[CS 지식] Dynamic Memory Allocation
명시적 할당기 / 묵시적 할당기
명시적 할당기 (Explicit Allocator)
- 메모리 할당 및 해제를 사용자가 직접 관리하는 경우
- 라이브러리에 따라 할당-해제 쌍으로 묶는다면: malloc-free, new-delete
- C, C++, Rust 등
묵시적 할당기 (Implicit Allocator)
- 운영체제나 라이브러리에 의해 자동으로 처리되는 경우
- Garbage Collector
- python, javascript 등
mmap / munmap
mmap
- mmap 시스템 콜 호출 시 운영체제 수준에서 메모리 매핑
- 가상 메모리 주소 공간에 파일이나 디바이스를 매핑하므로 커널 레벨의 접근 권한 요구
- 페이지 단위로 메모리를 할당하며, 페이지 크기는 시스템에 따라 다름 (일반적으로 4KB)
munmap
- munmap 시스템 콜 호출 시 운영체제 수준에서 메모리 매핑 해제
- 마찬가지로 커널 레벨의 접근 권한 요구
- 매핑된 페이지 단위로 메모리 매핑을 해제
brk
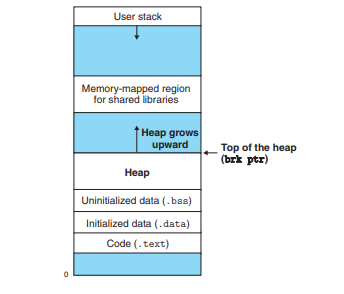
스택의 스택 포인터(%rsp)의 힙 영역 버전. brk는 더하기 연산을 할 시에 메모리가 할당되고 빼기 연산을 할 시에 메모리가 반납된다.
더블 워드 (8byte) 정렬 룰
x86-64 아키텍처에서 메모리를 8의 배수로 정렬하는 이유는 주로 성능 및 효율성과 관련이 있다.
하드웨어 요구 사항: 대부분의 하드웨어 아키텍처에서, 특히 x86-64 아키텍처에서, 데이터가 8바이트 블록으로 읽히는 것이 효율적이다. 메모리를 8의 배수로 정렬하면 이러한 8바이트 블록을 효과적으로 활용할 수 있다.
캐시 효율성: 많은 프로세서는 캐시 라인 크기가 8바이트의 배수인 경우 성능이 향상되는 경향이 있다. 따라서 메모리를 8의 배수로 정렬하면 캐시에서의 데이터 액세스가 최적화되어 성능 향상을 가져올 수 있다.
SIMD 명령어 집합 활용: Single Instruction, Multiple Data (SIMD) 명령어 집합을 사용하는 경우, 데이터가 8의 배수로 정렬되면 SIMD 연산이 최적화되어 더 빠르게 수행된다.
메모리를 8의 배수로 정렬하는 것은 이러한 하드웨어 특성을 최대한 활용하여 성능을 최적화하고, 메모리 액세스의 효율성을 향상시키기 위한 일반적인 관행이다.
메모리 패딩 (Memory Padding)
메모리 할당 시 8의 배수 정렬 룰에 의해 적용되는 패딩은 메모리를 할당할 때 요청된 크기에 8의 배수가 되도록 조정되는 과정을 말한다. 이로 인해 할당된 메모리 블록의 크기는 요청된 크기보다 조금 더 크게 되며, 남는 바이트들이 0으로 채워져 패딩이 추가된다. 이렇게 정렬된 메모리는 성능 향상 및 하드웨어 요구 사항을 충족하기 위한 목적으로 사용된다.
메모리 패딩으로 인해 내부 단편화가 발생하고, 이는 외부 단편화를 최소화하기 위한 전략이기 때문에 내부 단편화와 외부 단편화 사이의 밸런스를 조정하기 위해 메모리 패딩의 적절한 크기 설정이 중요하다.
내부 단편화 / 외부 단편화
내부 단편화 (Internal Fragmentation)
- 더블 워드 정렬 룰 등으로 인해 실제로 필요한 크기보다 큰 메모리 블록을 할당한 경우, 해당 블록 내에 남는 공간이 발생. 메모리의 일부가 실제로 사용되지 않고 낭비되는 상황
외부 단편화 (External Fragmentation)
- 동적으로 할당되고 해제되는 메모리 블록들이 메모리 공간에 흩어져 있어, 실제로 사용 가능한 큰 메모리 블록이 존재하지만 이들을 활용하기 어려운 경우. 외부 단편화는 총 사용 가능한 메모리 공간은 충분하지만, 단일 큰 블록을 할당하는 데 어려움을 겪는 상황

출처 - 그림으로 알아보는 메모리 동적할당 - Implicit, Explicit, Segregated list Allocator
묵시적 가용 리스트 / 명시적 가용 리스트 / 분리 가용 리스트
*참고로 위의 묵시적 할당기/명시적 할당기와는 관계 없는 용어다. 헷갈리지 말자.
묵시적 가용 리스트 (Implicit Free List)
- 힙 내부에서 할당된 블록과 가용 블록이 연속적으로 배치되며, 블록의 할당 여부를 블록의 헤더 정보를 통해 구분하는 방식
- 각 블록의 헤더에는 블록의 크기와 할당 여부를 나타내는 정보가 포함되어 있어, 이 정보를 통해 가용 블록을 묵시적으로 파악
- 할당 요청: 힙을 순차적으로 탐색하며 적절한 크기의 가용 블록 순회 탐색. 이 과정에서 할당된 블록은 건너뛰고, 탐색 정책(□□□-fit)에 따라 할당 가능한 블록을 색출
- 할당 해제: 해제된 블록의 헤더 정보를 업데이트하여 가용 블록으로 표시. 이때, 인접한 가용 블록들과 병합(coalescing)하여 더 큰 가용 블록을 생성할 수 있음
- 묵시적 가용 리스트는 구현이 간단하고 메모리 오버헤드가 적지만, 할당 및 해제 연산 시 힙 전체를 탐색해야 하는 문제
명시적 가용 리스트 (Explicit Free List)
- 가용 블록들을 별도의 Linked List로 관리하는 방식
- 각 가용 블록의 헤더에는 다음 가용 블록과 이전 가용 블록의 주소를 가리키는 포인터가 있어, 이를 통해 가용 블록들이 양방향 연결 리스트로 명시적으로 연결
- 할당 요청: Linked List(=가용 블록 리스트 묶음)를 탐색하여 적절한 크기의 가용 블록을 찾아 할당
- 할당 해제: 해당 블록을 다시 가용 리스트에 추가
- 연결 리스트 사용으로 인해 블록 할당 및 해제 시 추가 오버헤드가 발생할 수 있지만, 가용 블록 탐색이 효율적이며 외부 단편화를 최소화
분리 가용 리스트 (Segregated Free List)
- 가용 블록들을 크기에 따라 여러 개의 크기 클래스로 나누어 관리하는 방식
- 각 크기 클래스는 해당 크기 범위에 속하는 가용 블록들을 관리하는 독립적인 Linked List로 구성
- 할당 요청: 요청된 크기에 해당하는 크기 클래스의 Linked List를 탐색하여 적절한 가용 블록을 찾아 할당. 이때 가용 블록 리스트 묶음을 크기별로 나눈 상위 묶음에서 탐색
- 할당 해제: 해제된 블록을 해당 크기 클래스의 Linked List에 추가. 이때, 인접한 가용 블록들과의 병합(coalescing)도 고려 가능
- 크기 클래스의 개수와 범위는 메모리 할당자의 설계에 따라 다양하게 설정. 일반적으로 작은 크기의 블록들은 더 세분화된 크기 클래스로 관리
- Segregated Free List는 가용 블록 탐색의 효율성을 높이고, 메모리 할당 및 해제 연산의 속도를 향상 및 외부 단편화를 최소화
묵시적 가용 리스트 - 할당 블록 배치
first-fit
- First-fit 전략은 가용한 메모리 블록 중에서 요청한 크기와 가장 먼저 맞는 첫 번째 블록을 선택하여 할당하는 방식이다. 이 방법은 빠르게 가용 블록을 찾을 수 있어 효율적이지만, 가용 블록의 크기와 요청한 크기가 정확히 일치하지 않을 경우 내부 단편화가 잦은 문제가 있다.
next-fit
- Next-fit 전략은 직전에 할당된 위치에서부터 순서대로 가용한 블록을 검색하여 처음으로 맞는 블록을 선택하여 할당한다. 이 방법은 항상 특정 위치에서 탐색을 시작하므로 특정 영역에 집중되어 내부 단편화가 잦은 문제가 있다.
best-fit
- Best-fit 전략은 요청한 크기와 가장 근접한 크기의 가용 블록을 선택하여 할당한다. 이 방법은 내부 단편화를 최소화하려는 목적이 있어, 가능한 최적 크기의 가용 블록을 모두 탐색하고, 그 중 하나에 할당한다. 그러나 블록을 찾는 데에 시간이 더 많이 소요되어 First-fit이나 Next-fit에 비해 더 많은 연산이 필요할 수 있다.
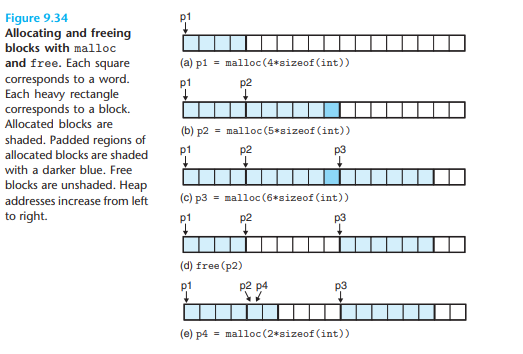
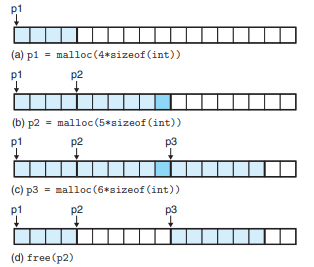
묵시적 가용 리스트 - 가용 블록 분할
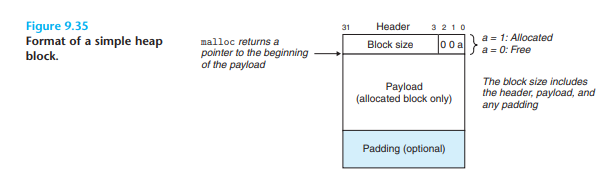
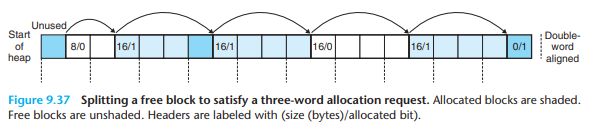
- (전체 블록 리스트의 헤더와 푸터 사이에) 헤더와 페이로드와 패딩으로만 구성된 할당 블록 리스트들이 배치된 모습이다. 할당 정책에 따라 블록 리스트를 할당하고 해제를 반복하다 보면 위 사진과 같이 가용 블록 리스트가 분할되기 마련이며, 이는 외부 단편화를 나타낸다.
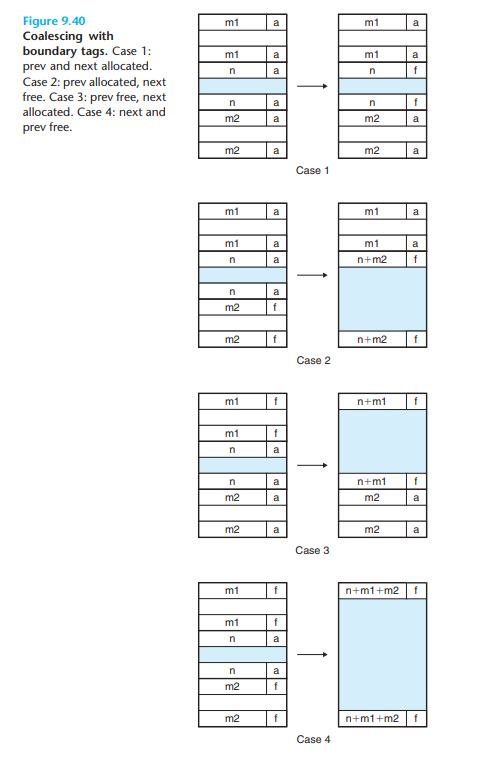
묵가리 - 가용 블록 병합(coalescing)
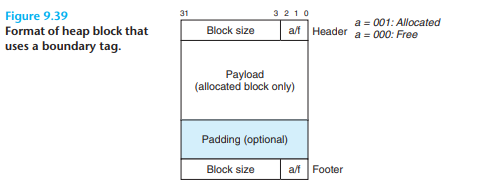
- 위와 같은 외부 단편화를 최소화하기 위해 블록 하나를 소비해 경계 태그라고 하는 푸터를 추가한다. 이러면 할당 블록 리스트를 해제할 때마다 왼쪽 이웃 블록 리스트가 가용 블록인 조건에서 병합하는 과정을 추가할 수 있다. (오른쪽 이웃 블록 리스트는 헤더로 병합할 수 있다)
- 병합 케이스는 아래 사진에 잘 나와있다.