Connection Draining(Target Deregistration Delay)
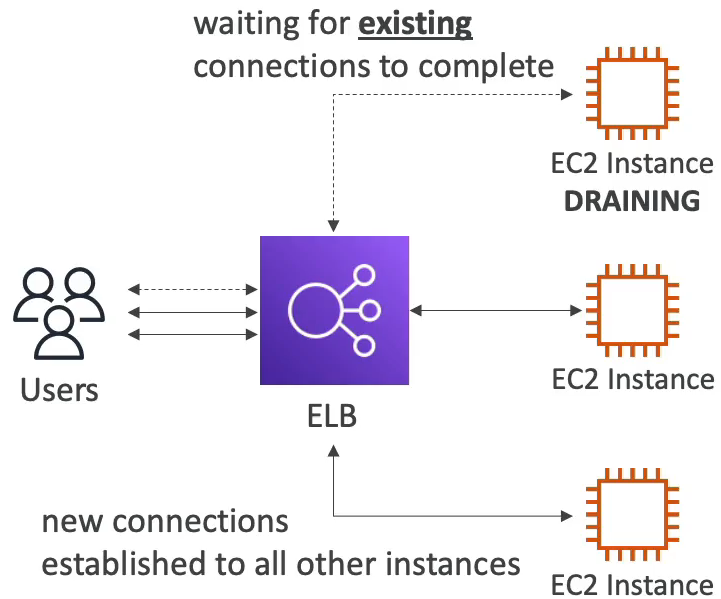
인스턴스(또는 타깃)를 서비스에서 빼거나(스케일 인, 교체, 종료) 헬스체크 실패로 제거할 때, 기존에 열린 연결(요청)을 일정 시간 동안 유지해 처리 완료되도록 하고 새로운 연결은 그 인스턴스로 보내지 않게 하는 기능
=> 트래픽을 “부드럽게 끊는” 장치
Classic ELB vs ALB/NLB(=ELBv2) 용어 차이
-
Classic ELB: 용어로 Connection Draining이라 부름(콘솔/CLI 옵션 있음)
-
ALB / NLB (ELBv2 Target Group): Deregistration delay 라고 부름 (초 단위로 설정)
동일한 개념: 제거 시 기존 연결을 일정 시간 허용
필요한 이유?
-
요청 중단 방지: 사용자의 요청(특히 긴 요청, 업로드/다운로드, WebSocket 등)이 중간에 끊기는 걸 막음
-
무중단 배포: 인스턴스 교체(Auto Scaling, 배포) 시 서비스 가용성 유지
-
데이터 무결성: 트랜잭션/세션이 중단되는 사고를 줄임
동작 원리
-
인스턴스/타깃을 Deregister(또는 ELB가 인스턴스 종료를 감지) 요청을 받음
-
ELB/Target Group은 그 인스턴스로의 새 연결(요청)을 중단시킴
-
기존에 이미 맺어진 연결이나 이미 전달된 요청(인플라이트 requests)은 지정된 대기 시간(드레이닝 시간) 동안 계속 처리되도록 허용
-
드레이닝 시간 내에 처리 완료되면 정상적으로 연결 종료
-
시간이 지나도 연결/요청이 남아있다면 강제 종료(컷오프) 후 완전 제거
설정(AWS 관점)
-
Target Group (ALB/NLB): deregistration_delay.timeout_seconds (최대 3600초(1시간) 가능)
예: 기본 300초(5분)인 경우가 많음(계정/설정에 따라 다름)
-
Classic ELB: Connection Draining 설정에서 Enabled + Timeout(초) 설정 가능
- ALB&NLB CLI 예시
aws elbv2 modify-target-group-attributes \
--target-group-arn <tg-arn> \
--attributes Key=deregistration_delay.timeout_seconds,Value=300
- CLB CLI 예시
aws elb modify-load-balancer-attributes \
--load-balancer-name my-elb \
--load-balancer-attributes '{"ConnectionDraining":{"Enabled":true,"Timeout":300}}'
세부 동작 / 주의 포인트
-
새 연결은 차단되지만 기존 연결(keep-alive, WebSocket, TCP 연결 등) 은 유지됨
-
ALB의 경우, HTTP 요청이 이미 백엔드에 도달한 상태라면 그 요청은 처리되도록 허용
-
긴 시간 걸리는 요청(대용량 업로드 등)이 있으면 드레이닝 시간을 충분히 길게 잡아야 함
-
강제 종료 조건: 드레이닝 시간이 끝나면 남은 연결은 강제로 닫힘 — 그러므로 처리시간보다 드레이닝 시간을 길게 잡아야 안전
-
Health checks: 인스턴스가 헬스체크 실패 상태로 바뀌면 드레이닝이 트리거됨(제거 절차 시작)
-
Sticky session 영향: 쿠키 기반 세션이 있어도, 드레이닝 중엔 해당 인스턴스로 새 요청을 보내지 않으니 세션 유실 가능성 고려 필요(세션 공유 권장)
‼️ 헬스체크가 즉시 드레이닝을 트리거하진 않고, 헬스체크의 판정(연속 실패 수)이 나와야 드레이닝(제거 절차)이 시작된다
=> 헬스체크가 설정한 unhealthy threshold 만큼 연속 실패하면 그 타깃을 언헬시로 표시하고, 그 시점에 deregistration(제거) 절차/드레이닝이 시작
요약 정리
-
헬스체크가 ‘실패했다 → 바로 드레이닝’이 아니다: 실패는 연속 실패 수로 판정되므로 즉시 트리거 되지 않음(설정에 따라 지연 있음)
-
드레이닝 중에도 헬스체크는 계속 수행된다
-
드레이닝 시작 후 타깃이 다시 정상(헬시) 판정을 받으면, ALB는 드레이닝을 중단하고 해당 타깃을 다시 서비스에 포함시킬 수 있다
-
즉, 일시적 장애(네트워크 일시 오류 등)였고 빠르게 회복되면 제거가 취소될 수 있음
-
인스턴스가 즉시 죽거나 프로세스가 강제 종료된 경우에는 '드레이닝 대기'가 의미가 없고 이미 맺어진 연결도 끊김 → 사용자 요청 실패
