AID 내부 칼럼 중 공동 1위를 한 NLP 기초 스터디 팀의 칼럼입니다.
저희 NLP 기초 스터디에서는 ChatGPT를 시작으로 자연어 처리(NLP)에 관심을 가지게 된 분들이 많습니다. 이는 다른 분들도 마찬가지일 것으로 보이며, GPT를 직접 사용해 본 경험이 있는 분들이 거의 대부분일거라 생각합니다. 최근 들어 다양한 생성형 AI가 등장하고 있지만, 여전히 가장 널리 알려진 것은 GPT라는 점을 부인하기 어렵습니다. 오늘은 GPT의 역사와 각 버전의 작동원리, 그리고 앞으로의 발전 방향에 대해 알아보는 칼럼을 준비했습니다.
GPT-1
먼저 GPT-1 부터 시작해보도록 하겠습니다.
GPT란 무엇인가?

GPT는 Generative Pre-Training of a language model의 약자입니다. GPT를 이해하기 위해 이름에 또렷이 나타나는 이 세 가지 컨셉을 알아보고 시작하겠습니다.
첫째, Language Model (언어 모델) 입니다.
Language model은 현재 알고 있는 단어들을 기반으로 다음 단어를 예측하는 데 많이 사용되는 모델입니다. 쉬운 예제로 검색창에 단어를 입력하다보면 다음 단어가 미리 예측되는 것을 보신 적이 있으실겁니다.
Deep learning Tutorial 을 검색하려고 Deep learning이라는 단어를 입력했을 때 검색 키워드를 미리 띄워주는 language model이 사용될 수 있습니다. 많은 단어를 입력할 수록 제가 원하는 값을 잘 예측해줍니다. 이 정도면 훌륭한 language model이라 할 수 있겠습니다.

GPT가 언어 모델(Language Model)을 사용하는 이유
이제 GPT가 왜 언어 모델(Language Model)을 사용하는지에 대해 살펴보겠습니다. 언어 모델의 가장 큰 장점 중 하나는 데이터에 별도의 레이블링(labeling)이 필요하지 않다는 점입니다. 전통적인 자연어 처리(NLP) 머신러닝 모델들을 떠올려보면, 대부분 레이블이 부착된 학습 데이터를 요구합니다. 이러한 레이블링 과정은 사람이 직접 데이터를 태깅(tagging)해야 하기 때문에 상당한 비용과 시간이 소요됩니다. 더군다나, 사람이 만든 레이블링 결과도 완벽히 정확하지 않을 가능성이 높습니다.
반면, 언어 모델은 이러한 레이블링 과정을 필요로 하지 않습니다. 언어 모델의 기본 학습 메커니즘은 "현재 단어를 기반으로 다음 단어를 예측하는 것"에 기반하기 때문입니다. 즉, 기존에 존재하는 대규모 텍스트 데이터를 활용해 학습할 수 있으며, 별도로 사람을 고용해 레이블링을 진행할 필요가 없습니다.
특히 방대한 양의 텍스트 데이터를 학습에 활용하면 모델의 오류가 줄어들 뿐 아니라, 우리가 이미 알고 있는 자연어의 특성뿐만 아니라 미처 알지 못했던 특성까지도 학습하게 됩니다. 이러한 학습 방식은 GPT-1의 핵심 아이디어 중 하나이며, 이를 통해 뛰어난 자연어 처리 성능을 가진 모델을 개발할 수 있는 토대를 마련했습니다.

두 번째 컨셉으로 넘어가보겠습니다.
GPT의 G, Generative Training의 의미
GPT에서 "G"는 Generative Training을 의미합니다. 머신러닝 학습 방법을 크게 두 가지로 나눌 수 있다면, Generative Model 학습과 Discriminative Model 학습으로 구분할 수 있습니다. GPT가 채택한 언어 모델 학습 방법은 바로 Generative Training에 해당합니다.
대부분의 사람들이 무의식적으로 더 익숙하게 사용하는 방법은 Discriminative 학습 방법입니다. 예를 들어, 타이타닉 생존 예측 문제를 생각해봅시다. 승객의 나이, 성별, 탑승 클래스 등 인적 정보를 활용해 특정 승객이 구조되었는지 아닌지를 예측하는 방식이 Discriminative 학습의 전형적인 사례입니다. Discriminative 모델은 데이터를 분류하거나 경계를 그어 특정 결과를 예측하는 데 초점을 맞춥니다.
Discriminative 모델의 원리는 입력 데이터 x와 결과 레이블 y 간의 관계를 직접 학습하는 것입니다. 이때 모델은 P(y∣x), 즉 주어진 입력 데이터 x에서 결과 y가 나올 조건부 확률을 최대화하는 데 중점을 둡니다. 이를 통해 레이블을 예측하거나 경계를 정의해 데이터를 구분합니다.
Discriminative 모델의 특징:
- 강점: 레이블 간의 명확한 경계를 학습하며, 분류 문제나 예측 문제에서 높은 정확도를 자랑합니다.
- 단점: 데이터가 제한적일 경우 특정 패턴에 지나치게 치우치는 과적합(Overfitting)이 발생할 가능성이 높습니다. 또한, 데이터의 전반적인 분포를 학습하지 않기 때문에, 새로운 데이터를 생성하거나 데이터의 구조를 심층적으로 이해하는 데는 한계가 있습니다.
예를 들어, 위 차트를 살펴보겠습니다. 두 번째 차트에서 빨간색과 파란색으로 구분된 일부 샘플 데이터가 있습니다. 물음표로 표시된 새로운 데이터가 주어졌을 때, 오른쪽 데이터만을 본다면 이 물음표는 빨간색 데이터로 분류될 가능성이 높아 보입니다. 이는 제한된 데이터로 인해 왜곡된 판단을 초래할 수 있는 상황입니다.
하지만 모든 데이터를 포함하는 첫 번째 차트를 보면, 물음표 데이터는 오히려 파란색 데이터로 분류되는 것이 더 합리적으로 보입니다. 이처럼 Discriminative 모델은 데이터를 잘못 일반화하거나 제한된 샘플에 치우치는 경향이 있어 데이터의 대표성과 범위에 민감합니다.

Generative 모델의 차별점
GPT가 채택한 Generative Training은 기존의 Discriminative 모델과는 본질적으로 다른 접근 방식을 따릅니다. 이 두 가지 모델은 학습 대상, 목적, 강점과 한계에서 뚜렷한 차이를 보입니다.
먼저, 학습 대상에서 차이가 나타납니다. Discriminative 모델은 P(y∣x), 즉 입력 x가 주어졌을 때 결과 y가 나올 조건부 확률을 학습합니다. 이 과정은 데이터 간의 경계를 정의하거나 특정 레이블을 예측하는 데 초점을 맞춥니다. 예를 들어, 이메일이 스팸인지 아닌지를 분류하거나, 사진 속에 특정 객체가 포함되어 있는지 판별하는 작업이 Discriminative 모델의 대표적인 응용 사례입니다.
반면, Generative 모델은 P(x,y), 즉 입력 x와 결과 y의 공동 확률 분포를 학습하거나, 데이터 자체의 분포 P(x)를 학습합니다. 이는 데이터의 생성 과정을 모델링할 수 있음을 의미하며, 단순히 데이터를 분류하는 것을 넘어 새로운 데이터를 생성하거나 데이터의 전체적인 패턴을 이해하는 데 활용됩니다. 예를 들어, GPT는 텍스트 데이터를 학습한 후 이를 기반으로 새로운 문장을 생성할 수 있는 능력을 갖춥니다.
이러한 차이는 두 모델의 목적에서도 명확히 드러납니다. Discriminative 모델은 주로 분류, 예측 등 경계를 학습하는 데 초점을 맞추는 반면, Generative 모델은 새로운 데이터를 생성하거나 데이터의 패턴을 학습하는 데 중점을 둡니다. 전자의 목적이 "결과를 정확히 예측"하는 것이라면, 후자는 "데이터의 본질적 구조를 이해하고 활용"하는 데 있습니다.
강점과 한계 또한 양측의 중요한 구분점입니다. Discriminative 모델은 명확한 경계를 정의하고 높은 예측 정확도를 제공하는 강점을 가지고 있습니다. 하지만 데이터 생성에는 적합하지 않으며, 데이터가 부족할 경우 과적합(Overfitting) 문제가 발생할 가능성이 높습니다
이에 비해 Generative 모델은 데이터의 분포를 학습하여 새로운 데이터를 생성하는 능력을 갖추고 있지만, 대규모 데이터와 높은 계산 자원이 필요하며, 분류 문제에서 예측 정확도가 Discriminative 모델보다 낮을 수 있습니다.
GPT는 이러한 Generative Training 방식을 채택하여 대규모 텍스트 데이터를 학습하며 자연어의 문맥과 패턴을 효과적으로 이해하고, 이를 기반으로 새로운 텍스트를 생성할 수 있습니다. Discriminative 모델이 단순히 결과를 예측하는 데 그치는 것과는 달리, GPT는 데이터를 생성하고, 문맥을 이해하며, 새로운 패턴을 학습할 수 있다는 점에서 차별화됩니다. 이는 GPT가 자연어 처리(NLP)에서 다양한 문제를 해결하는 데 유리한 기반을 제공하며, 단순한 분류를 넘어선 혁신적인 모델로 자리 잡을 수 있었던 이유이기도 합니다.
GPT의 P, Pre-Train의 중요성
다음 컨셉은 GPT의 P에 해당하는 Pre-Train입니다.
GPT는 단순히 Language Model에 그치지 않습니다.

GPT-1은 등장과 함께 Natural Language Inference(자연어 추론), Question Answering(질의응답), Semantic Similarity(문장 유사도), Classification(분류) 등의 다양한 자연어 처리(NLP) 작업에서도 뛰어난 성능을 입증했습니다. 이처럼 GPT는 단순한 언어 모델을 넘어, 폭넓은 자연어 처리 능력을 가진 모델로 주목받게 되었습니다.

GPT-1의 핵심은 Language Model 학습 방법에 기반을 둡니다. 엄청난 양의 텍스트 데이터를 학습해 자연어 처리 능력을 갖춘 모델을 만들어내는 것이 이 접근법의 핵심입니다. 기존의 자연어 처리 모델은 특정 작업을 수행하기 위해 추가적인 딥러닝 구조나 복잡한 전처리를 필요로 했지만, GPT-1은 별도로 추가적인 구조를 붙일 필요 없이 간단한 파인 튜닝(Fine-Tuning)만으로 다양한 작업에 활용할 수 있다는 점에서 혁신적이었습니다. 이는 기본 모델이 이미 뛰어난 자연어 처리 능력을 보유하고 있다는 점을 증명합니다.
GPT-1의 두 단계 학습 과정
GPT-1은 두 단계 학습 과정을 거칩니다. 첫 번째 단계는 Pre-Training이며, 두 번째 단계는 Fine-Tuning입니다.
-
Pre-Training
Pre-Training 단계에서는 대규모 텍스트 데이터를 사용하여 Language Model로서의 기본 능력을 학습합니다. 이 단계에서 GPT는 방대한 언어 데이터를 바탕으로 텍스트 생성, 문맥 이해, 패턴 학습과 같은 기본 능력을 습득하게 됩니다. Pre-Training은 Fine-Tuning을 위한 기초 작업으로, 이후 추가 작업 없이도 모델이 높은 성능을 발휘할 수 있는 기반을 제공합니다.
-
Fine-Tuning
Fine-Tuning 단계에서는 특정 작업(예: 문장 분류, 질의응답)에 맞춰 Pre-Training된 모델을 조정합니다. 이 단계에서는 비교적 적은 양의 데이터를 사용하며, 특정 도메인이나 과업에 맞는 추가 학습을 수행합니다. Pre-Training이 이미 완료된 상태이기 때문에 Fine-Tuning은 빠르고 효율적으로 진행됩니다.
먼저 왜 GPT가 트랜스포머 디코더를 Main Design으로 삼았는지 알아보기 이전에 트랜스포머가 무엇인지 간단히 알아보고 가도록 하겠습니다.
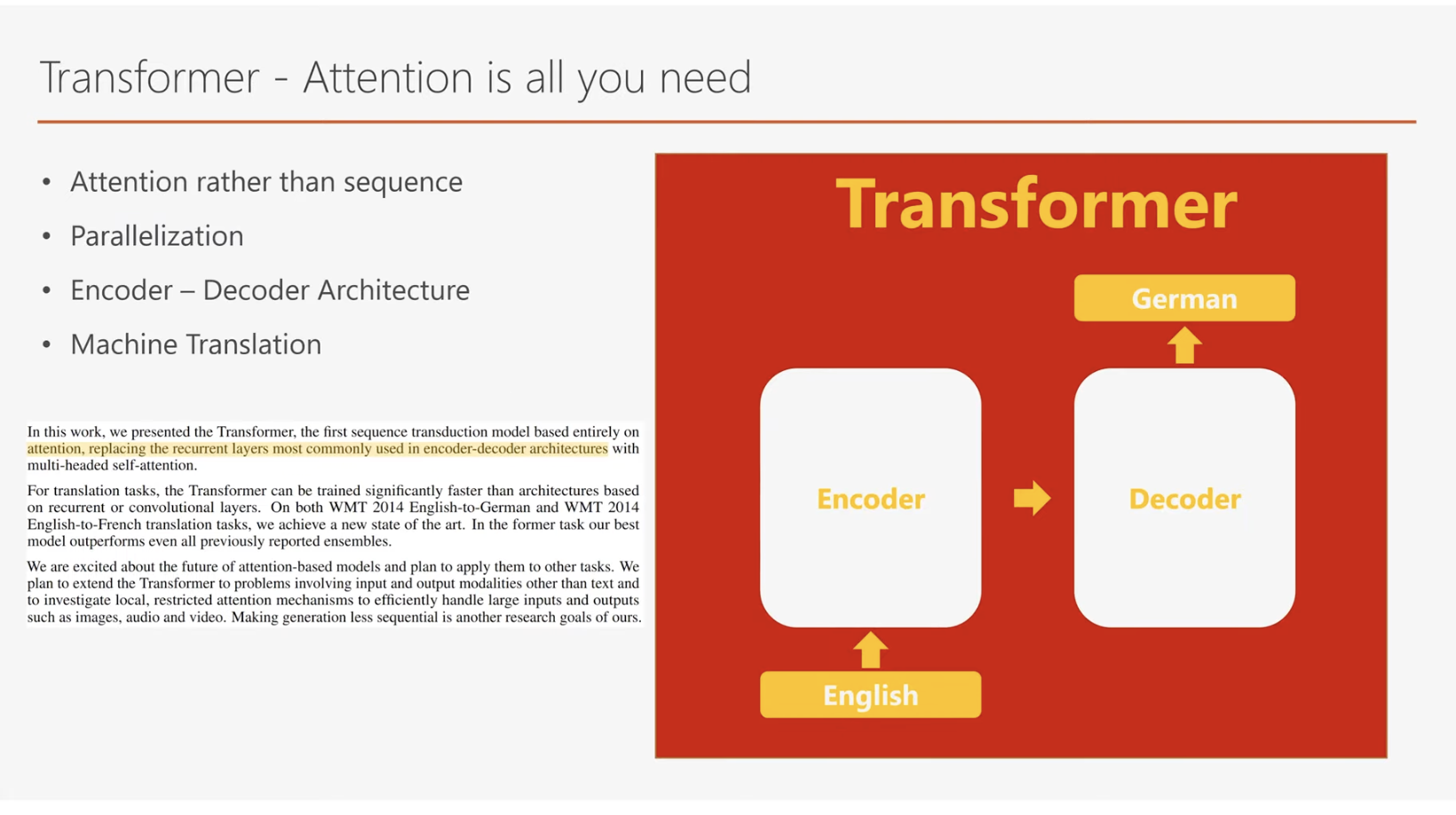
트랜스포머와 기본 구조
트랜스포머는 Attention is All You Need에서 소개된 딥러닝 모델로, 기존의 번역 모델들이 주로 사용하던 RNN 대신 Attention Mechanism을 기반으로 설계되었습니다. RNN은 입력된 데이터를 순차적으로 처리해야 하기 때문에 입력 시퀀스의 길이가 n일 경우, 연산이 n번에 걸쳐 진행되며, 연산 시간은 히든 레이어의 크기 및 행렬 연산 복잡도에 따라 달라집니다. 반면, Attention Mechanism은 입력 문장 내 모든 단어 간의 관계를 병렬로 계산하므로 연산 속도가 훨씬 빠릅니다. 이는 RNN이 가지고 있던 순차 처리의 병목 현상을 해결하며, 긴 문장에서도 효율적인 처리를 가능하게 합니다.
트랜스포머는 이러한 Attention Mechanism을 통해 기존 RNN의 순차적 구조를 대체하면서도, 번역 모델에서 자주 사용되던 Encoder-Decoder Architecture는 유지했습니다. 이러한 혁신 덕분에 트랜스포머는 영어-독일어와 영어-프랑스어 번역 작업에서 최고 성능을 기록하며 주목받았습니다.
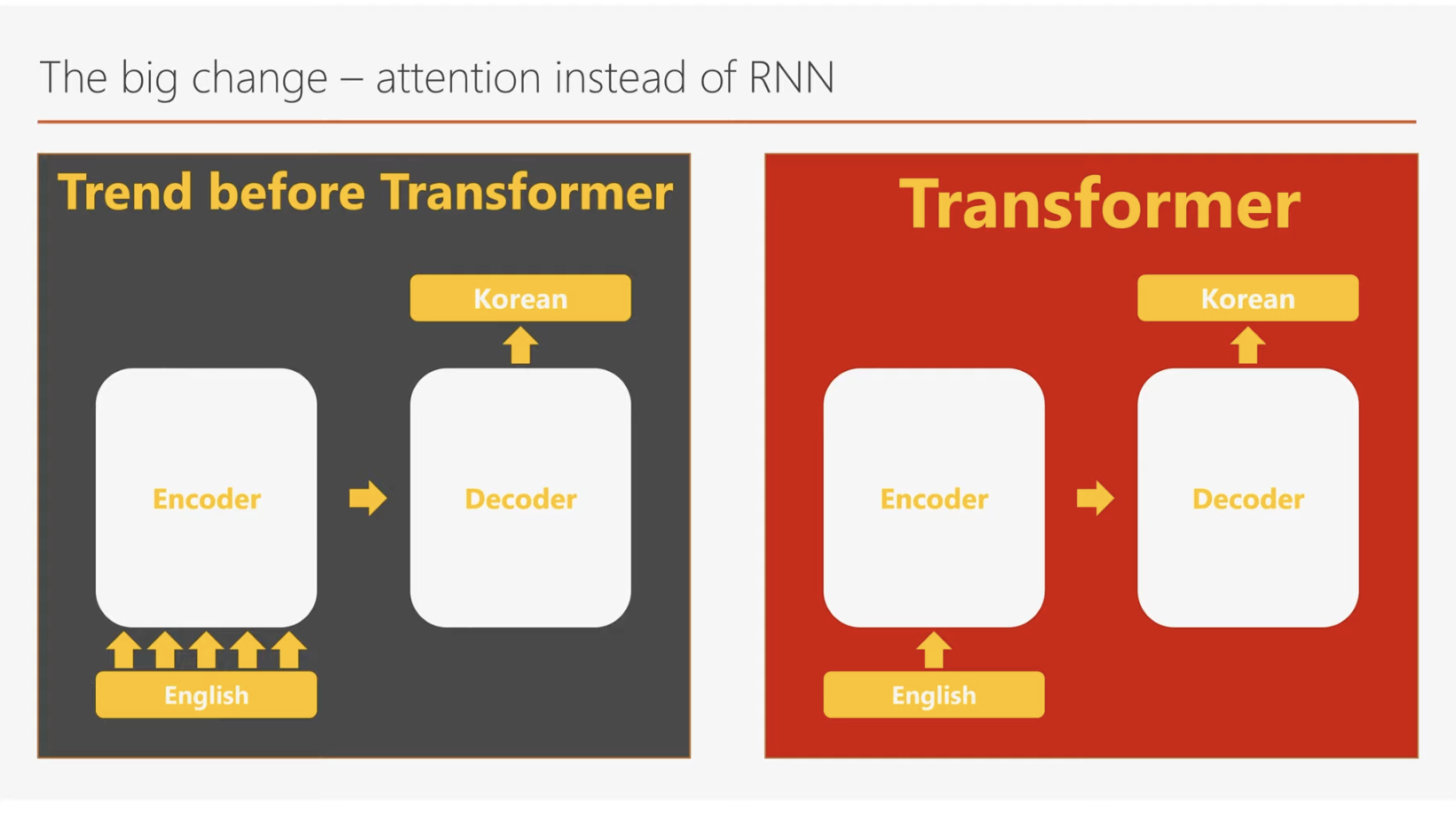
트랜스포머와 기존 RNN 모델의 차이
기존 모델들과 트랜스포머의 가장 큰 차이는 바로 Attention Layer의 도입입니다. 이전에는 Encoder-Decoder 구조에서 주로 RNN이 사용되었지만, 트랜스포머는 RNN의 순차적 처리 방식을 과감히 Attention Mechanism으로 대체했습니다. Attention Layer는 모든 단어 간의 상호 연관성을 한 번에 계산할 수 있어 병렬 처리와 빠른 연산이 가능하며, RNN의 한계로 꼽히던 장기 의존성(Long-Term Dependency) 문제를 해결합니다.
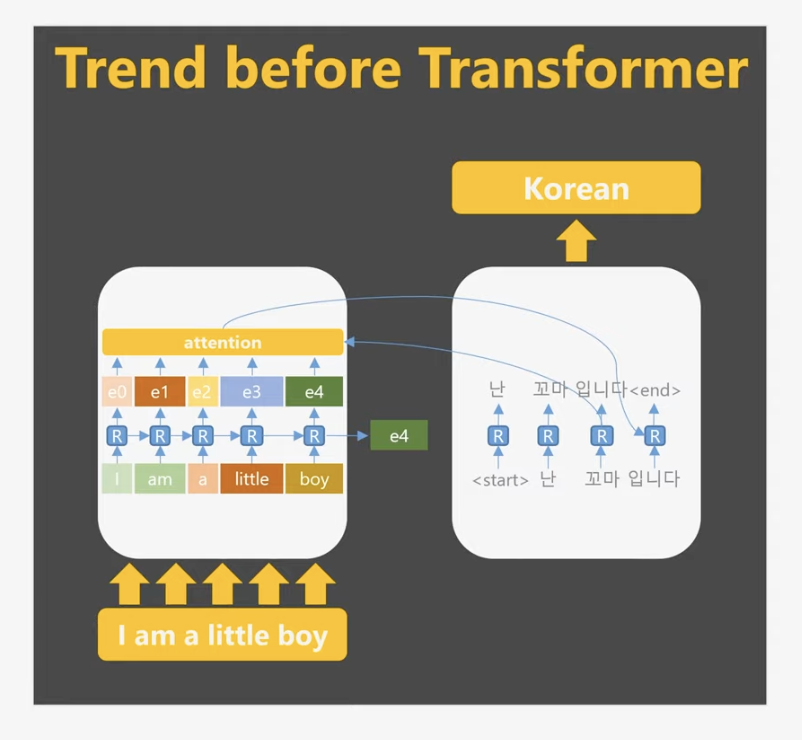
기존 RNN 기반 Encoder-Decoder 구조의 작동 방식
인코더(Encoder)의 작동원리
기존 RNN 기반 Encoder-Decoder 구조는 데이터를 순차적으로 처리합니다. 첫 번째 토큰이 입력되면 RNN은 이를 처리해 첫 번째 출력값을 생성합니다. 이후 두 번째 토큰이 입력되면, 이전 출력값과 함께 계산되어 새로운 출력값이 생성됩니다. 이 과정은 모든 토큰에 대해 반복되며, 마지막 토큰까지 처리한 후 최종 출력값이 생성됩니다.
RNN의 장점은 이전 출력값을 고려하여 현재 출력값을 결정할 수 있다는 점으로, 이는 사람이 문장을 순서대로 읽으며 문맥을 이해하는 방식과 유사합니다. 그러나 이러한 순차적 처리 방식은 효율성이 떨어지고, 문장이 길어질수록 초반 단어의 의미가 희미해지는 한계를 가지고 있습니다.
디코더(Decoder)의 작동 원리
디코더는 RNN 셀(RNN cell)을 사용해 인코더에서 생성된 출력값(히든 상태)을 활용하여 출력을 생성합니다. 디코더의 첫 번째 단계에서는 시작 토큰(start token)과 인코더의 최종 히든 상태가 결합되어 초기 출력을 생성합니다. 이후 출력값은 다음 단계의 디코더 RNN 셀로 전달되며, 이 과정은 종료 토큰(end token)이 출력될 때까지 반복됩니다.
이처럼 디코더의 기본 작동 원리를 이해하면, 트랜스포머(Transformer)가 기존의 인코더-디코더 구조를 어떻게 발전시켰는지 파악하는 데 충분한 기반이 됩니다.
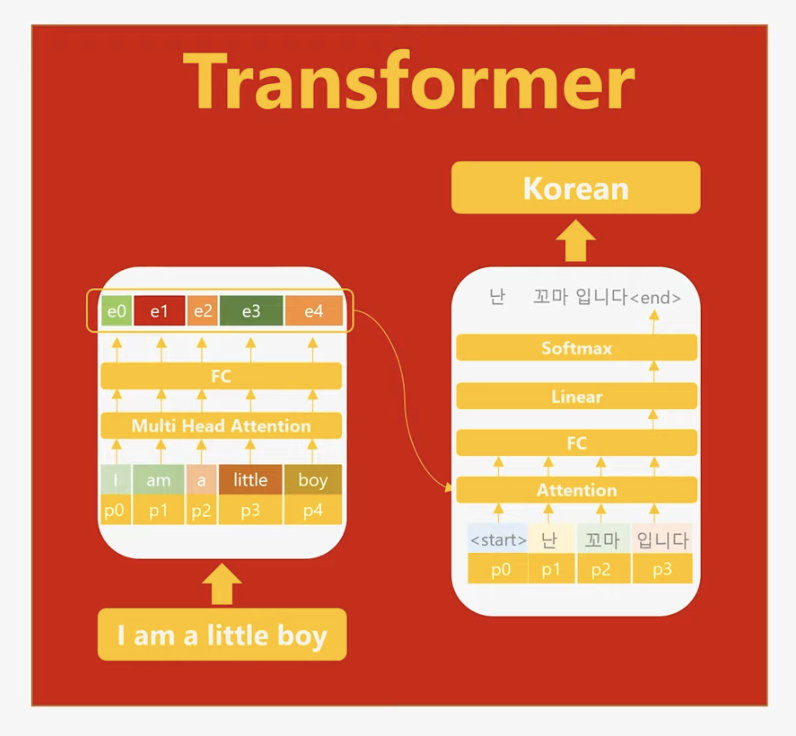
트랜스포머의 차별화된 설계
트랜스포머는 기존의 인코더-디코더 구조와 달리 RNN을 완전히 제거하고, 병렬 연산이 가능한 Attention Mechanism만을 활용합니다. 순차적 처리 과정을 생략하면서도 각 단어의 위치 정보를 유지하기 위해 포지셔널 인코딩(Positional Encoding)을 도입했습니다. 포지셔널 인코딩은 단어의 위치를 수치로 표현하여 모델이 단어 간 순서를 이해할 수 있도록 돕습니다. 위의 그림에서 p0,p1,…,p4로 나타난 요소들이 이를 나타냅니다.
트랜스포머는 멀티헤드 어텐션(Multi-Head Attention)을 활용하여 여러 방향으로 주의를 분산시키며, 풍부한 문맥 정보를 학습합니다. 또한, 스킵 커넥션(Skip Connection)을 통해 입력 데이터의 정보를 상위 층으로 효과적으로 전달해 정보 손실을 방지하고, 기울기 소실(Gradient Vanishing) 문제를 완화하여 안정적인 학습이 가능하게 합니다.
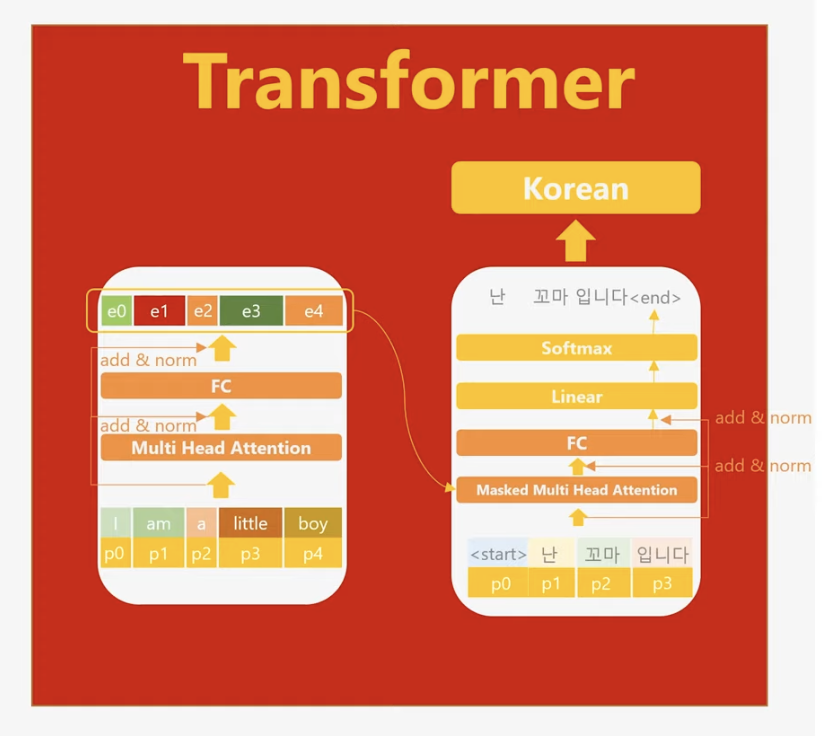
위 그림에서 확인할 수 있듯이, 모델 구조에는 스킵 커넥션(skip connection)이 존재합니다. 이는 모델 설계에서 두 가지 주요 장점을 제공합니다.
첫째, 상위 층(layer)으로 갈수록 입력 토큰의 원래 의미가 점차 희석되는 경향이 있습니다. 스킵 커넥션은 하위 층에 존재하는 입력 토큰의 의미를 상위 층으로 효과적으로 전달하여 정보 손실을 줄이는 역할을 합니다.
둘째, 딥러닝 모델의 층이 깊어질수록 기울기 소실(Gradient Vanishing) 문제가 발생하여 학습 효율성이 저하될 가능성이 큽니다. 그러나 스킵 커넥션은 상위 층에서 발생한 기울기(gradient)를 하위 층까지 효율적으로 전달함으로써 학습 안정성을 높이고, 층이 많은 딥러닝 모델에서도 효과적인 학습이 가능하도록 돕습니다.
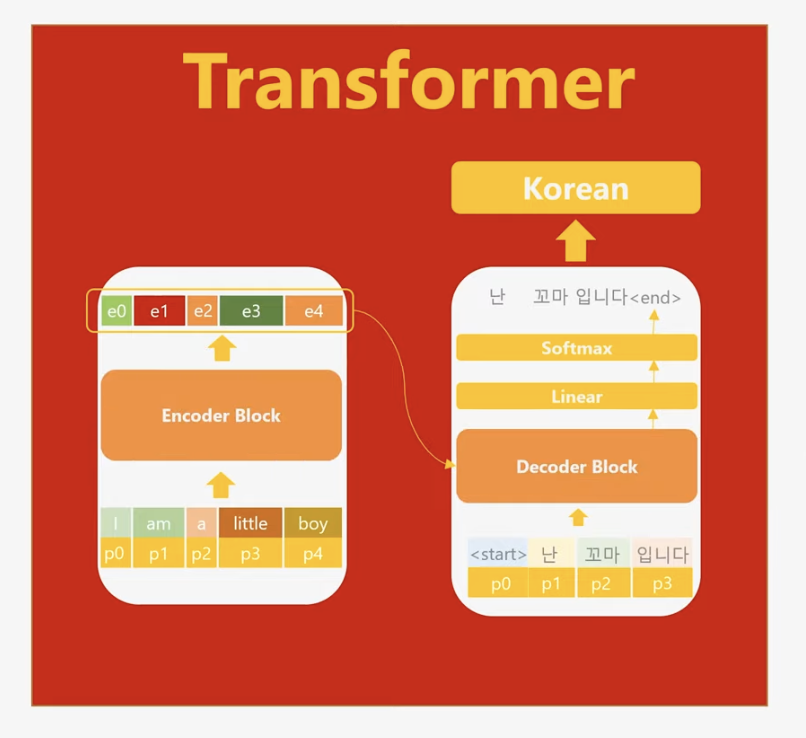
인코더 안에 multi-head attention과 fully-connected layer을 합쳐서 인코더 block이라고 불리고 디코더 안에 있는 동일한 set은 디코더 block 이라 부릅니다.
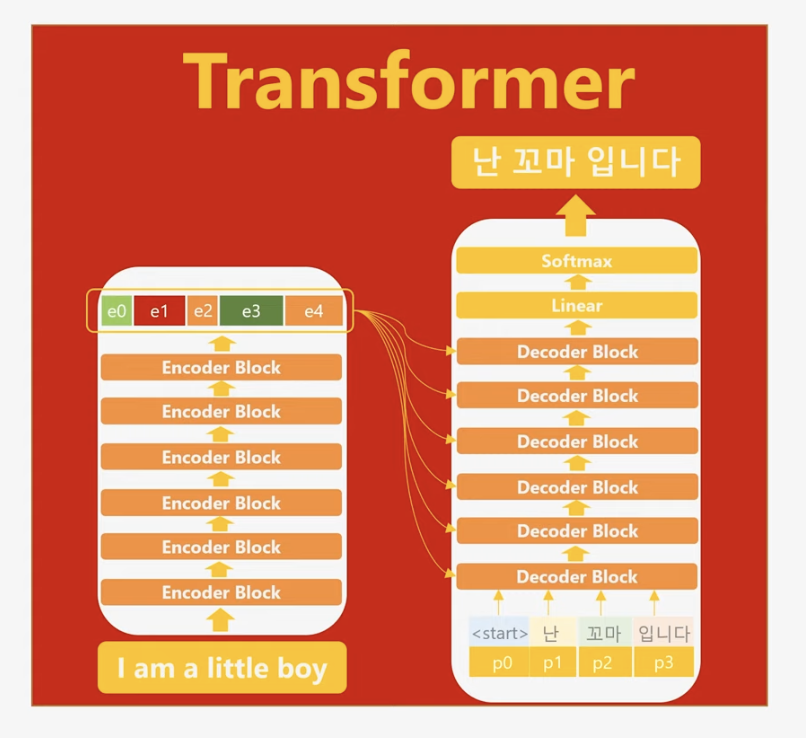
논문에서는 인코더와 디코더의 각각의 block이 6개씩 존재합니다.
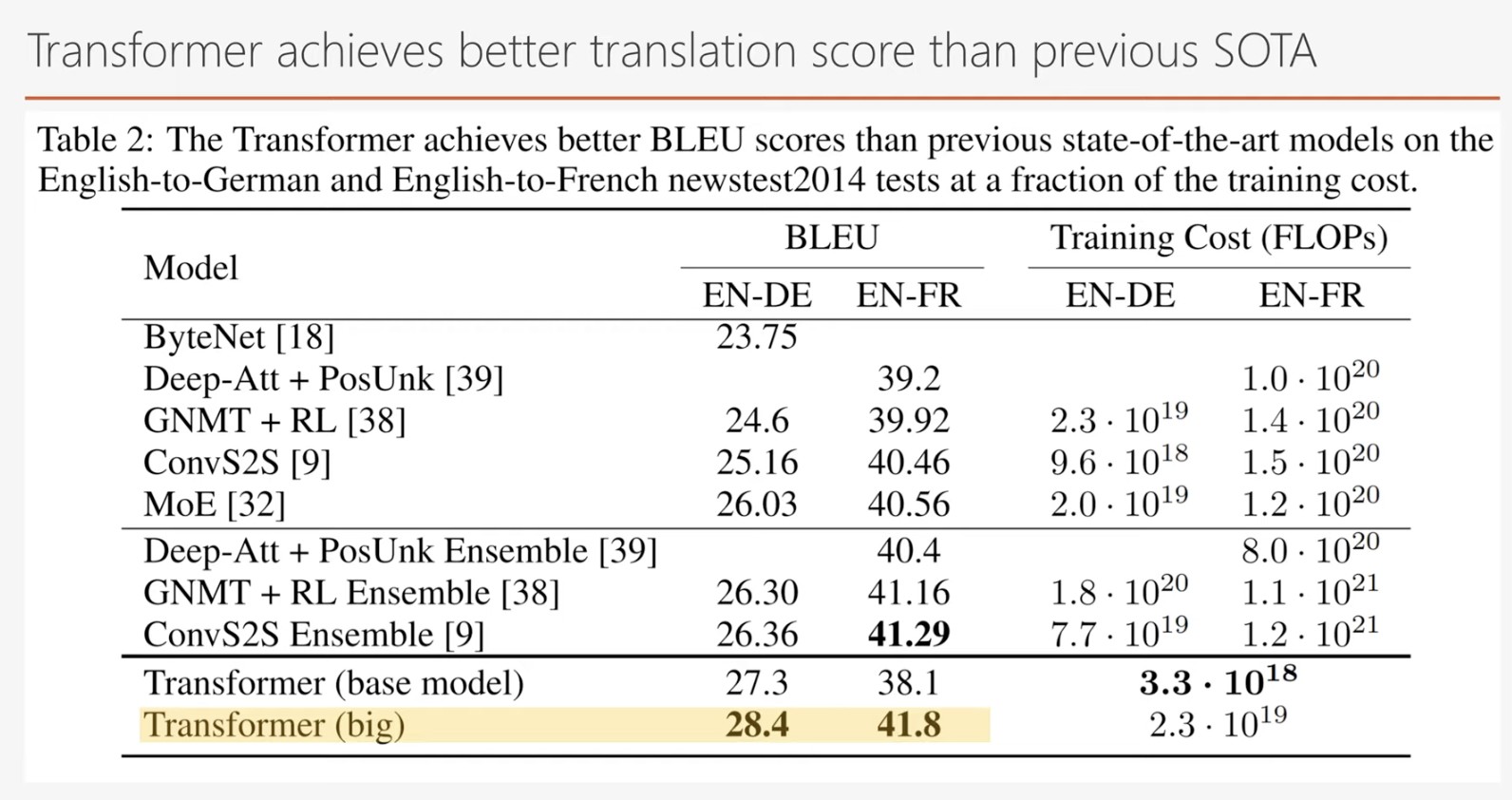
트랜스포머는 기존 기계어 번역의 최고 점수를 갱신하게 되고 현재에도 많은 자연어 처리 딥러닝 모델들이 이 트랜스포머에서 파생되어서 다양한 자연어 처리 문제를 해결하고 있습니다.

트랜스포머의 성과와 현재 활용
트랜스포머는 기존 기계 번역 모델의 성능을 뛰어넘으며 자연어 처리의 패러다임을 바꾸었습니다. 연구원들은 이 모델이 기계 번역을 넘어 다양한 자연어 처리 문제에 활용될 수 있음을 논문에서 강조했으며, 현재 트랜스포머 기반 모델은 NLP의 핵심으로 자리 잡았습니다.
특히, 트랜스포머의 인코더 구조를 사용하는 BERT와 디코더 구조를 사용하는 GPT는 현대 NLP의 양대 산맥으로, 자연어 처리 기술의 발전을 크게 이끌고 있습니다. GPT를 이해하기 위한 트랜스포머의 설명은 이 정도로 마무리하겠습니다.

자 이제 본론으로 들어가서 GPT-1을 알아보도록 하겠습니다. 트랜스포머가 기계어 번역에 초점을 맞춘 반면에 GPT-1은 Natural Language Inference , Question Answering (질의응답), Semantic Similarity (비슷한 문장 맞추기), Classification (자연어 처리 분류)에 있어서 놀라운 성능을 보여주었습니다.

Natural Language Inference 모델은 두 문장이 주어졌을 경우에 두 문장의 관계를 유추하는 딥러닝 모델입니다.
예를 들어서 A문장이 참일 경우에 B문장이 반드시 참일 경우 이 관계를 true (entailment)라고 합니다. 또 두 문장이 모순될 경우에는 false (contradiction)이라고 합니다.
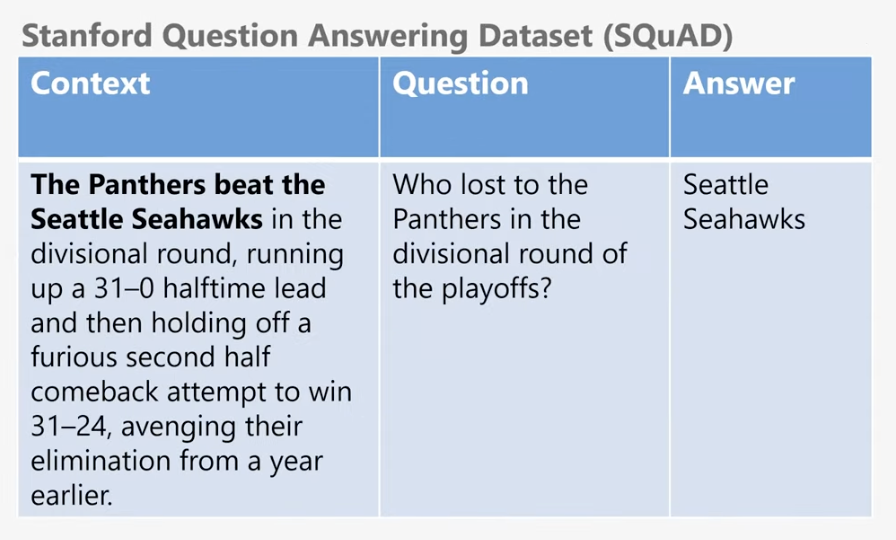
질의 응답은 딥러닝 모델에게 질문과 함께 관련된 정보를 준 후에 딥러닝 모델이 관련된 정보에서 정답을 제대로 찾는지 테스트하는겁니다.

비슷한 문장 맞추기는 두 문장이 비슷한지 아닌지 판단하는 테스트이고
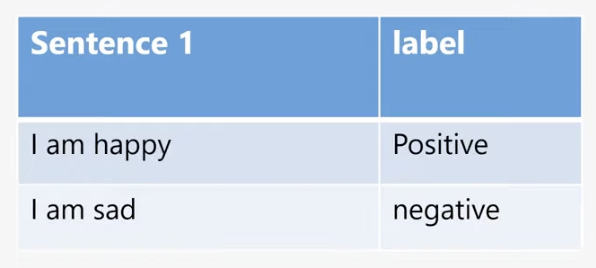
분류는 주어진 문장을 이미 정의한 어떤 그룹으로 분류하는 테스트입니다.

GPT-1의 학습 과정
GPT-1은 두 단계의 학습 과정을 통해 모델을 완성합니다.
-
Language Model 학습 (Pre-Training)
먼저 방대한 양의 레이블이 없는 텍스트 데이터를 사용해 Language Model로서의 기본 학습을 진행합니다. 이 단계는 비지도 학습으로, 모델이 텍스트의 구조와 패턴을 이해하고 문맥을 학습하도록 설계되었습니다. Language Model 학습은 단어 또는 문장을 입력했을 때, 다음 단어를 예측하는 방식으로 진행되며, 이를 통해 모델은 자연어의 일반적인 특성을 학습합니다.
-
파인 튜닝 (Fine-Tuning)
Language Model 학습이 완료된 후, 각 자연어 처리(NLP) 문제에 특화된 학습을 진행합니다. 이 단계에서는 레이블이 있는 데이터를 활용하며, 주로 지도 학습 방식으로 진행됩니다. 파인 튜닝은 특정한 NLP 과제(예: 문장 분류, 질의응답 등)에 맞게 모델의 가중치를 미세하게 조정하는 과정입니다. 이를 통해 GPT-1은 다양한 자연어 처리 작업에 적합한 성능을 발휘할 수 있게 됩니다.

논문에서 볼 수 있는 것처럼 Language model 학습 공식은 기존 Language model 학습 공식과 동일합니다. GPT-1은 트랜스포머의 디코더로 구성되어있습니다.


기존 모델에서는 파인 튜닝을 수행할 때 과제의 목적에 맞게 추가적인 레이어(layer)를 설계하고 추가해야 했습니다. 이 작업은 상당한 시간과 노력이 필요했으며, 모델 구조를 변경하는 복잡성을 동반했습니다.
GPT-1의 혁신은 파인 튜닝 과정에서 이러한 레이어 추가 작업을 과감히 생략한 점입니다. GPT-1은 기본 모델 구조를 그대로 유지한 채, 레이블링된 데이터를 입력하고 최적화하는 방식만으로 파인 튜닝을 진행합니다. 즉, 별도의 구조 변경 없이 모델을 특정 과제에 맞춰 미세 조정할 수 있습니다.
이를 Entailment(함의 관계) 과제를 예로 들어 이해해보겠습니다. GPT-1은 추가적인 레이어 없이 기존 모델 구조를 그대로 사용하며, 레이블이 있는 데이터를 입력하는 것만으로 파인 튜닝을 수행합니다. Entailment 과제는 두 개의 문장 간의 관계를 분석하는 작업으로, GPT-1은 두 문장을 스페셜 캐릭터로 연결해 하나의 입력 문장으로 변환한 후 이를 처리합니다.
이 과정을 통해, GPT-1은 레이블링된 데이터를 기반으로 모델을 최적화하며, Entailment 과제에 적합한 성능을 발휘하게 됩니다. 이러한 방식은 지도 학습에 해당하며, 기존 방식에 비해 간결하고 효율적입니다.
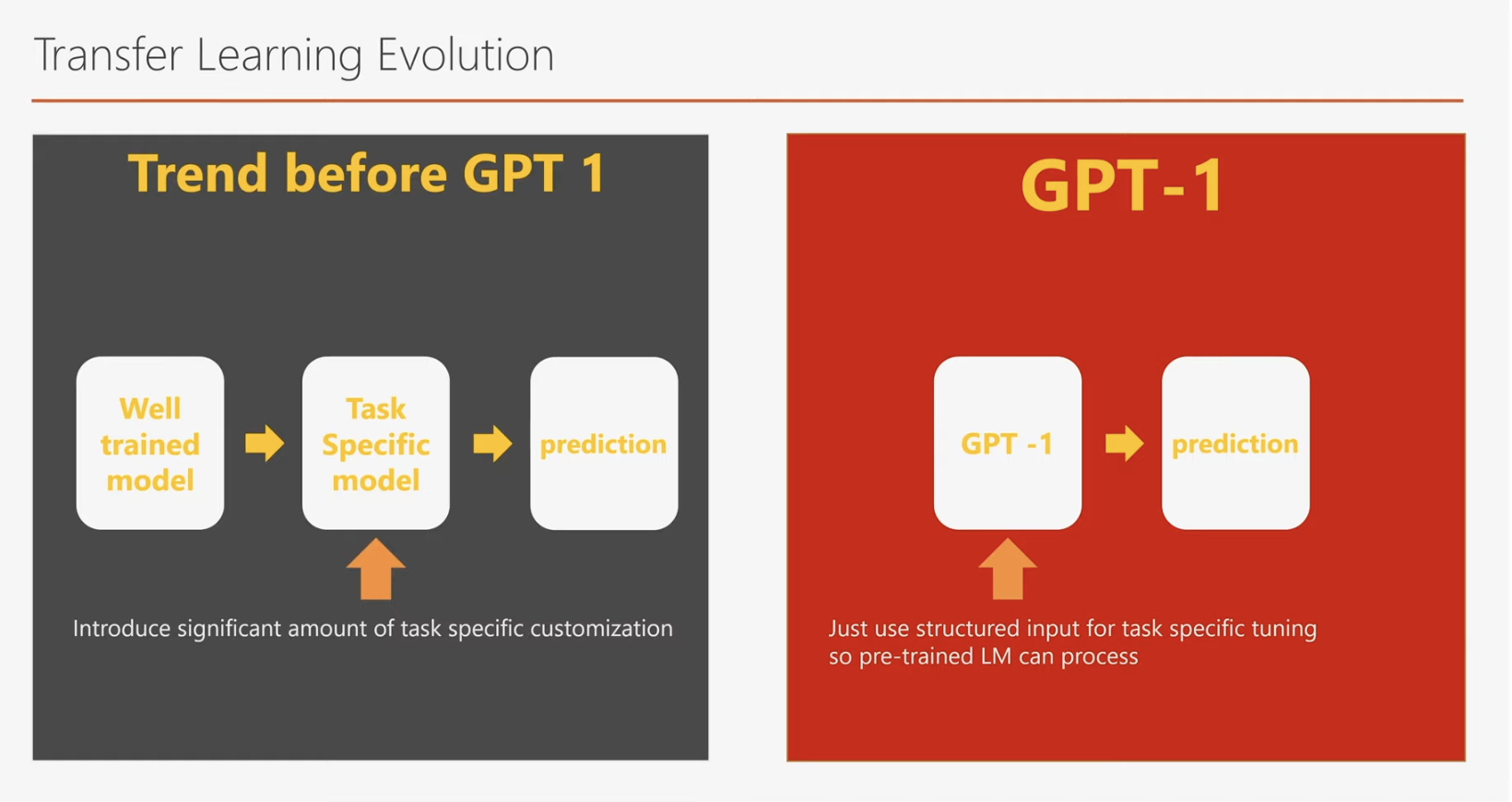
이는 GPT-1의 중요한 혁신 포인트 중 하나입니다. 기존의 모델들은 파인 튜닝을 수행하기 위해 과제에 따라 추가적인 레이어(layer)를 설계하고 삽입해야 했습니다. 이 작업은 많은 시간과 노력이 소요되는 과정이었습니다.
반면, GPT-1은 Language Model 학습에 사용된 트랜스포머 디코더 모델을 그대로 유지한 채 파인 튜닝을 진행합니다. 즉, 추가적인 레이어 설계나 구조 변경이 필요하지 않으며, 기본 모델을 그대로 활용해 레이블링된 데이터를 입력하고 최적화하는 방식만으로 과제를 해결할 수 있습니다.
이 방식이 가능했던 이유는, GPT-1이 Language Model 학습 과정에서 이미 자연어 처리의 핵심적인 능력을 습득했기 때문입니다. 덕분에 GPT-1은 소량의 파인 튜닝 데이터만으로도 모델 변경 없이 탁월한 성능을 발휘할 수 있습니다.
또한, 다양한 형태의 입력값을 하나의 입력값으로 변환해 처리하는 방식도 눈에 띄는 혁신 중 하나입니다. 예를 들어, Entailment(함의 관계) 과제에서는 두 개의 문장을 스페셜 캐릭터로 결합하여 하나의 입력 문장으로 변환한 후 GPT-1에 입력합니다. 이러한 입력 변환 방식은 모델의 유연성을 높이며, 파인 튜닝 과정의 간결함과 효율성을 극대화합니다.
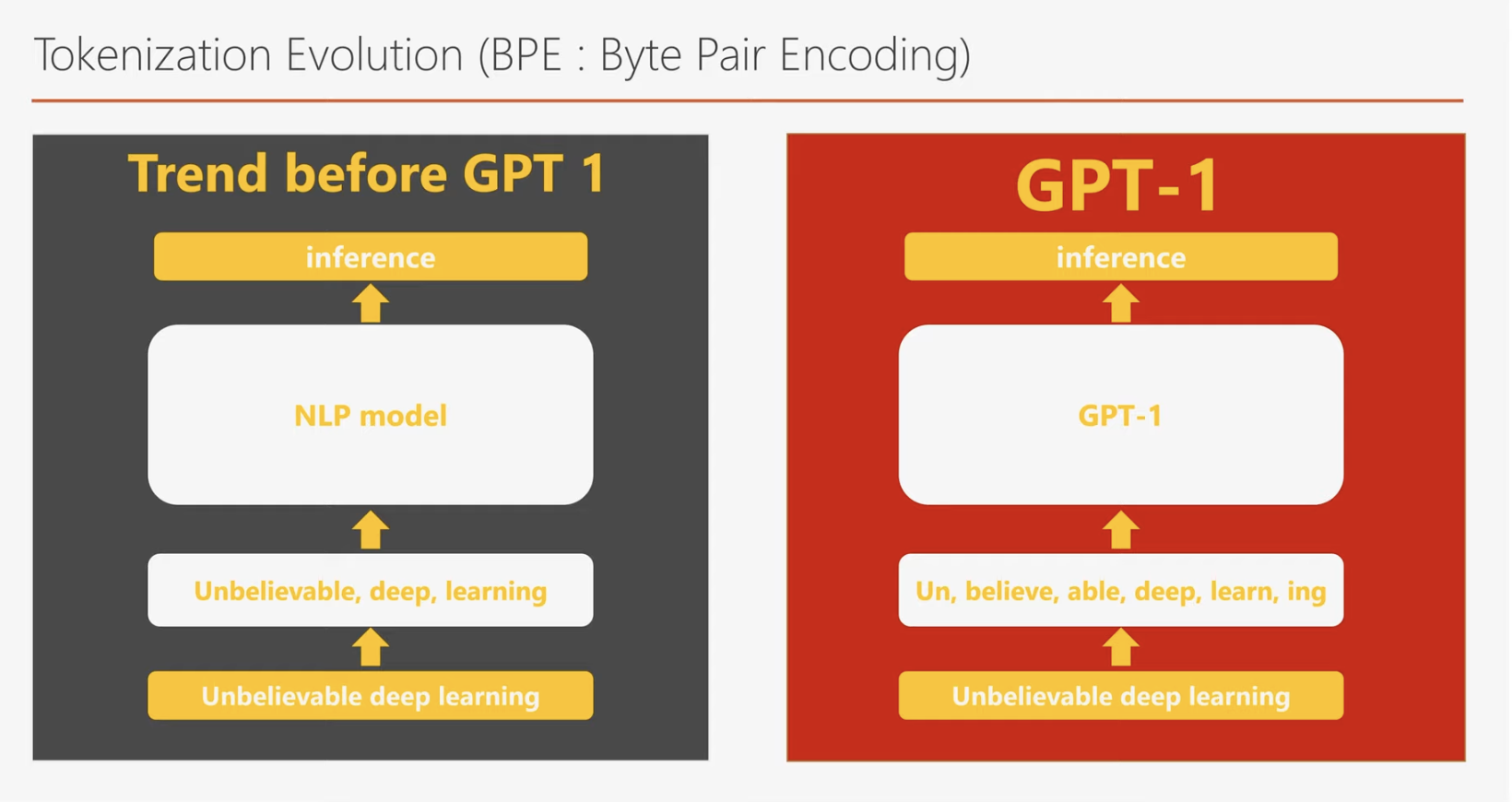
GPT-1은 기존 딥러닝 모델들이 사용하던 임베딩(embedding) 방법보다 진화된 방식을 채택했습니다. 기존의 모델들이 주로 Word Embedding 또는 Character Embedding을 사용했다면, GPT-1은 Byte Pair Encoding(BPE)을 활용합니다.
BPE는 자주 함께 사용되는 문자(character) 조합을 하나의 묶음으로 처리하는 인코딩 방식입니다. 이 방법은 Word Embedding과 Character Embedding의 장점을 결합하여 자연어 처리의 효율성과 정확성을 높입니다.
Word Embedding과 Character Embedding의 장단점
- Word Embedding
- 장점: 단어 간의 유사도를 벡터 공간에서 표현할 수 있습니다. 예를 들어, "king"과 "queen"이 유사한 의미를 가지는 단어라면 벡터 간의 거리가 가깝게 학습됩니다.
- 단점: 학습 과정에서 보지 못했던 단어(예: 신조어, 오탈자)는 처리할 수 없어, 단순히 제로 벡터(zero vector)로 대체됩니다. 이는 새로운 단어에 대한 대응력이 부족함을 의미합니다.
- Character Embedding
- 장점: 모든 단어는 일정한 문자(character) 조합으로 이루어져 있으므로, 새로운 단어라도 벡터로 표현할 수 있습니다.
- 단점: 단어의 문자 조합만 학습하므로, 단어 간의 의미적 유사도를 표현하는 데 한계가 있습니다.
Byte Pair Encoding(BPE)의 혁신
BPE는 Word Embedding과 Character Embedding의 장점을 모두 취한 방법입니다. 이 방식에서는 단어를 의미 단위로 쪼갤 수 있어, 새로운 단어도 효과적으로 처리할 수 있습니다. 예를 들어, "hackable deep learning"이라는 문장에서 "hackable"은 생소한 단어로, Word Embedding에서는 제로 벡터로 처리될 가능성이 큽니다. 반면, BPE는 "hackable"을 자주 사용되는 단위인 "hack"과 "able"로 나누어 각각 임베딩합니다.
이 접근 방식의 장점은 다음과 같습니다:
- 효율성: 단어를 소단위로 분해하여 학습하므로, 신조어와 오탈자에 강합니다.
- 의미 전달: 분해된 단위(예: "hack"과 "able")의 벡터 조합이 원래 단어의 의미를 잘 보존합니다. 이는 단순히 제로 벡터로 처리되거나, 단어 간 유사도가 떨어지는 Character Embedding보다 훨씬 더 나은 성능을 제공합니다.
GPT-1은 이처럼 BPE를 활용하여 자연어 처리에서 더 높은 유연성과 정확성을 구현했습니다. 새로운 단어나 복잡한 단어 구조를 효율적으로 처리할 수 있는 BPE의 도입은 GPT-1의 성능 향상에 중요한 역할을 했습니다.

GPT-1 요약
-
트랜스포머 디코더 기반
GPT-1은 트랜스포머 아키텍처 중 디코더(Decoder)를 기반으로 설계된 모델입니다.
-
비지도 학습을 통한 Language Model 학습
Language Model 학습은 비지도 학습 방식으로 진행되며, GPT-1은 다양한 분야에서 수집된 방대한 텍스트 데이터를 활용해 Pre-Training을 수행합니다. 이를 통해 일반적인 자연어 처리 능력을 효과적으로 내재화합니다.
-
효율적인 파인 튜닝
Language Model 학습을 통해 이미 강력한 자연어 처리 능력을 학습한 GPT-1은 추가적인 레이어를 설계할 필요 없이, 소량의 레이블링된 데이터만으로 쉽게 파인 튜닝이 가능합니다. 이러한 접근법은 적은 양의 데이터로도 높은 성능을 발휘할 수 있음을 보여줍니다.
-
Byte Pair Encoding(BPE)의 활용
GPT-1은 기존의 Word Embedding이나 Character Embedding 방식을 넘어, Byte Pair Encoding(BPE)을 도입하여 임베딩 방식을 한 단계 진화시켰습니다. 이를 통해 신조어나 오탈자 등 새로운 단어 처리에서 강력한 유연성을 보여줍니다.
지금까지의 GPT-1에 대한 내용은 논문 ‘Improving Language Understanding by Generative Pre-Training’을 참조하여 작성되었습니다.
GPT-2
GPT-2: GPT-1과의 차이점 및 발전
이제 GPT-2에 대해 간략히 알아보고, GPT-1과 비교해 어떤 점이 달라지고 발전되었는지 살펴보겠습니다.
GPT-1의 주요 단점 중 하나는 여전히 파인 튜닝(Fine-Tuning) 과정이 필요하다는 점이었습니다. 비록 GPT-1이 추가적인 레이어 없이 파인 튜닝이 가능하다는 점에서 효율적이었지만, 특정 작업에 맞춰 레이블이 있는 데이터를 사용해 모델을 미세 조정해야 했습니다. 이 과정은 여전히 데이터 준비와 학습 비용이 요구되며, 실제 응용에서 제약으로 작용할 수 있었습니다.

GPT-2는 이러한 한계를 극복하기 위해 제로 샷 학습(Zero-Shot Learning) 능력을 강화하며, 특정 작업에 대해 별도의 파인 튜닝 없이도 우수한 성능을 발휘할 수 있도록 설계되었습니다.
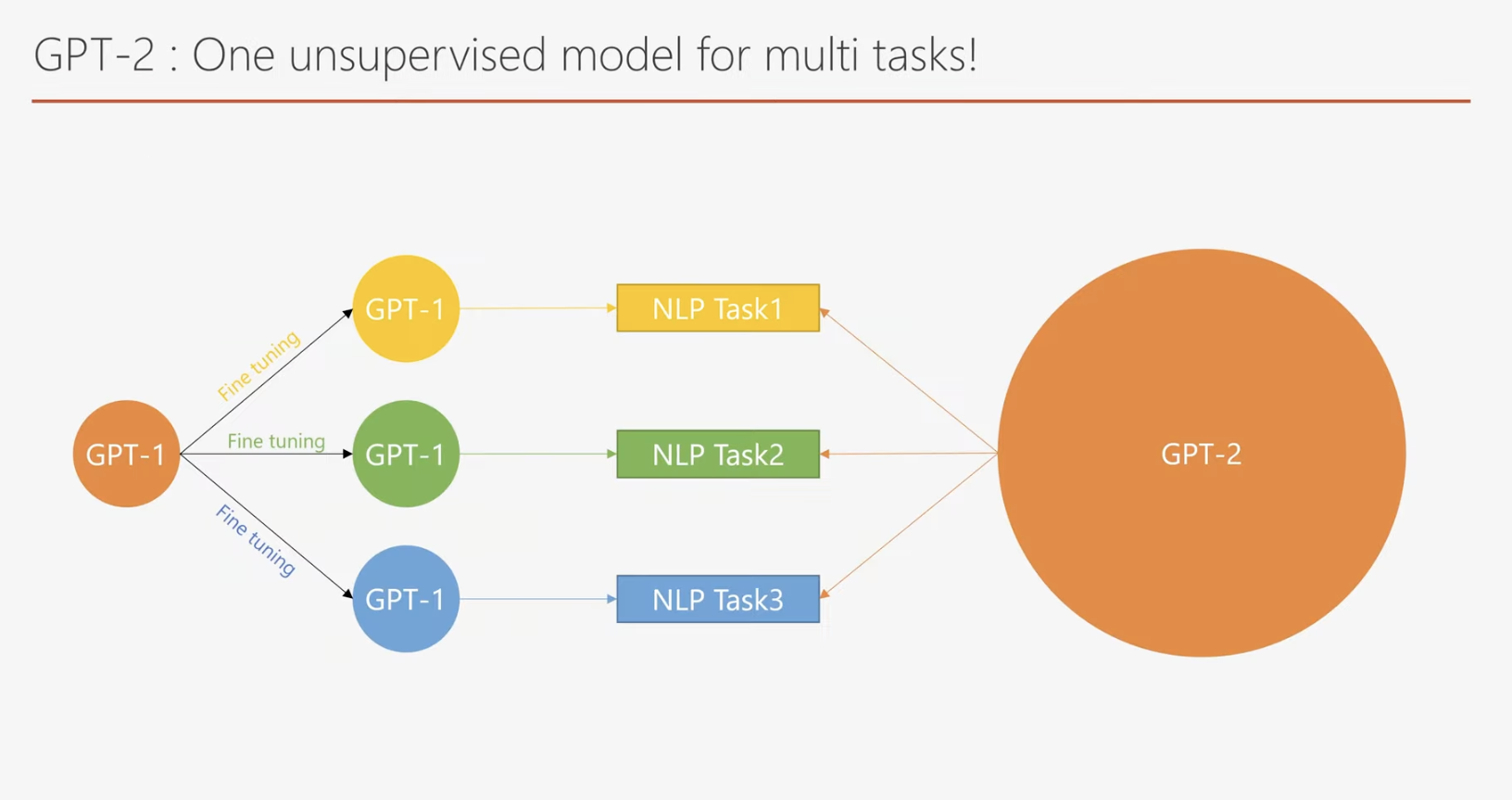
GPT-2의 주요 변화
위 그림에서 가장 눈에 띄는 변화는 GPT-2의 크기와 학습 데이터의 확장입니다.
첫째, GPT-2는 GPT-1보다 10배 이상 큰 모델로, 매개변수의 수가 크게 증가했습니다.
둘째, 학습 데이터 역시 GPT-1에 비해 10배 이상의 방대한 데이터를 사용했습니다.
셋째, GPT-2는 GPT-1과 달리 파인 튜닝(Fine-Tuning) 없이 다양한 자연어 처리 작업을 수행할 수 있습니다.
파인 튜닝은 많은 시간과 비용을 요구하며, 특정 작업에 최적화된 모델은 다른 작업에 재사용할 수 없는 단점이 있습니다. 이러한 점에서 파인 튜닝 없이도 범용적으로 사용할 수 있는 GPT-2는 매우 매력적인 모델입니다. 예를 들어, 자연어 처리 서비스를 제공하는 상황에서, 파인 튜닝 없이 사용료만 지불하고도 뛰어난 성능을 발휘하는 모델이 있다면 시간과 비용 모두 절약할 수 있는 효율적인 선택이 될 것입니다.

보통 language model 학습은 현재 입력된 값들을 통해서 다음 단어가 나올 확률을 최대한 높이도록 모델 변수들을 조정하도록 되어 있습니다.
GPT-1도 이와 같은 방식으로 학습이 됩니다. GPT-2의 학습 방법은 조금 다릅니다.
GPT-2는 입력된 값들과 수행해야 할 task를 함께 입력 받아서 다음 단어를 출력하도록 되어 있습니다. 예제를 보면서 그 차이를 알아보겠습니다.
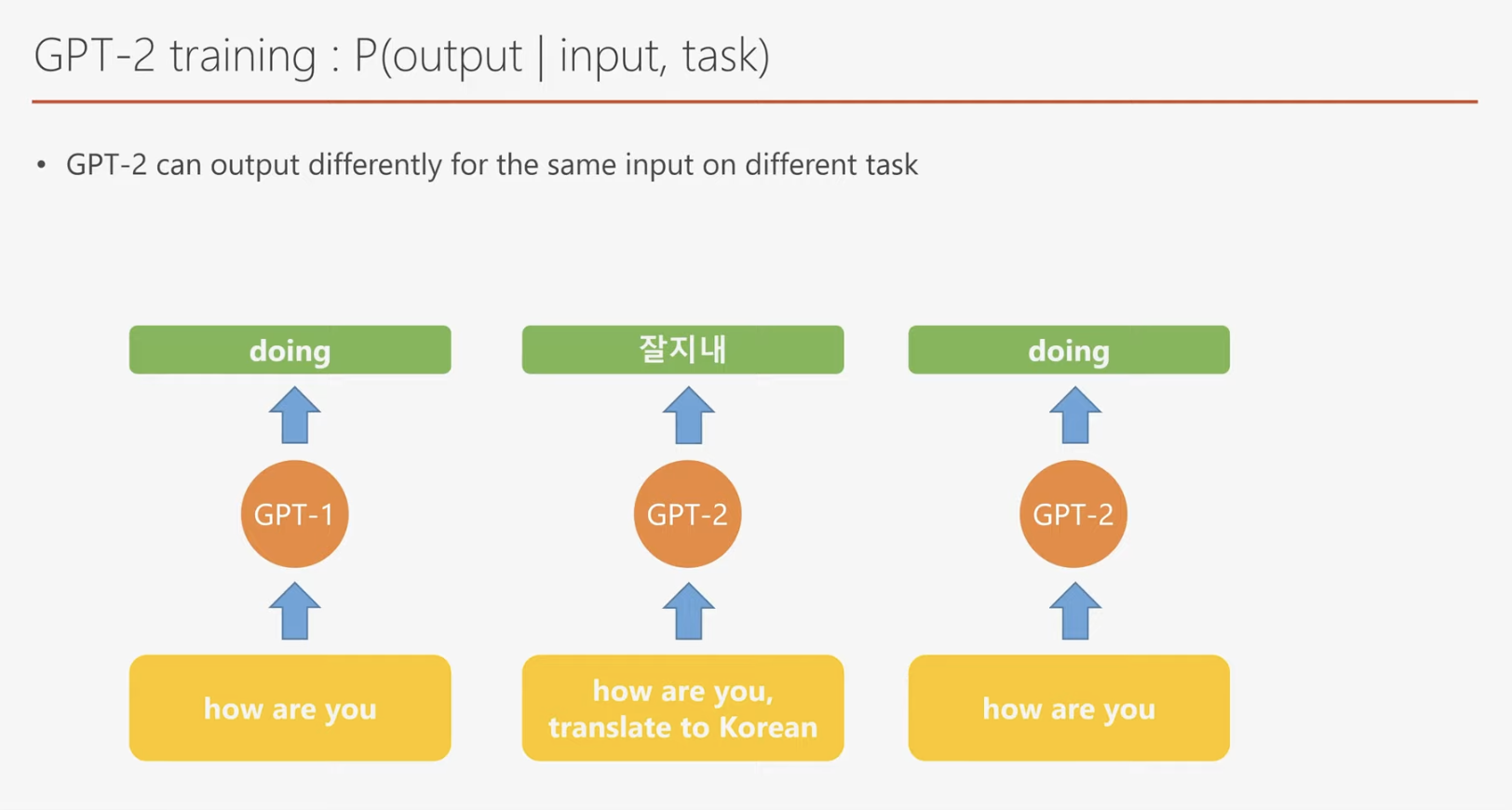
만약 "How are you doing"이라는 데이터를 이용해 GPT-1을 학습시킨다면, "How are you"를 입력값으로 사용하고 "doing"을 출력값으로 생성하도록 모델을 학습할 수 있습니다. 이는 GPT-1이 다음 단어를 예측하는 방식으로 학습되기 때문입니다.
반면, GPT-2의 경우는 이를 조금 더 발전시킨 학습 방식이 적용됩니다. 예를 들어, 기계 번역(task-specific)의 학습 사례를 살펴보겠습니다. "How are you"라는 입력값 뒤에 기계 번역 작업을 나타내는 특수 토큰(special token)을 추가한 다음, GPT-2에 입력합니다. 그러면 모델은 이에 따라 "잘 지내"라는 번역 결과를 출력하게 됩니다.
GPT-2 또한 GPT-1처럼 단순히 다음 단어를 예측하도록 학습될 수 있지만, 차별화된 점은 입력값에 포함된 task-specific 정보를 활용한다는 점입니다. 이를 통해 GPT-2는 단순히 다음 단어를 예측할지, 기계 번역을 수행할지, 혹은 질문에 답변할지를 스스로 판단할 수 있습니다.
다만, 하나의 모델이 다양한 작업(task)을 처리하기 위해서는 작업별로 대규모의 학습 데이터와 방대한 양의 모델 파라미터(parameter)가 필요합니다. 이로 인해 GPT-2는 한층 더 복잡하고 강력한 언어 처리 능력을 가지게 되었습니다.
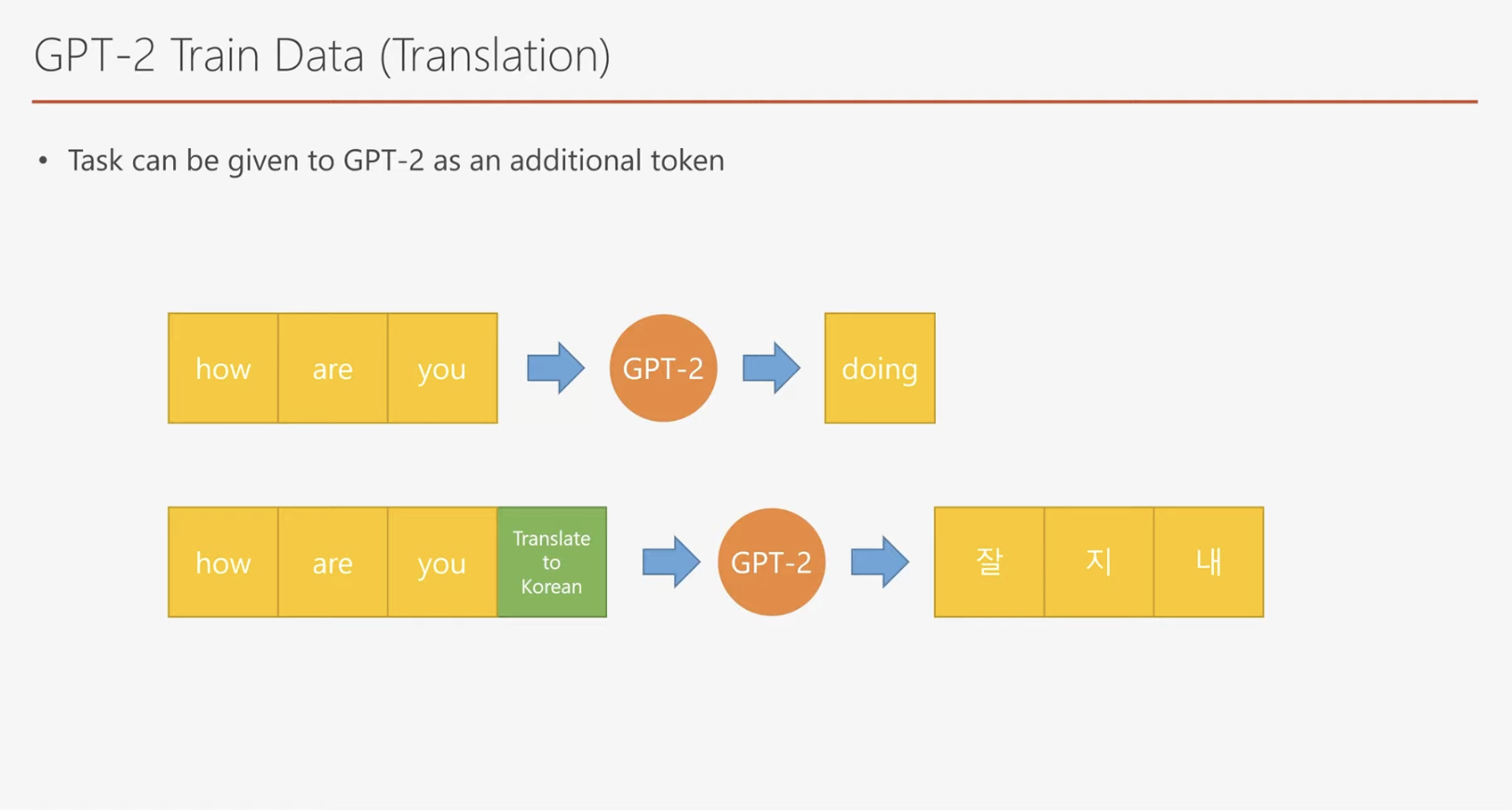
위 GPT-2 학습 데이터 예제에서는 한국어로 변환하라는 특수 토큰(special token)이 사용된 것을 확인할 수 있습니다. 이를 통해 GPT-2가 동일한 입력값에 대해 상황에 따라 다른 출력을 생성할 수 있음을 알 수 있습니다.
GPT-2는 GPT-1과 마찬가지로 언어 모델(language model)로 설계되었지만, 작업(task)을 명시적으로 알려주는 특수 토큰을 추가함으로써 다목적 언어 모델로 진화하였습니다. 이러한 설계는 모델이 단순히 다음 단어를 예측하는 데 그치지 않고, 번역, 질문 응답, 요약 등의 다양한 작업을 수행할 수 있게 만듭니다.
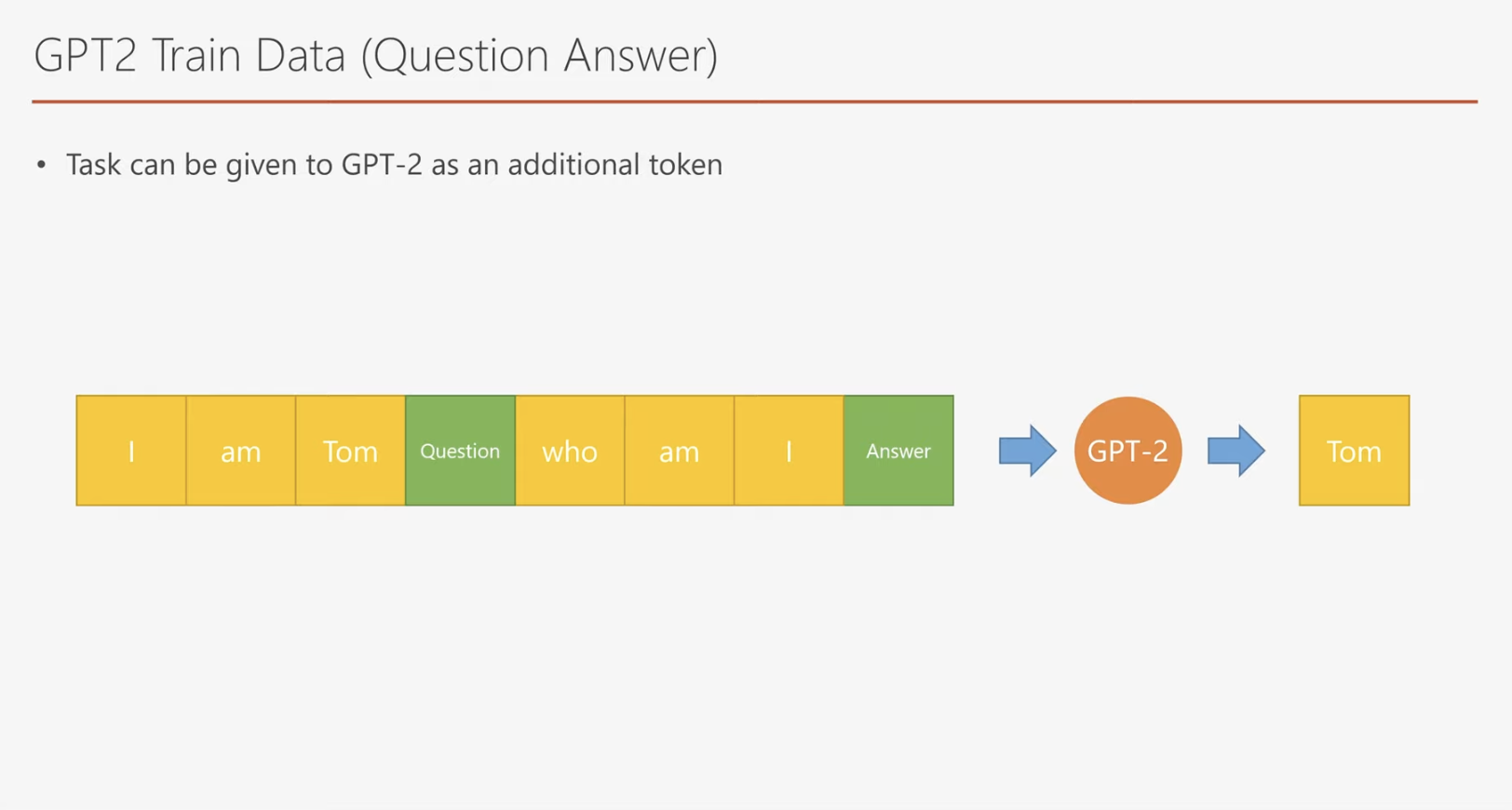
GPT-2는 질의응답, 번역 등 다양한 작업을 처리하기 위해 Special Token을 도입했습니다. 예를 들어, 질의응답 작업에서는:
- 문맥 데이터를 입력하고,
- "질문 입력"을 나타내는 Special Token을 추가,
- 질문 입력 후 "답변 생성"을 나타내는 Special Token을 추가하여 데이터를 구성합니다.
이 과정을 통해 GPT-2는 다양한 작업에 적응할 수 있는 범용성을 갖추게 됩니다.
다만, Special Token을 추가한 데이터셋 구성 과정은 GPT-2가 완전히 레이블 없는 학습을 한 것이 아니라, 작업 정보를 명시적으로 나타낸 데이터를 사용했음을 의미합니다. 학습 데이터는 인터넷에서 수집된 텍스트를 바탕으로 작업 유형에 맞게 전처리되었으며, Special Token을 통해 작업 맥락을 모델에 전달합니다.
따라서, GPT-2의 학습 과정은 전통적인 지도 학습(Fine-Tuning)과는 다르지만, 암묵적인 레이블링이 포함된 데이터 전처리 과정을 거쳤다고 보는 것이 더 정확합니다.

GPT-2 논문에 사용된 기계 번역 데이터를 살펴보면, 데이터 수집 과정에서 품질 관리에 상당한 노력이 투입되었음을 알 수 있습니다. 데이터는 동일한 포맷을 가진 쌍(pair) 형태로 구성되어 있으며, 같은 의미를 지닌 두 문장이 포함되어 있습니다. 이는 모델이 학습 과정에서 정확히 대응되는 문장을 학습할 수 있도록 설계된 것입니다.
그렇다면, 어떻게 GPT-2는 품질 높은 데이터를 효율적으로 수집할 수 있었을까요?
GPT-2는 데이터의 품질을 보장하기 위해 Reddit 플랫폼에서 3개 이상의 추천을 받은 글들만을 선별적으로 활용했습니다. Reddit은 사용자가 다양한 주제에 대해 글을 게시하고, 커뮤니티 구성원들의 추천 및 답변을 통해 상호작용하는 플랫폼으로, 이를 통해 신뢰할 수 있는 고품질 데이터셋을 구축할 수 있었습니다.
여기 GPT-1과 GPT-2 모델의 차이를 한 표에 담아보았습니다. 확실히 GPT-2가 훨씬 더 크고 큰 벡터를 다루고 있고 문맥도 더 넓게 관찰하고 학습 시 batch 사이즈도 더 큽니다.
Layer normalization 도 약간의 변화를 주었습니다.
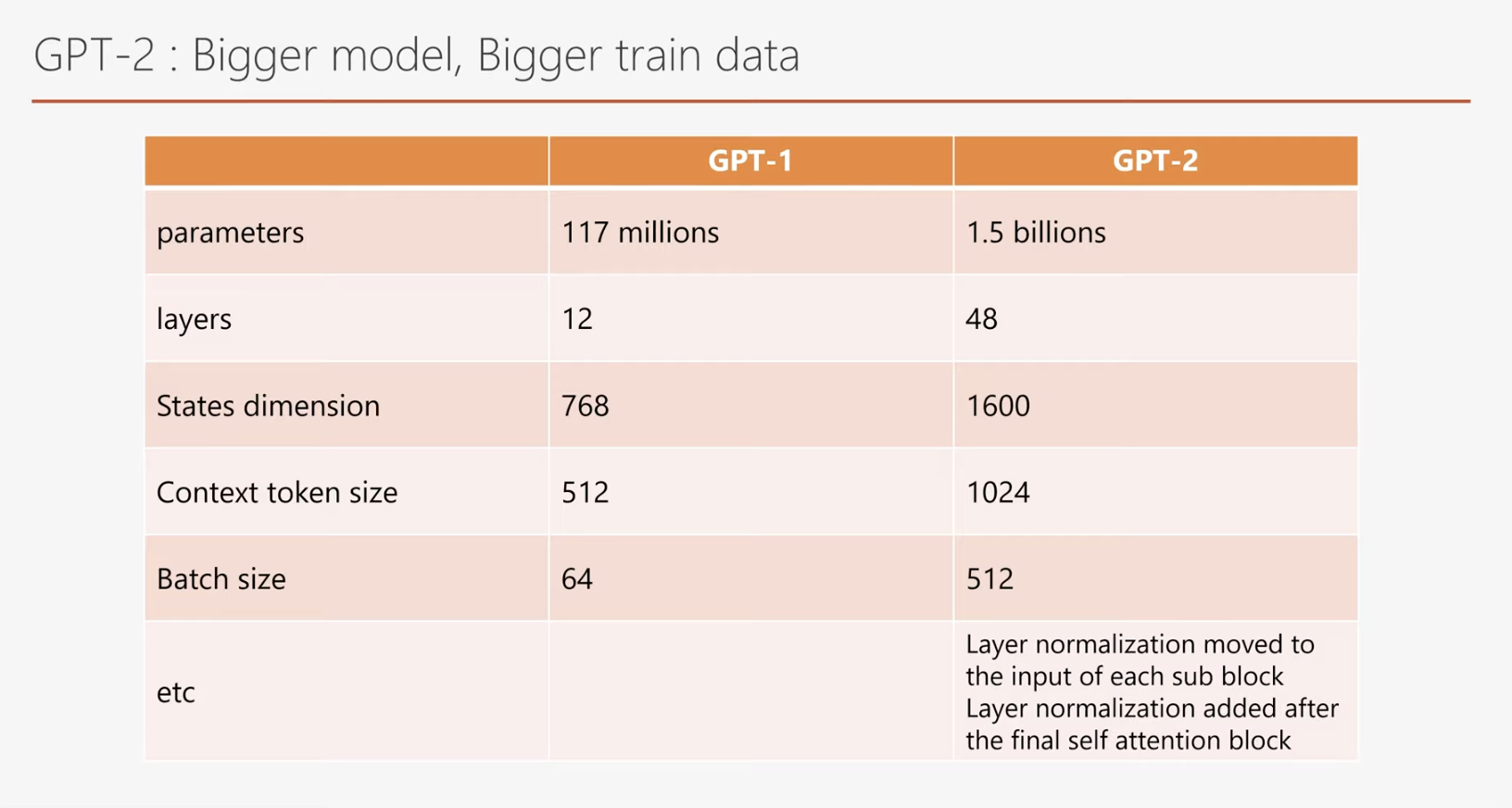
GPT-1과 GPT-2 모델의 차이점
을 요약한 표입니다.
GPT-2는 GPT-1에 비해 훨씬 더 큰 모델 크기와 벡터를 다루며, 더 넓은 문맥을 관찰할 수 있습니다. 또한 학습 시 배치 크기(Batch Size)가 더 크며,
Layer Normalization 에서도 일부 개선이 이루어졌습니다.
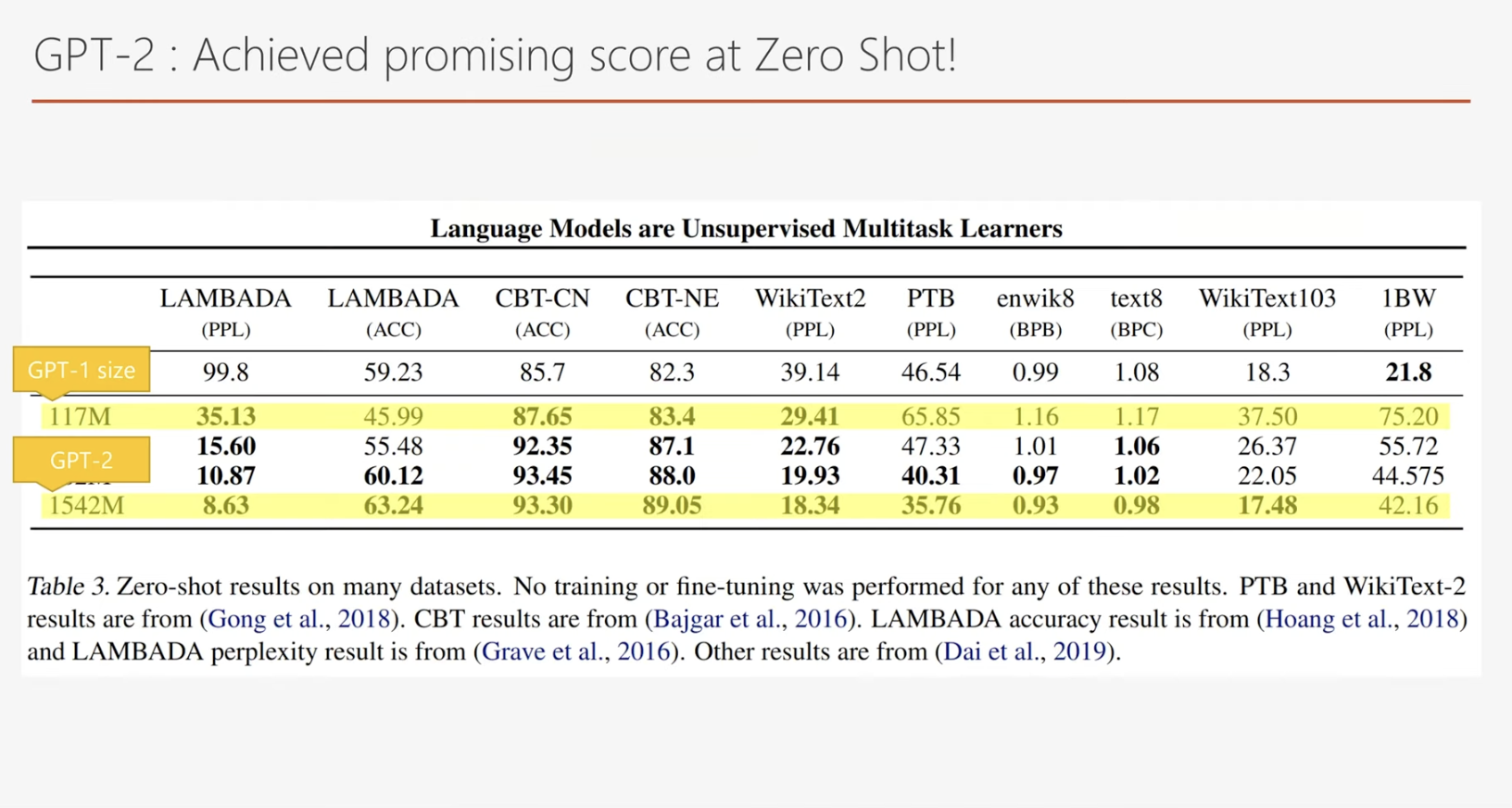
GPT-2는 사람이 직접적으로 특정 작업을 가르치거나 파인 튜닝하지 않아도 다양한 작업을 수행할 수 있습니다. 이러한 특성으로 인해 GPT-2는 Zero-Shot Learning이 가능한 모델로 평가받습니다.
표에서 주목해야 할 점은 모델 크기와 Zero-Shot Learning 성능 간의 상관관계입니다. GPT-2와 같은 더 큰 모델이 Zero-Shot Learning을 수행했을 때, 기존의 작은 모델에 비해 현저히 우수한 성능을 발휘했다는 점입니다. 이는 GPT-1에 비해 GPT-2가 더 큰 모델로 설계될 수밖에 없었던 이유를 잘 설명해줍니다.
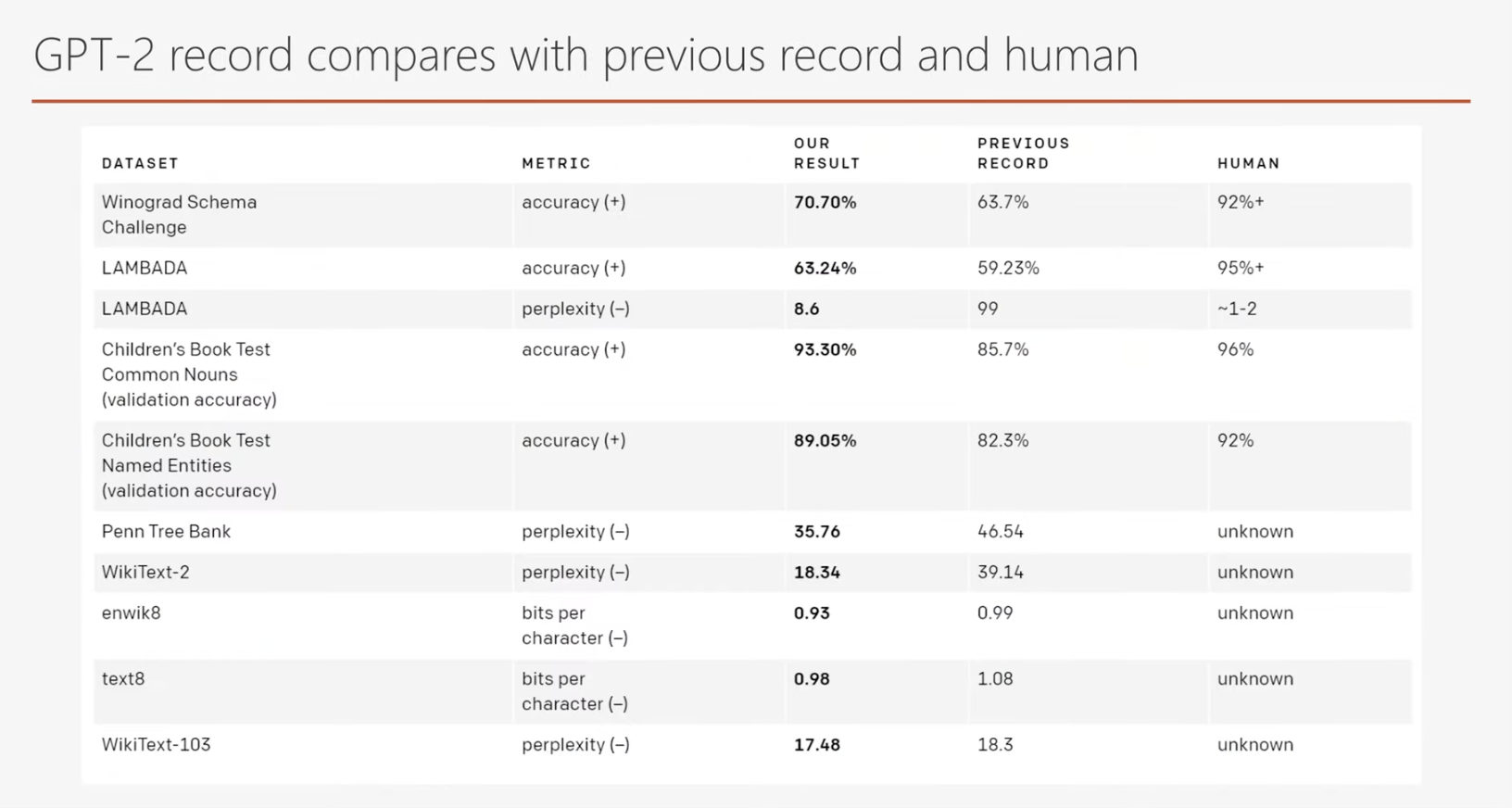
해당 표에서 주목해야 할 점은 Zero-Shot Learning만으로도 기존에 특정 작업에 집중하여 파인 튜닝된 최고 성능의 모델들을 능가했다는 점입니다. 특히, 일부 테스트에서는 사람과 견줄 만한 성능을 보여주며 GPT-2의 뛰어난 학습 능력을 입증했습니다.
GPT-3
GPT-3로 넘어가도록 하겠습니다.
GPT-3 에 대한 내용은 Language Models are Few-Shot Learners 라는 논문을 읽고 요약하였습니다. (https://arxiv.org/abs/2005.14165)

최근 자연어 처리(NLP)는 눈부신 발전을 이루었습니다. 과거에는 잘 훈련된 워드 임베딩(Word Embedding)을 재사용하는 방식이 주를 이루었다면, 이제는 잘 훈련된 NLP 모델을 다운로드받아 각자의 작업(Task)에 맞게 파인 튜닝하는 시대가 되었습니다. 그러나 파인 튜닝 자체도 여전히 많은 작업이 필요합니다.
데이터를 수집하고 레이블링하며, 추가 레이어를 설계하고, 최적의 파라미터를 찾기 위한 긴 학습 과정을 거치는 등 상당한 시간과 노력이 요구됩니다.
GPT-3의 가장 큰 혁신은 바로 파인 튜닝 과정을 제거하는 데 있습니다.
GPT-3는 방대한 데이터로 미리 학습된 모델을 기반으로, Few-Shot Learning을 통해 다양한 작업에 대한 일반화된 능력을 제공합니다. 이를 통해 사용자는 특정 작업을 위해 추가적인 학습 없이도 이미 준비된 모델을 활용할 수 있습니다.
GPT-3의 핵심은 사전 학습된 범용 NLP 모델을 제공하여 사용자의 부담을 크게 줄이는 것입니다.
GPT vs BERT

과거 GPT는 처음 등장하여 자연어 처리(NLP) 성능 평가에서 우수한 성적을 거두며 주목받았습니다. 그러나 얼마 지나지 않아 구글이 BERT를 발표하면서, GPT는 그 자리를 내주는 듯했습니다. BERT는 보다 뛰어난 성능과 혁신적인 접근 방식으로 NLP 분야를 이끌어 나갔습니다.
이후 GPT-2가 출시되며 상황은 다시 반전되었습니다. GPT-2는 GPT-1에 비해 성능이 대폭 업그레이드되었을 뿐 아니라, Language Model의 특성을 살려 놀라운 글쓰기 능력을 보여주었습니다. 마치 작가가 쓴 것 같은 GPT-2의 텍스트 생성 능력은 사람들에게 깊은 인상을 남겼습니다. GPT와 BERT는 현재까지도 서로 경쟁하며 NLP 모델의 발전을 주도하고 있습니다. 만약 트랜스포머(Transformer)에게 의식이 있다면, 이러한 두 모델의 경쟁에 흐뭇해할지도 모릅니다.
현재 많은 사람들이 사전 학습된 자연어 처리 모델을 다운로드받아 각자의 작업(Task)에 맞게 파인 튜닝(Fine-Tuning)을 거쳐 모델을 활용합니다. 그러나 파인 튜닝이 단순하고 쉬운 작업일까요? 파인 튜닝 과정은 데이터 수집과 레이블링 작업을 요구하며, 특히 번역 모델과 같이 특정 작업에 특화된 모델을 만들려면, 해당 언어 데이터를 확보하기 위해 막대한 자본과 시간이 필요합니다.
GPT-3는 이러한 한계를 극복하며 등장했습니다. GPT-3는 파인 튜닝이 필요 없는 더욱 강력한 모델로, Few-Shot Learning만으로 다양한 자연어 처리 작업에서 우수한 성능을 보여줍니다. 물론 GPT-3 역시 파인 튜닝이 가능하지만, 전혀 파인 튜닝하지 않은 상태에서도 성능 평가에서 뛰어난 결과를 기록했습니다. 이는 GPT-3의 모델 크기와 사전 학습 데이터의 방대함이 가능하게 한 혁신적인 접근입니다.
흥미롭게도, Few-Shot Learning은 인간이 지식을 습득하는 방식 중 하나와 유사합니다. 최소한의 힌트와 맥락만으로 새로운 작업을 수행할 수 있는 GPT-3의 능력은 자연어 처리 모델의 새로운 가능성을 제시하며, NLP의 패러다임을 바꾸고 있습니다.

GPT-3의 핵심은 Few-Shot Learning을 통해 파인 튜닝 없이도 고성능의 다목적 자연어 처리 모델을 제공한다는 점입니다. GPT-3는 Language Model을 학습하는 동안, Few-Shot Learning을 활용하여 다양한 작업에서 요구되는 패턴 인지 능력을 함께 학습하도록 설계되었습니다. 이를 통해 GPT-3는 별도의 추가 학습 없이도 다양한 자연어 처리 작업을 효과적으로 수행할 수 있습니다.
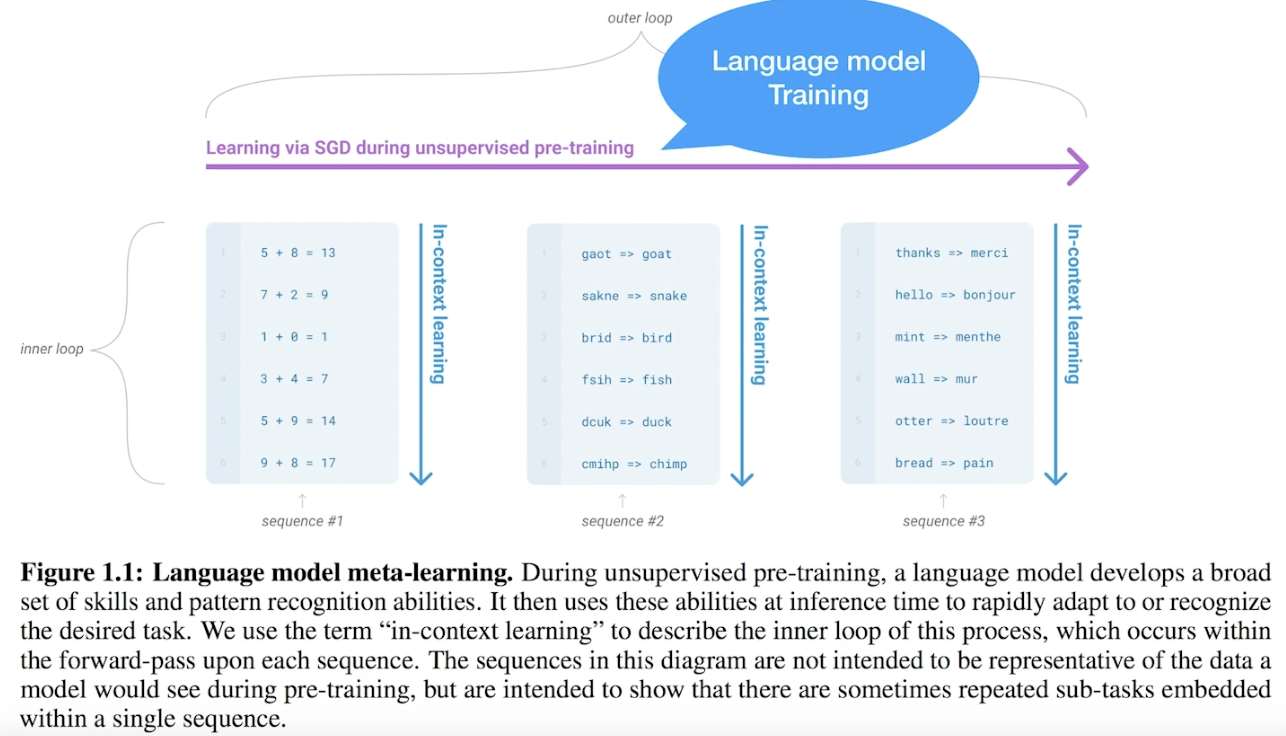
예를 들어, 사칙 연산, 오타 검색, 번역과 같은 작업의 패턴을 GPT-3는 Few-Shot Learning을 통해 학습할 수 있습니다. 이러한 능력은 다양한 작업에서 뛰어난 성능을 발휘하게 하며, 논문에는 이를 입증하는 여러 테스트 결과가 수록되어 있습니다.

GPT-3는 작은 모델부터 1750억 개의 매개변수(175 billion parameters)를 가진 거대한 모델까지 성능을 평가하였습니다. 또한, Zero-Shot Learning과 Few-Shot Learning의 성능을 비교한 결과, Few-Shot Learning이 Zero-Shot Learning보다 더 우수한 성능을 발휘하는 것을 확인할 수 있었습니다. 더불어, 모델 크기가 클수록 성능이 향상되며, 거대한 모델이 작은 모델에 비해 확연히 뛰어난 결과를 보여주었습니다.
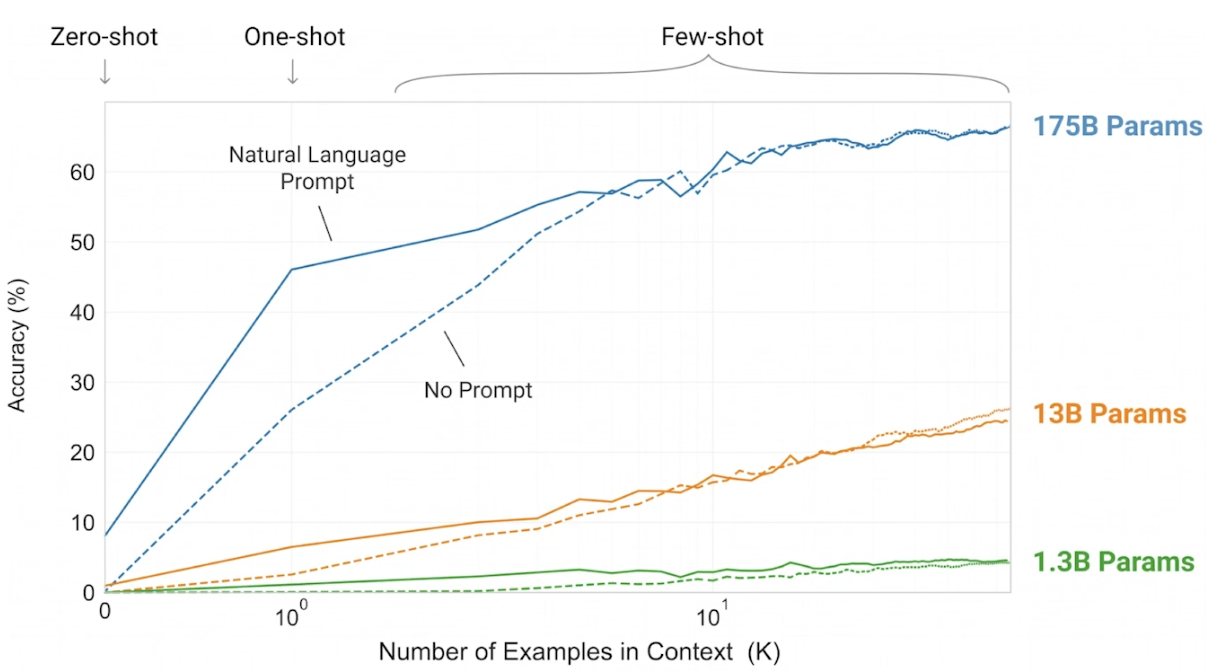
차트를 보면 GPT-3가 1750억 개의 매개변수(175 billion parameters)를 사용해야만 했던 이유와, Zero-Shot Learning 대신 Few-Shot Learning을 선택한 이유를 직관적으로 이해할 수 있습니다. 데이터에서 명확히 드러나는 성능 차이가 이러한 설계 선택을 뒷받침합니다.
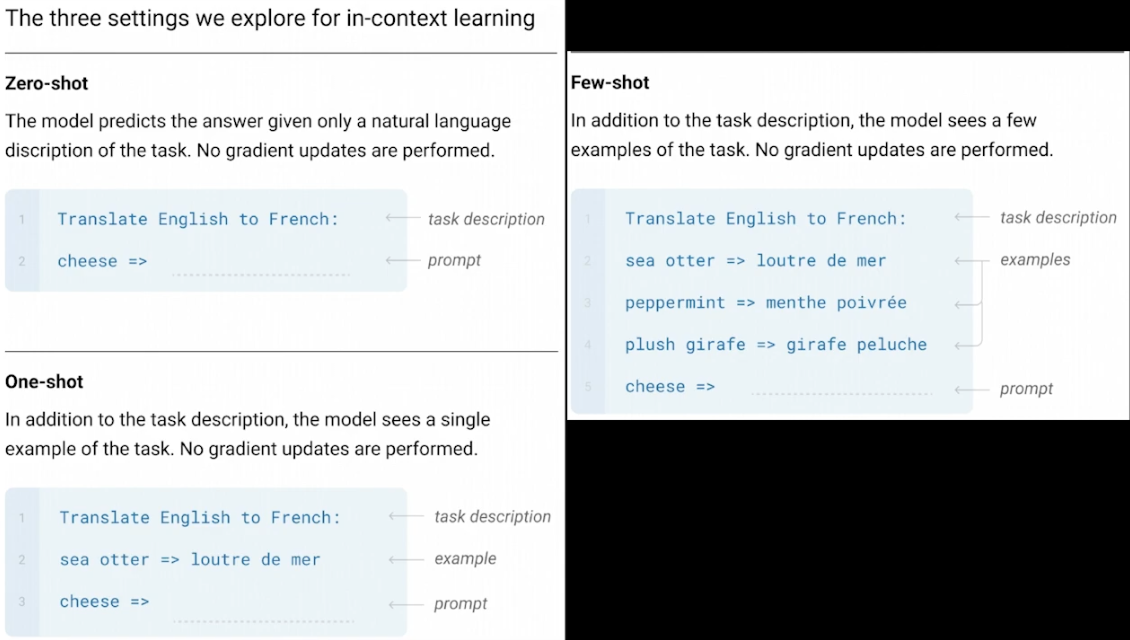
실제 사용된 텍스트 기반 Few-Shot Learning 예제를 통해 차이를 확인할 수 있습니다.
- Zero-Shot Learning: 작업(Task)만 주어지고, 추가적인 예제는 제공되지 않습니다.
- One-Shot Learning: 하나의 예제가 제공되어 작업의 맥락을 전달합니다.
- Few-Shot Learning: 몇 개의 예제가 추가로 제공되어, 모델이 작업의 패턴을 더 잘 이해할 수 있습니다.
이러한 예제는 Zero-Shot, One-Shot, Few-Shot Learning의 차이를 명확히 보여주며, GPT-3가 다양한 작업에서 어떻게 학습하고 수행하는지 이해하는 데 도움을 줍니다.
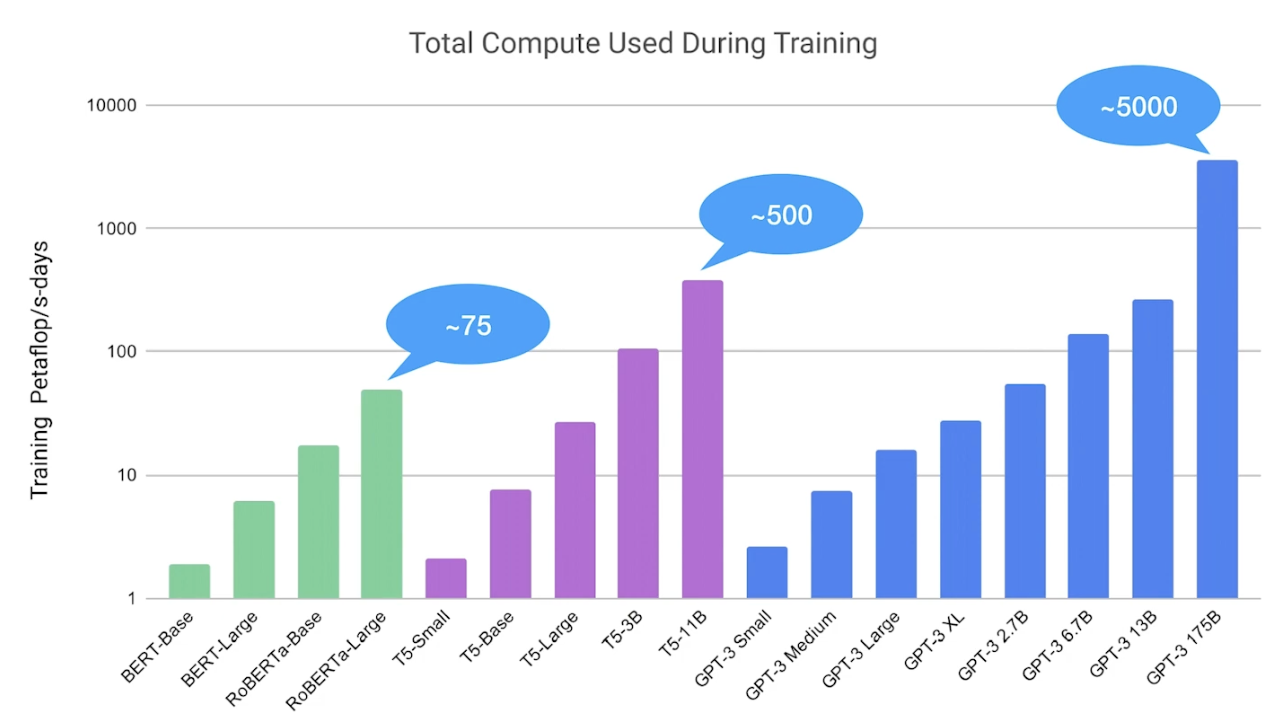
이 차트는 GPT-3의 위력을 잘 보여줍니다. GPT-3는 T5와 같은 대규모 모델보다도 10배 이상 많은 에너지를 사용하며, 이를 통해 얼마나 강력한 성능을 가진 모델인지 확인할 수 있습니다. 이러한 수치는 GPT-3가 자연어 처리에서 새로운 기준을 제시하는 "괴물" 같은 모델임을 입증합니다.

이 부분에서는 GPT-3가 파인 튜닝(Fine-Tuning)도 가능하지만, 주된 목적은 파인 튜닝 없이 자연어 처리 성능 평가를 수행하는 데 있음을 강조합니다. 평가 결과, 일부 작업에서는 당시 최고의 모델 성능을 능가했지만, 다른 작업에서는 상대적으로 낮은 성능을 보이는 경우도 있었습니다.
그럼에도 불구하고, 파인 튜닝 없이 이러한 성과를 거두었다는 점은 놀라운 성취로 평가할 수 있습니다. 이는 GPT-3의 범용성과 강력한 사전 학습 능력을 입증하며, 자연어 처리 모델의 새로운 가능성을 제시합니다.



GPT-3는 GPT-2의 구조를 그대로 활용하며, Common Crawl 데이터셋을 학습 데이터로 사용했습니다. 좋은 모델은 좋은 데이터에서 나온다는 원칙에 따라, GPT-3는 학습 데이터의 품질을 높이기 위해 세심한 과정을 거쳤습니다.
- 고품질 데이터 선별: 학습에 사용된 데이터는 철저히 선별되었으며, 불필요한 중복을 줄이고 추가적으로 양질의 데이터를 삽입했습니다.
- 대규모 토큰 수집: 총 3,000억 개(300 billion tokens)의 토큰이 수집되었으며, 대부분의 데이터가 중복되지 않았다는 점은 특히 주목할 만합니다.
이처럼 GPT-3는 데이터 수집 및 전처리에 막대한 노력을 기울였고, 이를 통해 모델 성능을 극대화했습니다.

GPT-3는 거대한 모델 학습을 위해 큰 배치 크기(batch size)와 작은 학습률(learning rate)을 적용했다고 합니다. 이러한 설정은 대규모 데이터를 효과적으로 학습하고, 안정적인 최적화를 이루기 위한 전략으로 널리 사용됩니다.

GPT-3 성능
자 이제 GPT-3의 성능 평가 결과를 봅시다. 첫 성능 평가는 language model 성능 평가입니다. 보다시피 이 GPT-3가 당시에 기존 최고 성능 평가 기록을 압도했다고 합니다.
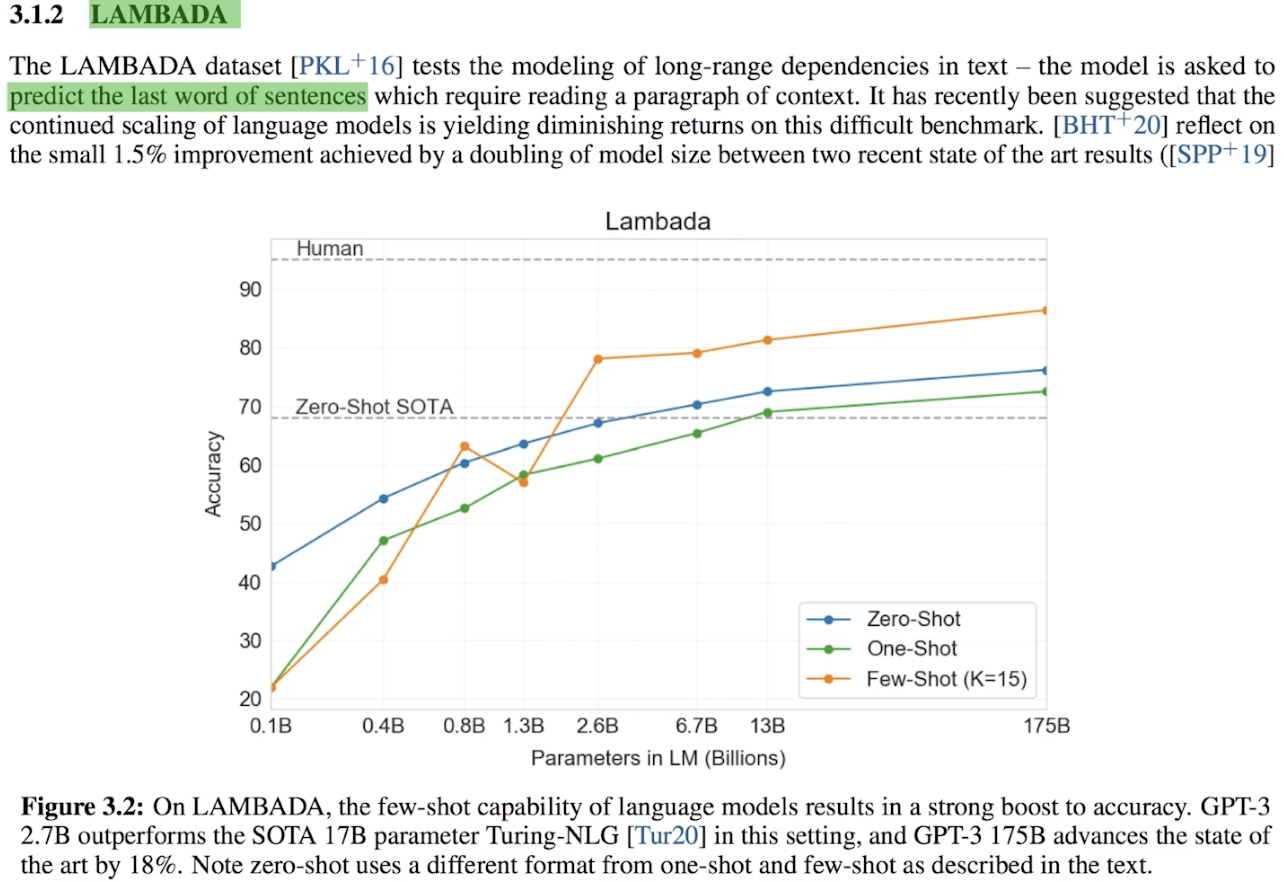
두 번째 성능 평가는 LAMBADA 입니다. 쉽게 말해서 모델이 문장의 마지막 단어를 잘 예측하는지 성능을 평가하는 것입니다. 이 성능 평가에서 GPT-3는 최고로 우수한 성적을 달성했었습니다.

GPT-3는 가장 적합한 마지막 문장을 선택하는 테스트에서 기존 최고 점수에는 미치지 못하는 결과를 얻었습니다. 그러나 파인 튜닝 없이 이 정도 성과를 낸 것은 여전히 놀라운 결과로 평가할 수 있습니다.
GPT-3 한계
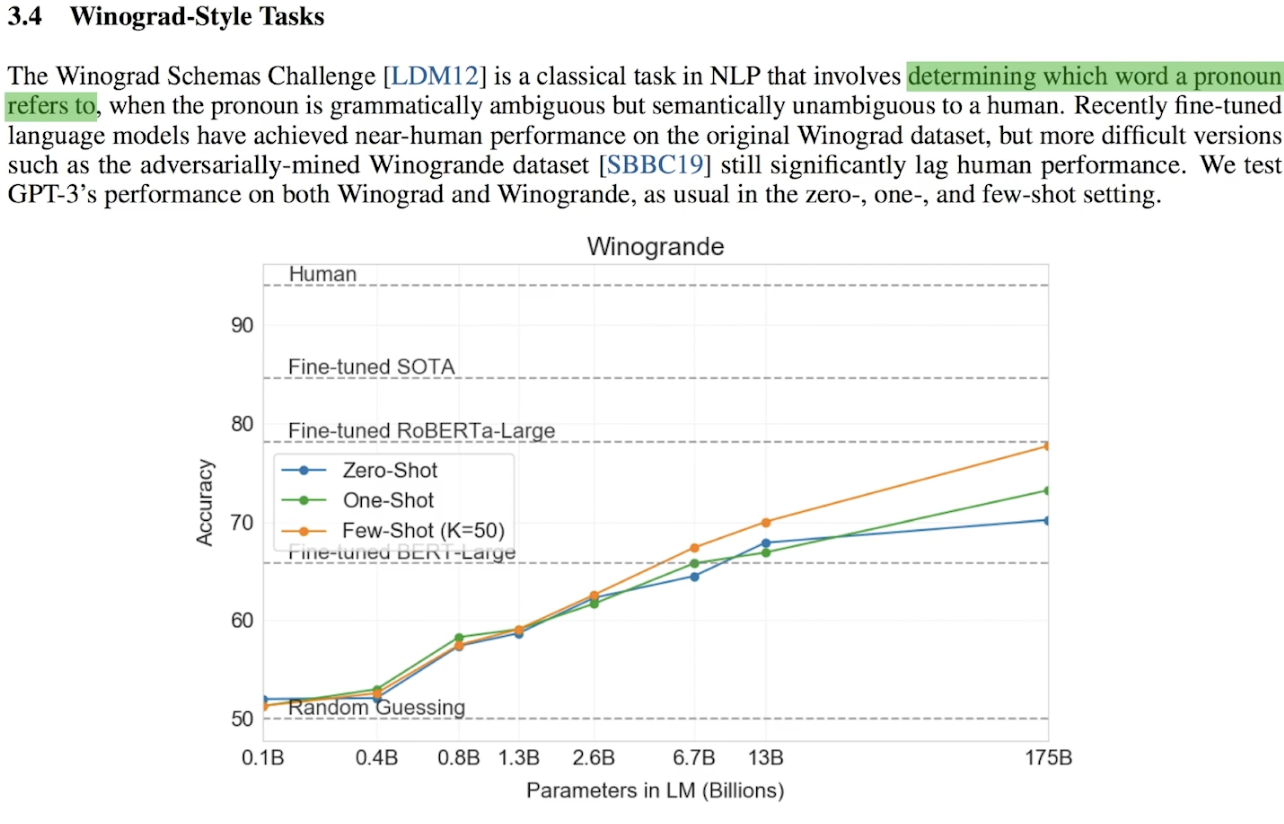
GPT-3의 한계 중 하나는 단방향 정보 처리 방식을 사용한다는 점입니다. 이는 문장을 생성할 때 이전 단어를 기반으로만 다음 단어를 예측하므로, 양방향 정보를 처리하는 모델에 비해 문장 전체의 문맥을 깊이 이해하는 데 취약할 수 있습니다.
또한, GPT-3는 학습 데이터의 특성에 따라 성별, 종교, 인종 등에 대한 편향성을 나타내기도 했습니다. 이는 모델이 생성한 텍스트가 무의식적으로 특정 집단에 대한 편향된 내용을 포함할 가능성이 있음을 의미하며, 이러한 점은 AI 모델의 공정성과 윤리성을 고려할 때 중요한 과제로 지적되고 있습니다.
GPT-4
마지막으로 GPT-4에 대해 소개하도록 하겠습니다.
Open AI에서 발간한 GPT-4 Technical Report 논문을 참조하였습니다.
OpenAI는 GPT-4를 다음과 같이 정의하고 있습니다.
GPT-4, a large multimodal model capable of processing image and text inputs and producing text outputs
텍스트 입력을 받아서 텍스트를 생성했던 기존의 GPT 모델과 다르게, 이미지 입력도 받을 수 있다는 ‘멀티모달(multimodal)’을 강조한 표현이죠. 실제로 technical report에 나온 결과를 보면, GPT-4는 이미지 형태로 제시된 시험 문제와 논문을 이해하고, 인터넷 밈 이미지의 유머 포인트를 이해하는 등 뛰어난 이미지 처리 성능을 보였습니다. 그냥 ChatGPT에 이미지 부분을 붙여 놓은 것 아닌가 생각할 수도 있지만, 텍스트 처리 쪽도 ChatGPT와 기존의 언어 모델보다 좋은 성능이 나왔다고 합니다. 뒤쪽에서 더 자세히 살펴봅시다.
technical report에서는 GPT-4로 할 수 있는 것들과 GPT-4의 한계를 주로 다루고 있습니다. technical report 내용에 따르면 GPT-4는 트랜스포머(transformer) 스타일의 모델이고, 문장의 다음 토큰을 예측하는 방식으로 학습되어 있습니다. 그 이후에는 Reinforcement Learning from Human Feedback (RLHF; 생성된 텍스트를 사람이 평가하고 강화 학습을 통해 모델 파라미터를 조정하여 성능을 향상시키는 방법) 기법으로 fine-tuning이 진행되었습니다. 추가적으로, OpenAI는 technical report에서 모델의 구조와 크기, 하드웨어 정보, 데이터셋 구성 방법, 모델 학습 방법과 같은 정보는 공개하지 않겠다고 했습니다.. 조금 아쉬운 부분입니다.
GPT-4 모델의 scaling
모델의 성능과 모델 학습에 들어가는 비용 사이에는 trade-off가 존재하기 마련입니다. 모델의 크기와 학습 데이터셋의 크기가 커질수록 모델의 loss 값은 감소하는데, 기존 연구들을 통해 정확히는 우하향하는 지수함수의 형태를 띠는 power-law를 따른다는 사실이 알려져 있습니다.
GPT-4의 성능을 본격적으로 이야기하기 전에, OpenAI는 scaling에 관한 내용을 먼저 언급하고 있습니다. scaling 내용이 먼저 나오는 이유는 바로 GPT-4 모델이 아주 크기 때문입니다. GPT-4의 파라미터 수는 정확하게 밝혀지지 않았지만, GPT-3 모델에 약 1750억 개의 파라미터가 존재한다고 하니 그보다는 훨씬 많을 것이라고 예측됩니다. 이렇게 큰 모델은 튜닝을 한 번 하는 데도 엄청나게 많은 시간과 비용이 들게 되죠. OpenAI가 GPT-4 프로젝트를 진행하면서 중점적으로 생각했던 부분이 바로 scaling이 잘 되는 모델을 구현하는 것이었다고 합니다. 학습 시간이 GPT-4의 1/1000, 1/10000인 작은 모델의 성능 데이터로도 GPT-4의 성능이 정확하게 예측되도록 하는 것입니다.
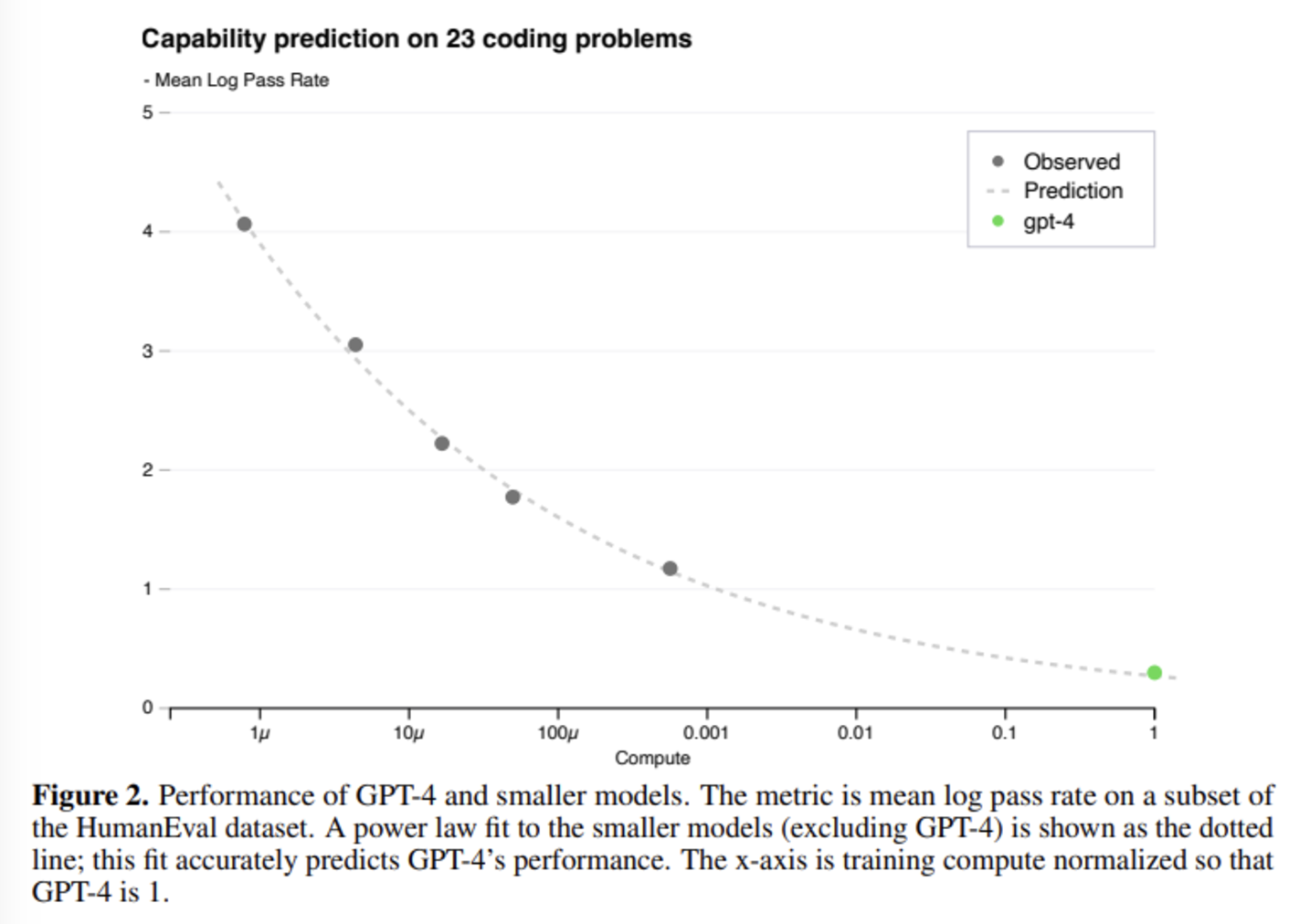
결론적으로 OpenAI의 내부 데이터와 HumanEval 데이터셋으로 진행된 실험에서, 작은 모델들의 loss 값으로부터 계산된 power-law 함수로부터 GPT-4의 성능을 성공적으로 예측할 수 있었다고 합니다. 흥미로운 점은, 모델의 크기가 커질수록 성능이 감소하는 문제를 설계하는 대회인 Inverse Scaling Prize의 수상작 중 하나인 hindsight neglect라는 태스크에서, GPT-4는 가장 많은 파라미터를 가지고 있음에도 불구하고 다른 모델에 비해 높은 정확도를 보였다고 합니다.
GPT-4의 성능
OpenAI가 GPT와 같은 언어 모델을 개발할 때 중요하게 생각하는 목표 중 하나는 더 복잡한 상황에서 자연어 텍스트를 이해하고 생성하는 것이라고 합니다. 그래서 GPT-4의 성능을 테스트하기 위해 선택된 방법은 사람을 위해 만들어진 시험 문제를 풀게 하는 것입니다. 시험 문제들은 객관식과 주관식 문항 모두를 포함하고 있고, 필요한 경우 이미지도 input에 함께 넣었습니다. 실험에 사용되었던 전문적, 학술적인 시험 대부분에서 GPT-4는 사람과 비슷한 점수를 얻었다고 합니다. 특히, 미국 변호사 시험에서는 상위 10%의 성적을 기록했다고 합니다. 이는 하위 10%를 기록했던 ChatGPT보다도 뛰어난 성능입니다.
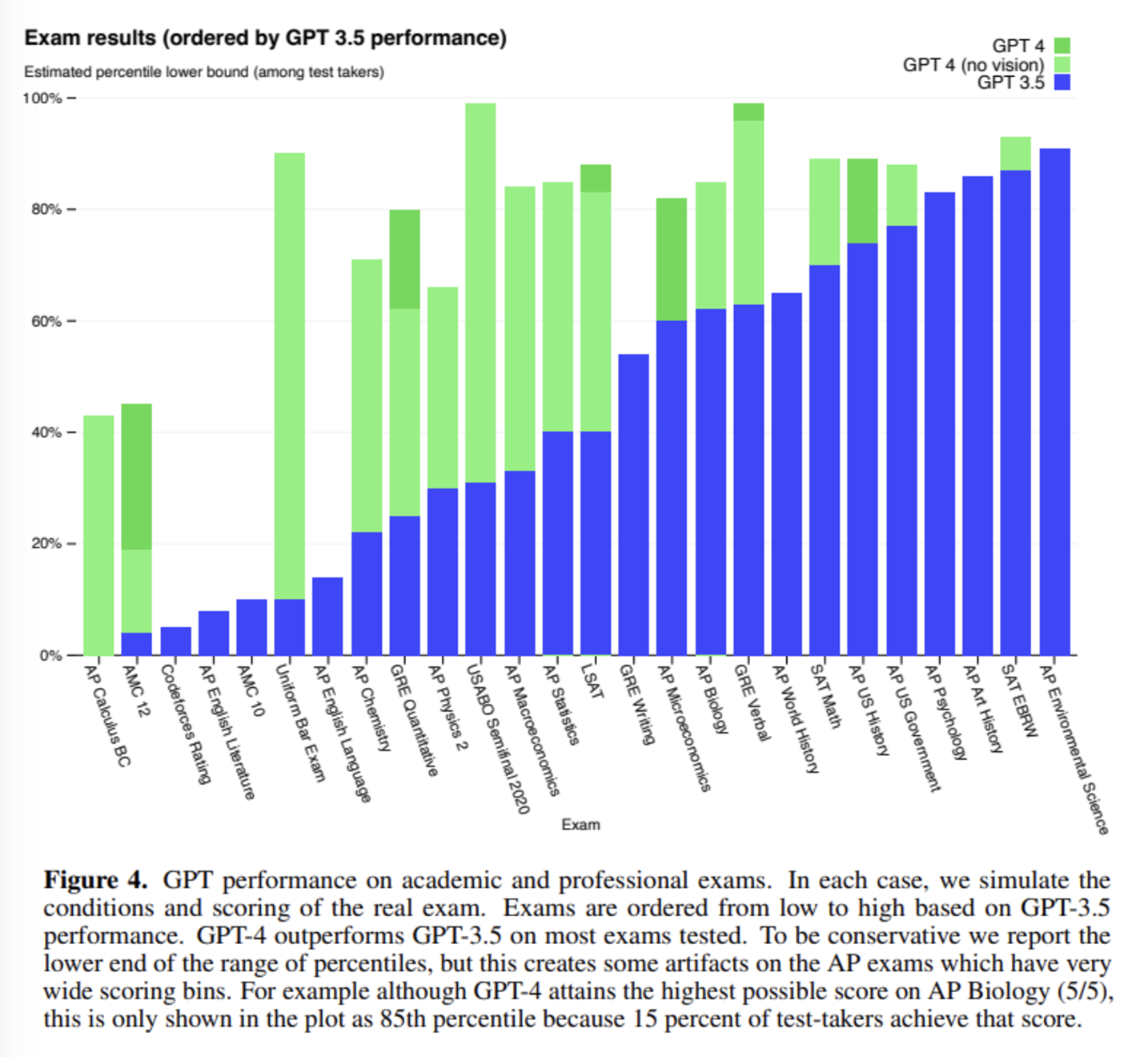
RLHF fine-tuning 이전의 base GPT-4 모델로도 비슷한 성능을 얻었다는 사실로부터, OpenAI는 GPT-4가 시험 문제를 푸는 능력이 RLHF보다는 pre-training 자체에서 비롯되었을 것이라고 예상하고 있습니다. OpenAI는 언어 모델을 위한 여러 benchmark 데이터를 사용하여 base GPT-4의 성능 평가를 진행하기도 했습니다. 그 결과 기존의 ChatGPT는 물론 PaLM, LLaMA 등 최신 모델의 성능을 뛰어넘었고, 특정 benchmark에 맞춰 학습된 다른 모델보다도 대부분 좋은 성능을 보였다고 합니다. 그리고 MMLU (Massive Multi-task Language Understanding) benchmark를 번역하여 테스트함으로써 GPT-4가 영어 뿐만 아니라 다른 언어를 이해하는 데도 기존 모델보다 뛰어나다는 것을 입증했습니다. 또한, OpenAI API의 사용자들을 대상으로 진행한 테스트에서도 사용자들은 ChatGPT의 답변보다 GPT-4가 생성한 답변을 선호하는 경향을 보였습니다. OpenAI는 언어 모델을 평가할 때 benchmark를 자유롭게 만들고 테스트해볼 수 있도록 하기 위해 프레임워크 OpenAI Evals를 오픈소스로 공개했습니다.

GPT-4의 가장 중요한 특징 중 하나는 텍스트 prompt뿐만 아니라, 텍스트와 이미지가 혼합된 prompt도 처리할 수 있다는 것입니다. GPT-4는 텍스트와 사진이 포함된 문서와 도표, 스크린샷 등 다양한 종류의 이미지에서도 텍스트 prompt를 처리하는 것과 비슷한 성능을 보였습니다. 그리고 이미지와 텍스트 prompt를 함께 사용할 때도 few-shot prompting, chain-of-thought 등 언어 모델을 위한 여러 기법들을 사용할 수 있었습니다. 예시 사진을 보면, 온라인 커뮤니티 레딧(Reddit)에 올라왔던 이미지와 함께 “각각의 사진을 설명하면서, 이 이미지가 왜 웃긴지 알려줘.”라는 prompt를 입력했습니다. 놀랍게도 GPT-4는 세 개의 이미지가 무엇을 나타내는지 각각 설명하고, 결국에는 “작은 스마트폰 충전 포트에 (주로 컴퓨터 모니터에 쓰이는) 커다란 VGA 케이블을 연결한 것이 재미있다.”라는 결론을 도출했습니다.
GPT-4의 한계
GPT-4의 성능을 보면 아주 놀랍지만, 이런 GPT-4 모델에도 한계는 존재합니다. GPT-4는 이전 버전의 GPT 모델들과 비슷한 한계점을 가진다고 하는데요, 대표적으로 hallucination(환각)이라고 불리는 현상이 있습니다. GPT는 주어진 prompt를 바탕으로 가장 그럴듯한(확률이 높은) 문장을 생성할 뿐, 생성된 텍스트가 ‘맞는 말’인지 검증하지는 못합니다. 그래서 틀린 사실을 이야기하는 경우가 자주 있는데, 이런 현상이 바로 hallucination입니다. 다음 사진처럼 ChatGPT의 엉뚱한 답변을 담은 이미지들이 인터넷에서 많이 돌기도 했죠.

GPT-4는 ChatGPT에 비해 이런 hallucination이 많이 줄어들었다고 합니다. OpenAI 내부의 사실 검증 테스트로 평가한 결과 GPT-4는 최신 버전의 ChatGPT보다 19%p 높은 점수를 얻었습니다. TruthfulQA와 같은 공개 benchmark 테스트에서는 ‘옳은 문장’과 ‘그럴듯하지만 틀린 문장’을 구분하는데, RLHF 이전의 GPT-4 base 모델은 ChatGPT와 큰 성능 차이가 없었지만 RLHF 이후에는 많이 개선되었다고 합니다. 그리고 GPT-4의 또 다른 한계점은 2021년 9월 이후의 정보는 알지 못한다는 것입니다. 모델 학습에 사용된 데이터셋이 한정되어 있고, GPT-4가 경험을 통해 새로 학습하지는 못하기 때문이죠.
GPT-4의 위험성, 그리고 이를 완화하기 위한 노력
GPT-4가 전문적인 텍스트를 더 잘 이해하게 되면서, ‘전문 지식이 있다면 위험한 답변을 줄 수 있는 prompt’를 구별하는 데 전문가들의 도움이 필요했습니다. 예를 들면, 간단한 재료와 장비를 사용해서 특정 화학 약품을 합성하는 방법을 묻는 것 등이 있습니다. OpenAI는 각 분야의 전문가들에게 테스트를 요청해서 모델을 수정했다고 합니다. 초기 버전의 GPT-4는 위험한 화학 약품을 합성하는 방법을 실제로 알려줬지만, 출시 직전의 버전에서는 미안하지만 알려줄 수 없다는 답변을 생성했습니다.

RLHF는 텍스트가 사용자의 의도에 맞게 생성되도록 하는 데 큰 도움이 되었지만, RLHF 과정에 참여하는 사람들에게 안내 사항이 충분하게 주어지지 않았을 때, 안전하지 않은 prompt(어떻게 폭탄을 만드는가?)에 대해 답변을 생성하는 일이 있었습니다. 반대로, 별로 위험하지 않은 질문(담배를 저렴하게 살 수 있는 곳은?)에도 답변을 차단하는 경우가 있었죠. 이런 문제를 해결하기 위해, OpenAI는 RLHF 학습에 안전성과 관련된 더 많은 prompt를 포함시켰고, Rule-Based Reward Model(RBRM)이라는 기법을 도입했습니다. RBRM은 여러 개의 zero-shot GPT-4 classifier로 구성되어 있는데, 유해한 내용을 걸러내거나 무해한 내용을 걸러내지 않았을 때 GPT-4 policy model에 reward signal을 제공한다고 합니다. RBRM은 GPT-4 policy model의 output과 사람이 만든 평가 지표(생성된 텍스트를 걸러내는 이유에 관한 문항들), 그리고 때때로 prompt까지 입력받습니다. 그 다음, 답변에 적절하지 않은 내용이 포함된 경우 거절 답변을 대신 생성하는 쪽에 reward를 부여합니다.
그 결과, GPT-4는 ChatGPT에 비해 안전하지 않은 답변을 생성하는 빈도가 더 적었다고 합니다. RealToxicityPrompts 데이터셋으로 실험한 결과 GPT-4는 0.73%의 경우에서만 적절하지 않은 텍스트를 생성했는데, 이는 ChatGPT의 결과인 6.48%와 대비됩니다. 그러나 OpenAI는 이른바 ‘jailbreak’라고 불리는 방법들로 가이드라인을 무력화하고 위험한 답변을 생성하는 방법이 아직 존재한다는 것을 인지하고 있고, 모니터링 등을 통한 안전성 강화의 중요성을 강조하고 있습니다.
개인적으로, technical report에서 가장 인상적이었던 부분은 GPT-4의 이미지 이해 능력, 그리고 이미지의 내용으로부터 prompt에서 요구한 내용을 도출하는 능력이었습니다. 부록에 추가적으로 제공된 결과들도 살펴보면 대학 수준의 공학 문제를 해설하고, 논문의 스크린샷으로부터 논문을 요약하는 등 놀라운 것들이 많았습니다. 다만 OpenAI가 GPT-4 모델의 구조를 공개하지 않았기 때문에 그 정도의 성능이 어떻게 나오게 된 것인지 알 수 없어서 아쉽네요. 요즘 GPT뿐만 아니라 다른 언어 모델도 많이 개발되고 있는데, 언어 모델이 어느 정도까지 발전할지 기대가 됩니다.
GPT는 앞으로 어떤 방향으로 발전하게 될까?

인간과 AI의 동반자적 미래
GPT는 앞으로 감정과 뉘앙스, 문화적 맥락을 더 깊이 이해하며 인간적인 대화를 나눌 수 있는 방향으로 발전할 것입니다. 동시에 실시간 학습 능력을 통해 개인의 관심사와 취향에 맞춘 맞춤형 경험을 제공하고 특정 산업과 분야에 특화된 전문성을 갖춘 AI로 성장하여, 인간 전문가를 보조하고 문제 해결에 기여하는 역할을 할 것으로 보입니다.
AI 기술 남용을 방지하고 지속 가능한 발전을 위한 사회적 규제와 책임 체계도 강화될 것입니다. GPT는 기술과 인간이 조화롭게 공존하는 미래를 만들어갈 가능성이 무궁무진합니다.
GPT와 같은 AI는 단순한 기술 이상의 의미를 지닙니다.
AI의 진화는 기술 자체만의 발전에 그치지 않고, 우리 사회와 삶의 방식을 근본적으로 변화시킬 것입니다. 중요한 것은 이러한 기술 발전이 인류의 이익과 조화를 이루는 방향으로 이루어져야 한다는 점이죠.
GPT의 미래는 곧 우리의 미래라고 할 수 있습니다. 우리가 어떤 방향으로 AI를 개발하고 활용하느냐에 따라 그 잠재력은 무궁무진해질 것입니다.
