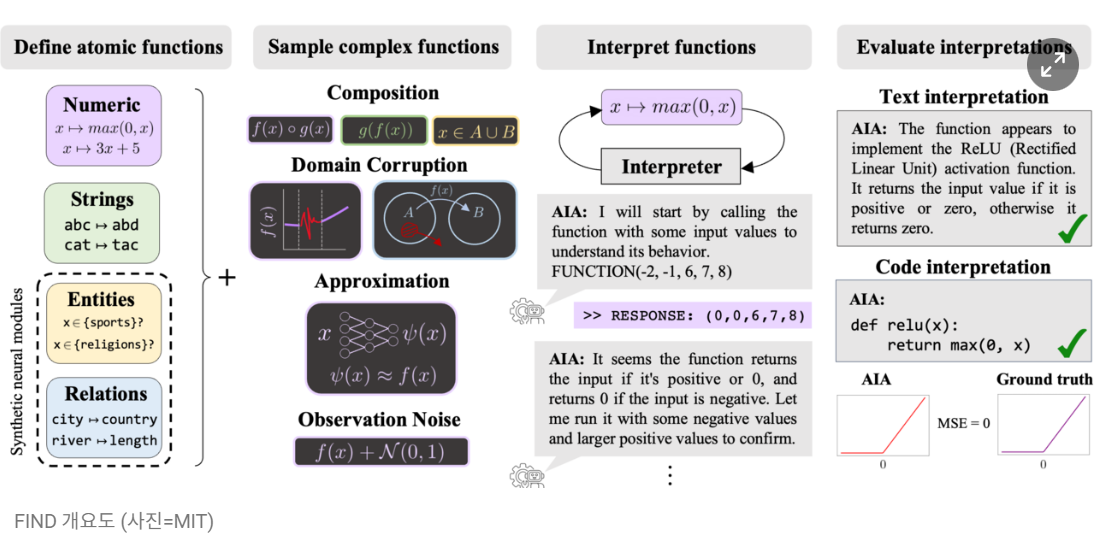
물론 모든 초기 연구가 그렇듯이 검증된 결과인지는 지켜봐야 할겁니다.
궁금한 점
XAI에 대해 처음 접한 건 제가 들어가 있는 인공지능 관련 오픈카톡에서 처음 보고 새로운 모델인가? 하고 찾아본 게 이렇게 글을 쓰게 됐습니다. 인공지능을 설명하려는 노력이 중요하다는 건 이해하고 충분히 공감이 갔습니다. 그런데 최신 근황 기사를 보면서 이렇게 인공지능을 설명하는데 있어서 새로운 인공지능을 도입하는 것이 맞는 방법론인가? 라는 의문점이 들었습니다. 인공지능의 블랙박스를 설명하기 위해 새로운 블랙박스를 제시하는 건 아닌지, 뭔가 순환 논리의 오류인 거 같다는 생각을 지울 수가 없었습니다. 논문을 자세히 읽어본 건 아니라서 이들이 어떤 방법을 이용하여 새로운 기술을 제시했는지 모르겠습니다.
여러분은 어떻게 생각하시나요? 의견 달아주세요.
긴 글 읽어주셔서 감사합니다.!
새로운 내용이 있으면 다시 찾아뵙겠습니다. 😀
REFERENCE
- https://www.aitimes.com/news/articleView.html?idxno=156532
- https://arxiv.org/abs/2006.11371
- https://www.youtube.com/watch?v=Grc7egfZP84
- https://www.youtube.com/watch?v=U43fxbC-4JQ!
작성자 : 손봉국
